







前言
从卷积神经网络登上历史舞台开始,经过不断的改进和优化,卷积早已不是当年的卷积,诞生了分组卷积(Group convolution)、空洞卷积(Dilated convolution 或 À trous)等各式各样的卷积。今天主要讲一下深度可分离卷积(depthwise separable convolutions),这是 Xception 以及 MobileNet 系列的精华所在。而它最早是由Google Brain 的一名实习生 Laurent Sifre 于2013年提出,Sifre在其博士论文中对此进行了详细的分析和实验,有兴趣的可以去翻阅。
从 Inception module 到 depthwise separable convolutions
Xception 的论文中提到,对于卷积来说,卷积核可以看做一个三维的滤波器:通道维+空间维(Feature Map 的宽和高),常规的卷积操作其实就是实现通道相关性和空间相关性的联合映射。Inception 模块的背后存在这样的一种假设:卷积层通道间的相关性和空间相关性是可以退耦合的,将它们分开映射,能达到更好的效果(the fundamental hypothesis behind Inception is that cross-channel correlations and spatial correlations are sufficiently decoupled that it is preferable not to map them jointly.)。


以上的图中,Figure 1 是一个典型的 Inception 模块,它先在通道相关性上利用 1×1 卷积将输入的 Feature Map 映射到几个维度比原来更小的空间上,相当于每个通道图乘上不同的因子做线性组合,再用 3×3 卷积这些小空间,对它的空间和通道相关性同时做映射。以第二个分支为例,假设 Input 是 28×28×192 的 Feature Maps,在通道相关性上利用 32 个 1×1×192 的卷积核做线性组合,得到 28×28×32 大小的 Feature Maps,再对这些 Feature Maps 做 256 个 3×3×32 的卷积,即联合映射所有维度的相关性,就得到 28×28×256 的 Feature Maps 结果。可以发现,这个结果其实跟直接卷积 256 个3×3×192 大小的卷积核是一样。也就是说,Inception 的假设认为用 32 个 1×1×192 和 256 个 3×3×32 的卷积核退耦级联的效果,与直接用 256个 3×3×192 卷积核等效。而两种方式的参数量则分别为32×1×1×192 + 256×3×3×32 = 79872 和 256×3×3×192 = 442368。
Figure 2 是简化后的 Inception 模块(仅使用3×3卷积并去除 Avg pooling),基于 Figure 2 的简化模块可以将所有的 1×1 卷积核整合成一个大的 1×1 卷积,如将 3 组 32 个 1×1×192 的卷积核重组为 96个 1×1×192 的卷积核,后续再接3组 3×3卷积,3×3卷积的输入为前序输出的1/3(Figure 3)。Xception 论文进而提出在 Figure 3 的基础上,是否可以做出进一步的假设:通道相关性和空间相关性是完全可分的,由此得到 Figure 4 中的 “extreme” Inception。如 Figure 4 所示,先进行 1×1 的通道相关性卷积,后续接的 3×3 卷积的个数与 1×1 卷积的输出通道数相同。
Figure 4 中的 Inception 模块与本文的主角-深度可分离卷积就近乎相似了,但仍然存在两点区别:
1、深度可分离卷积先进行 channel-wise 的空间卷积,再进行1×1 的通道卷积,Inception则相反;
2、Inception中,每个操作后会有一个ReLU的非线性激活,而深度可分离卷积则没有。
回过头来看一下从常规卷积 -> 典型的Inception -> 简化的Inception -> “极限”Inception,实际上是输入通道分组的一个变化过程。常规卷积可看做将输入通道当做整体,不做任何分割;Inception则将通道分割成3至4份,进行1×1的卷积操作;“极限”Inception则每一个通道都对应一个1×1的卷积。
引入深度可分离卷积的 Inception,称之为 Xception(Extreme Inception),其结构图如下,图中的SeparableConv即是深度可分离卷积,另外可以看出每个模块均采用残差连接(开头和结尾的几个除外):

Xception architecture
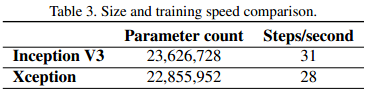
Xception 作为 Inception v3 的改进版,在 ImageNet 和 JFT 数据集上有一定的性能提升,但是参数量和速度并没有太大的变化,因为Xception 的目的不在于模型的压缩。下图是 ImageNet 上 1000 类分类网络的训练参数和训练速度对比:
MobileNet 中的 depthwise separable convolutions
MobileNet 是Google推出的一款高效的移动端轻量化网络,其核心即是深度可分离卷积。

按照前文所述,深度可分离卷积将传统的卷积分解为一个深度卷积(depthwise convolution)+ 一个 1×1的卷积(pointwise convolution)。如下图所示,(a)是传统卷积,(b)、©分别对应深度可分离卷积的深度卷积和 1×1的卷积:

假设输入特征图大小为 D_F×D_F×M,输出特征图大小为 D_F×D_F×N,卷积核大小为 D_K×D_K,则传统卷积的计算量为:
D_K×D_K×M×N×D_F×D_F
深度可分离卷积的计算量为深度卷积和 1×1 卷积的计算量之和:
D_K×D_K×M×D_F×D_F+M×N×D_F×D_F
深度可分离卷积与传统卷积的计算量之比为:
\frac{D_K×D_K×M×D_F×D_F+M×N×D_F×D_F}{D_K×D_K×M×N×D_F×D_F} = \frac{1}{N} + \frac{1}{D_K^2}
以上文中 28×28×192 的输入,28×28×256 的输出为例,卷积核大小为 3×3,两者的计算量之比为:
\frac{39889920}{346816512} = 0.1150
深度可分离卷积的计算量缩减为传统卷积的 1/9 左右。
下图是传统卷积(左)与MobileNet中深度可分离卷积(右)的结构对比。Depth-wise卷积和1×1卷积后都增加了BN层和ReLU的激活层。

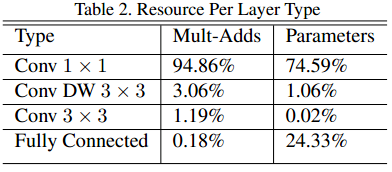
Deep-wise结合1×1的卷积方式代替传统卷积不仅在理论上会更高效,而且由于大量使用1×1的卷积,可以直接使用高度优化的矩阵相乘(如GEMM)来完成,并且1×1的卷积不需要im2col的预处理操作,大大提升运算效率。MobileNet 中有约95%的乘加运算来自1×1卷积(同时也占总参数量的75%):
MobileNet的整体结构如下图所示,共含有28个网络层:

为了满足模型更小、速度更快的应用需求,MobileNet 提出了宽度因子 \alpha 和分辨率因子 \rho两个超参数。前者用于控制输入输出的通道数,后者则用于控制输入输出的分辨率。加入超参数后的深度可分离卷积的计算量为:
D_K×D_K× {\alpha}M× {\rho}D_F× {\rho}D_F+ {\alpha}M× {\alpha}N× {\rho}D_F× {\rho}D_F
理论上,加入超参数后的计算量约为加入前的 \frac{1}{{\alpha}2*{\rho}2}:

Tensorflow 中 depthwise separable convolutions 接口
Tensorflow 里深度可分离卷积的实现代码位于python/ops/nn_impl.py文件中,函数接口为:
def separable_conv2d(input,
depthwise_filter,
pointwise_filter,
strides,
padding,
rate=None,
name=None,
data_format=None):
除去与实现无关的name和data_format两个参数外,其他6个参数:
input:4-D的 Tensor 输入,形如[batch, height, width, in_channels]
depthwise_filter:4-D的 Tensor,形如[filter_height, filter_width, >in_channels, channel_multiplier]。是深度卷积的卷积核。
pointwise_filter:4-D的Tensor,形如[1, 1, channel_multiplier * in_channels, out_channels]。是1×1卷积的卷积核。
strides:1-D Tensor,大小是4。深度卷积的滑动步长。
padding:边缘填充方式,string类型,值为VALID或SAME。
rate:1-D Tensor,大小是2。与实现空洞卷积相关的参数。
函数实现上,先通过with_space_to_batch接口进行depth-wise卷积,再调用conv2d进行1×1的卷积,最后返回4-D的输出Tensor。
MACE 中 depthwise separable convolutions 的实现
小米的MACE框架中,并没有depthwise separable convolutions的直接接口,但是有深度卷积(depthwise convolutions)的接口,在mace\kernel\depthwise_conv2d.h 中。
CPU版本的代码对于卷积和为(3,3),stride大小为(1,1)或(2,2)会进行NEON指令集加速,其他情况则通过DepthwiseConv2dGeneral接口实现。
作者:Kaami
链接:https://www.jianshu.com/p/38dc74d12fcf
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。














 7376
7376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









