







*** 2017 ICCV 3DSTN ***
#Abstract
为了在大的位姿中提取一致的对齐点,必须在对齐步骤中考虑面部的3D结构。然而,从单个2D图像中提取3D结构通常首先需要对齐。文章提出了一种新颖的方法,即通过三维空间变压器网络(3DSTN)同时提取人脸的三维形状和语义一致的二维对齐,从而对摄像机投影矩阵和三维模型的翘曲参数进行建模。通过使用一个通用的3D模型和一个(TPS)翘曲函数,能够生成受试者特定的3D形状,而不需要一个大的3D形状基础。
Introduction
为了处理大范围的姿态变化,有必要利用人脸的三维结构信息。然而,现有的许多三维人脸建模方案存在计算时间和复杂度等诸多不足。在文章中使用一个简单平均形状以变形到输入图像,以相对较低的计算成本生成相当准确的三维模型。
Contributions
1.
采用一个简单的平均形状,并通过对图像进行对齐来使用该形状的参数化、非线性翘曲,从而能够对任何不可见的示例进行建模。
2.有效地实现在一个端到端的深度学习框架,允许对齐和3D建模任务是相互依存的
3.
实现更快的实时处理图像与最先进的性能超过其他2D和3D方法的对齐。
3D Spatial Transformer Networks
TPS和摄像机参数作用:
(这里首先说一下这两个参数的作用,便于理解文章)TPS参数可用于扭曲人脸模型,以匹配网络估计的真实三维形状,而摄像机投影参数可用于从二维图像纹理三维坐标。此外,面部的姿态可以通过相机参数来确定,从而为3D模型生成可视化地图。这允许我们只使用图像中可见的纹理顶点,而不是被脸部本身遮挡的顶点。
Camera Projection Transformers
简而言之即是:由众所周知的摄像机投影方程表示的三维点映射到摄像机坐标的建模;数学公式表示如下:pc是相机中2d坐标点,pw是世界坐标系中3d点。M是3 X 4的相机投射矩阵。
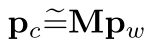
文章中的对每一个坐标点求梯度(求导)的公式较易理解,这里不在多叙述了,大家应该很容易就看明白了。
3D Thin Plate Spline Transformers
TPS参数将从深度网络中估计出来并作为输入传递给三维网格生成器模块。
一个点(x,y,z)中仅x坐标位置的3D TPS函数表示如下(y,z处同理):

经过此函数以后会输出一个新的3D点。
Warped Camera Projection Transformers
TPS之后(上一步骤)的新3d点作为输入传进这一模块,再对这些新的3D点进行相机投射修正其相应的2d点。(对3D点反传求导)。
2D Landmark Regression
为了进一步提高标记点精度,通过标记点细化阶段来扩展网络。此阶段将来自前阶段的投影2D坐标视为初始点,并估采用另一回归模块来计算每个点的偏移量,得到其相应的点坐标。
3D Model Regression From 2D Landmarks
由于上一步骤之后2点坐标发生变化,即原先的3D模型与2d肯定不会相互对应了,为保持3d-2d之间的对应关系,对原3d model进行wrap得到新的3D点与回归后的2d点进行对齐。

好了,以上知识点了解以后,接下来便进入最重要的网络环节了
Network

1.首先看最上面即第一层,输入一张图片,经过基础卷积之后(蓝色块之前)进如了TPS网络估计TPS参数,利用估计出来的TPS参数,对generic 3Dmodel(可理解为3DMM中的平均model)按照指定的参数进行扭曲。并输入下一层网络(2Dgrid generator module.);
2.下一层网络(2Dgrid generator module.)
在蓝色块之后采用Camera Projection 网络估计出相机参数,对上一层输入进来的投射,获取2d关键点,并当作初始化的点;
3.第三层网络在蓝色快之后又加了两层33和11的卷积对初始化的2d点(需要把上一层中的2D点输进来)进行feature map 采样,采用双线性插值法得到其偏移量δ x and δ y。进而将求得的偏移量与原来2d坐标值的进行相加得到其新的回归后的2d坐标;
ps:本人3D新人一枚,以上内容仅代表个人对文章的理解,如有不当之处还恳请各位指出。















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









