







【比赛向】东京证卷交易所预测-赛题理解(Kaggle_2022_Structured Data)
比赛地址:https://www.kaggle.com/competitions/jpx-tokyo-stock-exchange-prediction
东京证卷交易所预测 系列文章目录
1 赛题背景
金融市场的成功需要一个人去识别可靠的投资。当一只股票被低估时买入是有意义的;如果估值过高,又该卖出。虽然这些财务决策以往都是由专业人士手工做出,但科技为散户投资者带来了新机会。具体而言,数据科学家可能会对探索量化交易感兴趣,在这种交易中,决策是基于训练过的模型进行预测得到。目前有很多定量交易工具用于分析金融市场和制定投资策略。创建和执行这样的策略需要历史和实时数据,这对于散户来说很难获得。
该比赛将从日本真实股票市场中提供财务数据,让散户投资者能够最大限度分析市场。日本证券交易所集团(JPX)是一家控股公司,运营者世界上最大的证券交易所之一——东京证券交易所(TSE)。
本次比赛将在模型训练结束后,将模型和真实的未来回报进行比较。具体而言,每个参赛者将对约2,000只股票进行预期回报率从高到低排序,并根据前200支股票和后200支股票的回报率差进行评估。参赛者可以访问来自日本市场的财务数据,例如股票信息和历史股票价格。
简述:对确定日期和股票代码进行Rank预测,Rank表示2000只股票中每只股票的第二天收盘价和第二天收盘价的变化率的排名。
2 赛题数据

五大文件夹:
- data_specification: 给出数据表的各列具体意义(仅给出各列的具体含义)
- example_test_files: 测试集的数据文件夹,用于预测提交,与train_files格式一致,只是缺少’Target’
- jpx_tokyo_market_prediction: 启动测试提交的API,需5分钟内提交所有行并少于0.5GB内存(我们不必考虑文件内容,与比赛数据无关)
- supplemental_files: 包含补充训练数据的动态窗口
- train_files: 训练集,主要文件夹包含了各类股票信息
- stock_list.csv: SecuritiesCode(即股票id)和公司名称之间的映射,以及有关公司所在行业的一般信息
2.1 Stock_list.csv

给出了4417只股票和对应公司的信息
具体而言,各列的意义为:
股票id、有效日期、公司名称、部门/产品、TSE市场重组后的类别、TOPIX-17分类标准下的股票行业种类代码、TOPIX-17的股票股票行业种类、TOPIX-17的种类代码、TOPIX-17的名称、TOPIX系列代码、TOPIX系列代码名称、计算市值的交易日期、交易日期下的收盘价、已发行的证券数、2021年12月3日的市值、需要预测的股票标记
个人觉得有意义的是:
EffectiveDate、Section/Products、NewMarketSegment、33SectorCode、17SectorCode、NewIndexSeriesSizeCode
2.2 train_files
- stock_prices.csv: 股票基本信息表
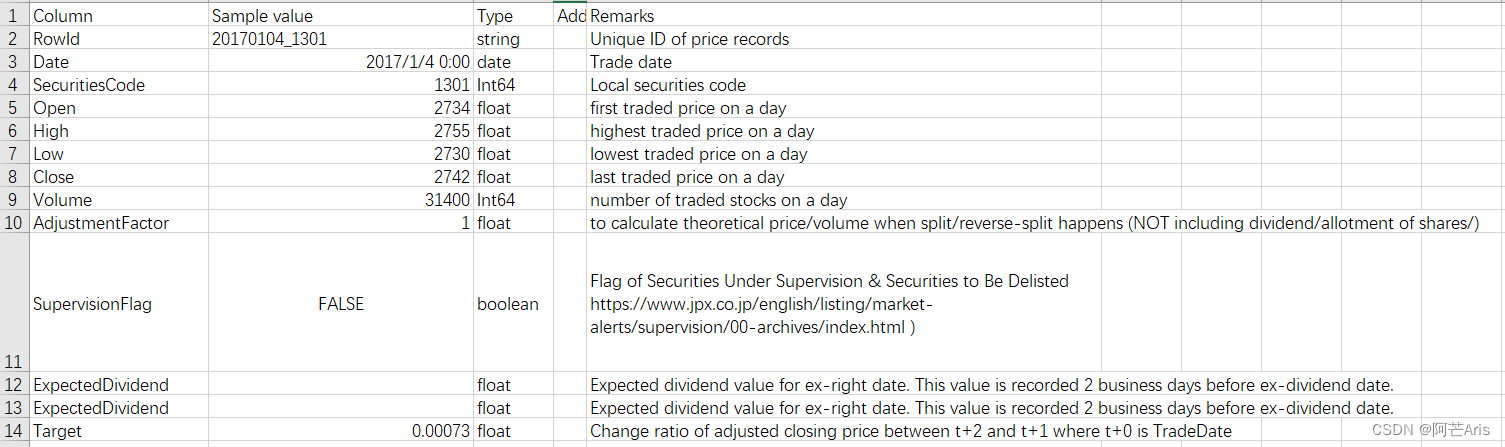
主要包含了各只股票的基本信息,如
Open:开盘价(当天首次交易价格)、Close:收盘价(最后一次成交价)、Volume:一天内股票交易量、AdjustmentFactor:理论价格/成交量、ExpectedDividend:除权日(ex-right date)的预期股息价值,该值是在除息日期前2个营业日记录的,共99.19%缺失,不考虑使用、
以及Target = [Close(t+2)-Close(t+1)] / Close(t+1)
而我们最终预测的Rank就是Target的逆排序,Target越大Rank排名越靠前
-
secondary_stock_prices.csv: 股票基本信息表,格式同stock_prices
stock_prices是核心数据集,包含了2000种最常交易的股票。但许多流动性较低的股票也在东京市场上交易,他们虽然没有评分,但可以帮住评估整个市场 -
options.csv: 基于大盘的期权状况数据。期权隐含了对股票市场未来价格的预测,即使期权没有打分,但可能很有价值
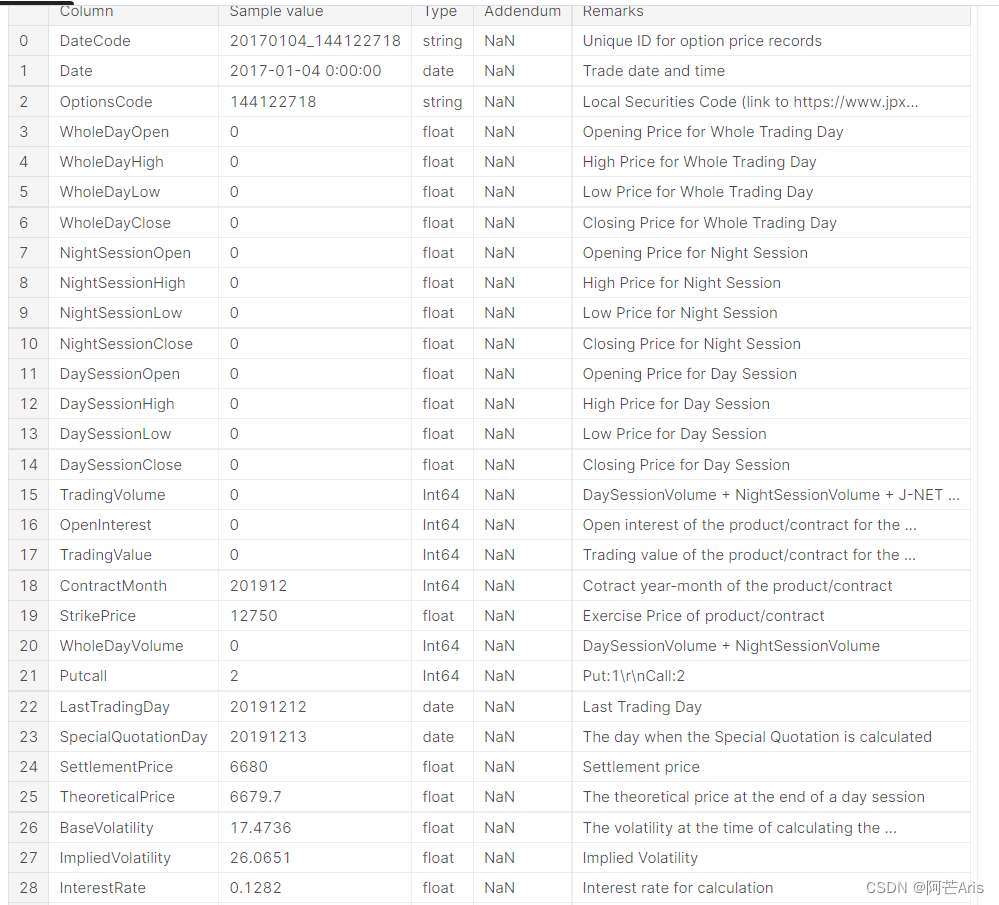
暂时不清楚这个options.csv该怎么结合到stock_prices里,没有理解清楚期权和股票的区别和关系。 -
financials.csv
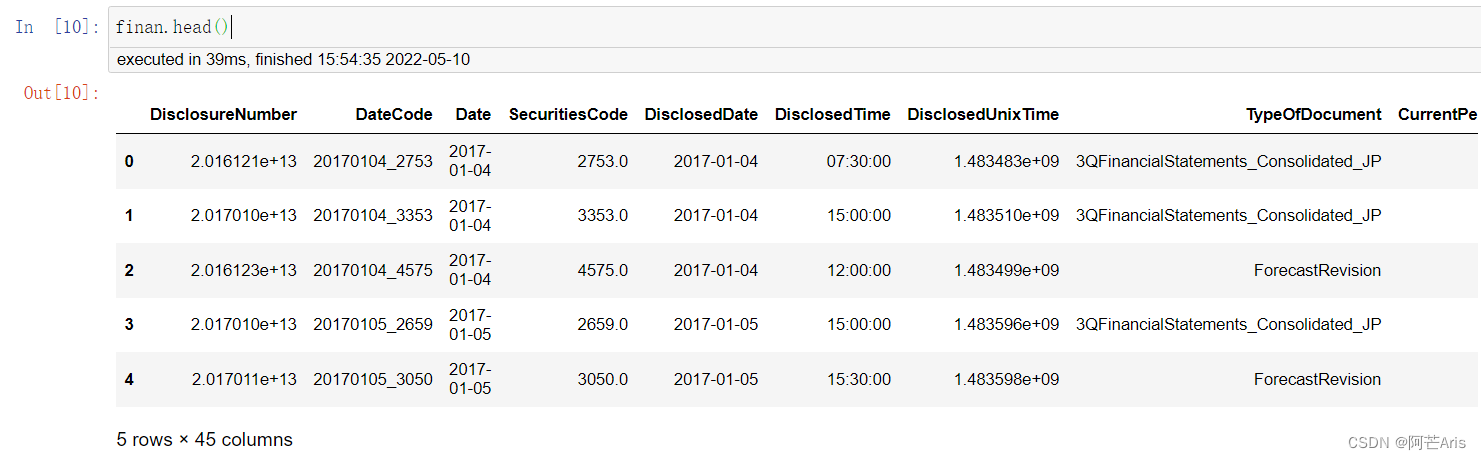
financial.csv是针对4071只股票的季度收益报告的结果,其中可以通过DateCode列与stock_prices的RowId相对应使用。 -
trades.csv
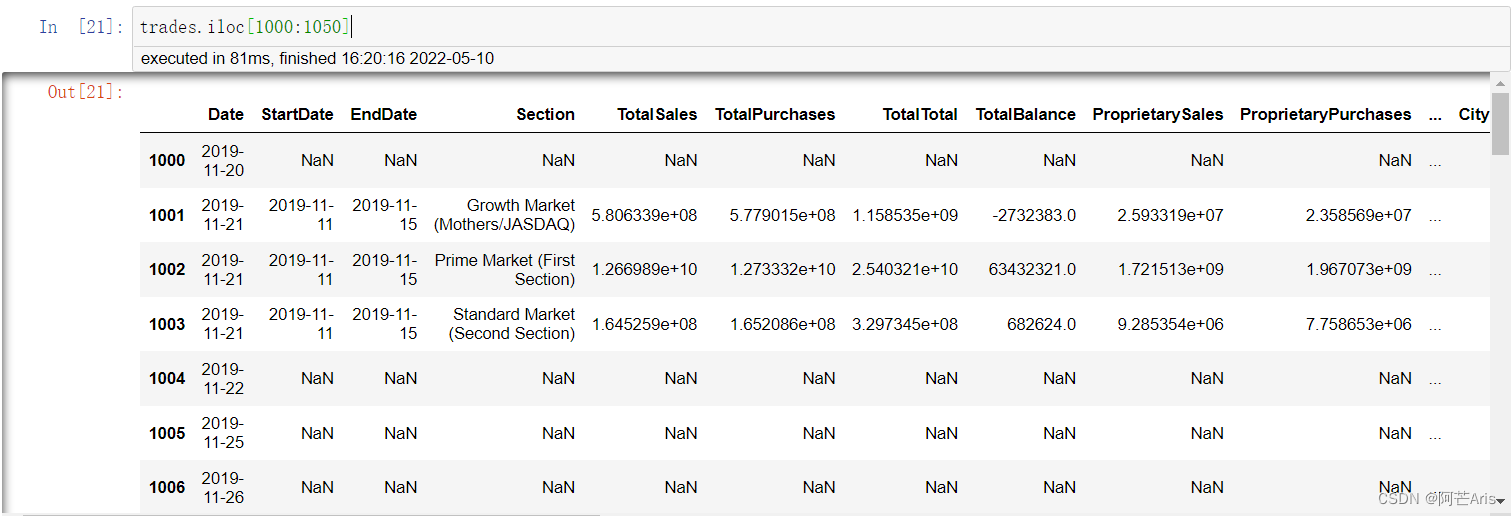
trades.csv是上一个商业星期的总交易量。共1712条数据,缺失严重,约44.68%的行不能使用。
可以通过Date列与stock_price相关联。
2.3 supplemental_files
与train_files文件内容格式完全一致,将会在5月初、6月初的竞赛主阶段,以及提交文件锁定前大约一周,用新数据更新。
在最终模型训练过程中,需要将这里面的数据与train_files合并作为我们最终的训练集使用。
2.4 jpx_tokyo_market_prediction
测试提交API文件,与赛题内容无关
2.5 example_test_files
与train_files内容格式相同,数据中没有‘Target’一项,仅多出一个sample_submission.csv文件,文件格式如下,这个文件便是最终预测提交的。
在此,注意,针对2000只股票的排序,我们的Rank是0-1999,而非1-2000,其中的Rank是根据‘Target’得到的。

2.6 data_specifications
针对train_files文件夹内的五个文件,说明数据表各列的具体含义并给出示例。
3 baseline
- 导入相关库,其中本地运行时,不用导入
import jpx_tokyo_market_prediction,它用于线上预测
import os
import pickle
import sys
import warnings
from glob import glob
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import shap
import lightgbm as lgb
import xgboost as xgb
from scipy.stats import spearmanr
from sklearn.ensemble import (
ExtraTreesRegressor,
GradientBoostingRegressor,
RandomForestRegressor,
)
from sklearn.metrics import accuracy_score, mean_squared_error
from tqdm.notebook import tqdm
import jpx_tokyo_market_prediction
import warnings; warnings.filterwarnings("ignore")
- 读取数据
# stock_li = pd.read_csv('./input/stock_list.csv')
# stock_li_spec = pd.read_csv('./input/stock_list_spec.csv')
train_dir = "../input/jpx-tokyo-stock-exchange-prediction/train_files/"
supplemental_dir = '../input/jpx-tokyo-stock-exchange-prediction/supplemental_files/'
test_dir = '../input/jpx-tokyo-stock-exchange-prediction/example_test_files/'
stock = pd.read_csv(train_dir+'stock_prices.csv')
options = pd.read_csv(train_dir+'options.csv')
sec_stock = pd.read_csv(train_dir+'secondary_stock_prices.csv')
finan = pd.read_csv(train_dir+'financials.csv')
trades = pd.read_csv(train_dir+'trades.csv')
stock_supplemental = pd.read_csv(supplemental_dir+'stock_prices.csv')
stock_test = pd.read_csv(test_dir+'stock_prices.csv')
submission = pd.read_csv(test_dir+'sample_submission.csv')
- 特征工程+模型训练
def upper_shadow(df): return df['High'] - np.maximum(df['Close'], df['Open'])
def lower_shadow(df): return np.minimum(df['Close'], df['Open']) - df['Low']
# A utility function to build features from the original df
# It works for rows to, so we can reutilize it.
def get_features(df):
df_feat = df[['Open', 'High', 'Low', 'Close', 'Volume']].copy()
df_feat['Upper_Shadow'] = upper_shadow(df_feat)
df_feat['Lower_Shadow'] = lower_shadow(df_feat)
return df_feat
def get_Xy_and_model(df_train):
df_proc = get_features(df_train)
df_proc['y'] = df_train['Target']
df_proc = df_proc.dropna(how = "any")
X = df_proc.drop("y", axis=1)
y = df_proc["y"]
try: # GPU LGB
model = lgb.LGBMRegressor(device_type = 'gpu')
model.fit(X, y)
except: # CPU LGB
model = lgb.LGBMRegressor()
model.fit(X, y)
return X, y, model
print(f"Training model")
X, y, model = get_Xy_and_model(stock)
Xs, ys, model = X, y, model
- 模型预测
# 传入两个参数即可线上测试:model模型、get_features函数
env = jpx_tokyo_market_prediction.make_env()
iter_test = env.iter_test()
for (df_test, options, financials, trades, secondary_prices, df_pred) in iter_test:
df_pred['row_id'] = (df_pred['Date'].astype(str) + '_' + df_pred['SecuritiesCode'].astype(str))
df_test['row_id'] = (df_test['Date'].astype(str) + '_' + df_test['SecuritiesCode'].astype(str))
x_test = get_features(df_test)
y_pred = model.predict(x_test)
df_pred['Target'] = y_pred
df_pred = df_pred.sort_values(by = "Target", ascending = False)
df_pred['Rank'] = np.arange(0,2000)
df_pred = df_pred.sort_values(by = "SecuritiesCode", ascending = True)
df_pred.drop(["Target"], axis = 1)
submission = df_pred[["Date", "SecuritiesCode", "Rank"]]
env.predict(submission)
完成测试集的预测,接下里就可以提交了。如下图所示,注意要将Internet关闭后,代表离线模式,保存版本,在比赛界面上就可以submit submission了。
优化方法:
- 关联更多的数据表,2 赛题数据部分 已经指出了
- 构建更多有意义的特征工程
- 时序模型的优化使用
















 1988
1988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











