






 RandLA-Net是一种用于大规模点云语义分割的网络,通过随机采样和局部特征聚合模块处理高效率的点云数据。局部特征聚合包括局部空间编码、注意力池化和空洞残差块,分别用于捕捉局部几何模式、增强点特征和扩大感受野。代码实现中,这些模块被详细地用TensorFlow实现,包括寻找邻居点、相对位置编码和注意力分数计算等关键步骤。
RandLA-Net是一种用于大规模点云语义分割的网络,通过随机采样和局部特征聚合模块处理高效率的点云数据。局部特征聚合包括局部空间编码、注意力池化和空洞残差块,分别用于捕捉局部几何模式、增强点特征和扩大感受野。代码实现中,这些模块被详细地用TensorFlow实现,包括寻找邻居点、相对位置编码和注意力分数计算等关键步骤。
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds 论文阅读笔记
目录
一、 论文部分:
整体结构简单说就是:
RandLaNet= ⑴ random sampling + ⑵ local feature aggregator
第⑴部分,为了高效的对大的点云进行采样
第⑵部分,因为random sampling 会丢失一些点,以此做为增强
⑵ Local feature aggregator = ① local spatial encoding (LocSE) + ② attentive pooling + ③ dilated residual block
①有效的收集局部几何模式,因此增强整个网络有效的学习复杂的局部结构(编码),分为三步:finding neighbouring points; relative point position encoding; point feature augmentation。
②用来增强点p附近点的特征(聚集),分为两步:computing attention scores; weighted summation。
③大点云下采样,所以用来增强每一个点的感受野。这样输入的点云的几何细节可以观察到。
网络示意图:

图1 each layer of RandLA-Net

图2 RandLa-Net
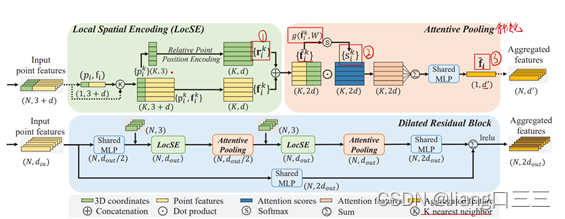
图3 local feature aggregation module
二、 代码部分:
Local Feature Aggregation
(1)Local Spatial Encoding
公式1:

在代码的RandLANet.py:
**①Finding Neighbouring Points **,论文中的KNN。就是代码中的gather_neighbour函数中(暂时是377行)。
②Relative Point Position Encoding
relative_feature = tf.concat([relative_dis, relative_xyz, xyz_tile, neighbor_xyz], axis=-1)
在代码的relative_pos_encoding函数中(暂时是324行)。代码中的relative_feature就是这里的r_i^k,把它记作: f_xyz 。
③Point Feature Augmentation,f ̂_ik=r_ik+f_i^k。 其中在代码的building_block函数中(暂时是第301行),f_neighbours就是论文中的f_i^k;# f_xyz就是论文中的r_i^k;f_concat就是论文中的f ̂_i^k。
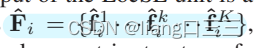
(2)Attentive Pooling
①Computing Attentive Scores
g()用来去学习每一个特征的一个unique的注意力分数

②Weighted Summation

f_reshaped = tf.reshape(feature_set, shape=[-1, num_neigh, d])
att_activation = tf.layers.dense(f_reshaped, d, activation=None, use_bias=False, name=name + 'fc')
att_scores = tf.nn.softmax(att_activation, axis=1)
f_agg = f_reshaped * att_scores
f_agg = tf.reduce_sum(f_agg, axis=1)
f_agg = tf.reshape(f_agg, [batch_size, num_points, 1, d])
f_agg = helper_tf_util.conv2d(f_agg, d_out, [1, 1], name + 'mlp', [1, 1], 'VALID', True, is_training)
在代码的att_pooling函数中(暂时是393行)。其中tf.layers.dense()就是论文中的g()函数,它用于添加一个全连接层。
tf.layers.dense(
inputs, #层的输入
units, #该层的输出维度
activation=None, #激活函数
use_bias=True, #是否使用偏置项。
kernel_initializer=None, # 卷积核的初始化器
bias_initializer=tf.zeros_initializer(), # 偏置项的初始化器
kernel_regularizer=None, # 卷积核的正则化
bias_regularizer=None, # 偏置项的正则化
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True, #表明该层的参数是否参与训练。
name=None, # 层的名字
reuse=None # 是否重复使用参数
)
论文中的f ̂_i^k 是代码中的f_reshaped;论文中的s_i^k是代码中的att_scores。所以最后代码中的f_agg就是论文中的f ̃_i。
(3)Dilated Residual Block
在dilated_res_block函数中(暂时是第286行)。在这篇文章中,堆叠了两层LocSE 和 Attentive Pooling。

















 3412
3412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









