







numpy基础
数据类型
| 名称 | 描述 | 字符码 |
|---|---|---|
| np.bool | ‘b’ | |
| np.int8 | ‘i’ | |
| np.int16 | short | 'i2‘ |
| np.int32 | int | ‘i4’ |
| np.int64 | long long | ‘i8’ |
| np.uint8 | ‘u’ | |
| np.uint16 | ‘u2’ | |
| np.uint32 | ‘u4’ | |
| np.uint64 | ‘u8’ | |
| np.float16 | ‘f2’ | |
| np.float32 | float | ‘f4’ |
| np.float64 | double | ‘f8’ |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | ‘c8’ |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | ‘c16’ |
| np.object_ | python对象 | ‘O’ |
| np.string_ | 字符串 | ‘S’ |
| np.unicode_ | unicode类型 | ‘U’ |
数组创建
array , arange
array : 生成ndarray的数组
arange : python中的range
np.array(list) # (列表)
np.array(list,np.int32) # (列表,类型)
np.arange(1,30,2) # 产生一个数组,返回值是ndarray (开始,结束-1,步长)
zeros , ones , empty
zeros : 生成一个给定shape的全是0的数组
ones : 生成一个给定shape的全是1的数组
empty : 生成一个为初始化 , 随机的一个数组 , 因为没有初始化 , 所以速度很快
这三个数组默认的数据格式都是浮点型
np.zeros((2,3,4)) # 生成 (2,3,4) shape的数组
np.zeros((2,3,4),np.int32) # 定义数组的类型
#三个函数的使用方法是一样的
randn , randint
random.randn : 生成n个符合正态分布的数 , 标准差为1 , 均值为0
random.randint : 生成一个指定范围的大小为shape的数组
np.random.randn(100) # n
np.random.randint(1,20,(3,4)) # [l,r) 和 shape 注意不包括右区间
数组基本属性
| 函数 | 描述 |
|---|---|
| ndim | 数组一共有多少个维度 |
| shape | 数组的形状是什么 , 返回一个元组 |
| dtype | 数据的类型 |
| size | 一共占有多少位置 , 也就是shape的乘积 |
| itemsize | 一个单位占有多少的空间 |
| nbytes | 一共占有多少的内存空间 |
| T | 矩阵转置 |
| flat | 扁平迭代器 |
自定义复合类型
data = [("zyy",[10,20,30,40],18),("lzb",[10,22,13,53],19)]
第一种方式
a = np.array(data,"U3,4int32,int32")
第二种方式
a = np.array(data,{'names': ['name', 'scores', 'ages'],
'formats': ['U3', '4int32', 'int32']})
print(a[0]['name'],'is',a[0]['ages'],'years old')
# 将定义过的names作为第二索引,第一索引为第二索引的哪一个
print('partial score is:',a[0]['scores'][0],a[0]['scores'][1])
# 再在最后加上一个第三索引,就是访问这个列表的第几个
数组操作
形状
reshape
reshape : 不改变数据的情况下修改形状
a = np.arange(12).reshape(3,4)
a = a.reshape(3,4) # 注意reshape是有返回值的
flat , ravel
flat : ndarray的扁平迭代器
ravel : 得到ndarray的扁平数组的函数
a = np.arange(12).reshape(3,4)
for i in a.flat: # 等价于 for i in a.ravel():
print(i,end=',')
# 0,1,2,3,4,5,6,7,8,9,10,11
a.flat # <numpy.flatiter>
a.ravel() # [ 0 1 2 3 4 5 6 7 8 9 10 11]
维度
swapaxes
swapaxes : 交换维度
a = np.arange(60).reshape(3,4,5)
print(a.shape) # (3,4,5)
a = a.swapaxes(0,2)
print(a.shape) # (5,4,3)
expand_dims , squeeze
expand_dims : 在指定位置插入新的轴扩展维度
squeeze : 去掉所有为1的维度
x = np.arange(12).reshape(3,4)
x = np.expand_dims(x,0) # (1,3,4)
x = np.expand_dims(x,1) # (3,1,4)
x = np.expand_dims(x,2) # (3,4,1)
y = np.arange(12).reshape(1,1,3,1,4,1)
x = np.squeeze(y) # (3,4)
修改
tile , broadcast_to
tile : 将数组复制多次 , 相当于matlab的repmat
broadcast_to : 对数组进行扩展 , 不如tile好用…
x = np.array([[1,2],[3,4]])
x = np.tile(x,(3,4)) # (3,4) 意思为最后为3*4的块
# [1 2 1 2 1 2 1 2]
# [3 4 3 4 3 4 3 4]
# [1 2 1 2 1 2 1 2]
# [3 4 3 4 3 4 3 4]
# [1 2 1 2 1 2 1 2]
# [3 4 3 4 3 4 3 4]
y = np.arange(4)
print(np.broadcast_to(y,(2,4))) # 写(4,2)报错,原有的放后面
# [0 1 2 3]
# [0 1 2 3]
concatenate,split
concatenate : 按照维度连接两个数组
split : 按照维度分割数组
x = np.zeros((2,2,2),np.int32)
y = np.ones((2,2,2),np.int32)
z = np.concatenate((x,y),0) # (4,2,2)
z = np.concatenate((x,y),1) # (2,4,2)
z = np.concatenate((x,y),2) # (2,2,4)
x = np.arange(9)
y = np.split(x,3) # 将x平均分成3份
# [array([0, 1, 2]), array([3, 4, 5]), array([6, 7, 8])]
[a,b,c] = b # 类似matlab的方法来处理
b = np.split(a,[4,7]) # 按照位置(索引前,也就是个数)来分割
# [array([0, 1, 2, 3]), array([4, 5, 6]), array([7, 8])]
a = np.arange(12).reshape(3,4)
b = np.split(a,[1],1) # 第三个参数是维度
#[[0] [[1 2 3]
# [4] + [5 6 7]
# [8]] [9 10 11]]
append , insert
append : 向数组中加入新的元素
insert : 向数组指定位置加入新的元素
a = np.arange(12).reshape(3,4)
b = np.arange(6).reshape(3,2)
c = np.append(a,b) # 未定义维度时返回一维数组
#[0,1,2,3,4,5,6,7,8,9,10,11,0,1,2,3,4,5
c = np.append(a,b,1) # 当前维度之外的必须相同
#[[ 0 1 2 3 0 1]
# [ 4 5 6 7 2 3]
# [ 8 9 10 11 4 5]]
a = np.arange(6).reshape(2,3)
b = np.insert(a,1,[666,666],axis = 1) # 未定义维度时返回一维数组
#[[0 666 1 2]
# [3 666 4 5]]
delete
delete : 删除数组指定位置的元素
a = np.arange(6)
a = np.delete(a,3) # 删除指定的下标的数字
# [0 1 2 4 5]
a = np.arange(12).reshape(3,4)
b = np.delete(a,1,0) # 删除第一行
b = np.delete(a,0,1) # 删除第零列
b = np.delete(a,np.s_[1:3],1) # np.s_[1:3] -> slice(1,3)
#[[0 3]
# [4 7]
# [8 11]]
unique
unique : 去重 , 参数可选
a = np.random.randint(1,6,(3,3))
[new_array,first_index,construct,cnt] = np.unique(a,1,1,1)
# a = [[3 5 5]
# [3 3 2]
# [3 4 3]]
# new_array:去重剩下的一维数组
# [2 3 4 5]
# first_index:将数组拍平之后第一次出现的索引
# [5 7 0 1]
# construct:根据这个可以重建拍平的原数组,数字是对应new_array的第几个
# [1 3 3 1 1 0 1 2 1]
# cnt:每一个数字出现了多少次
# [1 5 1 2]
排序
sort
sort : 将数组排序,可选’quicksort’(默认,快排),‘mergesort’(归并),‘heapsort’(堆排)
a = np.array([[3,7],[9,1]])
np.sort(a)
#[[3 7]
# [1 9]]
np.sort(a,axis=0,kind='mergesort')
#[[3 1]
# [9 7]]
type = np.dtype([('name','U10'),('age',int)])
a = np.array([('zyy',18),('zk',18),('lzb',19)],dtype=type)
b = np.sort(a,order = 'name')
# [('lzb', 19) ('zk', 18) ('zyy', 18)]
argsort
argsort : 得到排序之后的下标
x = np.array([1,5,4,2,6,3])
y = np.argsort(x) # [0 3 5 2 1 4]
x[y] # [1 2 3 4 5 6]
# 同样支持 axis kind order
lexsort
lexsort : 对于多个数组进行排序
math = [10, 20, 50, 10]
chinese = [30, 50, 40, 60]
total = [40, 70, 90, 70]
# 将优先级高的项放在后面
ind = np.lexsort((math, chinese, total))
for i in ind:
print(total[i],chinese[i],math[i])
# 40 30 10
# 70 50 20
# 70 60 10
# 90 40 50
# 还可以添加 axis
numpy操作
定义 :
- 切片 : 将一个数组分割成一块
- 索引 : 索引数组中的某一个位置
切片
a = np.arange(1,10) # 一维
# [1 2 3 4 5 6 7 8 9]
print(a[0:3]) # [1 2 3]
print(a[::-1]) # [9 8 7 6 5 4 3 2 1]
print(a[-1:-3:-1]) # [9 8]
a = np.arange(1,13).reshape(3,4) # 二维
# [1 2 3 4]
# [5 6 7 8]
# [9 10 11 12]
print(a[1:3,1:3])
# [6 7]
# [10 11]
a = np.arange(1,28).reshape(3,3,3) # 三维
print(a[1:,1:3,1:3])
# ...
索引
基础索引
a = np.arange(1,13).reshape(3,4)
a[2][3] # 12 同 c++ 索引方式
数组索引
输出一维数组 :
a = np.arange(1,13).reshape(3,4)
# [ 1, 2, 3, 4]
# [ 5, 6, 7, 8]
# [ 9, 10, 11, 12]
a[[2,1,0],[3,2,1]] # [12 7 2]
# 第一个列表是第一个维度
# 第二个列表是第二个维度
输出多维数组 :
a = np.arange(1,13).reshape(3,4)
# [ 1, 2, 3, 4]
# [ 5, 6, 7, 8]
# [ 9, 10, 11, 12]
rows = np.array([[0,0],[2,2],[0,2]])
cols = np.array([[0,3],[0,3],[2,1]])
print(a[rows,cols])
# [1 4]
# [9 12]
# [3 10]
布尔索引
由布尔索引可以过滤掉一些我们不想要的元素
a = np.arange(1,13).reshape(3,4)
b = np.arange(1,21)
a[a>6] # a>6 为一个判断矩阵
# [9 10 11 12]
花式索引
按照指定顺序索引一片区域
x = np.arange(32).reshape(8,4)
#0 [ 0 1 2 3]
#1 [ 4 5 6 7]
#2 [ 8 9 10 11]
#3 [12 13 14 15]
#4 [16 17 18 19]
#5 [20 21 22 23]
#6 [24 25 26 27]
#7 [28 29 30 31]
x[[4,2,1,7]] # 也就是第四,二,一,七行
# [16 17 18 19]
# [ 8 9 10 11]
# [ 4 5 6 7]
# [28 29 30 31]
x[np.ix_([4,2,1,7],[3,1,0,2])] # 上述的行,规定一个列的顺序,注意,要加上ix_
# 等价于 x[[[4],[2],[1],[7]],[[3,1,0,2]]]
# [19 17 16 18]
# [11 9 8 10]
# [ 7 5 4 6]
# [31 29 28 30]
迭代
使用迭代器nditer,迭代的顺序就是存储的顺序
a = np.arange(8).reshape(2,2,2)
for x in np.nditer(a): # 默认行序优先
print (x,end=",")
# 0,1,2,3,4,5,6,7,
# 列序优先:np.nditer(a,order='C')
# 行序优先:np.nditer(a,order='F')
在迭代中修改元素需要传入参数 , 默认是不修改的
a = np.arange(1,11).reshape(2,5)
cnt=10
for i in np.nditer(a,op_flags=['readwrite']):
i[...]=cnt # i[...] 是修改原numpy元素,i只是个拷贝。
cnt+=1
numpy运算
广播
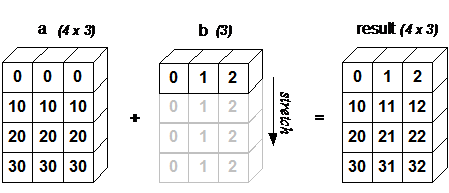
规则 : b有一维shape为1,其他的都和a一样 , 然后就会按照缺失的维度复制
x = np.arange(168).reshape(3,4,2,7)
y = np.arange(84).reshape(3,1,2,7)
print(y.shape)
print(x.shape)
print(x*y)
numpy字符串
add
add :连接两个字符串
np.char.add(['hello'],['d3ac'])
# ['hellod3ac']
np.char.add([['a','b'],['c','d']],[['e','f'],['g','h']])
#[['ae' 'bf']
# ['cg' 'dh']]
multiply
multiply : 重复字符串多次
print(np.char.multiply('orzz ',6))
# orzz orzz orzz orzz orzz orzz
center
center : 使用特定字符串填充使得字符串居中
print(np.char.center('d3acorzz', 20,fillchar = '*'))
# (填充字串,填充之后总共的长度,填充字符)
# ******d3acorzz******
capitalize , title
capitalize : 函数将字符串的第一个字母转换为大写
title : 将字符串的每个单词的第一个字母转换为大写
print(np.char.capitalize('d3ac'))
# D3ac
print(np.char.capitalize('d3ac orzz qwq'))
# D3ac Orzz Qwq
lower ,upper
lower : 将每一个字符变成小写
upper : 将每一个字符变成大写
print(np.char.lower('D3AC'))
# d3ac
print(np.char.lower('d3ac'))
#D3AC
split
split : 按照指定的字符对字符串进行分割 , 默认按照空格
print(np.char.split('d3ac orzz qwq',seq=' '))
# ['d3ac','orzz','qwq']
strip
strip : 去除字符串开头和结尾处的特定的字符
print(np.char.strip('@d3ac @eat food@@','@'))
# d3ac @eat food
print(np.char.strip(['@d3ac','@eat','food@@'],'@'))
# d3ac eat food
join
join : 在字符串中间加入指定字符
print(np.char.join('-','d3ac'))
# 'd-3-a-c'
print(np.char.join(['-','+'],['d3ac','orzz']))
# ['d-3-a-c','o+r+z+z']
replace
replace : 将指定的字符串’x’替换成指定的’y’
print(np.char.replace('i want to eat food','i','you'))
# 'you want to eat food'
numpy 统计
sum
sum : 求一个数组的和 , 可以添加维度
list = np.arange(1,25).reshape(2,4,3)
# [ 1, 2, 3]
# [ 4, 5, 6]
# [ 7, 8, 9]
# [10, 11, 12]
# [13, 14, 15]
# [16, 17, 18]
# [19, 20, 21]
# [22, 23, 24]
np.sum(list) # 所有元素的和
# 300
np.sum(list,axis = 0) # 第一维度
# [14, 16, 18],
# [20, 22, 24]
# [26, 28, 30]
# [32, 34, 36]
np.sum(list,axis = 1) # 第二维度
# [22, 26, 30]
# [70, 74, 78]
np.sum(list,axis = 2) # 第三维度
# [ 6, 15, 24, 33]
# [42, 51, 60, 69]
amin , amax
amin : 求数组指定范围的最大值
amax : 求数组指定范围的最大值
a = np.random.randint(1,100,(3,4,5))
print(np.amin(a,axis = 0))
# 返回值是一个(4,5)的矩阵,最小值是在(3)里面取的
# 也就是shape为(a1,a2...ak...an)的ndarray
# 返回矩阵形状是(a1,a2...ak-1,ak+1...an)
# 这个矩阵每一个地方的最小值就是(ak)个数字的最小值
print(np.amin(a)) # 所有值的最小值
a = np.random.randint(1,100,(6,4))
print(np.amin(a),axis=0) # 列最小值
print(np.amin(a),axis=1) # 行最小值
# 最大值同理
ptp
ptp : 返回最大值与最小值的差
a = np.random.randint(1,100,(3,4,5))
print(np.ptp(a,axis = 0)) # 规则同amin
percentile
percentile : 得到百分位数 , (假设百分位数为78,百分数为 34%,表示有34%的数据小于78) , 将百分数设置为50可以得到中位数
a = np.arange(71,81)
print(np.percentile(a,70)) # 77.3
print(np.percentile(a,50)) # 75.5
print(np.percentile(a,95)) # 79.55
# 可以添加维度
median
median : 计算中位数
a = np.arange(71,81)
print(np.median(a)) # 75.5
# 可以添加维度
mean , average
mean : 求算术平均值
average : 带权平均值 ∑ i n x i w i ∑ i n w i \frac{\sum_i^nx_iw_i}{\sum_i^nw_i} ∑inwi∑inxiwi , 不输入权值参数等价于mean
a = np.arange(1,6)
[ans,wight_sum] = np.average(a,axis = 0,weights = [1,4,2,3,3],returned = 1)
# (3.23, 13.0)
# 最好填上axis,wights,returned
a = np.mean(a)
# 可以添加维度
*std , var
std : 求标准差
var : 求方差
def std(x):
return np.sqrt((np.mean((x-np.mean(x))**2)))
a = np.arange(12).reshape(3,4)
np.sqrt(a.var()) # 标准差还可以这样
a.var() # 方差
numpy矩阵
numpy 之前的都是ndarray的类型,其实numpy还有一个matrix类型 , numpy.matrix里面的函数和numpy里面的大同小异,只是换了一个名字而已
import numpy.matrix as mp
matmul , dot
matmul : 两个矩阵相乘
dot : 两个矩阵相乘(点积) , 和matmul是一样的
mp.matmul(a,b)
np.matmul(a,b)
np.dot(a,b)
vdot
vdot : 将数组展开计算内积
a = np.array([[1,2],[3,4]])
b = np.array([[11,12],[13,14]])
print (np.vdot(a,b))
# 1*11 + 2*12 + 3*13 + 4*14 = 130
identity
identity : 产生一个单位矩阵
mp.identity(5,dtype=int) # 5*5的单位矩阵
inner
inner : 两个向量的内积
print (np.inner(np.array([1,2,3]),np.array([0,1,0])))
# 等价于 1*0+2*1+3*0
a = np.array([[1,2], [3,4]])
b = np.array([[11, 12], [13, 14]])
print (np.inner(a,b))
#[[35 41]
# [81 95]]
# 1*11+2*12, 1*13+2*14
# 3*11+4*12, 3*13+4*14
det
det : 计算行列式的值
np.linalg.det(a)
eigvals
eigvals : 计算特征值,特征向量
a = [[3,55,6],[53,2,1],[12,12,78]]
a = mp.array(np.array(a))
[x,y] = np.linalg.eig(a)
# x = [-51.49517142 53.12717933 81.36799209]
# y = [[ 7.10392515e-01 -5.78993762e-01 1.57595028e-01]
# [-7.03805444e-01 -5.89179368e-01 1.17591660e-01]
# [-6.10407693e-04 5.63590184e-01 9.80477439e-01]]
# 在matlab中
# [x,y] = eig(a)
# x 即为上式的y
# y 即为上式的x分布在对角线上
# -51.4952 0 0
# 0 53.1272 0
# 0 0 81.3680
numpy IO
save , savez , load
save : 将一个数组保存在npy文件里
savez : 将多个数组保存在npy文件里
load : 读入save , savez过的文件
np.save('data.npy',a)
np.save('data',a) # 后缀会自动加上
np.save('C:\\Users\\d3ac\\Desktop\\temp\\data.npy',a)
# 读入
b = np.load('data.npy') # 注意不能省略后缀
a = np.array([[1,2,3],[4,5,6]])
b = np.arange(0, 1.0, 0.1)
c = np.arange(12).reshape(3,4)
np.savez('data.npz',a,b,c) # 保存多个数组
# 也可以给每一个数组取名
# np.savez('data.npz',data_a=a,data_b=b,data_c=c)
# 每个数组前面的那个赋值的 'data_x'就是取的名字
# 读入
file.files # 一共保存了哪些数组,这些数组的名字是什么
file[file.files[0]] # a
file[file.files[1]] # b
file[file.files[2]] # c
# 或者
file['arr_0'] # a
file['arr_1'] # b
file['arr_2'] # c
# 这是因为没有取名字的原因,所以会自动取名为arr_0...n
savetxt , loadtxt
savetxt : 以txt类型保存文件
loadtxt : 以txt类型读取文件 , 没有load快
a = np.arange(12).reshape(3,4)
np.savetxt("data.txt",a,fmt="%d",delimiter=',')
# 需要设置格式和间隔的符号,默认格式为float,符号为空格
b = np.loadtxt("data.txt",delimiter=",")
其他函数
shuffle
shuffle : 打乱数组 , 如果是一维的 , 那么就全部打乱 , 如果是二维的 , 那么就打乱第一维 , 以此类推
a = np.arange(1,21).reshape(4,5)
# [ 1 2 3 4 5]
# [ 6 7 8 9 10]
# [11 12 13 14 15]
# [16 17 18 19 20]
np.random.shuffle(a) # 返回值是 None
# [ 1 2 3 4 5]
# [16 17 18 19 20]
# [11 12 13 14 15]
# [ 6 7 8 9 10]
around
around : 将指定的数组四舍五入到某一位
a = np.array([5.55,0.567])
np.around(a,1)
# [5.6,0.57]
np.around(a,-1)
# [10.,0.]
reciprocal
reciprocal : 得到数组每一个数字的倒数
a = np.array([1,0.25,8])
print(np.reciprocal(a))
# [1. 4. 0.125]
*random_shuffle
random_shuffle : 打乱二维数组的所有数据
def random_shuffle(a):
This_shape = a.shape
a = a.reshape(1,a.size)[0][:]
np.random.shuffle(a)
print(type(a))
a = np.array([a,])
a = a.reshape(This_shape[0],This_shape[1])
return a
where , extract
where : 返回给定条件元素的索引
extract : 按条件提取元素
a = np.random.randint(1,11,(3,4))
#[[1 2 8 2]
# [7 9 9 4]
# [1 8 7 3]]
np.where(a>4)
#(array([0, 1, 1, 1, 2, 2], dtype=int64), array([2, 0, 1, 2, 1, 2], dtype=int64))
# 返回了两个array,前面的是0轴,后面的是1轴
a[b]
# [8 7 9 9 8 7]
x = np.arange(9).reshape(3,3)
condition = (x%2 == 0)
#[[ True False True]
# [False True False]
# [ True False True]]
np.extract(condition, x)
# [0 2 4 6 8]
astype
astype : 改变数组的数据类型
x = np.arange(9)
print(type(x[0])) # int32
x = x.astype(np.float32) # z
print(type(x[0])) # float32















 5671
5671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











