







一:jieba分词和pkuseg分词
原代码文件
链接:https://pan.baidu.com/s/1J8kmTFk8lec5ubfwBaSnLg
提取码:e4nv
目录:

1:分词介绍:
目标:中文句子中的词与词之间加上边界标记,本质是划分词的边界。
英文天然有空格作为分词符合。而对于中文如何让机器智能识别出单词词汇,是文本分析的第一步。
基本分词思想:(1) 由句子到词.(2) 由字到词
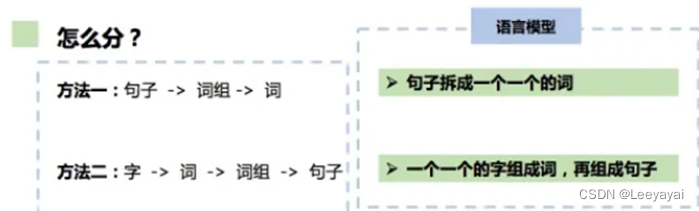
具体分词方法:


举例:
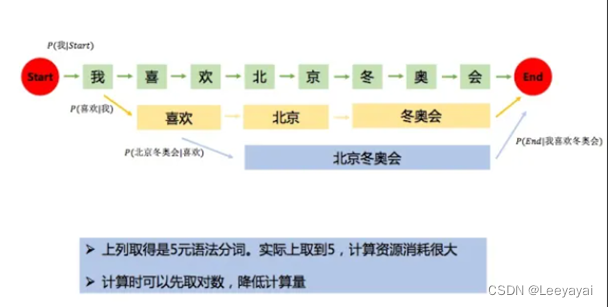
如何分词使得这个句子的共现概率最大
2:jieba中文分词
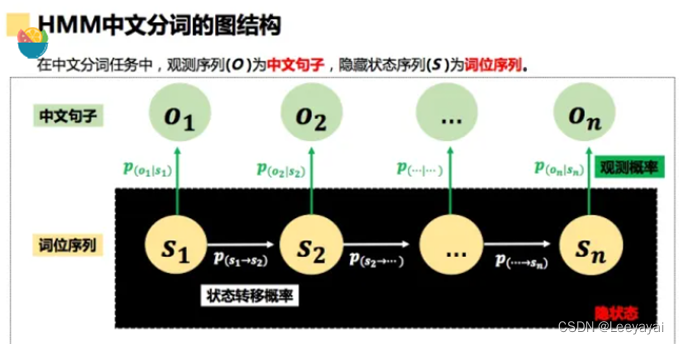
分词原理:HMM(隐马尔可夫模型)
(如何设置分词符号,使得句子的共线概率最大)
3:实践:分词
import jieba
import pkuseg
text = "绿子在电话的另一头久久默然不语,如同全世界的细雨落在全世界所有的草坪上一般的沉默在持续。"
seg_list = jieba.cut(text, cut_all=False, HMM=True)
print("jieba Cut result is: " + " ".join(seg_list))
seg = pkuseg.pkuseg() # 以默认配置加载模型
text = seg.cut(text) # 进行分词
print("pkuseg Cut result is: " + "/".join(text))
jieba Cut result is: 绿子 在 电话 的 另一头 久久 默然不语 , 如同 全世界 的 细雨 落 在 全世界 所有 的 草坪 上 一般 的 沉默 在 持续 。
pkuseg Cut result is: 绿子/在/电话/的/另/一头/久久/默然不语/,/如同/全世界/的/细雨/落/在/全世界/所有/的/草坪/上/一般/的/沉默/在/持续/。
二:去除停用词
1:实践:去除停用词
在使用使用jieba或pkuseg分词后,每一个句子被划分为一个个词。但是有些词是没有意义的(无法体现该段文本的
特征),如“在”,“的”,“一些”,标点符号等。因此我们需要去除这些词。这一步骤称为“去除停用词”。
如下是本次实验使用的停用词文件
#获取停用词集合
def get_stopwords():
stopwords = pd.read_csv ("F:\\研一课程\\周水生机器学习中的优化\\LSTM谣言检测\\rummordetection_lstm-main\\rummordetection_lstm-main\\stopwords\\stopwords.txt", index_col=False, sep="\t", quoting=3, names=['stopword'],
encoding='utf-8')
return set(stopwords['stopword'].values.tolist())
def cutsentences(sentences): #定义函数实现分词
print('原句子为:'+ sentences)
cutsentence = jieba.lcut(sentences.strip()) #精确模式
print ('\n'+'分词后:'+ "/ ".join(cutsentence))
stopwords = get_stopwords() # 这里加载停用词的路径
lastsentences = ''
for word in cutsentence: #for循环遍历分词后的每个词语
if word not in stopwords: #判断分词后的词语是否在停用词表内
if word != '\t':
lastsentences += word
lastsentences += "/ "
print('\n'+'去除停用词后:'+ lastsentences)
sentence = '绿子在电话的另一头久久默然不语,如同全世界的细雨落在全世界所有的草坪上一般的沉默在持续。'
cutsentences(sentence)
原句子为:绿子在电话的另一头久久默然不语,如同全世界的细雨落在全世界所有的草坪上一般的沉默在持续。
分词后:绿子/ 在/ 电话/ 的/ 另一头/ 久久/ 默然不语/ ,/ 如同/ 全世界/ 的/ 细雨/ 落/ 在/ 全世界/ 所有/ 的/ 草坪/ 上/ 一般/ 的/ 沉默/ 在/ 持续/ 。
去除停用词后:绿子/ 电话/ 另一头/ 久久/ 默然不语/ 全世界/ 细雨/ 落/ 全世界/ 草坪/ 沉默/ 持续/
附:查看停用词文件
stopwords = get_stopwords() # 这里加载停用词的路径
print(type(stopwords))
stopwords_=list(stopwords) #set是集合,无序,查看元素只能遍历所有打印出来,转为list.
print(stopwords_[1:20])
<class 'set'>
['个别', '.', '—', '乘势', '互相', '以前', '为什么', 'somewhere', 'keep', '一', '■', '对待', "i'll", '此次', '作为', '据此', '}>', '对比', '成年']
print(stopwords)
{nan, '个别', '.', '—', '乘势', '互相', '以前', '为什么', 'somewhere', 'keep', '一', '■', '对待', "i'll", '此次', '作为', '据此', '}>', '对比', '成年', '殆', 'thanks', '_', '傥然', '10', 'his', '-', '照着', '这些', '具体来说', '-[*]-', '|', '知道', '立刻', '恍然', 'usually', '借此', 'more', '不过', '这麽', '岂止', '=[', 'possible', 'off', 'probably', 'took', '一转眼', 'value', '致', '咱们', 'b]', '(', '!', '人', '除却', '允许', '100', '哼唷', '切勿', '咋', '见', '4', '89', '当前', '这么样', '左右', '庶乎', '接著', '第二大节', '结果', 'now', 'neither', '第五大道', '共同', '看起来', '⑧', 'says', '不拘', 'specify', '紧接着', '光', '我的', '冲', 'nor', 'on', '三番五次', '起见', '关于', '第二类', 'cannot', 'nine', '莫如', 'seemed', '奈', 'outside', '而又', '不会', '如若', '自从', '由于', '2016', 'twice', '有效', '91', '或许', 'hereafter', '93', '相等', '意思', '第五集', '53', '打', '争取', '当中', 'that', '」', '仅仅', '之前', "it'd", 'say', '@', 'seeming', '更有趣', '05', '取得', '除此以外', '吓', 'e]', '不一', 'once', '虽则', '向使', '来看', '敢情', '9', 'there', '其', '上午', '行动', 'seven', "you've", 'used', '下面', '大事', 'seeing', '很', '49', '暗地里', '从此以后', '也好', '尽管', 'indicated', '且说', '长此下去', '有一期', 'toward', '不曾', 'said', '70', '到处', 'per', '存心', '那末', '人人', '元/吨', 'indicates', '与其说', '勃然', '第二讲', '从此', 'believe', '吱', "there's", '当下', '赶早不赶晚', '平素', 'thereafter', '过来', 'go', '不问', '.一', '是否', 'our', '来不及', '秒', 'relatively', '哪边', '又笑', 'like', '要', 'far', 'seems', '往', '相当', '随后', '倒是', '反之亦然', '72', '倘', '看', '具有', 'follows', '一边', 'anybody', '如今', '第四者', '54', 'us', '②c', '第二盘', '可以', 'ones', '那么些', '适当', '怪', '有及', '一番', '奋勇', 'only', '是的', '来讲', '65', '新华社', '嗡嗡', '某', '别处', '≈', 'these', '极其', '处在', '和', '啪达', 'consequently', '仍然', '啊哟', '犹且', '极大', '绝顶', '第三件', '高兴', '遵照', 'into', '到头来', 'considering', '宁可', '简直', '长话短说', 'them', '正是', '我们', '上', '不但', '设使', '那时', '不限', '每每', '叫做', '如其', '几度', '自打', '总是', '不大', '之所以', '乌乎', '怎奈', '越是', 'specified', '大概', 'regards', 'four', 'becoming', '漫说', '不胜', '贼死', '尽如人意', '“', '别说', './', 'zt', '遵循', '以期', '大体', ';', '上去--', 'alone', '弗', 'towards', '。', '~+', '不惟', 'soon', '不下', '对', '〕〔', '谁知', 'co', '如是', '自后', '继后', '敢于', '非得', '第十六', 'below', '如常', '里面', '0', '便', '后面', ' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3686
3686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









