






 本文探讨了Xception和MobileNet中使用的深度可分离卷积技术,并对比了这两种方法的目的和实现方式。此外,还详细介绍了Inception系列的发展历程及如何演变为Xception的基本结构。文中还讨论了残差连接的作用、ReLU的使用限制、全连接层的重要性以及未来的研究方向。
本文探讨了Xception和MobileNet中使用的深度可分离卷积技术,并对比了这两种方法的目的和实现方式。此外,还详细介绍了Inception系列的发展历程及如何演变为Xception的基本结构。文中还讨论了残差连接的作用、ReLU的使用限制、全连接层的重要性以及未来的研究方向。
1、
Xception和MobileNet都是采用depthwise separable convolution进行的,但是二者的目的是不同的,Xception使用depthwise separable convolution的同时增加了网络的参数量来比对效果,主要考察这种结构的有效性,MobileNet则是用depthwise separable convolution来进行压缩和提速的,参数量明显减少,目的也不在性能提升上面而是速度上面
2、
Inception出来的思路是channel上的关联和空间上的关联是可以解耦的,首先看一下Depthwise seperable convolution,在MobileNet中有提到
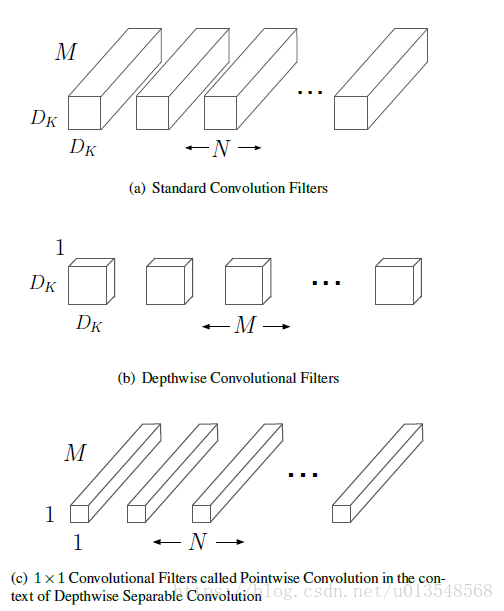
- 普通的卷积是假设输入M个通道,输出是N个通道,卷积核大小为Dk,那么卷积核大小为MxNxDkxDk。也即对之前的输入的M张map,每个MxDkxDk对之前的M张map都进行卷积,因为有N个MxDkxDk,最后的通道数是N。
- 但是对于Depthwise seperable convolution卷积他先通过MxDkxDk的卷积核对之前输入的M个特征通道卷积,但是这里MxDkxDk的每个DkxDk都只对输入的M通到中的对应的那个进行相应的卷积。最后输出是M个通道的输出,然后接上一个pointwise的卷积将输出映射为N个通道,这里pointwise卷积核大小变成了1x1。
3、
来看一下Inception的衍化过程,首先是Inceptionv3
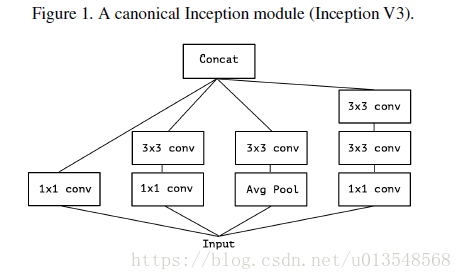
然后对InceptionV3进行改进,将AvgPool取消
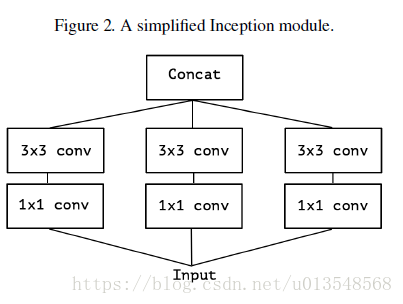
然后考虑将输入通道划分为三组,假设输入是120个通道,下面有三个分支,每个分支则只对应自己的40个通道进行卷积。
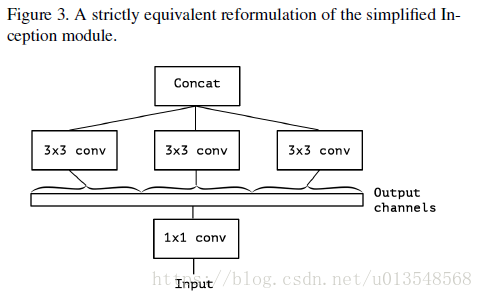
考虑极端情况,假设假设1x1卷积之后,输出的120个通道每个通道对应一个3x3的卷积,就是Xception的基本结构了
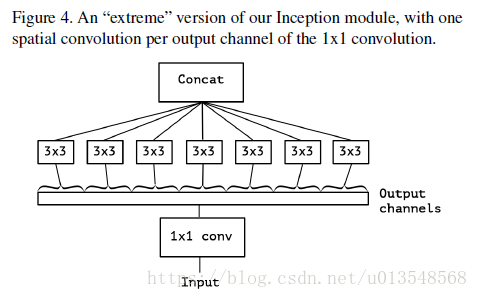
- 和MobileNet的设计稍微不同,这里会首先将1x1的卷积提到depthwise convolution之前。
- 还有就是Inception中的卷机操作之后都会加入非线性的relu,但是这里在depthwise convolution和pointwise convolution之间是不能加入relu的,作者的解释是至于加不加中间的非线性映射,中间特征空间的深度对于非线性来说是很关键的,也即channel数量,卷积对于n个通道一起卷积非线性映射效果是有提升的,但是depthwise卷积只对一张,map进行卷积,加入非线性映射回损坏整体的信息,主要是因为信息的丢失
3、
试验探讨了以下几个方面的考虑
- residue connection的影响,对于Xception来讲残差连接是有提升的,但这并不意味这残差连接到哪里都是适用的,对于简单地堆叠depthwise可分离卷积的这样的模型就不需要残差连接。
- depthwise和pointwise之间不需要需要加入非线性映射relu
- 全连接层对于整体性能有提升
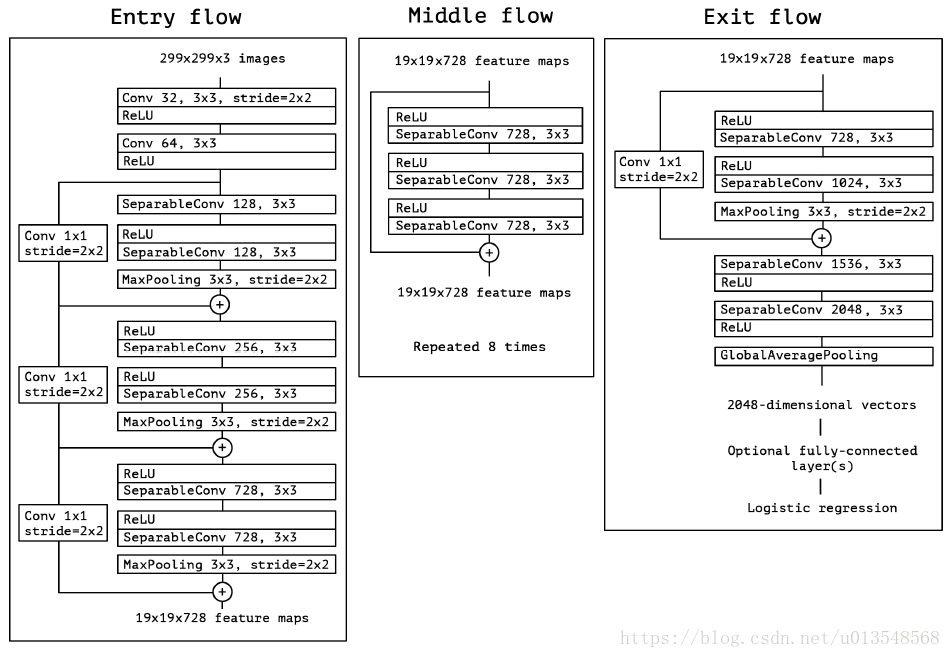
整体的网络结构图由EntryFlow+8*MiddleFlow+ExitFlow构成
4、未来的探讨
在普通卷积和depthwise卷积之间存在这样的离散谱,可以将输入通道分成若干个segment送入到普通卷积中,而depthwise卷积则是一种特例,每个segment都是一个,但这不意味着depthwise卷积是最优的,怎样寻求最优的搭配还值得探索。
5、补充
MobileNet文章介绍了网络压缩的常见的一些分支,参考文章开头。
6、
SeparableConv2D在keras中的实现
keras.layers.SeparableConv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), depth_multiplier=1, activation=None, use_bias=True, depthwise_initializer='glorot_uniform', pointwise_initializer='glorot_uniform', bias_initializer='zeros', depthwise_regularizer=None, pointwise_regularizer=None, bias_regularizer=None, activity_regularizer=None, depthwise_constraint=None, pointwise_constraint=None, bias_constraint=None)1)filters是一个数字,指出了pointwise conv输出的通道数(输出滤波器的个数)
2)kernel_size是指卷积核的大小,特指depthwise部分的卷积
3)strides是指卷积的stride,特指depthwise
4)depth_multiplier是指对于输入的每一个通道,输出几个通道。如果depth_multiplier是3的话,那么输入的一个通道对应的是3个输出,depthwise卷积的总的输出是depth_multiplier*filters_in
tensorflow也有类似的实现,tf.nn.separable_conv2d
对于torch来讲,他并没有把depthwise和pointwise卷积结合在一起,而是只实现了depthwise convolution
SpatialDepthWiseConvolution
对于pytorch中的conv2d来讲也可以间接实现depthwise卷积
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)采用group卷积即可。in_channels和out_channels都必须整除groups。groups的意思是,将输入的channel和输出的channel分别分成group个,假设group=4,输入是128,输出是256。输入将会分成4x32,输出将会分成4x64,每个1x32经过32xwxhx64的卷积核都会变成1x64的输出大小,因为一共有四组,每组的卷积都在自己组内完成,与其他组不相关,所以总体的卷积核的大小4x32xwxhx64的。什么group卷积是和depthwise等同的呢?
当in_channels=group的时候,这个时候就等同于depthwise卷积了,只不过TensorFlowflow里面会指定参数depth_multiplier,在pytorch里面则会指定out_channels,那么二者什么关系呢?
depth_multiplier = out_channels / group,在这种条件下可以用pytorch的conv2d实现depthwise卷积。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









