







 MVIN是SIGIR2020会议上提出的一种推荐系统,它通过用户-实体和实体-实体交互来丰富项目表示。模型包括面向用户的关系注意力和实体投影模块,以及混合层以捕获高阶连接信息。实验表明,MVIN在电影、音乐和图书推荐数据集上表现出色,优于基于矩阵分解、图卷积和路径方法的基线。消融实验验证了用户导向信息、KG增强信息和混合层的重要性。
MVIN是SIGIR2020会议上提出的一种推荐系统,它通过用户-实体和实体-实体交互来丰富项目表示。模型包括面向用户的关系注意力和实体投影模块,以及混合层以捕获高阶连接信息。实验表明,MVIN在电影、音乐和图书推荐数据集上表现出色,优于基于矩阵分解、图卷积和路径方法的基线。消融实验验证了用户导向信息、KG增强信息和混合层的重要性。
MVIN: Learning Multiview Items for Recommendation
概述
本文发布于SIGIR 2020
作者为来自台北中央研究院的 Tai Chang-You, Wu Meng-Ru 团队
代码链接:https://github.com/johnnyjana730/MVIN
原文链接:https://arxiv.org/pdf/2005.12516.pdf
从用户视图来看,面向用户的模块根据包含用户点击信息的异构知识图实体对特性进行评分和聚合,从而从个性化的角度提出建议。从实体视图来看,混合层对比各层的图神经网络信息,进一步从异构知识图(KG)内部实体-实体交互中获得综合特征
在现实世界中,每个用户对给定的项目都有不同的看法视图(views),在实体视图中,项目表示由异构知识图(KG)中连接到它的实体来定义的。这也对应了多视图的两大问题:如何丰富用户视图Graph,如何细化实体视图Graph。论文提出的MVIN,从user和item来学习多个视角下的商品表示,进而进行商品推荐
Introduction
和很多其他具有大量数据的实际应用一样,推荐系统(RSs)也能从深度神经网络中受益匪浅。基于矩阵分解[1]的协同过滤(CF)是最成功的推荐方法之一。然而基于CF的方法依赖于用户和项目过去的交互,这会导致冷启动问题[2],使用该种方法,没有交互的项目永远不会被推荐。为了缓解这一问题,现在更多的研究在整合辅助信息,比如社交网络[3],图片[4]和评论[5]
在众多辅助信息中,Knowledge Graph (以下简称为KGs) 以机器可读的 实体-关系-实体 三元组的形式包含丰富的信息,得到了广泛的应用。目前KGs已经在节点分类,句子补全和摘要生成等应用中陆续被使用。比如RippleNet[6]会传播用户在KG中的潜在偏好,并探索他们的层次兴趣。也有很多产品采用KG图卷积网络(GCN)[7],该网络被合并到GNN中以生成高阶项连通性。然而该种网络仍然有缺点,比如缺少不同层实体之间的比较
总体而言,基于GNN的推荐模型仍然面临挑战:user-view GNN enrichment(浓缩) 和 entity-view GCN refinement(精炼)。这篇论文研究了基于GNN的推荐,并提出了一种能满足上述两种挑战的网络。提出的知识图多视图项目网络MVIN,是一种基于GNN的推荐模型,该模型具有用户-实体和实体-实体交互模块
为了丰富用户和实体的交互,该模型首先学习了KG增强的用户表示,使用它面向用户的模块表征了每个实体之间关系的重要性和信息性
为了优化实体与实体之间的交互,该论文提出了一个混合层来进一步改进GCN聚合实体的嵌入,并允许MVIN从各个层的邻域特征中捕获混合的GCN信息
此外,为了保持计算效率和接近整个邻域的全景,本论文采用了分阶段策略[8]和采样策略[9,10]来更好地利用KG信息
论文贡献包括:
- 启用用户视图和个性化GNN
- 通过广泛和深入的GCN从实体视图中提炼项目嵌入,这为高阶连接带来了层次上的差异
- 通过真实数据集证明了MVIN具有的鲁棒性和优势,证明了该模型可以捕获识别用户兴趣的实体
相关工作
KG-aware Recommendation models
除了基于图神经网络(GNN)的方法外,还有另外两类KG-aware推荐
第一种是基于嵌入的方法,将KG的实体和关系结合到连续的向量空间中,然后通过增强语义表示对推荐系统进行辅助。比如,DKN[11]融合了新闻的语义级和知识级表示,并将KG表示合并到新闻推荐中。此外CKE[4]将CF模块与结构化的、文本的和可视化的知识组合成为一个统一的推荐扩展。然而这些机遇嵌入的知识图嵌入算法(KGE)更加适合于图内应用,比如链路预测
第二种是基于路径的方法,利用元路径和相关用户-物品对,探索KG中物品之间的连接模式。例如MCRec[12]在推荐中学习元路径的显式表示。此外,还考虑了元路径和用户-项目对之间的相互影响。与基于嵌入的方法相比,基于路径的方法直接使用图算法,更自然,直观的挖掘KG结构。然而,他们严重依赖元路径,这需要相关的领域知识和手工处理,因此不适合端到端的training
User-Item Interaction
由于用户和项目是推荐中设计的两个主要实体,许多研究都试图通过研究用户和项目之间的交互来提高推荐性能
例如[9]提出的KGCN,它表征了关系对用户的重要性。而KGCN中的聚合方法没有考虑与用户不同的实体的信息量。[13]提出了MCRec,它考虑了用户对元路径的不同偏好,却忽略了与用户关系的语义差异。此外,由于这两种方法不使用GCN,因此关于高阶连接的信息是有限的
[14]认为用户通常既有长期偏好又有短期兴趣,因此提出了LSTUR,该模型将用户表示添加到GRU中,以捕获用户个人的长期和短期兴趣
MVIN介绍
用户和项目的集合表示为 U = { u 1 , u 2 ⋯ } U=\{u_1,u_2 \cdots\} U={ u1,u2⋯}和 V = { v 1 , v 2 ⋯ } V=\{v_1,v_2 \cdots\} V={ v1,v2⋯},用户项交互矩阵根据隐式用户反馈定义为 Y = { y u v ∣ u ∈ U , v ∈ V } Y=\{y_{uv}|u\in U, v \in V\} Y={ yuv∣u∈U,v∈V}。如果观察到用户u和物品v之间存在交互作用,则 y u v y_{uv} yuv记录为 y u v = 1 y_{uv}=1 yuv=1,否则为 y u v = 0 y_{uv}=0 yuv=0
为了提高推荐质量,使用知识图 G G G中的信息。知识图由实体-关系-实体三元组 { ( h , r , t ) ∣ h , t ∈ ε , r ∈ R } \{(h,r,t)|h,t \in \varepsilon, r \in R \} { (h,r,t)∣h,t∈ε,r∈R},这个三元组描述从头实体 h h h到尾实体 t t t的关系 r r r, ε \varepsilon ε和 R R R表示G中实体和关系的集合
一个项目 v ∈ V v\in V v∈V可以与G中的一个或者多个实体 e e e相关联; N ( v ) N(v) N(v)指的是v周围的相邻实体。鉴于交叉矩阵Y和知识图G,该文试图预测是否用户u存在对项目v的潜在兴趣。最终目标是学习预测函数 y ^ u v = F ( u , v , Θ ) \hat{y}_{uv}=F(u,v,\Theta) y^uv=F(u,v,Θ),其中 y ^ u v \hat{y}_{uv} y^uv是用户u与项目v有交互的概率, Θ \Theta Θ为函数 F F F的模型参数
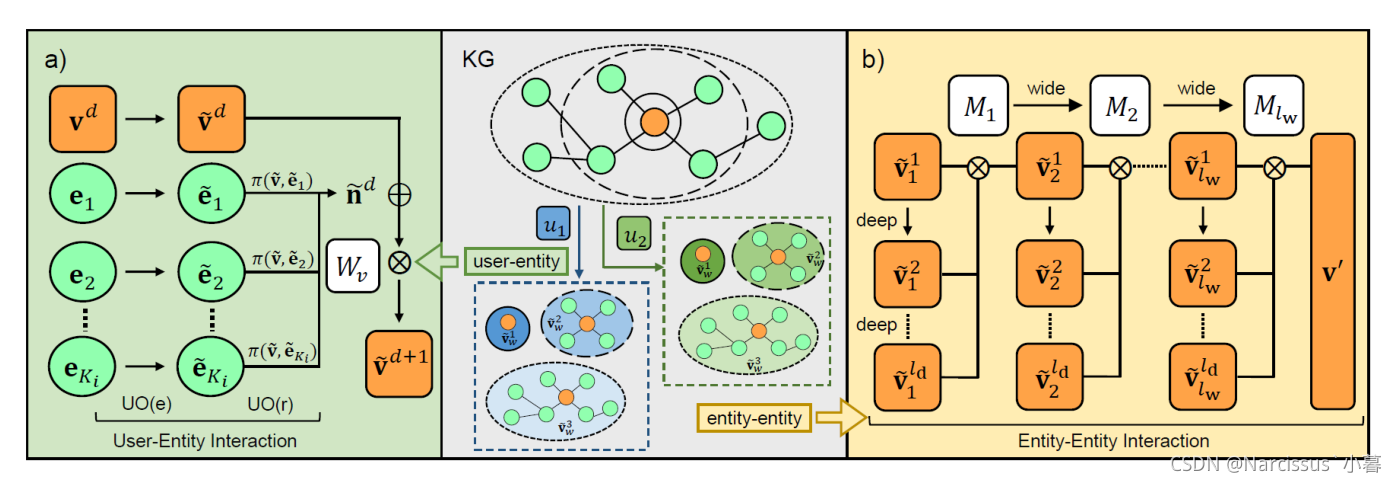
MVIN框架,通过用户-实体和实体-实体交互增强了项目表示
对于用户-实体交互,包含(a)面向用户的关系注意 U O ( r ) UO(r) UO(r)和实体投影模块 U O ( e ) UO(e) UO(e),从用户的角度收集KG实体信息
对于实体-实体交互,混合层允许MVIN不仅使用(a)聚合高阶连接信息,并且(b)按层混合GCN信息
1. user-entity interaction (模型目的之一为丰富用户-实体交互)
为了提高面向用户的性能,我们将用户实体交互分为面向用户的关系关注、面向用户的实体投影和kg增强的用户表示
用户和物品定义为 U = { u 1 , u 2 , … } , V = { v 1 , v 2 … } U=\{ u_1,u_2, \dots\} , V=\{ v_1,v_2 \dots \} U={ u1,u2,…},V={ v1,v2…}
三元组为 { ( h , r , t ) ∣ h , t ∈ ε , r ∈ R } \{ (h,r,t)|h,t \in \varepsilon, r \in \mathbb{R} \} { (h,r,t)∣h,t∈ε,r∈R}
1.1 user-oriented relation attention 面向用户的关系注意力
当MVIN从KG中给定商品的邻域收集信息时,它会以用户特有的方式为该商品的某个关系打分。所提出的面向用户的关系注意力机制利用给定用户、产品和关系的信息来确定连接到该产品的哪个邻居信息更加丰富。因此,领域的每个实体权重由分数 π r v , e u \pi_{r_{v,e}}^u πrv,eu<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6024
6024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









