







支持向量机 Support vector Machine
引入:目前已经学过了线性回归、逻辑回归、神经网络等学习算法。在监督学习中,很多学习算法的性能都非常相似。因此,选择哪个算法需要考虑的是:构建这些算法时所需要的数据量。比如特征选择、正则化。但还有一个广泛应用与工业界和学术界的学习算法——支持向量机(Support vector Machine ,SVM)。相比于逻辑回归、神经网络,SVM在学习复杂非线性方程时能够提供一种更为清晰和更加强大的方式。
学习目标:学习支持向量机。
优化目标 Optimization Objective
下面从逻辑回归开始,探讨如何通过一个小小的变动来得到支持向量机。定义
z
=
θ
T
x
z= \theta^T x
z=θTx。

逻辑回归中,数据集中的每个
(
x
,
y
)
(x,y)
(x,y)都会为代价函数增加一个
−
(
y
l
o
g
(
h
θ
(
x
)
+
(
1
−
y
)
l
o
g
(
1
−
h
θ
(
x
)
)
)
-(ylog(h_\theta (x)+(1-y)log(1-h_\theta (x)))
−(ylog(hθ(x)+(1−y)log(1−hθ(x)))项,这项代表每个
(
x
,
y
)
(x,y)
(x,y)对总体代价函数的“贡献”。
下面考虑两种情况。
- 假如 y = 1 y=1 y=1,代价函数中对应的项是 − l o g ( h θ ( x ) ) = − l o g 1 1 + e − z -log(h_\theta (x))=-log {\frac 1{1+e^{-z}}} −log(hθ(x))=−log1+e−z1。 z z z越大, l o g 1 1 + e − z log {\frac 1{1+e^{-z}}} log1+e−z1越小,也就是对代价函数的影响变小。为了构建支持向量机,将 z z z等于1开始的部分设置为水平线,之前部分设置为与 l o g 1 1 + e − z log {\frac 1{1+e^{-z}}} log1+e−z1效果类似的直线,即玫红色部分直线,命名为 c o s t 1 ( z ) cost_1(z) cost1(z)。
- 假如
y
=
0
y=0
y=0,代价函数中对应的项是
−
(
1
−
y
)
l
o
g
(
1
−
h
θ
(
x
)
)
=
−
l
o
g
(
1
−
1
1
+
e
−
z
)
-(1-y)log(1-h_\theta (x))=-log (1-{\frac 1{1+e^{-z}}})
−(1−y)log(1−hθ(x))=−log(1−1+e−z1)。类似的,将开始到-1设置为水平线,之后部分设置为与
−
l
o
g
(
1
−
1
1
+
e
−
z
)
-log (1-{\frac 1{1+e^{-z}}})
−log(1−1+e−z1)效果类似的直线,即玫红色部分直线,命名为
c
o
s
t
0
(
z
)
cost_0(z)
cost0(z)。
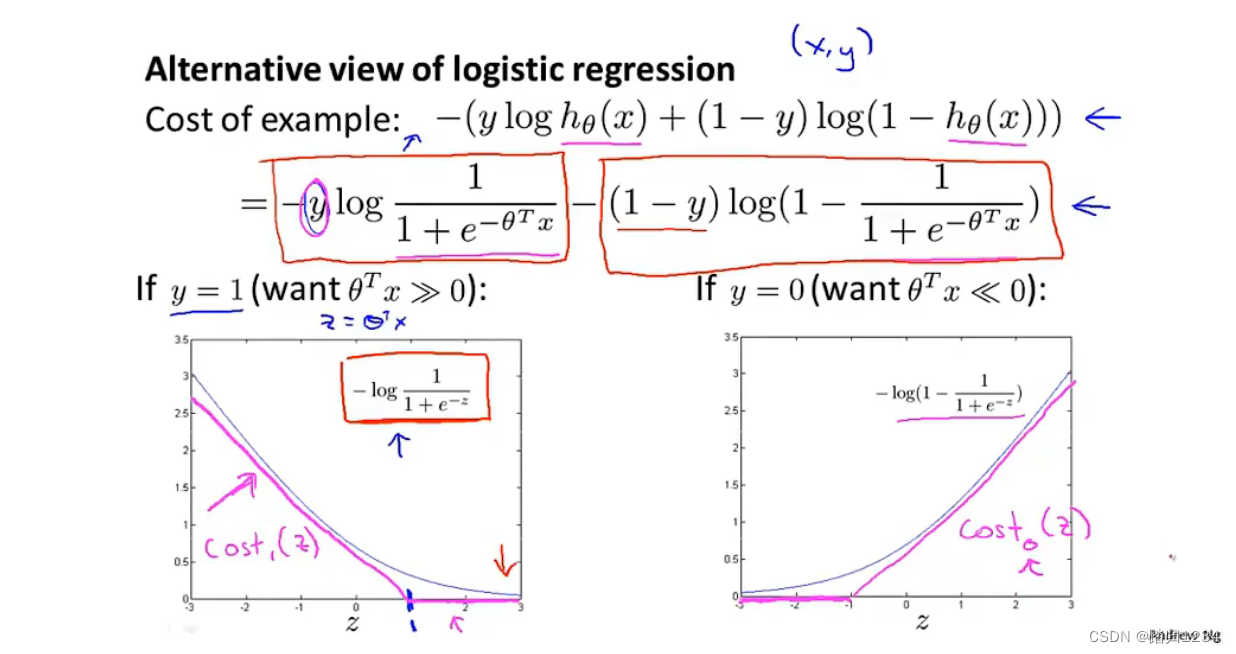
有了这些定义后,就可以开始构建支持向量机了。
在逻辑回归代价函数的基础上,将 − l o g ( h θ ( x ( i ) ) -log(h_\theta (x^{(i)}) −log(hθ(x(i))用 c o s t 1 ( θ x ( i ) ) cost_1(\theta x^{(i)}) cost1(θx(i))代替;将 − l o g ( 1 − h θ x ( i ) ) ) -log(1-h_\theta x^{(i)})) −log(1−hθx(i)))用 c o s t 0 ( θ ( x i ) ) cost_0(\theta (x^{i)}) cost0(θ(xi))代替;将 1 m \frac 1m m1去掉(无论 1 m \frac 1m m1是否去掉,对最终的 θ \theta θ值没影响)。之后,将 λ \lambda λ去掉,改为在A项(如图)前加入常数 C C C。最终得到支持向量机的代价函数

与逻辑回归不同的是,它的假设函数最终得到的不是一个概率,而是直接输入1/0。
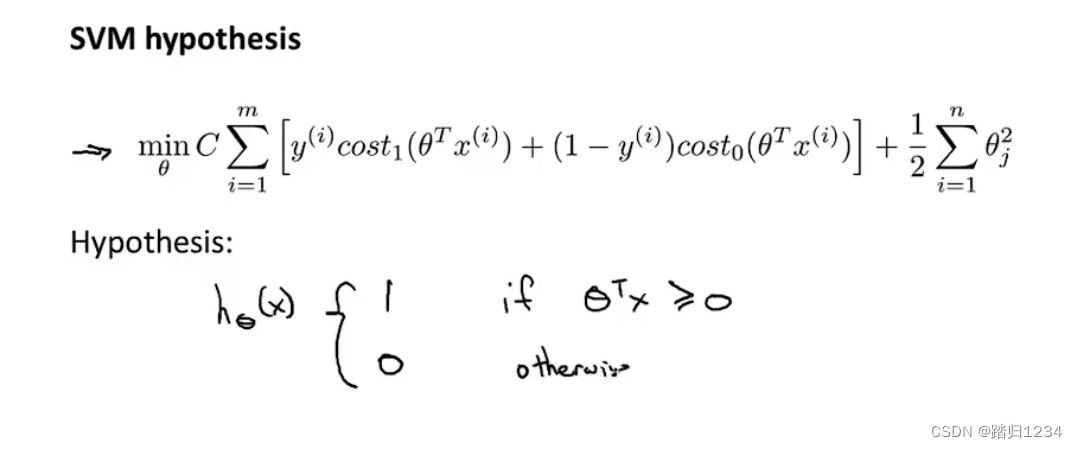
直观上对大间隔的理解 Large Margin Intuition
引入:支持向量机又称大间距分类器(large margin classifiers),这是什么意思呢?
学习目标:理解大间距分类器的含义,通过直观的图像理解SVM假设。
下图展示SVM的代价函数。假如有一个正样本(如 y=1),此时需要让
θ
T
x
\theta^T x
θTx大于等于1(对于逻辑回归,需要
θ
T
x
\theta^T x
θTx大于等于0),才能保证样本分类正确。这就相当于在SVM里面构建了一个安全因子(或者说安全距离),实际上逻辑回归也有类似的设定。
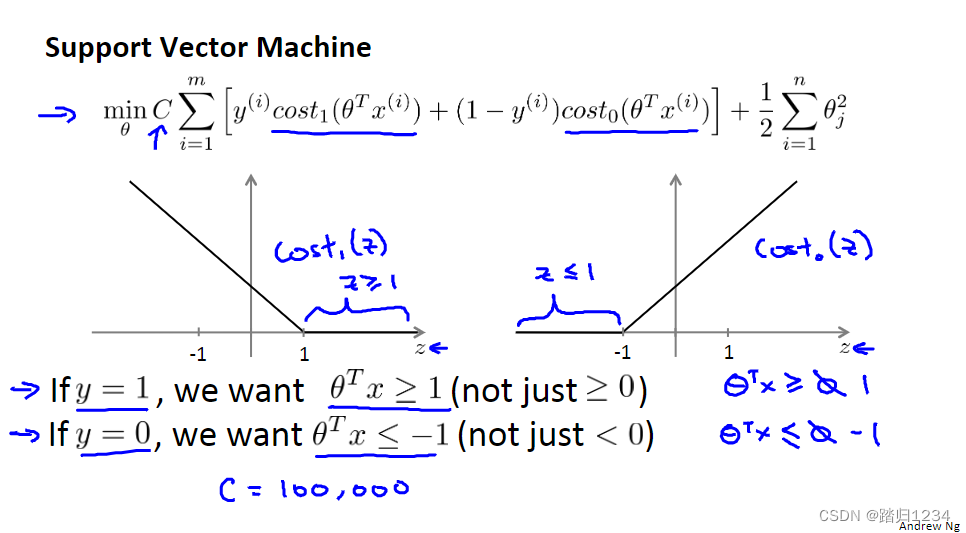
还是回归到SVM算法,这个因子会导致什么结果呢?假设设置C非常大,那么代价函数迫切需要解决的是优化
∑
i
=
1
m
[
y
(
i
)
c
o
s
t
1
(
θ
T
x
(
i
)
)
+
(
1
−
y
(
i
)
)
c
o
s
t
0
(
θ
T
x
(
i
)
)
]
\sum_{i=1}^m {[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)})cost_0(\theta^Tx^{(i)})]}
∑i=1m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))](即使其为0)。
假设把优化问题看作是通过选择参数来使得第一项等于0,那么优化问题就变成了
min
θ
C
0
+
1
2
∑
i
=
1
n
θ
j
2
\min\limits_\theta C0 +\frac 12 \sum\limits_{i=1}^n \theta_j^2
θminC0+21i=1∑nθj2
s
.
t
.
θ
T
x
(
i
)
≥
1
i
f
y
(
i
)
=
1
s.t. \quad \theta^Tx^{(i)}\ge1 \qquad if\quad y^{(i)}=1
s.t.θTx(i)≥1ify(i)=1
θ
T
x
(
i
)
≤
−
1
i
f
y
(
i
)
=
0
\quad \quad \theta^Tx^{(i)}\le-1 \qquad if \quad y^{(i)}=0
θTx(i)≤−1ify(i)=0

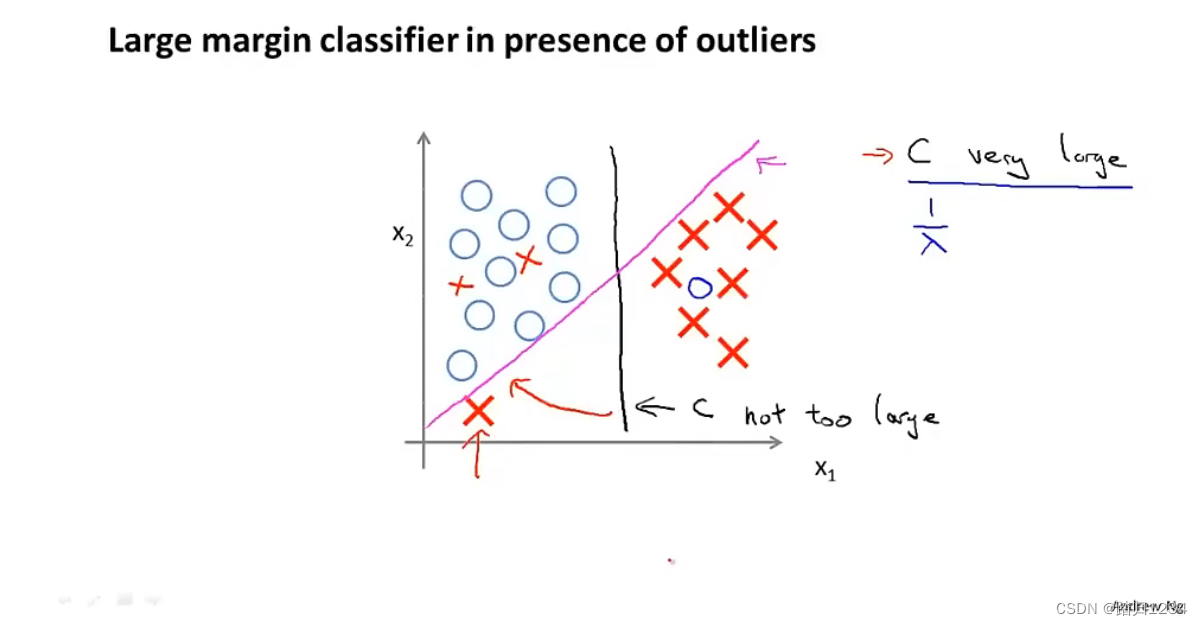
此时,会获得边界(决策边界)如下图。也就是存在很多条直线把正例、负例划分开。
存在一条划分正例、负例的直线(决策边界),它与正例、负例的距离都很远,也就是下图的黑线部分(这就是上述代价函数的优化结果)。将此时的正例负例间的距离称为支持向量机的间距,这使得支持向量机具有鲁棒性(robustness),因为它在分离数据时会尽量用大的间距去分离。这也就是为什么支持向量机有时又被称为大间距分类器(large margin classifier)。
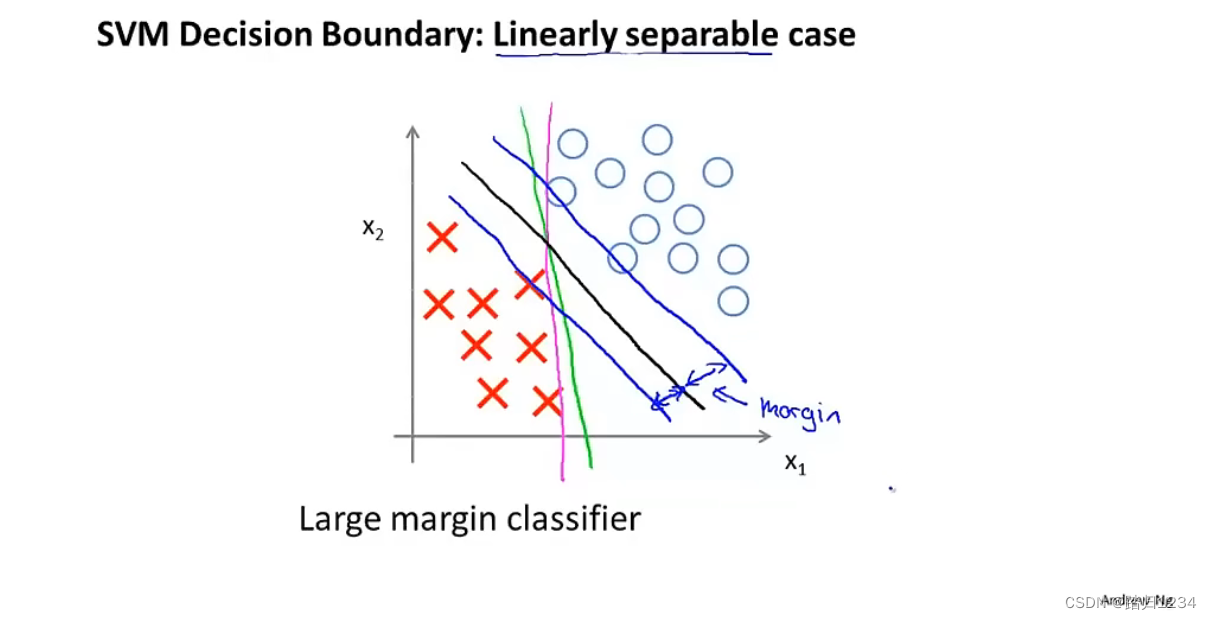
关于大间距分类器,还有一点需要注意。大间距分类器是通过把常数C设置地非常大才得到的。在实际的分类问题中,SVM要比这个大间距的视图更加复杂,尤其是只使用大间距分类器时,此时分类器对异常点会非常敏感。
也就是说,如果负例聚集处出现一个正例(如左下角),此时SVM的决策边界将从黑线变成玫红线。如果常数C比较小的话,可能最终得到的决策边界还是在黑线附近。
如果正例负例是线性不可分的,比如在原本负例聚集处出现一些正例,此时SVM还是能正确划分,只不过可能很难看到大间距的现象。这提醒我们,常数C的作用其实是与逻辑回归代价函数中的常数
1
λ
\frac 1\lambda
λ1的作用类似。
大间隔分类器的数学原理
学习目标:学习大间距分类器背后的数学原理,从而更好地理解SVM的代价函数与大间距分类器之间的联系。
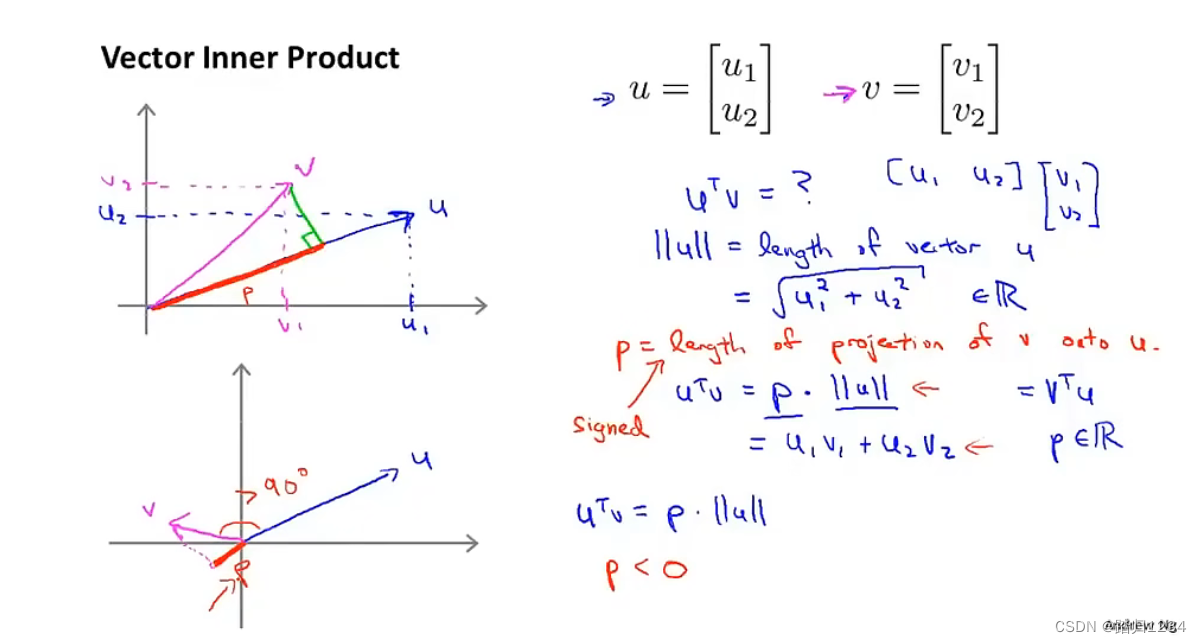
下面先复习下向量内积的性质,如图所示。
存在向量
u
、
v
u、v
u、v,
u
T
v
u^T v
uTv称为向量
u
、
v
u、v
u、v内积。
∣
∣
u
∣
∣
||u ||
∣∣u∣∣称为向量
u
u
u的范式或者长度。
p
p
p是向量
v
v
v投射到向量
u
u
u上的长(投影)。因此有
u
T
v
=
p
∣
∣
u
∣
∣
=
u
1
v
1
+
u
2
v
2
u^T v = p ||u || = u_1 v_1+u_2v_2
uTv=p∣∣u∣∣=u1v1+u2v2此外,
u
T
v
=
v
T
u
u^T v=v^T u
uTv=vTu,后者也可以用投影与范式乘积表示。
需要注意的是,
p
、
∣
∣
u
∣
∣
p、||u ||
p、∣∣u∣∣都是实数,前者有正负号。当
u
、
v
u、v
u、v之间的夹角大于90度时,
p
p
p为负数,反之同理。
注意:假设 u 、 v u、v u、v夹角为 θ \theta θ,那么 u T v = ∣ ∣ u ∣ ∣ ∗ ∣ ∣ v ∣ ∣ ∗ c o s θ = p ∣ ∣ u ∣ ∣ u^T v=||u||* ||v|| *cos\theta= p ||u || uTv=∣∣u∣∣∗∣∣v∣∣∗cosθ=p∣∣u∣∣
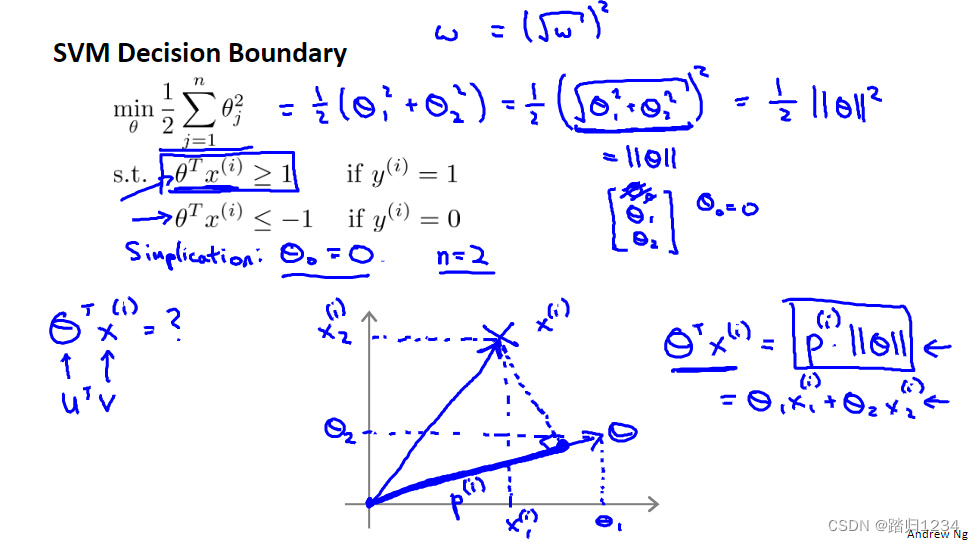
下面用向量内积的知识理解SVM优化目标函数。下图左上角部分是先前给出的SVM的优化目标函数。
为了使得目标函数便于分析,我们先忽略截距,也就是忽略
θ
0
\theta_0
θ0(设置
θ
0
=
0
\theta_0=0
θ0=0,不影响后面推导)。为了便于图示,将特征数n设置为2。再来分析优化目标函数,可得到:
min
θ
1
2
∑
i
=
1
n
θ
j
2
=
min
θ
∣
∣
θ
∣
∣
2
\min\limits_\theta\frac 12 \sum\limits_{i=1}^n \theta_j^2= \min\limits_\theta ||\theta||^2
θmin21i=1∑nθj2=θmin∣∣θ∣∣2再来考虑
θ
\theta
θ的转置乘以
x
(
i
)
x^{(i)}
x(i),并深入理解它们的作用。可以得到
θ
T
x
(
i
)
=
p
(
i
)
∣
∣
θ
∣
∣
=
θ
1
x
1
(
i
)
+
θ
2
x
2
(
i
)
\theta^Tx^{(i)}=p^{(i)}||\theta||=\theta_1 x^{(i)}_1+\theta_2 x^{(i)}_2
θTx(i)=p(i)∣∣θ∣∣=θ1x1(i)+θ2x2(i)这说明,
θ
\theta
θ的转置乘以
x
(
i
)
x^{(i)}
x(i)大于等于1或小于等于-1,相当于
p
(
i
)
∣
∣
θ
∣
∣
p^{(i)}||\theta||
p(i)∣∣θ∣∣大于等于1或小于等于-1。
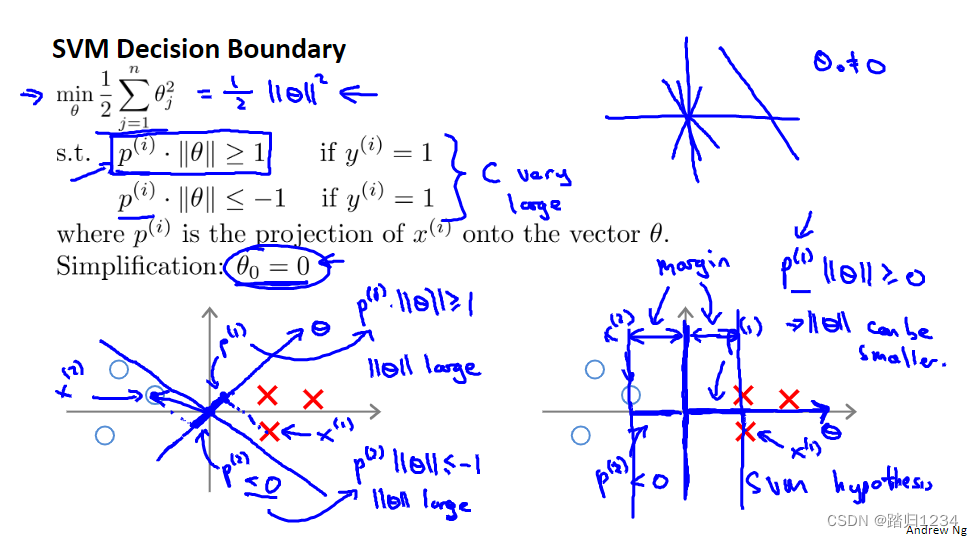
再将上述写入优化目标函数,可以得到下图左上角公式。
支持向量机是如何选择决策边界的呢?已知参数向量
θ
\theta
θ与决策边界90度正交,
θ
0
\theta_0
θ0=0意味着向量
θ
\theta
θ过原点(0,0)。对于正样本,需要
p
(
i
)
∣
∣
θ
∣
∣
p^{(i)} ||\theta||
p(i)∣∣θ∣∣大于等于1;对于负样本,需要
p
(
i
)
∣
∣
θ
∣
∣
p^{(i)} ||\theta||
p(i)∣∣θ∣∣小于等于-1。
- 如左下角图所示,绿线正负样本的 p ( i ) p^{(i)} p(i)都很小,因此需要 ∣ ∣ θ ∣ ∣ ||\theta|| ∣∣θ∣∣比较大。但是根据优化目标函数, ∣ ∣ θ ∣ ∣ ||\theta|| ∣∣θ∣∣需要足够小。因此绿线不是一个好的决策边界。
- 但是对于右下角图, p ( i ) p^{(i)} p(i)比较大,此时可以满足优化目标函数的 ∣ ∣ θ ∣ ∣ ||\theta|| ∣∣θ∣∣取足够小。
这就是为什么SVM会选择右下图的决策边界。因为优化目标函数需要
p
(
i
)
p^{(i)}
p(i)比较大(指的是绝对值),因此会找个一个大间距。其中,
θ
0
\theta_0
θ0是否取0决定着向量
θ
\theta
θ是否过原点(0,0),也就是决策边界是否过原点。这对于支持向量机大间距原理推导无影响。
核函数1 Kernels 1
学习目标:使用SVM构造复杂的非线性分类器。学习核函数Kernels 以及如何使用。
要画出下图的决策边界,可以通过构造复杂多项式如图右上部分公式。
定义新变量
f
f
f代替特征变量
x
x
x以及其组合。通过特征变量的组合可以构造新的特征变量,但问题是新构造的变量有用吗?

下面介绍一种构造新特征
f
1
、
f
2
、
f
3
f_1、f_2、f_3
f1、f2、f3的方法。
忽略特征变量
x
0
x_0
x0,即定义
x
0
=
1
x_0=1
x0=1。手动组合特征变量
x
i
x_i
xi,得到新点
l
(
i
)
l^{(i)}
l(i),称其为标记
l
(
i
)
l^{(i)}
l(i)。
给定实例
x
x
x,定义
f
i
(
i
=
1
,
2
,
3
)
f_i(i=1,2,3)
fi(i=1,2,3)为
x
、
l
(
i
)
x、l^{(i)}
x、l(i)的相似度,即
f
i
=
s
i
m
i
l
a
r
i
t
y
(
x
,
l
(
i
)
)
f_i=similarity(x,l^{(i)})
fi=similarity(x,l(i))。在这里,相似度函数属于核函数(kernel),是高斯核函数(Gaussian kernel),一般用
k
(
x
,
l
(
i
)
)
k(x,l^{(i)})
k(x,l(i))表示。

之后,再来看看这些核函数做了什么,以及为什么这些表达式是有意义的。
假如
x
x
x非常接近
l
(
i
)
l^{(i)}
l(i),那么可以得到
f
1
f_1
f1近似等于1。假如
x
x
x距离
l
(
i
)
l^{(i)}
l(i)非常远,那么可以得到
f
1
f_1
f1近似等于0。之前说过,给定
x
x
x以及标记的
l
(
1
)
、
l
(
2
)
、
l
(
3
)
l^{(1)}、l^{(2)}、l^{(3)}
l(1)、l(2)、l(3),可以得到新的特征变量
f
1
f_1
f1、
f
2
f_2
f2、
f
3
f_3
f3。

再来看看它的指数函数,来更好地理解这些函数是什么样的。并看看改变
σ
2
\sigma^2
σ2能产生多大的影响。
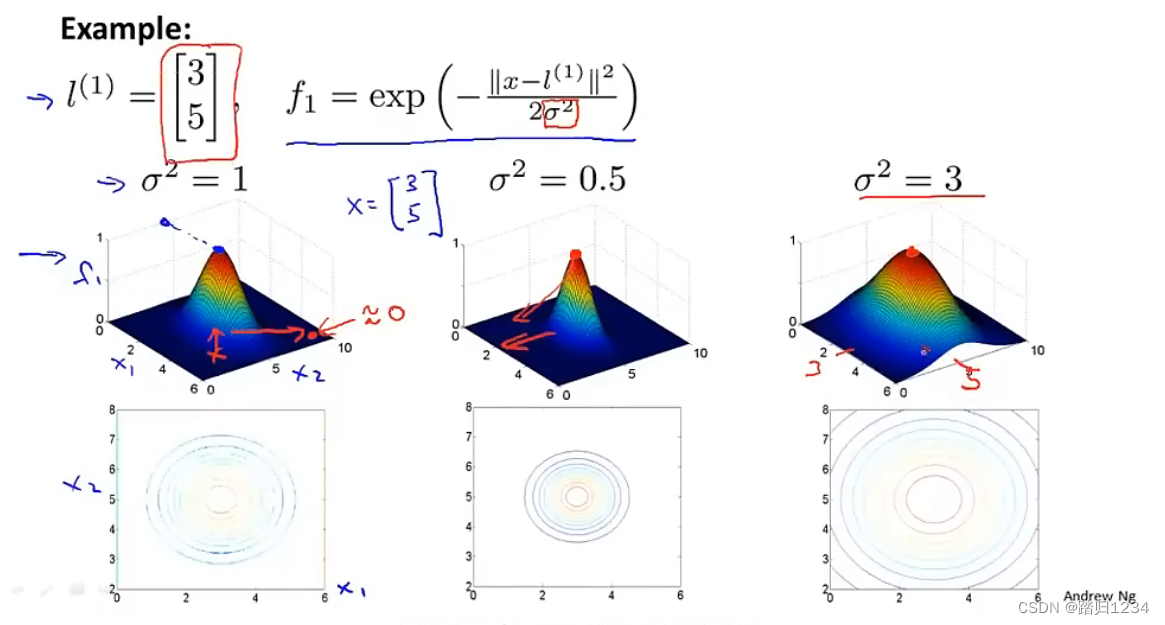
- 下图最左边部分表示 f 1 f_1 f1随 x 1 、 x 2 x_1、x_2 x1、x2变化的曲线。此时,取 σ 2 \sigma^2 σ2等于1。当 x 1 、 x 2 x_1、x_2 x1、x2分别取3、5时,即 l ( 1 ) = [ 3 5 ] l^{(1)}=\begin{bmatrix} 3 \\ 5 \end{bmatrix} l(1)=[35], f 1 f_1 f1达到局部最高值。如果 x x x往周围移动,离这个点越远, f 1 f_1 f1的值越接近0。这就是特征 f 1 f_1 f1,它衡量了 x x x到第一个标记有多近。
- 取 σ 2 \sigma^2 σ2等于0.5。可以看到,等高线图收缩了。局部最高值对应的 x x x不变。 f 1 f_1 f1从局部最高值下降到0的速度变快了。
- 取
σ
2
\sigma^2
σ2等于3。可以看到,与上者产生了相反的结果。等高线图扩展了。局部最高值对应的
x
x
x不变。
f
1
f_1
f1从局部最高值下降到0的速度变慢了。
讲完特征的定义后,再来看看,我们能得到怎么样的预测函数呢?
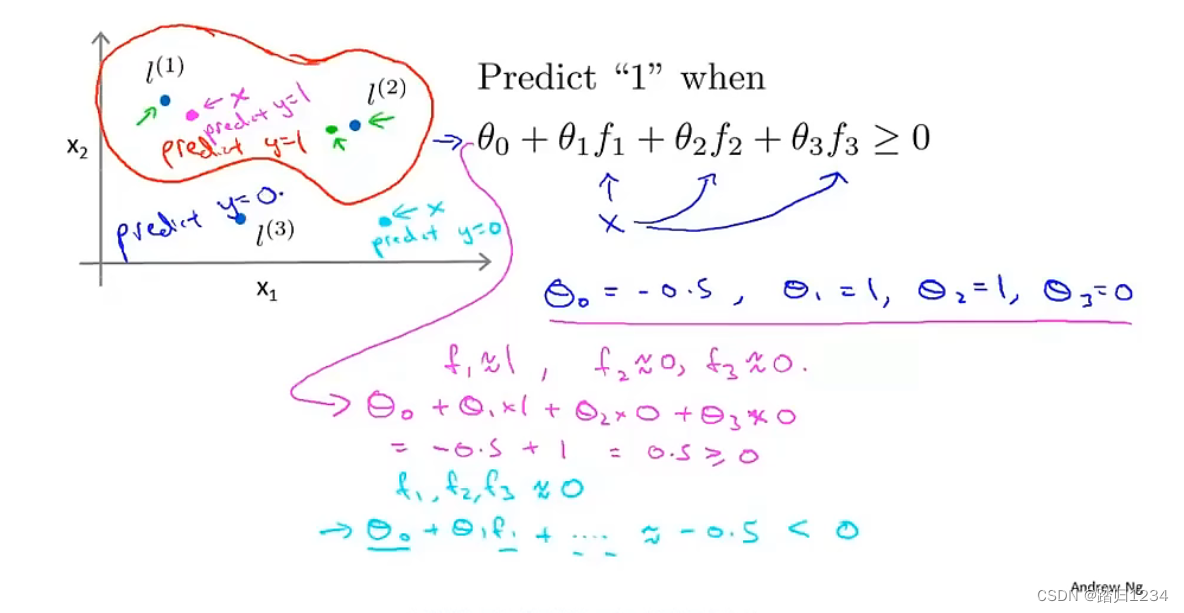
给定训练样本 x x x,我们准备计算出三个特征变量。假设已经找到了一个学习算法,也计算得到了参数 θ \theta θ的值。
如果有个训练样本处于如图洋红色点的位置,那么此时预测函数将给出怎么样的预测结果呢?因为训练实例x接近于 l ( 1 ) l_{(1)} l(1),那么有 f 1 f_1 f1接近于1;又因为训练实例x距离 l ( 2 ) 、 l ( 3 ) l_{(2)}、l_{(3)} l(2)、l(3)很远,那么有 f 2 、 f 3 f_2、f_3 f2、f3接近于0。此时假设函数接近于0.5,所以我们预测出这个点对应的 y y y值为1。
如果有个训练样本处于如图蓝绿色点的位置,那么此时预测函数将给出怎么样的预测结果呢?因为训练实例x距离 l ( 1 ) 、 l ( 2 ) 、 l ( 3 ) l_{(1)}、l_{(2)}、l_{(3)} l(1)、l(2)、l(3)很远,那么有 f 1 、 f 2 、 f 3 f_1、f_2、f_3 f1、f2、f3接近于0。此时假设函数接近于-0.5,所以我们预测出这个点对应的 y y y值为0。
总之,可以发现,我们会把接近 l ( 1 ) 、 l ( 2 ) 、 l ( 3 ) l_{(1)}、l_{(2)}、l_{(3)} l(1)、l(2)、l(3)的实例x预测为1,反之则预测为0。从而得到类似红色曲线的决策边界。这就是我们如何通过定义标记点和核函数,来训练出复杂的非线性决策边界。支持向量机的构想也正是如此。
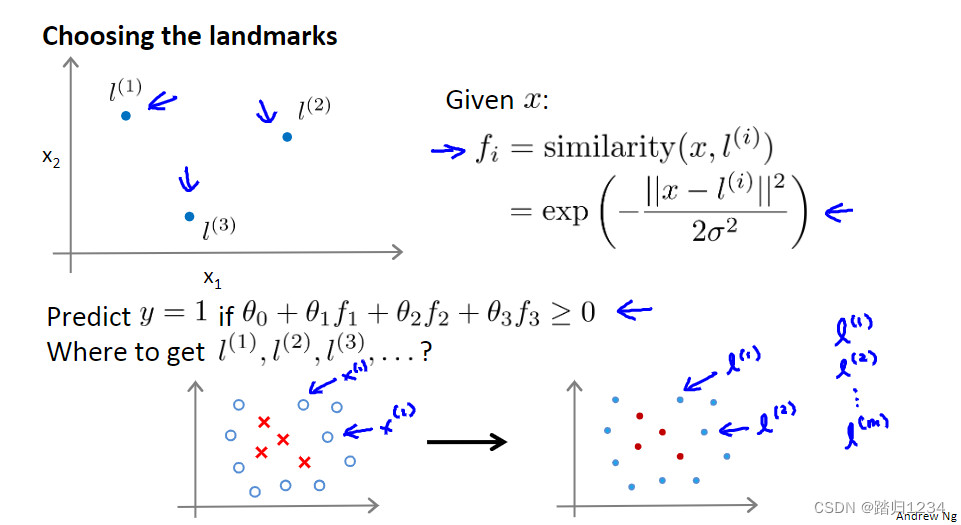
那么,如何得到并选择这些标记点、其他相似度方程又是怎样的呢?可以用其他相似度方程代替高斯核函数吗?
核函数 2 Kernels 2
学习目标:SVM思想补充,并学习如何在实际中应用这些思想(比如如何运用在SVM的偏差方差问题中)。
上节学习了选择标记点的过程,并通过标记点、相似度函数构造了预测函数。那么标记点是如何选择的呢?此外,在复杂学习问题中,标记点可能不止需要三个,此时该如何处理呢?
给定包含正例负例的数据集,我们将选取样本点。并且对于所拥有的每个样本点,只需要直接使用它们,也就是直接把训练样本当做标记点,最终获得m个标记点。这种选取方法挺不错的,因为这说明特征函数基本上是在描述每一个样本距离样本集中其他样本的距离。
下面列出这个过程的大纲,如下图。
给定样本
x
x
x(
x
x
x可为训练样本或交叉验证样本或测试样本),构造新特征变量
f
f
f。
如果我们拥有训练样本
(
x
(
i
)
,
y
(
i
)
)
(x^{(i)},y^{(i)})
(x(i),y(i)),我们对这个训练样本的计算特征即:给定
x
(
i
)
x^{(i)}
x(i),我们将其映射到
f
1
(
i
)
、
f
2
(
i
)
、
…
、
f
m
(
i
)
f_1^{(i)}、f_2^{(i)}、…、f_m^{(i)}
f1(i)、f2(i)、…、fm(i)。

那么给定标记点和相似度函数,如何使用简单的支持向量机呢?
给定训练样本
x
x
x,构造新特征
f
f
f(m+1维,即训练样本量)。如果要
y
=
1
y=1
y=1,只需
θ
T
f
>
0
\theta^Tf >0
θTf>0。与之前类似,我们通过最小化代价函数获得
θ
\theta
θ。只不过我们现在把
x
(
i
)
x^{(i)}
x(i)改为了
f
(
i
)
f^{(i)}
f(i)。
需要注意的是,
- θ \theta θ是m维的,因此正则化项有 n = m n=m n=m(还是不正则化 θ 0 \theta_0 θ0)。
- 大部分支持向量机求 ∑ j = 1 m θ j 2 \sum_{j=1}^m \theta^2_j ∑j=1mθj2,其实不是通过 θ T θ \theta^T\theta θTθ计算 θ 2 \theta^2 θ2,而是用 θ T M θ \theta^T M \theta θTMθ(M是一个矩阵,它取决于采用的核函数)。这是SVM的一个计算技巧,它使得SVM能够更有效率的运行,让其可以应用更大的训练集。
- 实际上,可以将类似于标记点的技术应用于逻辑回归算法,但支持向量机的计算技巧不能较好地推广到逻辑回归等其他算法中。因此,将核函数应用于逻辑回归将使其计算变得非常缓慢。
- 此外,SVM的具体代码实现其实不必通过自身写代码,而是建议使用已经写好的成熟的包。

还有一个需要注意的问题是:
- 如何选择支持向量机中的参数 C C C呢?它其实与 1 λ \frac 1\lambda λ1的作用类似。选择方法可参照 λ \lambda λ
- 如何选择高斯核函数中的
σ
2
\sigma^2
σ2呢?
σ
2
\sigma^2
σ2大,高斯核函数倾向于变得相对平滑且变化缓慢,这将带来较高的偏差和较低的方差;
σ
2
\sigma^2
σ2小,高斯核函数倾向于变得相对陡峭且变化迅速,这将带来较低的偏差和较高的方差

使用SVM
学习目标:讨论使用SVM时,实际需要的东西。
实际使用SVM时,推荐使用liblinear、libsvm两个包获取参数 θ \theta θ,而非自己写代码。我们需要做的事是:选择参数 C C C、相似函数、内核参数 σ 2 \sigma^2 σ2。
- 一个选择是不需要使用任何内核参数,即不构造新的特征变量 f f f。这种理念被称为线性核函数 linear kernel(对应线性核SVM)。线性核SVM可以看作SVM的一个版本,它只是给了一个标准的线性分类器,可以成为解决一些问题的合理选择。比如,特征量n很大、训练数据量m很小,需求是拟合一个线性的判定边界(数据量不足以支持复杂的判定边界)。
- 另一种选择是构建高斯核函数(Gaussian kernel),此时还需要合理选择参数 σ 2 \sigma^2 σ2**。什么时候使高斯核函数呢?如果忽略特征值x属于 R n R^n Rn,并且 n n n值很小、 m m m值很大,需求是获得一个相对复杂的非线性决策边界(因为此时数据量m足以支持相对复杂的非线性决策边界)。

具体来说,选择高斯核函数还需要做做的是:实现相似度函数或核函数,从而得到新特征变量 f f f。也有可能,有些软件包含了高斯核函数、线性核函数。
注意:如果特征变量量纲差异很大,此时需要将这些特征变量的大小按比例归一化。

无论是高斯核函数、线性核函数,还是其他核函数,这些核函数的使用都需要满足默赛尔定理(Mercer‘s Theorem)。需要满足这个定理的原因是:支持向量机算法或支持向量机实现函数有许多熟练的数值优化技巧(为了高效的求解参数
θ
\theta
θ),初始的SVM设定将我们的注意力仅仅限制在可以满足默赛尔定理的核函数上。
除了高斯核函数、线性核函数(最常用),还存在其他核函数(特少用)
- 多项式核函数(Polynomial kernel)。 k ( x , l ) = ( x T l + c o n s t a n t ) d e g r e e ,参数包括 c o n s t a n t 、 d e g r e e k(x,l) = (x^T l + constant)^{degree},参数包括constant、degree k(x,l)=(xTl+constant)degree,参数包括constant、degree。表现不如高斯核函数、使用较少。通常在 l 、 x l、x l、x都是严格的非负数时使用,因为此时才能保证内积非负。
- 字符串核函数(String kernel)。输入数据是本文字符串或其他类型字符串时使用。
- 直方相交核函数(chi_square kernel )等等

对于多分类问题,支持向量机如何选择恰当的判定边界呢?很多SVM软件内置了多分类函数,此外可以使用一对多方法(one-vs.-all method,参照逻辑回归的一对多)。

我们从逻辑回归构造了SVM,那么如何选择用逻辑回归函数还是支持向量机函数呢?
| 条件 | 推荐学习算法 | 原因 |
|---|---|---|
| n ≫ m n\gg m n≫m | 逻辑回归或线性核函数 | 特征变量个数远大于训练样本数,线性回归效果已经足够。并且训练数据量不足支持使用复杂的非线性函数 |
| n比较小,m适中 | 使用高斯核SVM(高斯核函数) | |
| m ≫ n m\gg n m≫n | 添加更多的新特征变量,然后使用逻辑回归函数或者线性核SVM | 训练集样本数非常大时,高斯核函数运行速度很慢 |
注意:
- 线性核SVM和逻辑回归算法其实非常相似,对于实例的运行效果很多情况下也都类似。
- 神经网络对于这些情况的训练效果都会挺不错,但是可能会运行更慢。SVM的优化问题是凸优化问题,因此优秀的SVM包总会找到全局最小值。但神经网络只能找到局部最小值

面对一个新机器学习问题,我们最需要考虑的其实不是该用那个学习算法。而是你拥有多少数据、你有多擅长做误差分析(error analysis)和排查学习(debugging learning)、如何设定新的特征变量、弄明白特征变量的输入等等。
总之,SVM是非常强大的学习算法之一,包含一个有效的方法去学习复杂的非线性函数。因此使用SVM、logistic 回归、神经网络来提高学习算法的应用非常广泛。














 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









