







1.论文概述
近年来,应用于编程语言的预训练模型得到飞速发展,相关任务比如code search, code completion, code summarization 也得到提升。但是,现有的预训练模型是将code snippet(代码片段)视为一个token序列。忽视了代码的结构。
GraphCodeBERT应运而生,GraphCodeBert是基于数据流(data flow)来表示源代码信息。数据流提取的信息是变量之间的信息流(where-the-value-comes-from)。数据流是一个图结构(graph)。图中的结点表示一个变量(variable),边表示变量之间的依赖关系(where-the-value-comes-from)。
GraphCodeBert采用数据流而不是AST,是考虑到数据流图不像AST这么复杂,也不会带来不必要的深层信息。
1.2.预训练任务
作者在这里提出2个预训练任务:
-
data flow edges prediction
数据流边预测,用来学习代码的结构化表示 -
variable-alignment across source code and data flow
源代码和数据流之间的变量分配,用于学习数据流结点来自源代码中哪个token
预训练用到的数据集是CodeSearchNet dataset
1.3.下游任务
作者在4个任务上评估预训练模型,分别是:
- natural language code search,代码搜索
- clone detection,克隆检测
- code translation,代码翻译
- code refinement,代码细化
1.4.论文贡献
- GraphCodeBERT是第一个利用代码的语义结构来学习代码表示的预训练模型
- 提出2个预训练任务,用于从源代码和数据流学习向量表示
- GraphCodeBERT在四个下游任务上提供了显著的改进,即代码搜索、克隆检测、代码翻译和代码细化
2.预训练
2.1.数据流图
数据流图用来表示变量之间的依赖关系 ,结点代表变量(variable),边代表变量之间的信息流向( where the value of each variable comes from),对于同一源代码,不同抽象语法下的数据流是相同的。
使用数据流的好处如下:
- 以
v = maxvalue − minvalue为例,程序员并不总是遵循命名约定,因此很难理解变量的语义,比如v。而数据流提供了一种在某种程度上理解变量v的语义的方法。数据流图中,v的值来自数据流中的maxvalue和minvalue。 - 数据流支持该模型考虑在遥远的地方使用相同的变量或函数所引起的长期依赖性。(dataflow supports the model to consider long-range dependencies induced by using the same variableor function in distant locations),比如下图中 x 3 , x 7 , x 9 , x 11 x^3, x^7, x^9, x^{11} x3,x7,x9,x11,4个变量有着相同的变量名,但语义信息不同
获取数据流图的流程如下:
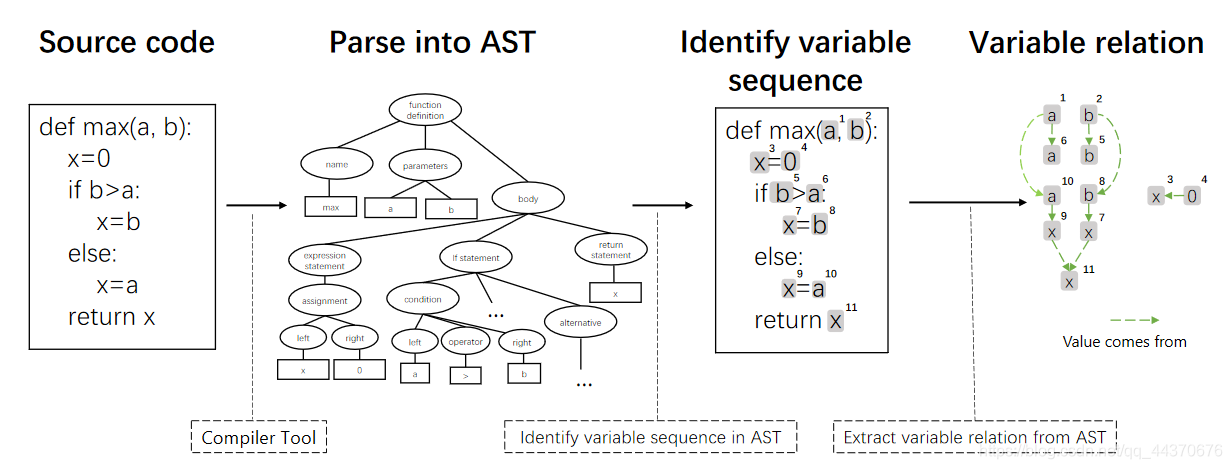
-
构造AST
给定源代码 C = { c 1 , c 2 , . . . , c n } C = \left\{ c_1, c_2,..., c_n \right\} C={c1,c2,...,cn} ,先有标准的编译工具将它们解析成AST。这里用到的解析工具是tree-sitter。该解析工具支持论文中提到的6种编程语言,打破了ANTLR的限制。 -
从AST种提取变量序列(variable sequence)
变量序列标识为 V = { v 1 , v 2 , . . . , v k } V = \left\{ v_1, v_2,..., v_k \right\} V={v1,v2,...,vk},变量序列种的每个元素都会作为数据流图的一个结点。 -
从AST中提取变量之间的依赖关系,构建数据流图
数据流图的每个结点来自变量序列,边 ε = ⟨ v i , v j ⟩ \varepsilon = \langle v_i, v_j \rangle ε=⟨vi,vj⟩ 表示变量序列中第 j j j 个变量依赖于第 i i i 个变量。在赋值语句x = expr #expr为表达式这句中。x依赖于expr中的所有变量。 边集合 E = { ε 1 , ε 2 , . . . , ε l } E = \left\{ \varepsilon_1, \varepsilon_2,..., \varepsilon_l \right\} E={ε1,ε2,...,εl} 。 数据流图 G ( C ) = ( V , E ) G(C) = (V, E) G(C)=(V,E) 为源代码 C C C 的数据流图。
2.2.GraphCodeBERT
模型架构如下图所示
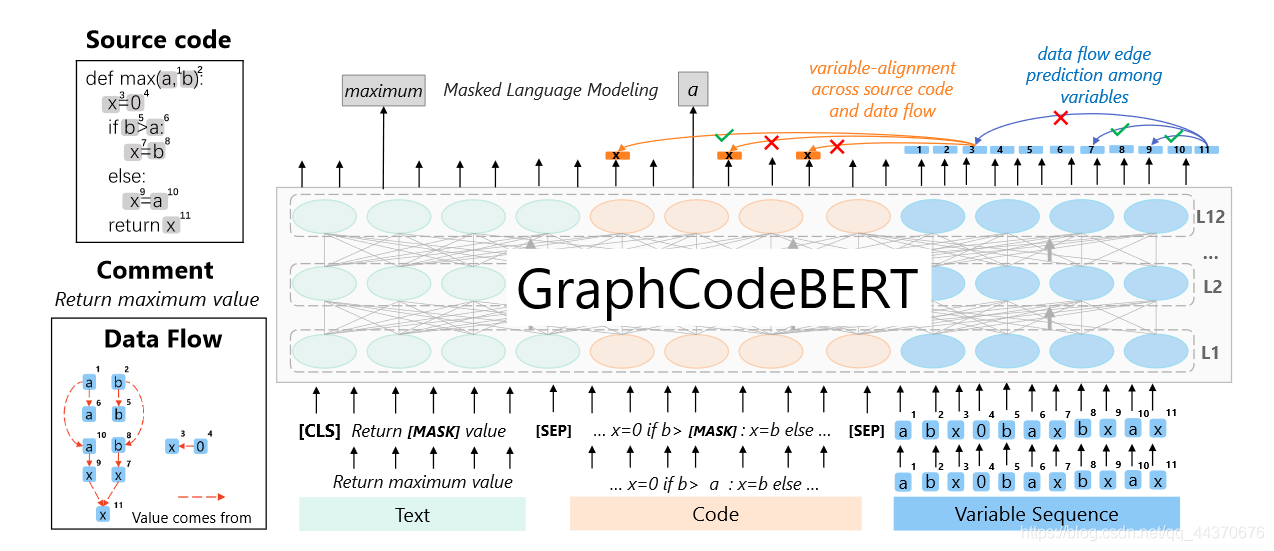 该模型以源代码和注释以及相应的数据流作为输入,并用标准的masked language模型应用在2个结构化预训练任务上:
该模型以源代码和注释以及相应的数据流作为输入,并用标准的masked language模型应用在2个结构化预训练任务上:
-
预测变量来源
predict where a variable is identified from (marked with orange lines) -
预测边
data flow edgesprediction between variables (marked with blue lines)
2.2.1.模型架构
GraphCodeBert使用Bert作为模型骨架。
给定源代码 C = { c 1 , c 2 , . . . , c n } C = \left\{ c_1, c_2,..., c_n \right\} C={c1,c2,...,cn}, 对应的注释 W = { w 1 , w 2 , . . . , w m } W = \left\{ w_1, w_2,..., w_m \right\} W={w1,w2,...,wm}。 相应的数据流图 G ( C ) = ( V , E ) G(C) = (V, E) G(C)=(V,E), V = { v 1 , v 2 , . . . , v k } V = \left\{ v_1, v_2,..., v_k \right\} V={v1,v2,...,vk}为变量序列, E = { ε 1 , ε 2 , . . . , ε l } E = \left\{ \varepsilon_1, \varepsilon_2,..., \varepsilon_l \right\} E={ε1,ε2,...,εl} 为边集合,其中每条边代表数据流向。
2.2.1.1.输入序列
输入包括以下部分:
- 源代码 C = { c 1 , c 2 , . . . , c n } C = \left\{ c_1, c_2,..., c_n \right\} C={c1,c2,...,cn}
- 对应的注释 W = { w 1 , w 2 , . . . , w m } W = \left\{ w_1, w_2,..., w_m \right\} W={w1,w2,...,wm}
- 变量序列 V = { v 1 , v 2 , . . . , v k } V = \left\{ v_1, v_2,..., v_k \right\} V={v1,v2,...,vk}
最终输入的序列
X
X
X 为上面3个序列的连接
X
=
{
[
C
L
S
]
,
W
,
[
S
E
P
]
,
C
,
[
S
E
P
]
,
V
}
X = \left\{ [CLS],W,[SEP],C,[SEP],V \right\}
X={[CLS],W,[SEP],C,[SEP],V}
[CLS]是三段前面的一个特殊标记,[SEP]是2个序列间的分隔符。
2.2.1.2.向量化
输入序列
X
X
X 会被转化为向量
H
0
H^0
H0。 包括了token和position embedding。并对变量序列
V
V
V 使用了一种特殊的position embedding 来标识它们是数据流图的一个结点。模型应用了
N
N
N 个transformer层来产生 contextual representations,论文里
N
N
N 的值设为12。
H
n
=
t
r
a
n
s
f
o
r
m
e
r
n
(
H
n
−
1
)
,
n
∈
[
1
,
N
]
H^n=transformern(H^{n−1}),n∈[1,N]
Hn=transformern(Hn−1),n∈[1,N]
H n H^n Hn 是 ∣ X ∣ × d h |X| \times d_h ∣X∣×dh 维度的向量,论文里隐层向量维度为768。
该transformer层内部如下
G
n
=
L
N
(
M
u
l
t
i
A
t
t
n
(
H
n
−
1
)
+
H
n
−
1
)
G^n=LN(MultiAttn(H^{n−1}) +H^{n−1})
Gn=LN(MultiAttn(Hn−1)+Hn−1)
H
n
=
L
N
(
F
F
N
(
G
n
)
+
G
n
)
H^n=LN(FFN(G^n) +G^n)
Hn=LN(FFN(Gn)+Gn)
其中
- M u l t i A t t n MultiAttn MultiAttn 是 multi-headed self-attention mechanism,论文设置了12个attention head。
- F F N FFN FFN 是 2层前向反馈网络
- L N LN LN 是 layer normalization操作
M u l t i A t t n MultiAttn MultiAttn 内部计算如下,设 G n ^ = M u l t i A t t n ( H n − 1 ) \hat{G^n} = MultiAttn(H^{n - 1}) Gn^=MultiAttn(Hn−1)
Q
i
=
H
n
−
1
.
W
i
Q
,
K
i
=
H
n
−
1
.
W
i
K
,
V
i
=
H
n
−
1
.
W
i
V
Q_i=H^{n−1}.W^Q_i, K_i = H^{n−1}.W^K_i, V_i = H^{n−1}.W^V_i
Qi=Hn−1.WiQ,Ki=Hn−1.WiK,Vi=Hn−1.WiV
h
e
a
d
i
=
s
o
f
t
m
a
x
(
Q
i
.
K
i
T
d
k
+
M
)
.
V
i
head_i = softmax(\frac{Q_i.K^T_i}{\sqrt{d_k}}+ M).V_i
headi=softmax(dkQi.KiT+M).Vi
G
n
^
=
[
h
e
a
d
1
;
.
.
.
;
h
e
a
d
u
]
.
W
n
O
\hat{G^n} = [head_1;...;head_u].W^O_n
Gn^=[head1;...;headu].WnO
其中
- ∣ X ∣ |X| ∣X∣ 表示输入序列的长度,包括 token序列, 注释序列,变量序列。
- H n H^n Hn 是 ∣ X ∣ × d h |X| \times d_h ∣X∣×dh 维度的向量。
- 模型参数 W i Q , W i K , W i V W^Q_i, W^K_i, W^V_i WiQ,WiK,WiV 是 d h × d k d_h \times d_k dh×dk 维度向量。
- 模型参数 W n O W^O_n WnO 是 d h × d h d_h \times d_h dh×dh 维度向量。
- M M M 是 Graph-Guided Masked Attention 矩阵(GraphCodeBert相比于Bert的特色之处), ∣ X ∣ × ∣ X ∣ |X| \times |X| ∣X∣×∣X∣ 维度向量。引用原文:where M i j M_{ij} Mij is 0 if i-th token is allowed to attend j-th token otherwise − ∞ -\infty −∞。大概功能就是在softmax时,如果序列第 i i i 个和第 j j j 个token之间没有数据流关联,softmax结果为0。
2.2.2.Graph-Guided Masked Attention
这里用
-
v i v_i vi 表示变量序列 V V V 第 i i i 个变量
-
c i c_i ci 表示源代码token集合 C C C 第 i i i 个token
-
E ′ E^{'} E′ 定义为,如果变量 v i v_i vi 与token序列第 j j j 个token c j c_j cj 相关联, 那么 〈 v i , c j 〉 / 〈 c j , v i 〉 ∈ E ′ 〈v_i,c_j〉/〈c_j,v_i〉∈E^′ 〈vi,cj〉/〈cj,vi〉∈E′
为了将图结构引入transformer,这里提出Graph-Guided Masked Attention 来过滤不相关signal。graph-guided masked attention用矩阵 M M M 表示。
M i j = { 0 i f ( q i ∈ [ C L S ] , [ S E P ] ) o r ( q i , k j ∈ W ∪ C ) o r ( 〈 q i , k j 〉 ∈ E ∪ E ′ ) − ∞ o t h e r w i s e M_{ij}=\left\{ \begin{array}{rcl} 0 & & {if (q_i∈{[CLS],[SEP]}) or( q_i,k_j∈ W∪C) or (〈q_i,k_j〉∈ E∪E^{'}}) \\ -\infty & & {otherwise}\\ \end{array} \right. Mij={0−∞if(qi∈[CLS],[SEP])or(qi,kj∈W∪C)or(〈qi,kj〉∈E∪E′)otherwise
-
[CLS], [SEP]可以和其它序列中所有的元素自由attention。( q i ∈ < C L S > , < S E P > q_i \in <CLS>, <SEP> qi∈<CLS>,<SEP>) -
自然语言和code token序列 W , C W, C W,C 中的元素之间可以自由attention。( < q i , k j > ∈ W ∪ C <q_i, k_j> \in W \cup C <qi,kj>∈W∪C)
-
如果一个变量 v i v_i vi 在token c j c_j cj 处定义,比如
int c = 10;中code tokenc和变量c对应。那么 v i v_i vi 可以和 c j c_j cj attention,反之不行。( < q i , k j > ∈ E ′ <q_i, k_j> \in E^{'} <qi,kj>∈E′) -
变量序列中的2个变量 v i , v j v_i, v_j vi,vj 只有在存在数据流关系的情况下可以进行attention( < q i , k j > ∈ E <q_i, k_j> \in E <qi,kj>∈E)。
可以通过如下代码获取Mask矩阵:
#calculate graph-guided masked function,初始化为0,设置为true表示可以自由attention
attn_mask=np.zeros((self.args.max_source_length,self.args.max_source_length),dtype=np.bool)
#calculate begin index of node and max length of input
# [CLS] W [SEP] C [SEP] 部分的position idx 从1开始,而 V [EOS] 部分的position idx全为0,因此node_idx为前半部分不包括data flow的所有结点
node_index = sum([i > 1 for i in self.examples[item].position_idx])
# 除了[CLS]之外的所有结点,包括data flow
max_length = sum([i != 1 for i in self.examples[item].position_idx])
#sequence can attend to sequence
# W, C, [SEP]部分之间的元素可以自由attention
attn_mask[:node_index, :node_index]=True
#special tokens attend to all tokens
# [CLS], [SEP], [EOS] 可以和其它token自由attention
for idx,i in enumerate(self.examples[item].source_ids):
if i in [0, 2]:
attn_mask[idx,:max_length]=True
#nodes attend to code tokens that are identified from
# vi和cj如何对应可以自由attention
for idx,(a,b) in enumerate(self.examples[item].dfg_to_code):
if a < node_index and b < node_index:
attn_mask[idx+node_index, a:b]=True
attn_mask[a:b,idx+node_index]=True
#nodes attend to adjacent nodes
for idx, nodes in enumerate(self.examples[item].dfg_to_dfg):
# a为idx的其中1个前驱结点
for a in nodes:
if a+node_index<len(self.examples[item].position_idx):
attn_mask[idx+node_index,a+node_index]=True
-
dfg_to_code的类型为List[Tuple[int, int]],长度和变量序列长度一致。为每个变量对应token在sub-token序列的开始和结束索引。 -
dfg_to_dfg的类型为List[List[int]],长度和变量序列长度一致。为每个变量对应的DFG中的前驱变量索引列表。
2.2.3.预训练任务
预训练任务使用Masked Language Modeling,Edge Prediction和Node Alignment。
2.2.3.1.Mask Language Modeling
对于序列 [ < C L S > , w 1 , . . . , < M A S K > , . . . , w n , < S E P > , c 1 , . . . , < M A S K > , . . . , c m , < S E P > , v 1 , . . . , v l , < E O S > ] [<CLS>, w_1, ..., <MASK>, ..., w_n, <SEP>, c_1, ..., <MASK>, ..., c_m, <SEP>, v_1, ..., v_l, <EOS>] [<CLS>,w1,...,<MASK>,...,wn,<SEP>,c1,...,<MASK>,...,cm,<SEP>,v1,...,vl,<EOS>],还原 < M A S K > <MASK> <MASK> 部分的token。这里不会对变量序列进行mask。
2.2.3.2.Edge Prediction
数据流边预测,目的在于让模型学习"where-the-value-comes-from"的信息,对应架构图中蓝色部分。
学习方式如下:
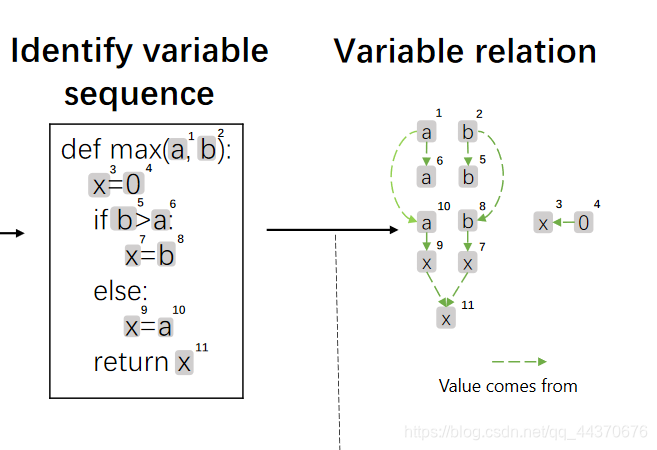 预训练时随机采样20%的node,记为集合
V
s
V_s
Vs ,mask的方式就是在mask矩阵
M
M
M (shape =
∣
X
∣
×
∣
X
∣
|X| \times |X|
∣X∣×∣X∣) 中,
V
s
V_s
Vs集合中的2个node如何有边相连, 那就把值设为
−
∞
-\infty
−∞。mask的边集合为
E
m
a
s
k
E_{mask}
Emask。
预训练时随机采样20%的node,记为集合
V
s
V_s
Vs ,mask的方式就是在mask矩阵
M
M
M (shape =
∣
X
∣
×
∣
X
∣
|X| \times |X|
∣X∣×∣X∣) 中,
V
s
V_s
Vs集合中的2个node如何有边相连, 那就把值设为
−
∞
-\infty
−∞。mask的边集合为
E
m
a
s
k
E_{mask}
Emask。
以 x 11 x^{11} x11 为例,预训练时会mask 边 ⟨ x 7 , x 11 ⟩ \langle x^{7}, x^{11} \rangle ⟨x7,x11⟩ 和 ⟨ x 9 , x 11 ⟩ \langle x^{9}, x^{11} \rangle ⟨x9,x11⟩。让模型预测这2条边。
记边集合 E c = V s × V ∪ V × V s E_c = V_s \times V \cup V \times V_s Ec=Vs×V∪V×Vs ( × \times × 为笛卡尔积) 为需要预测的边集合。
定义
δ ( e i j ∈ E ) = { 1 i f ⟨ v i , v j ⟩ ∈ E 0 o t h e r w i s e \delta(e_{ij} \in E)=\left\{ \begin{array}{rcl} 1 & & {if \langle v_i, v_j \rangle \in E} \\ 0 & & {otherwise}\\ \end{array} \right. δ(eij∈E)={10if⟨vi,vj⟩∈Eotherwise
训练loss的表达式为,引入了负采样。
l
o
s
s
E
d
g
e
P
r
e
d
=
−
∑
e
i
j
∈
E
c
[
δ
(
e
i
j
∈
E
m
a
s
k
)
.
l
o
g
(
p
e
i
j
)
+
(
1
−
δ
(
e
i
j
∈
E
m
a
s
k
)
)
.
l
o
g
(
1
−
p
e
i
j
)
]
loss_{EdgePred} = - \sum\limits_{e_{ij} \in E_c}[\delta(e_{ij} \in E_{mask}).log(p_{e_{ij}}) + (1 - \delta(e_{ij} \in E_{mask})).log(1 - p_{e_{ij}})]
lossEdgePred=−eij∈Ec∑[δ(eij∈Emask).log(peij)+(1−δ(eij∈Emask)).log(1−peij)]
p e i j p_{e_{ij}} peij 表示结点 i i i 和结点 j j j 之间存在边的概率,由GraphCodeBert模型中2个结点的向量表示内积 sigmoid所得
p e i j = s i g m o i d ( r e p r i . r e p r j ) p_{e_{ij}} = sigmoid(repr_i. repr_j) peij=sigmoid(repri.reprj)
r e p r i , r e p r j repr_i, repr_j repri,reprj 分别为GraphCodeBert关于两个变量输出的向量表示。
2.2.3.2.Node Alignment
该任务是为了学习数据流图与源代码之间的对应关系,与边预测不同的是,边预测学习的是变量序列
V
V
V 中2个结点之间的联系, 而变量分配任务学习的是源代码token序列
C
C
C 和变量序列
V
V
V 之间的联系, 也就是学习变量结点
v
i
v_i
vi 和 token
c
j
c_j
cj 的对应关系。以下图为例,
x
11
x_{11}
x11 与return x中的x对应。

与边预测相同,变量分配预测任务同样随机采样20%的node,记为集合
V
s
′
V_s^{'}
Vs′,不过这个边连接的是token和变量 ,mask的方式就是在mask矩阵
M
M
M (shape =
∣
X
∣
×
∣
X
∣
|X| \times |X|
∣X∣×∣X∣) 中,
V
s
′
V_s^{'}
Vs′集合中的2个node如何有边相连, 那就把值设为
−
∞
-\infty
−∞。mask的边集合为
E
m
a
s
k
E_{mask}
Emask。
E c = V s ′ × C E_c = V_s^{'} \times C Ec=Vs′×C ( C C C 为token序列)
训练loss的表达式为,引入了负采样。
l
o
s
s
N
o
d
e
A
l
i
g
n
=
−
∑
e
i
j
∈
E
c
′
[
δ
(
e
i
j
∈
E
m
a
s
k
′
)
.
l
o
g
(
p
e
i
j
)
+
(
1
−
δ
(
e
i
j
∈
E
m
a
s
k
′
)
)
.
l
o
g
(
1
−
p
e
i
j
)
]
loss_{NodeAlign} = - \sum\limits_{e_{ij} \in E_c^{'}}[\delta(e_{ij} \in E_{mask}^{'}).log(p_{e_{ij}}) + (1 - \delta(e_{ij} \in E_{mask}^{'})).log(1 - p_{e_{ij}})]
lossNodeAlign=−eij∈Ec′∑[δ(eij∈Emask′).log(peij)+(1−δ(eij∈Emask′)).log(1−peij)]
3.下游任务
3.1.Natural Language Code Search
给定一种自然语言作为输入,代码搜索(Code Search)的目的是从一组候选代码中找出语义上最相关的代码。
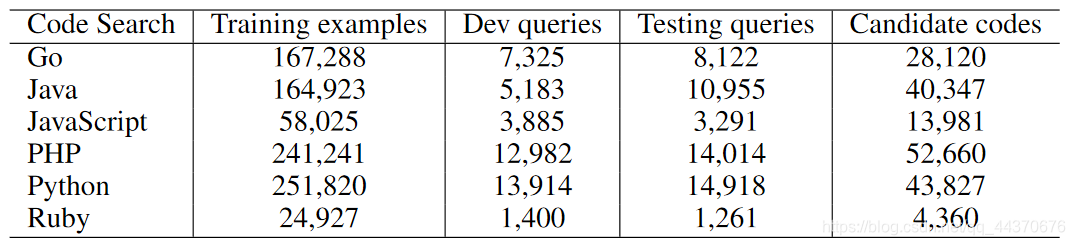
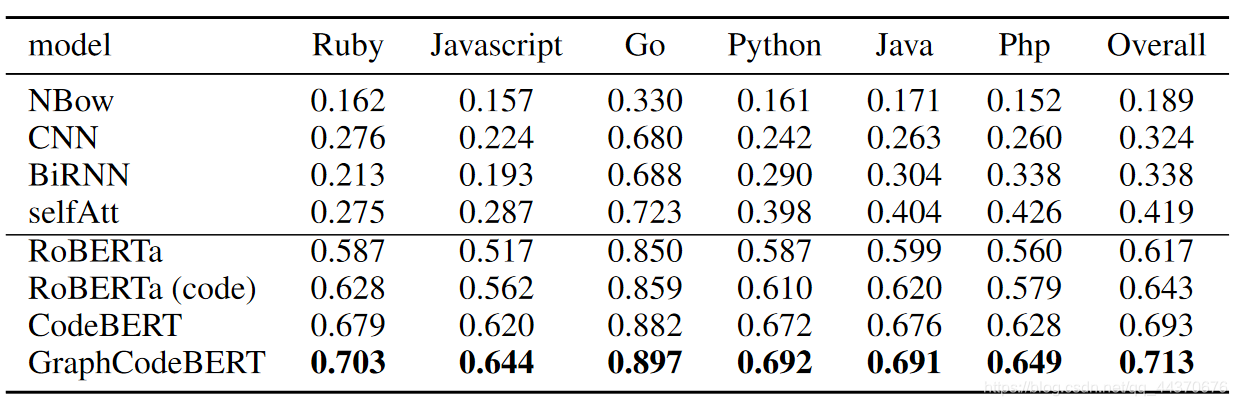
这里用到的数据集是CodeSearchNet的语料库。采用的方式是用代码文档的第一段作为query。这与code-nn类似。作者对数据集代码中无关文本(比如http://..)进行了过滤,过滤后数据集统计信息如下
对比实验结果如下,评估指标为Mean Reciprocal Rank
3.2.Code Clone Detection
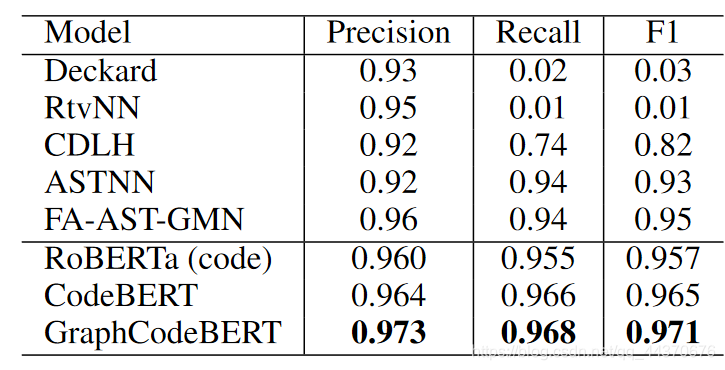
代码克隆检测的目的是度量两个代码片段之间的相似性,作者使用了BigCloneBench数据集。
该任务模型输入为2个代码片段,输出它们的相似度。
比如,如下2段java代码,相似度98.3%。
 对比实验结果如下
对比实验结果如下
3.3.Code Translation
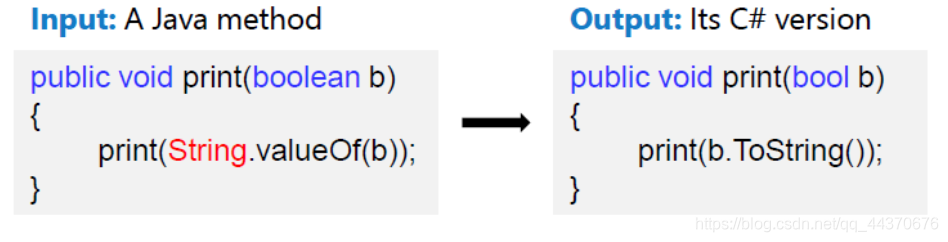
代码翻译旨在将遗留软件从平台中的一种编程语言迁移到另一种编程语言。用到的数据集是一些开源项目,包括
这些项目都有Java和C#的实现。作者基于文件名和方法名对2种编程语言进行pair,除去重复和函数体为空的方法后,method pairs的总数为11800,作者从中拆分出500对作为development set, 1000作为test set。
该任务中模型输入为Java(C#)代码,输出与之对应的C#(Java)代码。
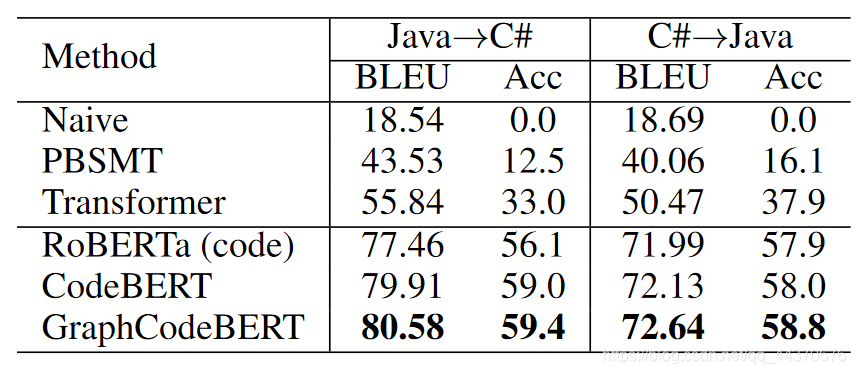
对比实验结果如下
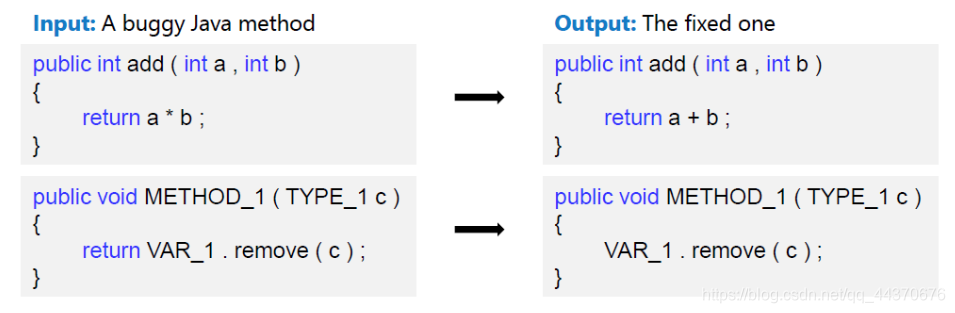
3.4.Code Refinement
代码优化旨在自动修复代码中的bug,作者用到了Java数据集。
模型输入Java代码,输出修复后的代码。
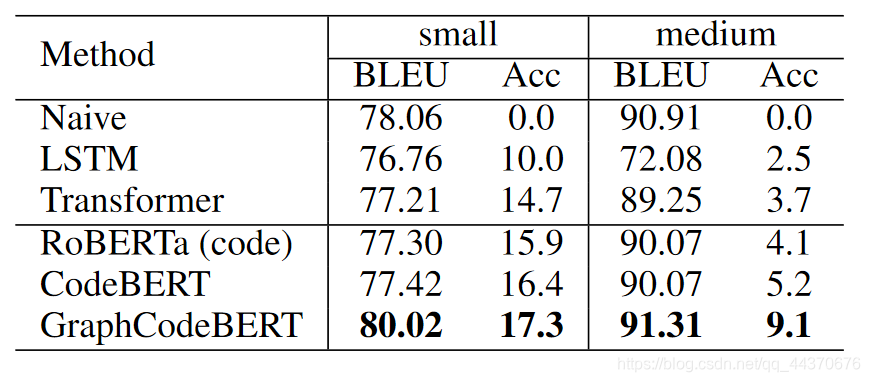
对比实验结果如下
4.总结
4.1.论文贡献
作者提出了GraphCodeBert,是CodeBert的升级版,与CodeBert相比引入了数据流结构。
CodeBert参考:CodeBERT: A Pre-Trained Model for Programming and Natural Languages
4.2.Graph-Guided Masked Attention矩阵
当然,引入数据流图不代表应用图神经网络,实际上最精髓的部分在于在transformer的Muti-head attention的公式中加入Graph-Guided Masked Attention 矩阵 M M M。
普通的head计算公式
h
e
a
d
=
s
o
f
t
m
a
x
(
Q
.
K
T
d
k
)
.
V
head = softmax(\frac{Q.K^T}{\sqrt{d_k}}).V
head=softmax(dkQ.KT).V
加入Graph-Guided Masked Attention后
h
e
a
d
=
s
o
f
t
m
a
x
(
Q
.
K
T
d
k
+
M
)
.
V
head = softmax(\frac{Q.K^T}{\sqrt{d_k}} + M).V
head=softmax(dkQ.KT+M).V
所以此时有得好好了解下 M M M 矩阵了。
整个模型的输入序列为 X = { [ C L S ] , W , [ S E P ] , C , [ S E P ] , V } X = \left\{ [CLS],W,[SEP],C,[SEP],V \right\} X={[CLS],W,[SEP],C,[SEP],V}
- W W W 为注释序列
- C C C 为代码token序列
- V V V 为变量序列(一个变量对应数据流图一个结点)
M
M
M 的维度为
∣
X
∣
×
∣
X
∣
|X| \times |X|
∣X∣×∣X∣,相当于邻接矩阵的改版, 定义如下
M
i
j
=
{
0
i
f
(
q
i
∈
[
C
L
S
]
,
[
S
E
P
]
)
o
r
(
q
i
,
k
j
∈
W
∪
C
)
o
r
(
〈
q
i
,
k
j
〉
∈
E
∪
E
′
)
−
∞
o
t
h
e
r
w
i
s
e
M_{ij}=\left\{ \begin{array}{rcl} 0 & & {if (q_i∈{[CLS],[SEP]}) or( q_i,k_j∈ W∪C) or (〈q_i,k_j〉∈ E∪E^{'}}) \\ -\infty & & {otherwise}\\ \end{array} \right.
Mij={0−∞if(qi∈[CLS],[SEP])or(qi,kj∈W∪C)or(〈qi,kj〉∈E∪E′)otherwise
大概的含义就是被mask的部分不参与softmax计算( M i j M_{ij} Mij 为0则不影响softmax,而 e − ∞ = 0 e^{-\infty} = 0 e−∞=0, 所以 M i j = − ∞ M_{ij} = -\infty Mij=−∞ 相当于softmax的时候被忽视了)
下图是草草画出的
M
M
M 矩阵。
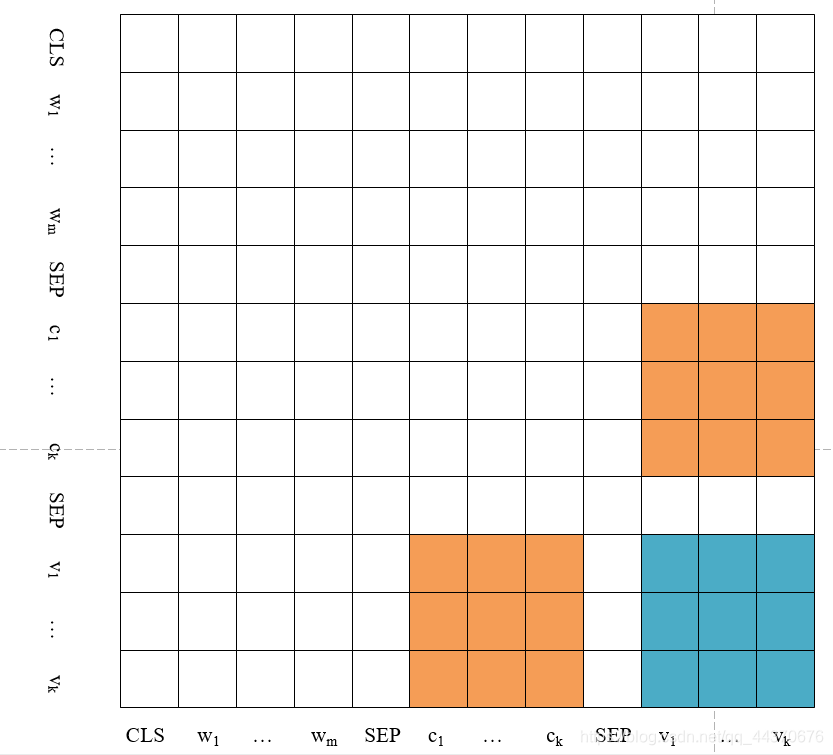 根据定义
根据定义
- 白色部分的值均为0
- 橙色部分,如果token
c
i
c_i
ci 与变量
v
j
v_j
vj 有对应关系 (比如上面例子中的
return x中的tokenx和 x 11 x^{11} x11 就是对应的,其它的token(包括其它的x)和 x 11 x^{11} x11 没有对应关系),那么 M c i v j = 0 M_{c_iv_j} = 0 Mcivj=0 , 否则为 − ∞ -\infty −∞ 。 - 青色部分,如果变量 v i v_i vi 与 v j v_j vj 有数据流关系。 那么 M v i v j = 0 M_{v_iv_j} = 0 Mvivj=0 , 否则为 − ∞ -\infty −∞ 。
4.3.相关代码
代码与codebert放在一起:CodeBert。

















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









