







策略π和价值函数
在前面的学习中,我们已经了解到了MDP,以及智能体和环境的交互过程和回报的定义。
我们知道在智能体与环境的交互过程中,会产生状态,动作,奖励的序列。而我们的目标是要最大化累积回报,那我们怎样才能从这些序列中学习经验来实现我们的目标?这里首先介绍一下价值函数这个概念。几乎所有的强化学习算法都涉及价值函数的计算。
价值函数是状态(或状态与动作二元组)的函数,用来评估当前智能体在给定状态(或给定状态与动作)下有多好。这里的“有多好”概念是用未来预期的收益定义的,或者更准确的说就是回报的期望值。智能体期望未来能得到的收益取决于智能体所选择的动作。因此价值函数是与特定的行为方式相关,我们把这种特定的行为方式称之为策略。通俗来说就是决策。在什么样的状态,智能体该做什么样的动作。严格来说,策略是从状态到每个动作的选择概率之间的映射。我们用π(a|s)表示St=s时,At=a的概率。这个策略π如何随着其经验发生变化和使用的强化学习算法有关。
下面来看看价值函数的定义,我们把策略π下状态s的价值函数记为Vπ(s),即从状态s开始,智能体按照策略π进行决策所获得的回报的概率期望值。对于MDP,我们可以正式定义为:
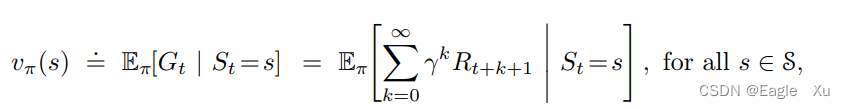
我们把函数Vπ称为策略π的状态价值函数。状态的价值取决于在这个状态下所有可能动作的的价值。你可以理解为这个函数是用来评估某个状态的好坏的。也就是说,当智能体在与环境不断的交互过程中,Gt在不断的变大的过程中,其交互的这些状态的V值也是越来越大的。类似的,我们把策略π下在状态s时采取动作a的价值记为qπ(s,a),定义如下:
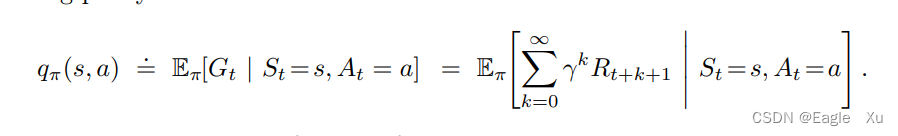
我们称qπ为策略π的动作价值函数。这个通俗的理解就是,环境给定一个状态s,智能体执行一个动作a,qπ对这个动作进行打分,评价这个动作到底是好还是坏。
贝尔曼方程
在强化学习和动态规划(后面的章节会提及)中。价值函数有一个基本特性,就是他们满足某种递归关系。对于任何策略π和状态s,s的价值与其可能的后继状态的价值之间存在以下关系:
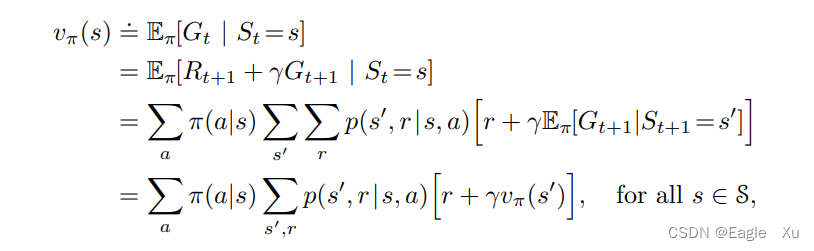
这个公式看起来挺吓人的,其实仔细一看也确实吓人,哈哈哈,骗你的。s`表示下一个状态,其他符号前面都讲过。我们把最后的那个结果分开来看。最外边的期望E是对所有动作求的。我们可以写成连加的形式,既然是对所有动作求的,那肯定要乘一个π(a|s),关于动作的概率分布。现在我们做出了一个动作,根据p(转态转移密度函数),又会有很多可能,所以这里又一个连加符号乘p,最后那一部分就是收到的奖励与下一个状态的价值。这真是设计得太优雅啦!
上图的最后一行表示的就是贝尔曼方程。他不仅用等式表达了状态价值与后继状态价值之间的关系,而且对所有可能性采用其出现概率进行了加权平均。这也说明了起始状态的的价值一定等于后继状态的(折扣)期望值加上对应的收益期望值。
下图是vπ的回溯图,通过这个图,我们可以更好的理解贝尔曼方程。
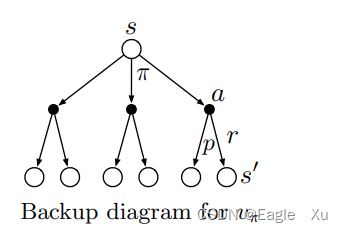
状态s下面有多个可能的动作,每个动作的概率由π决定。执行某个动作a后,会根据p转换到下一个状态。这和我前面的描述过程是一样的。
最优策略和最优价值函数
解决一个强化学习任务就意味着要找出一个策略,使其能够在长期过程中获得大量收益。对于有限MDP,我们可以通过比较价值函数精确的定义一个策略。从本质上来说,价值函数定义了策略上的一个偏序关系。即如果要说一个策略π与另一个策略π·相差不多甚至更好,那么其所有状态上的期望回报都应该等于或者大于π·的期望回报。也就是说,若对于所有的s∈S,π≧π·,那么应当Vπ(s)≧Vπ·(s)。总会存在一个策略不劣于其他所有策略,这就是最优策略。值得注意的是,最优策略可能不止一个。
我们用v*(s)来表示最优状态价值函数。定义为:
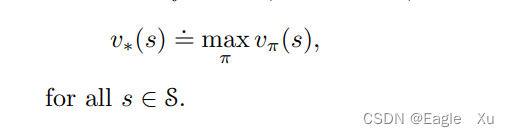
最优策略也共享相同的最优动作价值函数,记为q*:
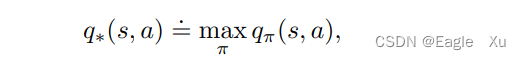
这里的π是最优的那个π策略
贝尔曼最优方程
因为v’(v星,格式原因,‘代替*)是策略的价值函数,它必须满足前面提到的贝尔曼方程中状态和价值的一致性条件。但因为他是最优的价值函数,所以v’(v星)的一致性条件可以用一种特殊的形式表示,而不用拘泥于特定的策略。这就是贝尔曼最优方程。
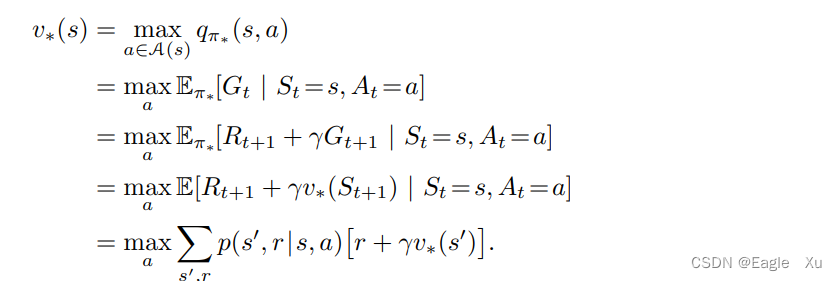
我们可以直观的理解为贝尔曼最优方程阐述了一个事实:最优策略下各个状态的价值一定等于这个状态下最优动作的期望回报。最后两个等式就是v的贝尔曼最优方程的两种形式。一种是期望的形式,一种是连加的形式(涉及到p)。下图是q的贝尔曼最优方程形式。
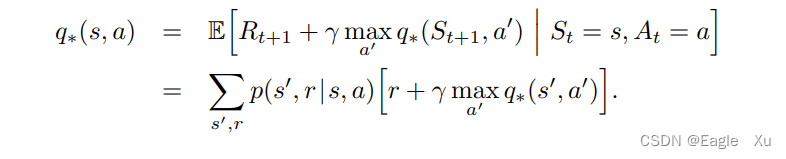
a’表示下一个动作。这个公式很重要,不出意外的话,后面的DQN算法中,我们会再次见面。对于有限的MDP来说,vπ的贝尔曼最优方程有独立于策略的唯一解。贝尔曼最优方程实际上是一个方程组,每一个状态对应一个方程式。也就是说,如果有n个状态,那么有n个含有n个未知量的方程。如果环境的动态特性p是已知的,那么原则上可以用解非线性方程组的方法来求解。
小结
我们已经定义了最优价值函数和最优策略。知道什么是最优的贝尔曼方程。显示的求解贝尔曼最优方程给出了找到一个最优策略的方法,也就是解决强化学习问题的方法。但是通过求解线性方程这种方法很少是直接有效的。这类似于穷举搜索,预估所有的可能性,计算每种可能性出现的概率及其期望收益。这种解法需要3个前提,一是知道p,二是计算资源足够,三是具有马尔科夫性。
按照上面的方法,智能体能够很好的学习到最优策略,但事实却不是这样的。这都是理想的情况下,真实情况下的智能体只能采用不同程度的近似方法。许多不同的决策方法都被视为近似求解贝尔曼最优方程的途径。比如启发式搜索算法,动态规划等。其中,动态规划算法与贝尔曼最优方程的关系更近,它们都是基于实际经历过的历史经验来预估未来的长期或全局期望。在强化学习中,我们最关心的是最优解无法找到而必须采用某种近似方法来逼近最优解的情况。下一小结,我们将介绍动态规划,在给定一个马尔科夫决策过程(MDP)描述的完备环境模型(p)情况下,其可以计算最优策略。

















 1286
1286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









