






学习链接:【论文精读】Focal Inverse Distance Transform Maps for Crowd Localization
问题
密度图回归并不能提供人头的准确位置。
原因如下:
1、密度图是由高斯模糊的斑点组成的;
2、在密度图的密集区域存在着严重的重叠区域。
因此提出FIDT地图来有效地提取出每个人头的确切位置,在密集区域也没有重叠。
贡献
- 为了有效应对密集场景下的人群定位任务,提出了
FIDT地图。FIDT地图的局部极大值表示精确的人员位置; - 引入
I-SSIM损失,使模型关注独立区域,增强模型处理局部极大值和背景区域的能力,来更好的生成FIDT地图。 - 基于FIDT地图,设计了一种局部最大值检测后处理策略
LMDS,可以有效地定位预测的局部最大值(头部中心)。 - 大量的实验表明,所提出的方法达到了先进的定位性能。此外,我们的方法对消极(例如兵马俑图片)和极度密集的场景具有鲁棒性。
知识补充:
distance transform (距离变换):主要用于计算非零像素到最近零像素点的距离。对图像进行二值化处理,然后给每个像素赋值为离它最近的背景像素点(图像边界)的距离值(Manhattan距离or欧氏距离),得到distance metric(距离矩阵),那么离边界越远的点越亮。
距离变换相关链接:数字图像的距离变换算法、Distance Transforms二值图像的距离变换及其应用
方法整体流程
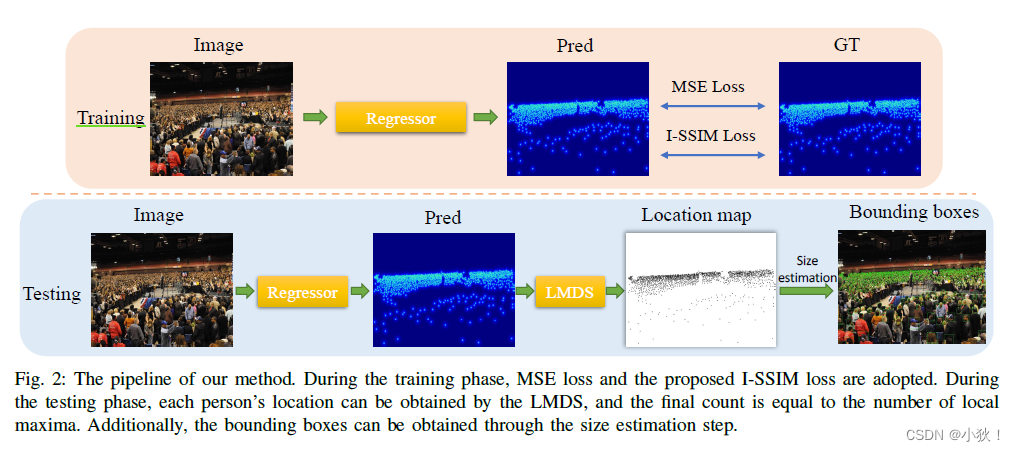
训练阶段: 用于训练生成FIDT地图的Regressor回归器。MSE损失和I-SSIM损失来评估真值和预测的FIDT地图之间的差别, 进而优化回归器。
测试阶段:模型生成预测的FIDT地图后,经过LMDS后处理策略生成 Location 地图,最终计数等于局部极大值的个数,后面可以使用KNN可以生成人头的检测框。
Focal Inverse Distance Transform Map
(FIDT 地图,聚焦反距离变换地图)
首先介绍欧氏距离的计算公式:

P
(
x
,
y
)
P(x,y)
P(x,y)代表了人头标注的真值中心点(x’, y’)与这幅图上的其他像素点(x, y)之间的欧氏距离,
B
B
B则代表了标注的真值人头中心点的位置集合。
因为直接回归这个距离变换地图比较困难(距离从0到这幅图的长度大小),所以使用了这个距离的倒数来进行表示,也就是对应的
I
′
I'
I′,计算公式如下:
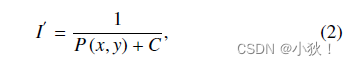
其中
C
C
C是1,为了防止分母为0。这个
I
′
I'
I′也就是IDT地图。但是为了让聚焦在人头中心的区域更加突出,使模型更加专注于头部,也就是说远离人头的时候衰减慢,在背景的区域应该迅速接近0。因此提出了FIDT地图,计算公式如下:
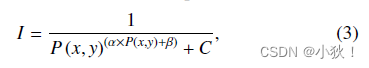
其实地图代表的也是反映了一种距离关系。
I
I
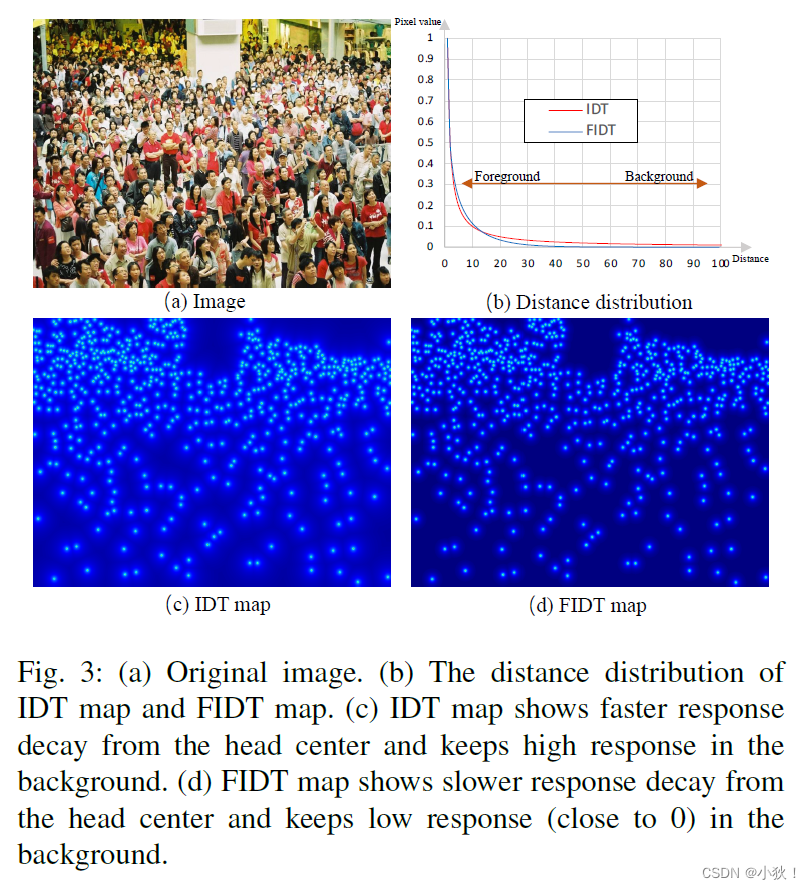
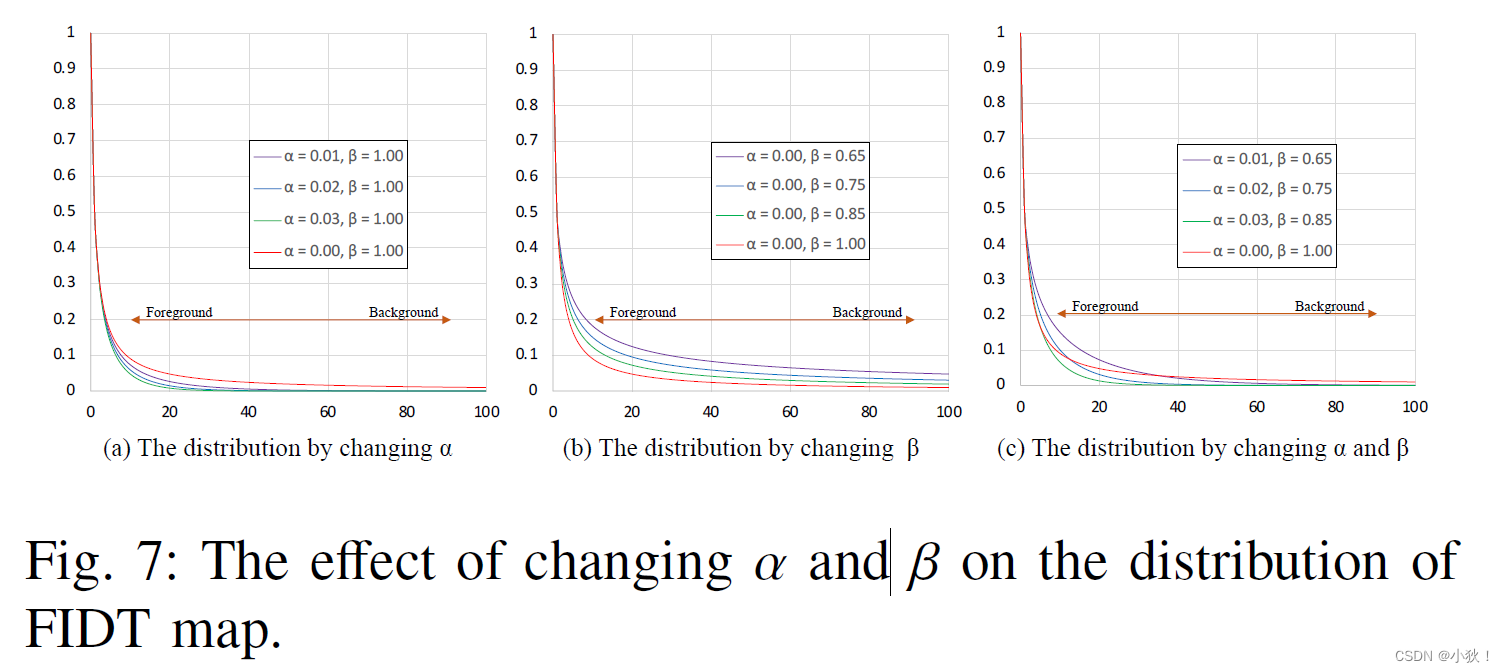
I就是提出的FIDT地图,α和β设定大小为0.02和0.75。从下图的b也能看出IDT和FIDT的距离分布,IDT在头部区域下降太快,在背景区域下降太慢,导致背景和头部不好区分,而FIDT在人头区域的时候比IDT衰减慢,在背景的区域迅速接近0,而IDT要高于FIDT。使得头部能够更加图突出。这个也在c和d图中能够看得出来,d的FIDT地图更加专注于头部,地图更加干练。
Localization framework
Regressor
本文的回归部分的模型以HRNET为主干网络,加了一个卷积和两个反卷积作为head,去回归FIDT值。
HRNet网络介绍:HRNet网络简介
本文代码实际的HRNet结构图如下:

Local Maxima Detection Strategy
使用LMDT策略的后处理操作来得到人头数和人头坐标位置。

输入:预测的FIDT地图
输出:人头坐标和人头总数
过程:
1.用maxpooling抑制3x3邻域内非最大值的点,非区域内的最大值都置0
2.若全局最大值<0.1,认为没人
3.取全局最大值的100/255为阀值,大于这个阈值的是头中心,小于阈值的是背景(上面伪代码0错误)
特点:非人但像人的图像计数也为0,计数正确。
人头bounding boxes可视化
用LDMS策略得到的人头坐标,计算每个人头坐标和它的K近邻的平均距离,并用参数
f
f
f(与图像大小有关)来控制bounding box的大小,不至于在人头稀疏的地方导致bounding box太大。计算公式如下:
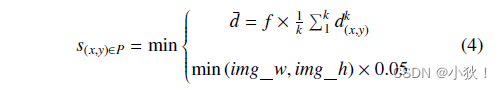
其中
S
(
x
,
y
)
S_{(x,y)}
S(x,y)就是要求的实例的bounding box大小,P是预测得出的人头坐标的集合。取计算得出的平均距离d和图像的长和宽的0.05的最小值作为最终bounding box的大小。
此过程只用于测试阶段的可视化效果,不影响定位和计数过程。
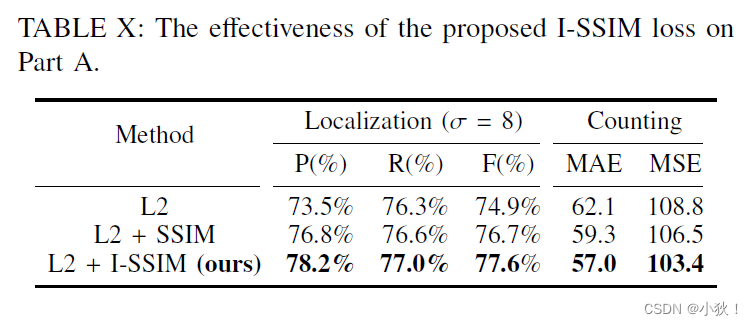
Independent SSIM Loss
仅用预测的特征图和FIDT地图的MSE损失,不足以约束人头区域的学习。下面是前人所提出的SSIM损失,计算公式如下:
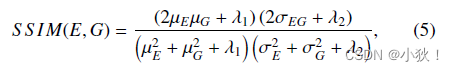
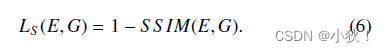
上面公式中,
E
E
E和
G
G
G分别表示预测图(estimated map)和真值图(ground-truth map),
μ
\mu
μ和
σ
\sigma
σ分别表示map的均值和协方差,
σ
2
\sigma^2
σ2代表map的方差,
λ
1
\lambda_1
λ1和
λ
2
\lambda_2
λ2大小分别为0.0001和0.0009来避免除0,SSIM的大小范围是[-1,1],数值越大代表预测图和真值图越像,因此损失函数就是用1-SSIM。
但是SSIM损失只是用滑窗去扫描全图,没有专注于人头区域,因此提出了Independent SSIM损失,计算公式如下:
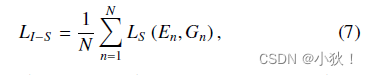
N
N
N代表了总的人头数(应该是GT中的),
E
n
E_n
En和
G
n
G_n
Gn代表了第n个独立的实例区域(也就是局部最大值的区域),区域的大小设置为了30*30,因为作者发现对于多数的独立实例来说,这个大小能够包囊了整个头部区域而不包含多余的背景。
最终的损失函数公式是由MSE损失和I-SSIM损失的和,计算公式如下:
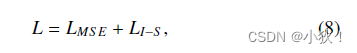
预测图和真值图上的人头的坐标如何才算匹配上呢?
两者之间存在距离阈值 σ \sigma σ,小于这个阈值才算两个坐标匹配上。详情见下面。
实验
参数大小
数据增强:随机裁剪(256x256(PartA&B), 512x512 for others)和水平翻转;
生成bounding boxes的参数大小:k:4,
f
f
f:0.1;
FIDT地图中的α和β分别设置为:0.02,0.75;
评价指标
1.定位指标
预测的头的坐标和真值坐标之间的距离存在距离阈值,他们之间的距离小于这个阈值则认为这两个点匹配上了。这个阈值
σ
\sigma
σ与真实的头的大小有关(如果这个数据集提供了box级别的标注)。
前人给出了两个关于阈值的定义:

w和h是标注的box的宽和高。
对于UCF-QNRF数据集,设置了不同的阈值(1,2,100像素)去计算P,R,F-measure;
对于JHU-Crowd++,ShanghaiTech PartA, Part B, and UCF CC 50数据集,设置了两个固定的阈值大小,4和8。
2.计数指标
使用MSE和MAE来计算,M是测试图片的数量,Pi和 Gi分别是第i副图片的预测的和真值的人头数量,计算公式如下:

实验结果
定位表现比较
表1:在NWPU-Crowd数据集上的定位表现。
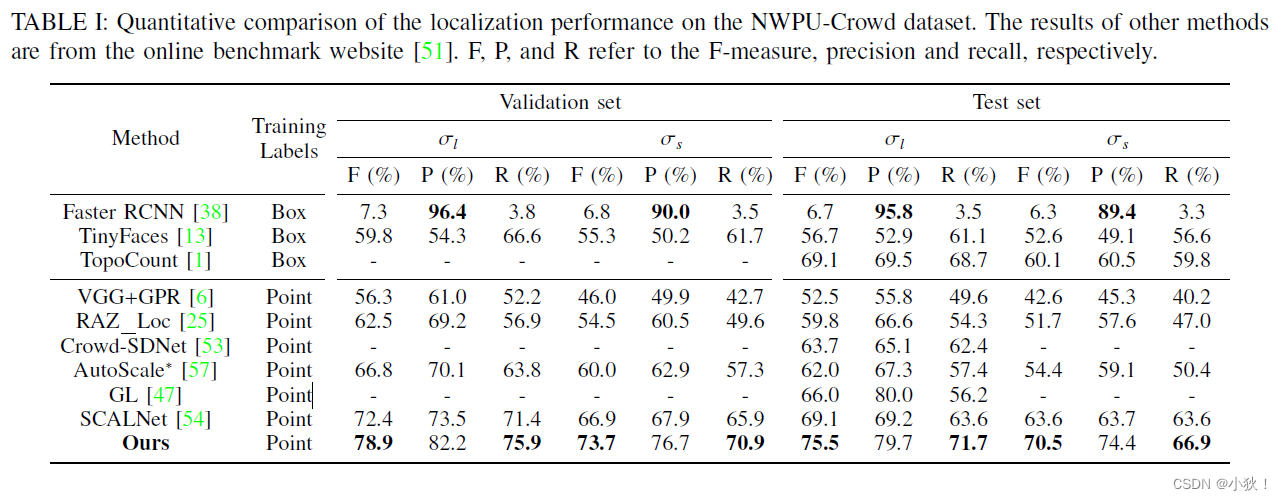
表2:在UCF-QNRF数据集上的定位表现。

表3:在JHU-Crowd++数据集上的定位表现。
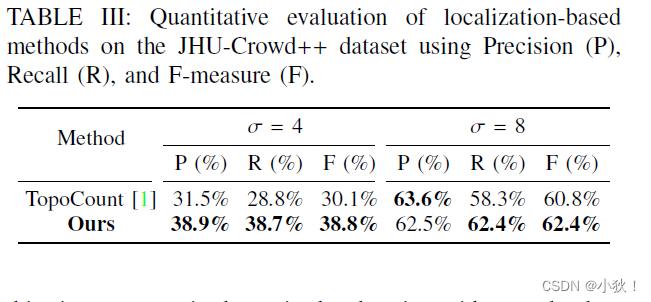
表4:在ShanghaiTech Part A & Part B数据集上的定位表现。
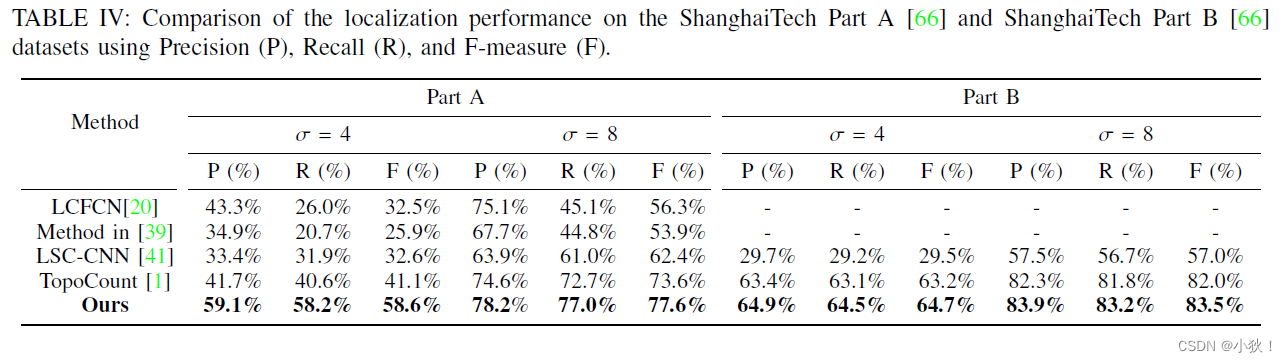
表5:在UCF_CC_50数据集上的定位表现。
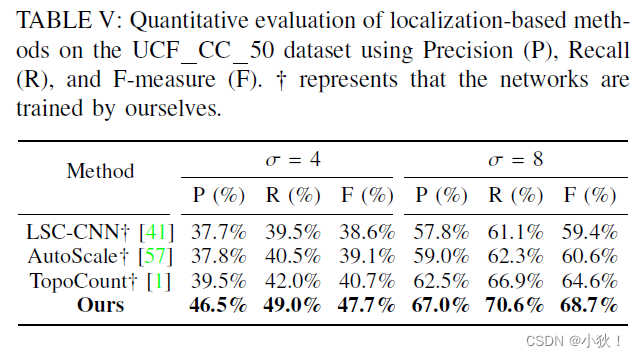
计数表现比较
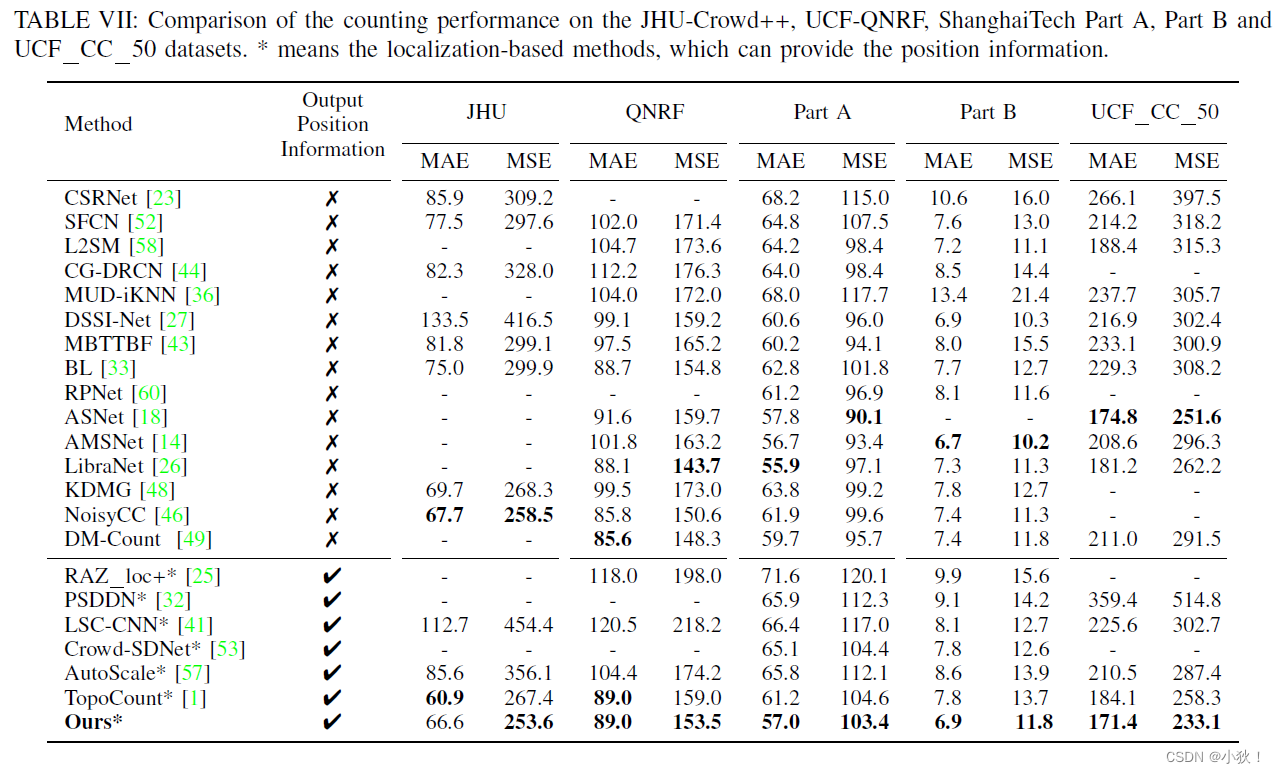
表6:在NWPU-Crowd数据集上的计数表现。
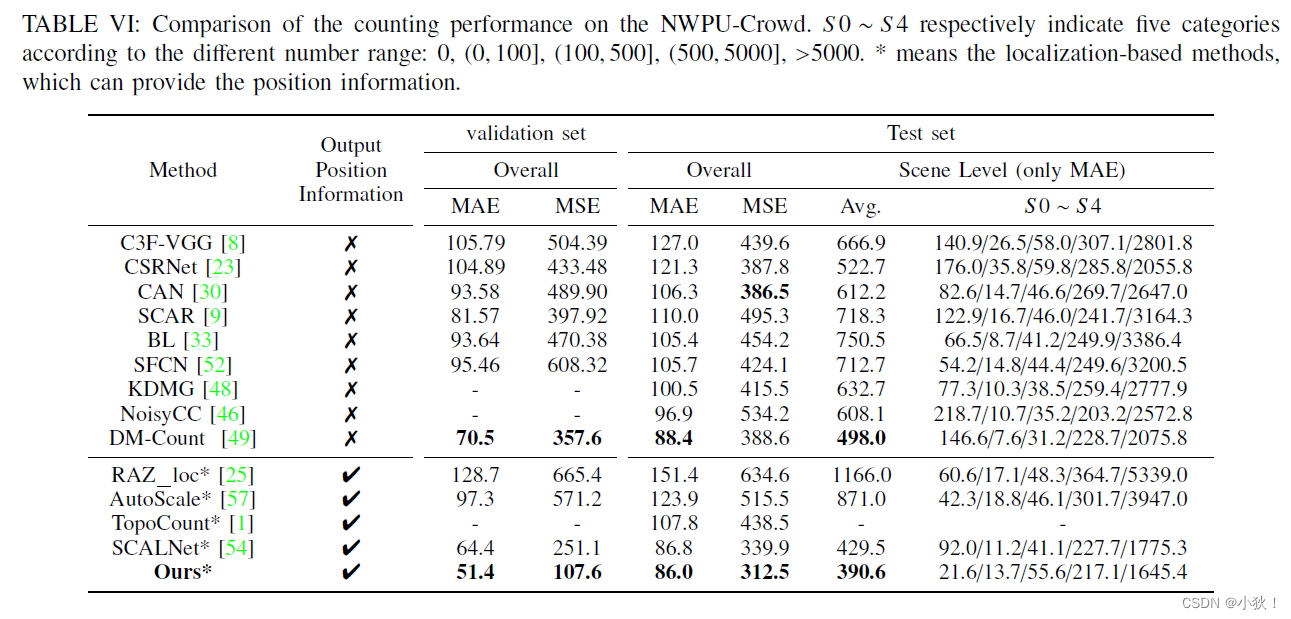
表7:在JHU-Crowd++, UCF-QNRF, ShanghaiTech Part A, Part B and UCF CC 50 数据集上的计数表现。
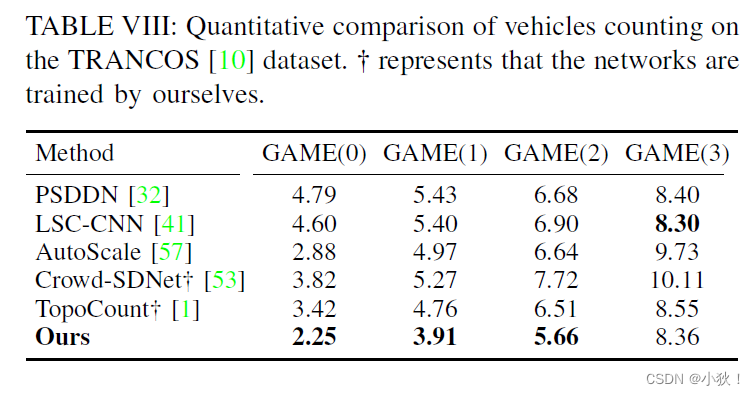
在车辆数据集上的表现
TRANCOS数据集上进行车辆计数,评价指标为GAME,计算公式为:
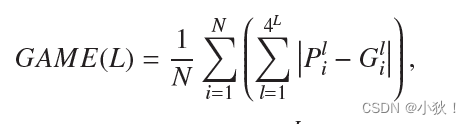
表8:在车辆数据集上的计数表现。
消融实现
FIDT地图的分析
分析不同的α和β值,哪组值表现最好。最后设置的大小为 α = 0.02 and β = 0.75。
I-SSIM损失的效果分析
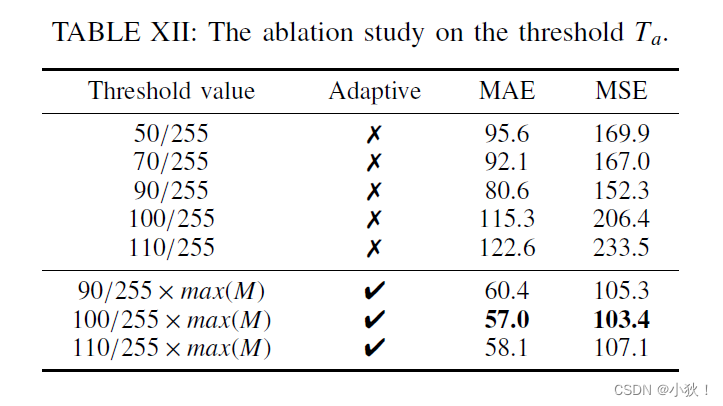
Ta值的分析
用于在LDMS策略中的划分positive点的阈值。定义的大小为
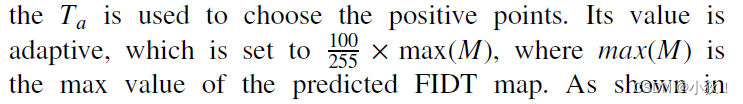
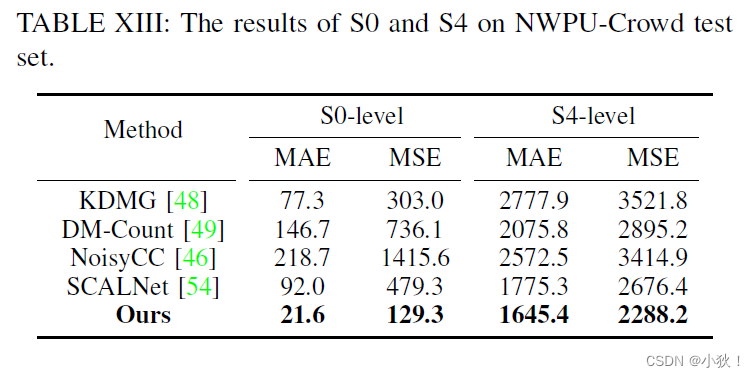
消极和密集区域的鲁棒性分析
表13:在NWPU-Crowd的不同密集程度上的不同算法的结果对比。
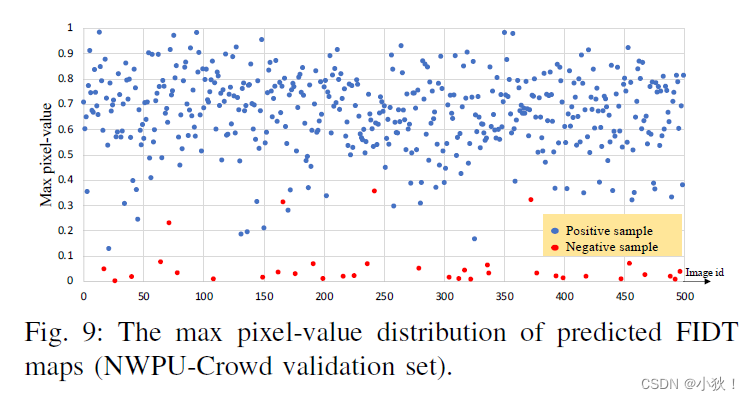
下图表现了在消极(不是人)图片上本文算法的鲁棒性。

判断是否有人的阈值Tf=0.1的由来,见下图。
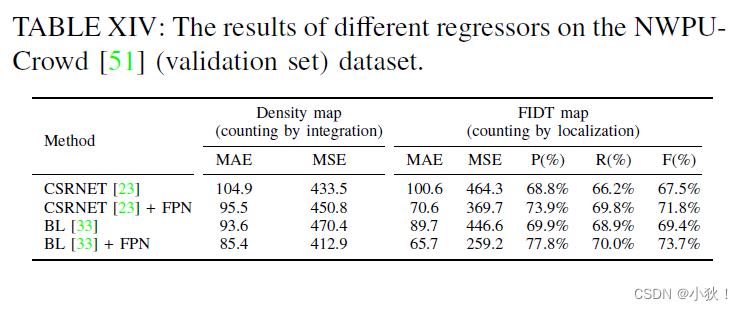
不同regressor的回归生成FIDT地图的情况-与密度图做对比
缺点
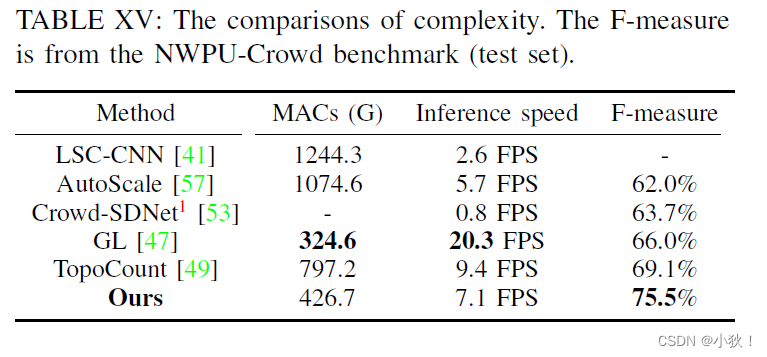
推理比一些实时性的方法要慢。















 2389
2389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









