







Exploring Incompatible Knowledge Transfer in Few-shot Image Generation
公众号:EDPJ
目录
0. 摘要
Few-shot image generation (FSIG) 学习使用少量(例如 10 个)参考样本从目标域生成多样化和高保真度的图像。 现有的 FSIG 方法从源生成器(在相关领域预训练)中选择、保存和迁移先验知识以学习目标生成器。 在这项工作中,我们调查了 FSIG 中一个未被充分探索的问题,称为不相容的知识转移,这将显着降低合成样本的真实性。 经验观察表明,问题源于源生成器中最不重要的过滤器。 为此,我们提出知识截断(knowledge truncation)来缓解 FSIG 中的这个问题,这是对知识保存的补充操作,并通过基于轻量级剪枝的方法实现。 大量实验表明,知识截断简单有效,始终如一地实现最先进的性能,包括源域和目标域更远的具有挑战性的设置。
1. 简介
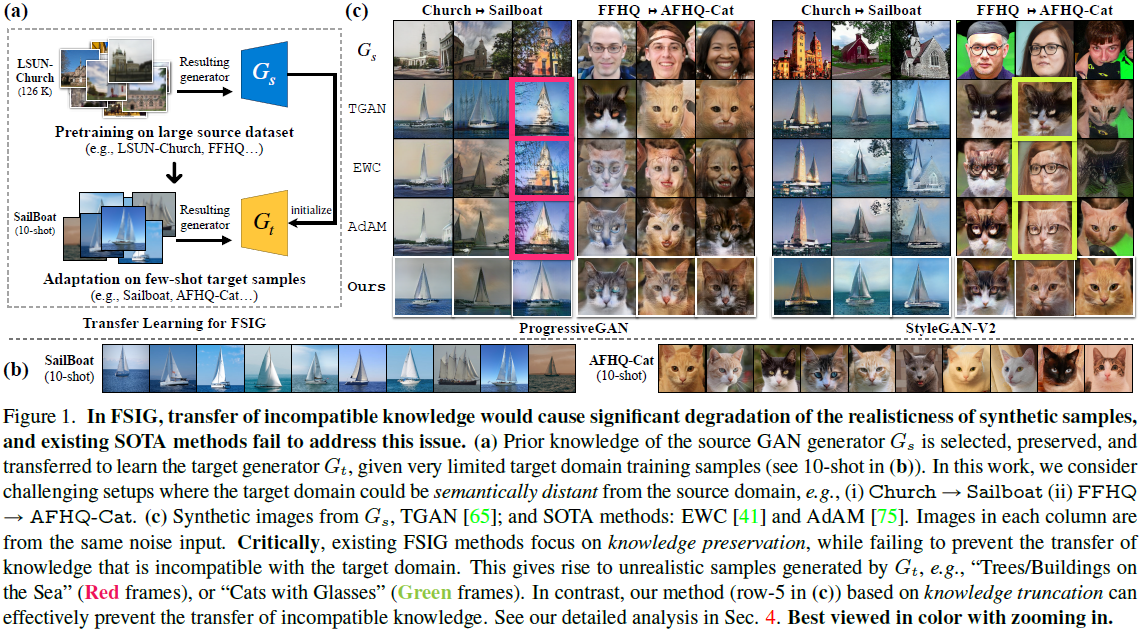
不相容的知识迁移。 尽管通过不同的知识保存方法取得了令人印象深刻的改进,但在这项工作中,我们认为防止不相容的知识迁移同样重要。 这是通过精心设计的调查揭示的,这种不相容的知识迁移表现在意想不到的语义特征的存在。 这些特征与目标域不一致,从而降低了合成样本的真实性。 如图 1 所示,树木和建筑物与 Sailboat 的域不兼容(通过检查 10 个参考样本可以观察到)。 然而,当应用现有的 SOTA 方法 [41、75] 以及在 Church 上训练的源生成器时,它们会出现在合成图像中。 这表明现有的方法不能有效地阻止不相容知识的迁移。
知识截断。 根据我们的观察,我们提出了移除不兼容知识 (Removing In-Compatible Knowledge,RICK),这是一种基于轻量级过滤器修剪的方法,用于在 FSIG 自适应期间移除编码不兼容知识的过滤器(即,估计自适应重要性最低的过滤器)。 虽然过滤器修剪已被广泛应用于以减少计算量实现紧凑的深度网络,但其在防止不相容知识迁移方面的应用尚未得到充分探索。 我们注意到我们提出的知识截断和不兼容过滤器的修剪是正交的,并且与 FSIG 中现有的知识保存方法互补。 通过这种方式,我们的方法有效地去除了与先前工作相比不兼容的知识,并显着提高了生成图像的质量(例如,FID)。
2. 相关工作
最近最先进的方法建议保留一些用于自适应的知识。
- FreezeD 固定了判别器的一些低层以进行自适应
- EWC 识别源任务的重要参数并对权重变化进行惩罚
- CDC 旨在保持自适应前后生成图像之间距离的一致性
- DCL 最大化来自相同输入隐编码的源和目标生成图像之间的互信息,以保存知识。
- 最近,AdAM 提出了一种基于调制的方法来识别对目标域重要的源知识,并保留知识以进行自适应。
3. 基础
现有的 FSIG 方法采用迁移学习(transfer learning,TL)方法并利用在大型源数据集上预训练的源 GAN。 我们将源生成器表示为 Gs(将源鉴别器表示为 Ds)。 在自适应过程中,目标生成器 Gt(目标鉴别器 Dt)是通过对抗性损失 L_adv 在少量目标图像上微调源 GAN 获得的。
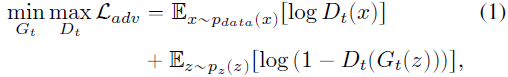
其中 z 是从噪声分布 p_z(z)(例如高斯分布)中采样的一维隐编码,p_data(x) 表示 few-shot 目标数据分布。 请注意,源数据是不可访问的。 在微调中,Gs(和Ds)的权重用于初始化 Gt(和Dt), 见图 1(a)。 FSIG 的主要目标是学习 Gt 以捕获 p_data(x)。
为了减轻由于目标样本非常有限而导致的模式崩溃,最近的方法通过知识保存来增强微调,以在自适应过程中仔细选择和保存源知识的子集,例如冻结、正则化和基于调制的方法。 这些方法的目的是保留被认为对目标生成器有用的知识,例如,提高目标样本生成的多样性。 对于被认为不太有用的知识,使用等式 1 进行微调是一种常见做法,在适自应过程中更新此类知识。
4. FSIG 中不兼容的知识转移
在本节中,作为我们的第一个贡献,我们观察并确定了现有 FSIG 方法中未被注意的不相容知识迁移问题,并揭示了基于微调的知识更新不足以在自适应后删除不相容的知识。
为支持我们的主张并找出不兼容知识迁移的根本原因,我们应用 GAN 解剖(dissection),这是一个可以跨不同图像识别过滤器与特定对象类(例如树)的语义分割之间的对应关系的框架 ,以揭示在微调后保留不兼容知识的过滤器。
4.1 调查不相容的知识
先前的 SOTA FSIG 方法提出了不同的知识保存标准来选择预训练的源知识以进行 few-shot 自适应。 自适应通常是通过使用少量目标样本微调源生成器(通过等式 1)来完成的。 这些方法中的一个假设是微调可以使源生成器适应目标生成器,从而可以删除或更新不相关和不兼容的源知识。
在这项工作中,我们表明,该假设在源域和目标域在语义上相距较远的情况下(例如,图 1 中的人脸和猫脸)变得无效,其中不兼容的知识迁移严重损害了生成图像的真实性。 我们注意到,这在之前的 SOTA FSIG 工作中没有得到很好的研究,因为它们主要关注从源头保存知识(见第 2 节),而很少关注与基于微调的知识更新不兼容的知识迁移。
在卷积神经网络中,每个过滤器都可以看作是知识的特定部分的编码。 直观地说,在生成模型中,此类知识可以是低级纹理(例如毛皮)或高级人类可解释的概念(例如眼睛)。 因此,我们假设可以通过关注生成器的过滤器来找到不相容知识迁移的线索。 最近,AdAM 提出了一种重要性探测(importance probing,IP)方法来确定源 GAN 过滤器是否对自适应很重要,并取得了令人印象深刻的性能。 在我们的分析中,我们采用 IP 来评估源生成器过滤器对目标域适应的重要性(我们在补充中简要介绍了 IP)。 我们提出了两个不同粒度的实验:
- Exp-1:使用固定的生成器输入生成图像。 我们通过不同的方法可视化生成的图像。 为了理解自适应前后的知识迁移,我们使用相同的噪声作为源和目标生成器的输入。 从概念上讲,这为我们提供了对知识迁移的直观和直接比较。
- Exp-2:剖析经过预训练和自适应的生成器。 为了找到与跨不同图像的特定类型知识最相关的过滤器(例如,与目标不兼容的源特征)并跟踪它们在适应前后的迁移,我们用估计的重要性(通过 IP) 标记 Gs 过滤器并应用 GAN 解剖来可视化对应于 Gs 和 Gt 的相同过滤器的语义特征。
- 这些实验可以帮助我们理解在粗粒度(像素空间中生成的图像的可视化)和细粒度(过滤空间中 Gs 和 Gt 的剖析)适应前后的知识转移。 接下来,我们讨论设置和结果。
4.2 实验设置
4.3 结果和分析


我们揭示了以源知识保存为重点的现有 SOTA FSIG 方法会导致不兼容知识的迁移。 更重要的是,这种不兼容的知识迁移的根本原因是 Gs 中最不重要的过滤器被确定为与目标域适应无关,并且微调不足以在自适应后去除不兼容的知识。 具体来说,我们总结了在图 1 和图 2 中观察的结果:
- 观察 1:在图 1 (c) 中,我们使用固定噪声输入通过不同方法可视化生成的图像。 有趣的是,与目标域不兼容的特征,在使用不同的知识保存标准进行自适应后,确实被迁移了,例如,“tree on sea”,其中 “tree” 来自 Church 域,“Cat with glasses”,其中 “glasses” 来自 FFHQ 领域。 所有这些不兼容的源特征严重削弱了生成的目标图像的真实感。 可以在 TGAN 上有类似的观察,即没有显式知识保存的基于简单微调的方法。 相反,我们的方法(我们在第 5 节中讨论)可以解决这个问题。
- 观察 2:在图 2 中,我们剖析和可视化了在图 1 中观察到的不兼容特征,并在 Gs 和 Gt 中找到了它们最相关的过滤器。 令人惊讶的是,我们发现 Gs 中被识别为对目标域重要性最低的过滤器与从源迁移的不兼容特征最相关,这是生成图像真实性退化的根本原因。在自适应后,相同的过滤器仍然会造成相同类型的不兼容特征,知识更新的微调无法有效解决这个问题。 当目标域变得遥远时,这种观察会更加明显。
5. 建议的方法
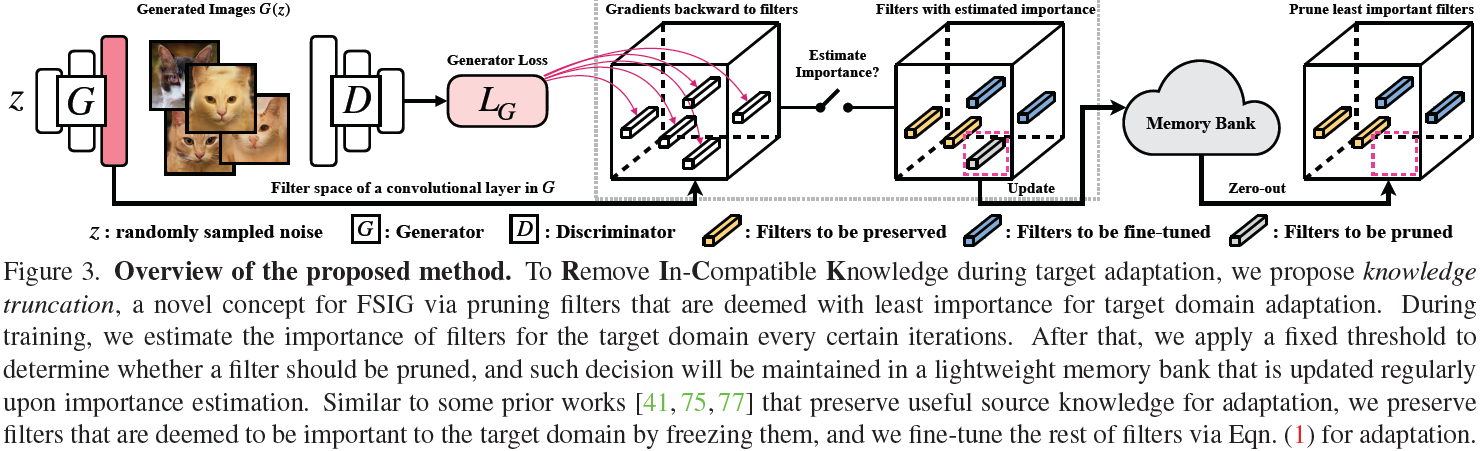
5.1 通过网络修剪进行知识截断
修剪是实现紧凑型神经网络的有用工具之一,其性能可与更大的整个模型相媲美。 压缩网络的早期工作集中在模型加速、推理效率和部署上,它们针对的是判别任务,例如图像分类和机器翻译,通常通过移除最不重要的神经元(重要性的定义可能多种多样,并在第 5.2 节中讨论)。 与之前追求模型稀疏性的网络修剪工作相比,我们旨在通过移除与目标域不兼容知识相关的最不重要的过滤器来提高生成图像的质量,特别是在 FSIG 任务中。
我们提出的方法包含两个主要步骤:1)在自适应过程中即时进行轻量级过滤器重要性估计; 2)根据估计的重要性确定过滤器的操作。 在步骤 1) 中,我们在自适应过程中利用梯度信息,每特定迭代次数,评估一次目标自适应的滤波器重要性。 然后在步骤 2) 中,基于估计的过滤器重要性,我们修剪重要性最低的过滤器,这些过滤器被认为与目标域无关,以去除不兼容的知识以进行自适应。 同时,我们保留具有高重要性的过滤器以实现 FSIG 中的知识保存,并对其余过滤器进行微调以使源生成器适应目标域。
提议的过滤器重要性估计。 我们通过在 FSIG 自适应期间利用即时梯度信息来估计每个过滤器的重要性。 我们将过滤器表示为
![]()
其中 k 是过滤器的空间大小,c^in 是输入特征图的维度(数量)。 我们使用 Fisher Information (FI) 作为每个过滤器 F(W) 的重要性估计器(将在第 5.2 节中进一步讨论),它可以给出过滤器权重和 FSIG 任务之间兼容性的定量信息。
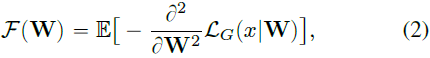
其中 L_G 是根据鉴别器的输出计算的二元交叉熵损失。 x 表示一组生成的图像。 在实践中,我们使用 FI 的一阶近似来降低计算成本。
我们对知识选择的过滤器重要性估计是轻量级且高效的:与提出不同知识选择标准的先前 SOTA 方法相比(尽管它们只关注知识保存),我们的方法不需要外部模型在适应过程中提供额外信息,也没有为重要性估计引入额外的可学习参数和预适应迭代,并且它在训练期间从 Gt 和 Dt 的输出中获益。
通过过滤器修剪建议的知识截断。 在第 4 节,我们已经展示了丰富的证据表明最不重要的过滤器与目标域不兼容的语义特征相关(例如“海上的树”或“海上的建筑结构”)。 重要的是,给定不同的知识保存标准,基于微调的知识更新不能在自适应后正确地删除不兼容的知识。 因此,我们提出了一种简单而新颖的知识截断方法,通过修剪(归零)对自适应最不重要的过滤器。
具体来说,在步骤 1) 中估计滤波器重要性之后,对于网络中的第 i 个滤波器 W^i,我们应用一个阈值(q%,即其重要性与所有滤波器相比的分位数)来确定是否应该修剪 W^i :
![]()
我们注意到,一旦确定要修剪过滤器,它将不再参与训练/推理,也不会在其余的训练迭代中恢复。 知识截断应用于生成器和鉴别器,我们对 Gt 和 Dt 使用单独的阈值。 由于我们定期估计自适应期间的过滤器重要性和修剪过滤器的“不可恢复”属性,因此使用等式 3 的零化过滤器的数量将在自适应结束时累积到特定值 p%。
与专注于知识保存并提出不同知识选择标准的先前工作类似,我们通过在训练期间冻结过滤器来保留具有高自适应重要性的过滤器。 对于其余的过滤器,我们只需让它们使用等式 3 进行微调。过滤器是否需要微调或保留取决于它对目标的重要性。我们在补充材料中讨论了选择高重要性过滤器的效果。 由于我们在自适应过程中多次估计过滤器的重要性,因此在不同的评估之后对特定过滤器的操作可能会发生变化,除非过滤器被修剪并且不会被恢复。
5.2 设计选择
在这里,我们讨论了我们提出的方法的设计选择和采用的重要性测量。 由于我们每隔一定的迭代就动态评估过滤器的重要性,因此我们需要保持对每个过滤器的操作(可以是“保留”、“微调”或“修剪”)直到下一次估计。 为了降低计算成本,我们在轻量级内存库 M 中保持每个过滤器的操作决定(通过估计过滤器重要性获得):对于每个高维过滤器 W,我们只需要一个字符来记录 M 中的相应操作。 例如,对于主要实验中使用的 StyleGAN-V2,其生成器包含大约 30M 的参数,M 是一个一维数组,大小大约为 5,000。
与之前的工作类似,我们使用 FI 作为重要性度量来估计网络参数(我们工作中的过滤器)在自适应任务上的表现。 我们注意到,还有其他测量方法可以估计过滤器对自适应的重要性,例如类别显着性或重建损失。 在补充材料中,我们进行了一项研究,并根据经验发现我们可以实现与 FI 类似的性能。 此外,在第 6.2 节,我们惊讶地发现,即使没有修剪(即只能保留或微调过滤器),与 SOTA 方法相比,我们提出的方法仍然可以获得有竞争力的性能,这意味着所提出的动态重要性估计器的有效性。
6. 实验
6.1 性能评估与对比

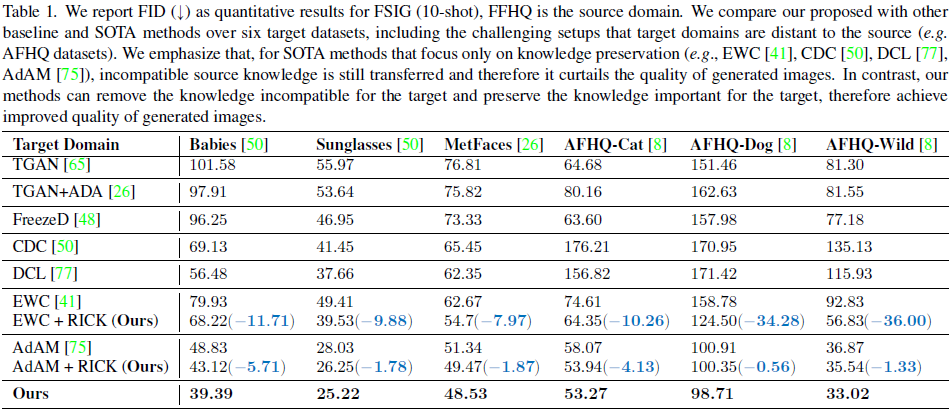
定性结果。在上图中,我们将自适应前后不同方法生成的图像可视化以进行比较。 在每一列中,图像都是从相同的噪声输入生成的。 我们使用 FFHQ 作为源域。 Babies 和 AFHQ-Cat 是与源具有不同语义接近度的目标域。 我们表明,我们提出的方法在保留有用的源知识的同时,可靠地去除了与目标不兼容的知识,从而提高了生成图像的质量。
定量结果。 考虑到整个目标数据集通常包含大约 5,000 张图像(例如 AFHQ-Cat),根据之前的工作,我们使用自适应生成器随机生成 5,000 张图像,并与整个目标数据集进行比较以计算 FID。 在表 1 中,我们展示了六个基准数据集的完整 FID 结果。 在上图中,我们还计算了 intra-LPIPS 作为对 10 次目标样本的多样性测量,并且我们使用相同的检查点报告 FID。 所有这些结果都表明了我们提出的方法的有效性。
6.2 讨论
不同方法的知识截断。 理想情况下,我们提出的 FSIG 知识截断概念可以应用于不同的方法,只要我们可以估计参数重要性(例如,我们方法中的过滤器重要性)。 在文献中,EWC 和 AdAM 提出了不同的方法来评估参数重要性:EWC 直接估计 Gs 的源数据集上的参数重要性,而 AdAM 使用基于调制的方法来估计目标数据集上的 Gs 参数重要性 。 因此,在表 1 中,我们还展示了将我们提出的知识截断应用于 EWC 和 AdAM 的结果。 由于我们的方法可以通过修剪最不重要的过滤器来有效地去除不兼容的知识,因此我们可以在不同的数据集上实现一致的改进性能。
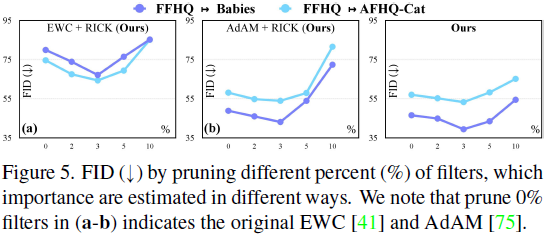
修剪不同百分比的过滤器。 我们根据经验研究修剪不同百分比的过滤器的影响。 根据图 5 中的结果,我们在三种不同的方法上修剪了不同数量的过滤器。 理想情况下,如果我们修剪更多的过滤器,一些重要的知识将被删除,性能将相应降低。 因此,我们在不同的设置中修剪 3%(即第 5.1 节中的 p=3)过滤器,这可以实现相当大且稳定的改进。
我们可以训练更长的时间来去除不相容的知识吗? 理想情况下,删除不兼容知识的一种直观且可能有用的方法是简单地训练更长的迭代。 然而,在补充中,我们进行了一项研究并表明,对于现有的 FSIG 方法,由于目标集仅包含 10 个训练图像,训练较长的迭代将使生成器过度拟合并倾向于复制少量目标样本,这样它可以骗过鉴别器。 生成图像的多样性显着降低。 因此,在过度拟合变得严重之前删除不相容的知识很重要。
7. 结论
我们在这项工作中解决了 few-shot 图像生成 (FSIG) 问题。 作为第一个贡献,我们发现了现有 SOTA 方法未被注意的不兼容知识迁移的的问题,这导致生成的图像真实感显着下降。 令人惊讶的是,我们发现这种不兼容的知识迁移的根本原因是被认为对目标自适应最不重要的过滤器,而基于微调的 SOTA 方法无法正确解决这个问题。 因此,我们提出了一个新的概念,即 FSIG 的知识截断,旨在通过对适应性最不重要的修剪过滤器来消除不兼容的知识。 我们提出的过滤器重要性估计利用了来自动态训练过程的梯度信息,并且计算成本很轻。 通过广泛的实验,我们表明我们提出的方法可以应用于具有不同 GAN 架构的各种自适应设置。 我们实现了新的最先进的性能,包括视觉上令人愉悦的生成图像,没有太多不相容的知识被迁移,以及改进的定量结果。
限制和伦理问题。 我们实验的规模与之前的工作相当。 尽管如此,我们的知识截断方法的扩展、额外的数据集和 GAN 之外的生成模型(例如,变分自动编码器或扩散模型)可以被视为未来的工作。 如果恶意用户使用我们提出的 FSIG 方法,可能会产生负面的社会影响。 然而,我们的工作有助于提高对有限数据图像生成的认识。
附录
F. 消融研究:高重要性过滤器的影响
在主要论文中,我们强调了我们在调查不相容知识迁移方面的贡献、它与最不重要过滤器的关系,以及为 FSIG 解决这个未被注意的问题所提出的方法。 除了知识截断之外,在之前的工作之后,我们还保留了有用的源知识以进行改编。 具体来说,我们通过冻结它们来保留被认为对目标自适应很重要的过滤器。 我们通过使用分位数(t_h,例如 75%)作为阈值来选择高重要性过滤器。在本节中,我们进行了一项研究,以显示保留被认为与目标适应最相关的不同数量过滤器的有效性和影响,结果见表 S1。 请注意,我们不会在此实验中修剪任何过滤器。

如表 S1 所示,用于保存的不同数量的过滤器实际上以不同的方式提高了性能。 在实践中,我们为 FFHQ → Babies 选择 t_h = 50%,为 FFHQ → AFHQ-Cat 选择 t_h = 70%,这个选择很直观:对于语义上更接近源的目标域,保留更多的源知识可能会提高性能。
H. 消融研究:其它的重要性测量
评估权重在生成任务中的重要性仍未得到充分探索。 在主论文中,我们遵循一些先前的工作,使用 Fisher 信息 (FI) 作为重要性估计的度量,并获得跨不同数据集的优势性能(参见主要论文中的表 1)。 然而,可能有不同的方法来评估在给定自适应任务的情况下获得的权重有多好。 在文献中,Class Salience (CS) 被用作一种工具来估计给定输入图像的哪些区域/像素在特定分类决策中脱颖而出,它类似于利用梯度信息的 FI。 因此,我们注意到 CS 可能与 FI 有联系,因为它们都使用梯度中编码的知识来进行知识重要性估计。
参考
Zhao Y, Du C, Abdollahzadeh M, et al. Exploring incompatible knowledge transfer in few-shot image generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7380-7391.
S. 总结
S.1 主要思想
本文研究few-shot 域自适应的不相容知识迁移问题:源域的与目标域不匹配的实体在自适应后可能会在目标域出现,影响自适应质量。作者使用基于滤波器重要性的网络修剪来解决这个问题。
S.2 网络修剪
不兼容知识迁移的原因是对自适应不重要的滤波器(提取非重要特征),通过删除这些滤波器可以解决问题。该操作分为两步:1) 估计滤波器对自适应的重要性 2) 基于重要性执行如下操作:
- 归零重要性低的滤波器:与目标域无关,删除以避免不兼容知识迁移
- 冻结重要性高的滤波器:以实现 few-shot 域自适应中的知识保存
- 微调剩余滤波器:以实现域自适应















 6787
6787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









