







模型评估与选择
P问题和NP问题
p问题:deterministic polynomial time question,多项式时间问题,能在多项式时间内解决的问题
NP问题:No-deterministic polynomial time question , 非确定多项式时间问题,不确定是否能在多项式时间内解决的问题,
NP-hardness问题:任意np问题都可以在多项式时间内规约为一类问题,规约的意思是为了解决了问题A ,先将问题规约为B问题,解决了问题B也间接解决了问题A。
NP-Complete问题:问题A为Np-hardness问题,也是NP问题,则问题A是NP-complete问题。即:只要解决这个问题,那么所有的np问题都解决了。
经验误差与过拟合
错误率(error rate)、精度(accuracy)、
误差(error):学习器的实际预测输出与样本的真实输出之间的差异。学习器在训练集上的误差成为“训练误差(training error)”、或者“经验误差(empirical error)”,在新样本上的误差称为“泛化误差(generalization error)”。
过拟合(overfitting 无法避免)和欠拟合(underfitting)
评估方法
调参与最终模型。
- 调参(parameter tuning) ,对算法参数进行设定。模型评估和选择后(学习算法和参数配置确定),需再用数据集D重新训练,这才是最终提交的模型。(之前模型选择评估仅仅使用数据集D的部分数据)
- 训练集,用于模型训练。测试集,把学得模型用于评估测试的数据集。模型评估与选择中用于评估测试的数据集常称为“验证集(validation set)”。例如,在研究对比不同算法的泛化能力时,用测试集上的判别效果来个估计模型在实际使用时的泛化能力。此时,把测试集划分为训练集和测试集,基于验证集上的性能来进行模型选择和调参。
下面展示常用性能度量
均方误差 mean square error (最常用之一)
-公式

- 适用范围:一般用于回归任务
错误率与精度(最常用之一)
- 定义:分类错误样本数占样本总数比例;分类正确数样本数占样本总数比例
- 公式

- 适用范围:二分类任务、多分类任务
查准率、查全率、F1分数
- 定义:
查准率(准确率,precision):预测结果为正例中,确实为正的比例;
查全率(召唤率,recall):真实为正例的,有多少被预测出来了。 - 公式
混淆矩阵
| 真实情况 | 预测结果 正例 | 预测结果 负例 |
|---|---|---|
| 正例 | TP(真正例) | FN(假反例) |
| 负例 | FP(假正例) | TN(正反例) |
则有:
P
=
T
P
/
(
T
P
+
F
P
)
R
=
T
P
/
(
T
P
+
F
N
)
P=TP/(TP+FP) \\ R=TP/(TP+FN)
P=TP/(TP+FP)R=TP/(TP+FN) 一般来说,P高,R低;反过来也是如此
根据学习器的预测结果,对样例进行排序。排在前面的为学习器认为“最可能”是正例的样本,后面……“最不可能”……。按此顺序逐个将样本作为正例进行预测,每次计算R、P,得到下图(P-R图、PR图;线 R-P曲线、PR曲线)。(注:实际情况为非单调、不平滑)
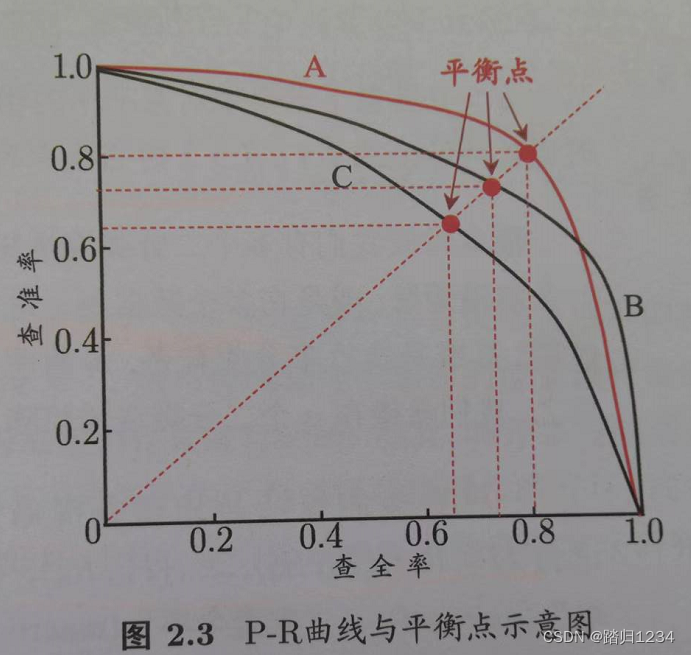
为了评比出分类器好坏,有BEP与F1,F1更常用
- 平衡点(Break-Even Point,BEP),P=R时取得。取大者
- F1分数

注意: 调和平均值,相对于算术平均值 P + R 2 \frac {P+R}2 2P+R、几何平均值 R ∗ P \sqrt{ R∗P} R∗P,更重视较小值。
- 扩充:
多次训练/测试(或在多个数据集上训练/测试,或者执行多分类任务),得到多个混淆矩阵。此时需要在n个二次混淆矩阵上综合考察查准率和查全率。此时需要用到以下性能度量:宏查准率、宏查全率、宏F1;微查准率、微查全率、微F1
1、宏查准率、宏查全率、宏F1:先分别计算各个混淆矩阵的P、R、F1,再计算平均值。
如宏F1: m a c r o − F 1 = ( 2 ∗ m a c r o − P ∗ m a c r o − R ) ( m a c r o − P + m a c r o − R ) macro-F1=\frac{(2*macro−P∗macro−R)}{(macro−P+macro−R)} macro−F1=(macro−P+macro−R)(2∗macro−P∗macro−R)
2、微查准率、微查全率、微F1:将各混淆矩阵的对应元素进行平均,得到TP等的平均值( T P ‾ \overline{TP} TP) 等,再基于平均值计算查全率等。
如微F1: m i c r o − F 1 = ( 2 ∗ m i c r o − P ∗ m i c r o − R ) ( m i c r o − P + m i c r o − R ) micro-F1=\frac{(2*micro−P∗micro−R)}{(micro−P+micro−R)} micro−F1=(micro−P+micro−R)(2∗micro−P∗micro−R) - 适用范围:二分类任务
ROC曲线、AUC
- 作用:为了衡量学习器在不同任务下的“期望泛化性能”好坏
- 公式
类似于R-P曲线,只不过横纵坐标改为假正例率(FPR)、真正例率(TPR)。 F P R = F P / ( T N + F P ) T P R = T P / ( T P + F N ) FPR=FP/(TN+FP) \\TPR=TP/(TP+FN) FPR=FP/(TN+FP)TPR=TP/(TP+FN)
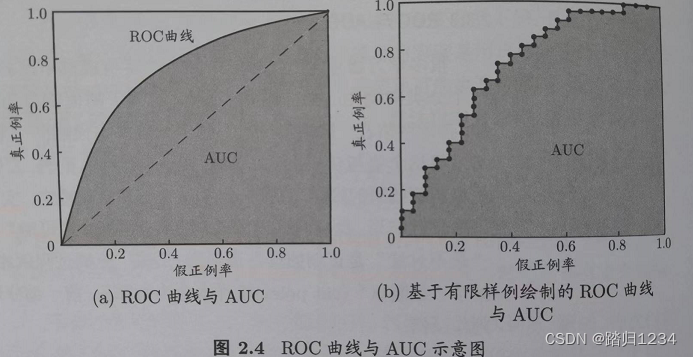
为了判断出分类器的好坏,得到AUC(Area Under ROC Curve),即比较ROC曲线下面的面积。
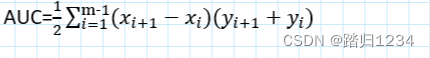
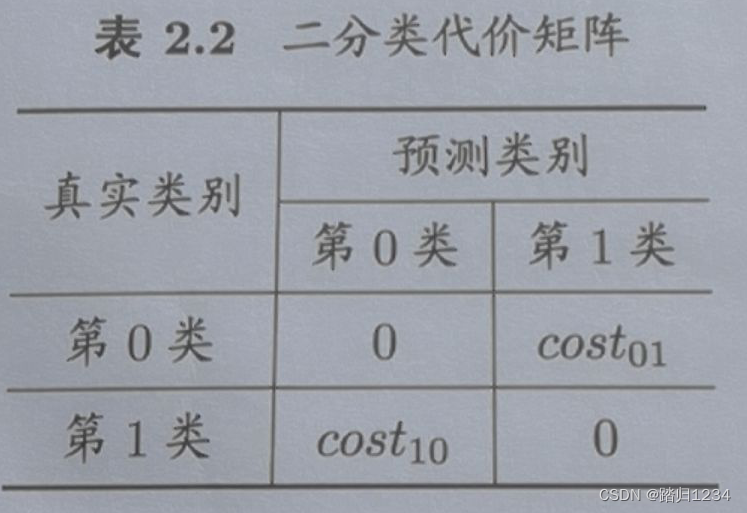
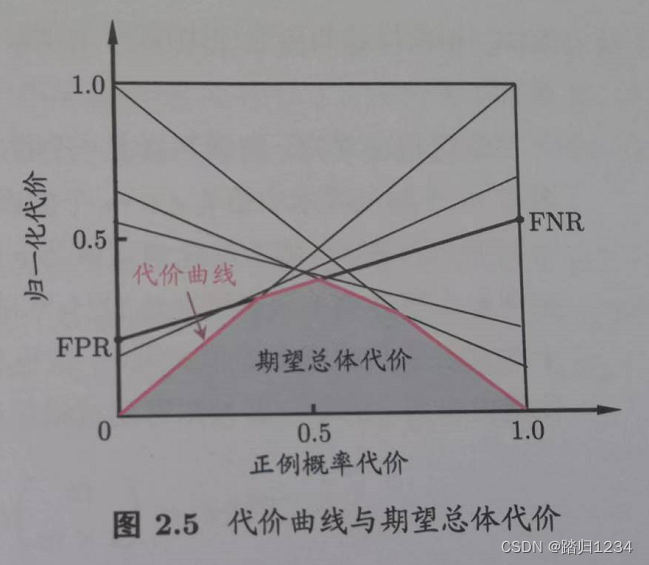
代价敏感错误率、代价曲线
- 作用:为了衡量不同类型错误造成的不同损失,为错误赋予非均等代价(unequal cost)
- 公式
以二分任务为例,设置二分代价矩阵。(重点在于代价比值)
c o s t i j cost_{ij } costij指的是将第 i i i类预测为第 j j j类的代价
令第0类为正类、第1类为反类, D + 、 D − D^{+ }、D^{- } D+、D−分别为正反例子值。
则**代价敏感的错误率(cost-sensitive)**为: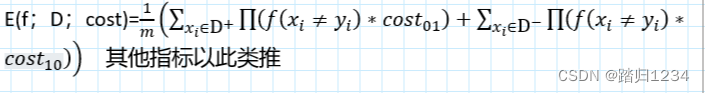
注意















 2297
2297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









