以下是基于Tensorflow的《Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor》版本的SAC强化学习算法的Python代码:
```python
import tensorflow as tf
import numpy as np
import gym
# Create actor network
class Actor(tf.keras.Model):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.layer1 = tf.keras.layers.Dense(256, activation='relu')
self.layer2 = tf.keras.layers.Dense(256, activation='relu')
self.mu_layer = tf.keras.layers.Dense(action_dim, activation='tanh')
self.sigma_layer = tf.keras.layers.Dense(action_dim, activation='softplus')
self.max_action = max_action
def call(self, state):
x = self.layer1(state)
x = self.layer2(x)
mu = self.mu_layer(x) * self.max_action
sigma = self.sigma_layer(x) + 1e-4
return mu, sigma
# Create two critic networks
class Critic(tf.keras.Model):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.layer1 = tf.keras.layers.Dense(256, activation='relu')
self.layer2 = tf.keras.layers.Dense(256, activation='relu')
self.layer3 = tf.keras.layers.Dense(1, activation=None)
def call(self, state, action):
x = tf.concat([state, action], axis=1)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
# Create Soft Actor-Critic (SAC) Agent
class SACAgent:
def __init__(self, state_dim, action_dim, max_action):
self.actor = Actor(state_dim, action_dim, max_action)
self.critic1 = Critic(state_dim, action_dim)
self.critic2 = Critic(state_dim, action_dim)
self.target_critic1 = Critic(state_dim, action_dim)
self.target_critic2 = Critic(state_dim, action_dim)
self.max_action = max_action
self.alpha = tf.Variable(0.1, dtype=tf.float32, name='alpha')
self.gamma = 0.99
self.tau = 0.005
self.optimizer_actor = tf.keras.optimizers.Adam(learning_rate=3e-4)
self.optimizer_critic1 = tf.keras.optimizers.Adam(learning_rate=3e-4)
self.optimizer_critic2 = tf.keras.optimizers.Adam(learning_rate=3e-4)
def get_action(self, state):
state = np.expand_dims(state, axis=0)
mu, sigma = self.actor(state)
dist = tfp.distributions.Normal(mu, sigma)
action = tf.squeeze(dist.sample(1), axis=0)
return action.numpy()
def update(self, replay_buffer, batch_size):
states, actions, rewards, next_states, dones = replay_buffer.sample(batch_size)
with tf.GradientTape(persistent=True) as tape:
# Compute actor loss
mu, sigma = self.actor(states)
dist = tfp.distributions.Normal(mu, sigma)
log_pi = dist.log_prob(actions)
q1 = self.critic1(states, actions)
q2 = self.critic2(states, actions)
q_min = tf.minimum(q1, q2)
alpha_loss = -tf.reduce_mean(self.alpha * (log_pi + self.target_entropy))
actor_loss = -tf.reduce_mean(tf.exp(self.alpha) * log_pi * q_min)
# Compute critic loss
next_mu, next_sigma = self.actor(next_states)
next_dist = tfp.distributions.Normal(next_mu, next_sigma)
next_actions = tf.clip_by_value(next_dist.sample(1), -self.max_action, self.max_action)
target_q1 = self.target_critic1(next_states, next_actions)
target_q2 = self.target_critic2(next_states, next_actions)
target_q = tf.minimum(target_q1, target_q2)
target_q = rewards + self.gamma * (1.0 - dones) * (target_q - tf.exp(self.alpha) * next_dist.entropy())
q1_loss = tf.reduce_mean(tf.square(q1 - target_q))
q2_loss = tf.reduce_mean(tf.square(q2 - target_q))
critic_loss = q1_loss + q2_loss + alpha_loss
# Compute gradients and update weights
actor_grads = tape.gradient(actor_loss, self.actor.trainable_variables)
critic1_grads = tape.gradient(critic_loss, self.critic1.trainable_variables)
critic2_grads = tape.gradient(critic_loss, self.critic2.trainable_variables)
self.optimizer_actor.apply_gradients(zip(actor_grads, self.actor.trainable_variables))
self.optimizer_critic1.apply_gradients(zip(critic1_grads, self.critic1.trainable_variables))
self.optimizer_critic2.apply_gradients(zip(critic2_grads, self.critic2.trainable_variables))
# Update target networks
for w, w_target in zip(self.critic1.weights, self.target_critic1.weights):
w_target.assign(self.tau * w + (1 - self.tau) * w_target)
for w, w_target in zip(self.critic2.weights, self.target_critic2.weights):
w_target.assign(self.tau * w + (1 - self.tau) * w_target)
# Update alpha
alpha_grad = tape.gradient(alpha_loss, self.alpha)
self.alpha.assign_add(1e-4 * alpha_grad)
def save(self, filename):
self.actor.save_weights(filename + '_actor')
self.critic1.save_weights(filename + '_critic1')
self.critic2.save_weights(filename + '_critic2')
def load(self, filename):
self.actor.load_weights(filename + '_actor')
self.critic1.load_weights(filename + '_critic1')
self.critic2.load_weights(filename + '_critic2')
# Create replay buffer
class ReplayBuffer:
def __init__(self, max_size):
self.max_size = max_size
self.buffer = []
self.position = 0
def add(self, state, action, reward, next_state, done):
if len(self.buffer) < self.max_size:
self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.max_size
def sample(self, batch_size):
indices = np.random.choice(len(self.buffer), batch_size, replace=False)
states, actions, rewards, next_states, dones = [], [], [], [], []
for idx in indices:
state, action, reward, next_state, done = self.buffer[idx]
states.append(np.array(state, copy=False))
actions.append(np.array(action, copy=False))
rewards.append(reward)
next_states.append(np.array(next_state, copy=False))
dones.append(done)
return np.array(states), np.array(actions), np.array(rewards, dtype=np.float32), np.array(next_states), np.array(dones, dtype=np.uint8)
# Create environment and agent
env = gym.make('Pendulum-v0')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
agent = SACAgent(state_dim, action_dim, max_action)
replay_buffer = ReplayBuffer(1000000)
# Train agent
max_episodes = 1000
max_steps = 500
batch_size = 256
update_interval = 1
target_entropy = -action_dim
for episode in range(max_episodes):
state = env.reset()
total_reward = 0
for step in range(max_steps):
action = agent.get_action(state)
next_state, reward, done, _ = env.step(action)
replay_buffer.add(state, action, reward, next_state, done)
if len(replay_buffer.buffer) > batch_size:
agent.update(replay_buffer, batch_size)
state = next_state
total_reward += reward
if done:
break
print("Episode:", episode, "Total Reward:", total_reward)
```
请注意,以上代码仅供参考,并且需要根据具体环境和参数进行调整和完善。








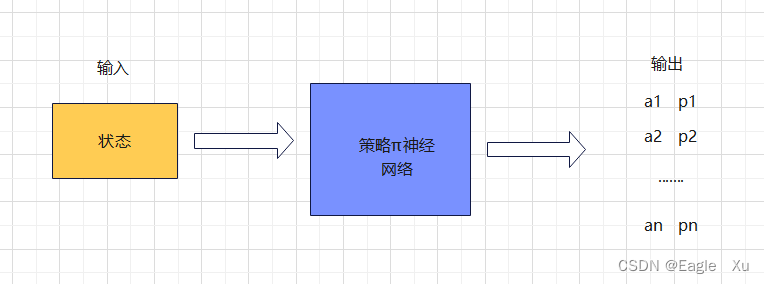
 本文介绍了强化学习中的策略梯度方法,通过策略网络近似策略函数,与基于价值的学习相对,适用于动作连续的场景。此外,还讨论了Actor-Critic算法,其中策略网络作为演员,价值网络作为评委,用于连续动作的控制任务。
本文介绍了强化学习中的策略梯度方法,通过策略网络近似策略函数,与基于价值的学习相对,适用于动作连续的场景。此外,还讨论了Actor-Critic算法,其中策略网络作为演员,价值网络作为评委,用于连续动作的控制任务。








 把之前的Vπ(st)的推导写成所有状态的形式。策略梯度可以写成下面定理中的期望形式
把之前的Vπ(st)的推导写成所有状态的形式。策略梯度可以写成下面定理中的期望形式





















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









