







论文题目: Context-Transformer: Tackling Object Confusion for Few-Shot Detection
论文地址:https://arxiv.org/pdf/2003.07304.pdf
在anchor和从textural field之间操作的注意力模块,自动的发现当前anchor box的重要的contextual field,然后聚合这种关系到anchor,增强OBJ以进行few-shot检测。和之前的《a syntax-guided edit decoder for neural program repair》中的注意力机制(整合错误语句的上下文)有些些区别。
目标检测器\目标混淆
目标检测器通过bounding box regressor进行定位,通过object + background classifier进行分类
bounding box regressor定位不依赖于特定的物体类别,background classifier也不依赖于特定的物体类别(相当于一个二分类,有物体再框内值为1,无物体为0,于这个物体是哪个类别的无关)。正是因为其不依赖于特定类别,所以可以使用源域的BBox作为目标域的初始化,然后争对目标域进行微调,background classifier也同理。
而object classifier是特定于类被的,所以其必须为目标域中的新类别进行随机初始化,但在目标域中,可训练的图像少,数据多样性(data diversity)低,增加了训练难度,且导致目标混淆问题 。(object confusion caused by annotation scarcity)
争对目标混淆这个问题,作者提出了Context-Transformer
设计灵感:在对一个物体不确定的时候,通过物体周围的环境(contextual fields)来进一步确定这个物体
Context-Transformer
分为Affinity discovery和Context aggregation部分
图来自论文中
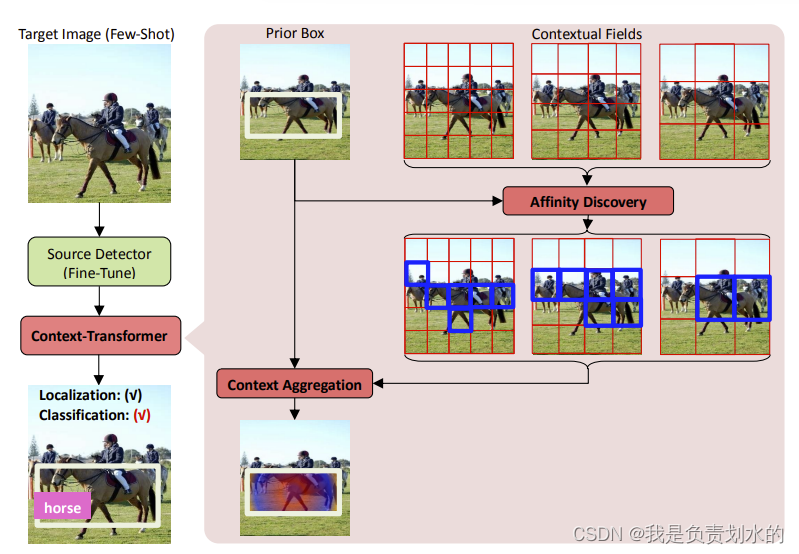
Affinity discovery:根据anchor box(先验框)构造一组上下文域,然后自适应利用先验框与上下文的关系。
具体做法见后面的推导。
Context aggregation:以affinity discovery得出的关系做为参考,将关键的上下文集成到每个先验框中。
通过集成上下文关系,减少检测的混淆。
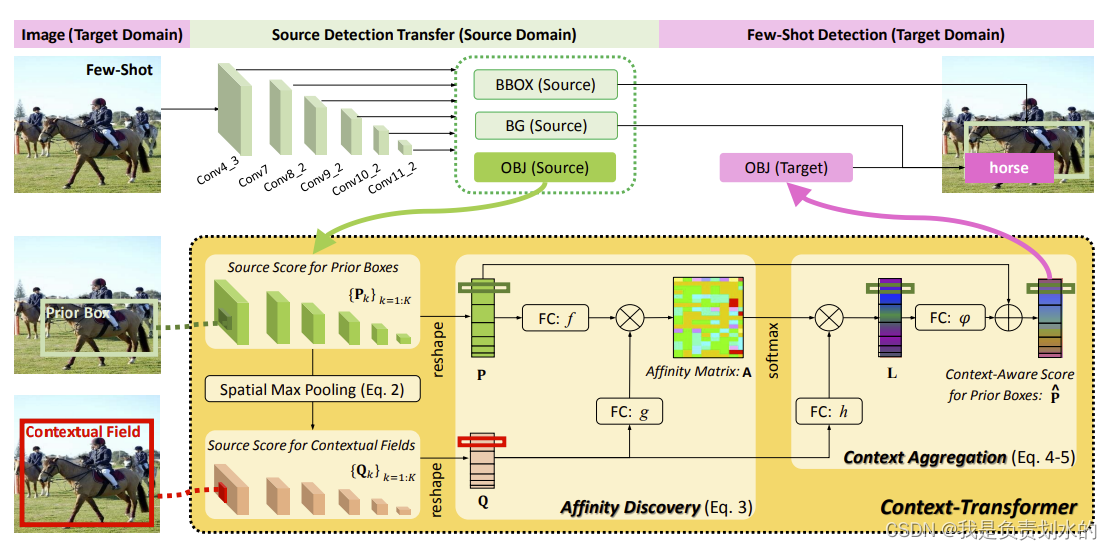
拆分BG+OBJ
BBOX微调
BG微调
OBJ 保留源域,并在其之上新增一个目标域的OBJ。
文中解释了原因,简单描述如下:在传统做法中,卸载源域OBJ,引入新的目标域OBJ会引入大量随机初始化的参数(在高维特征上),然后目标域中能只有少数几个带有注释的图像,训练困难。而通过保留源域,在源域之上添加新的OBJ,引入的额外参数会更少(源域OBJ的预测分数的维度【物体类别】小于卷积层的特征通道数),从而减小过拟合。
源和目标OBJ之间的Context-Transformer。保留源域OBJ在一定程度上可以降低目标域OBJ的训练难度。然而,简单的转移不足以解决few-shot目标检测的根本问题,即目标域中由于标注稀缺而导致的目标混淆。仍然有必要进一步有效地从仅有的几个标注的训练图像中挖掘目标领域的知识。自动利用上下文。然后,集成这些关系线索来增强目标OBJ。
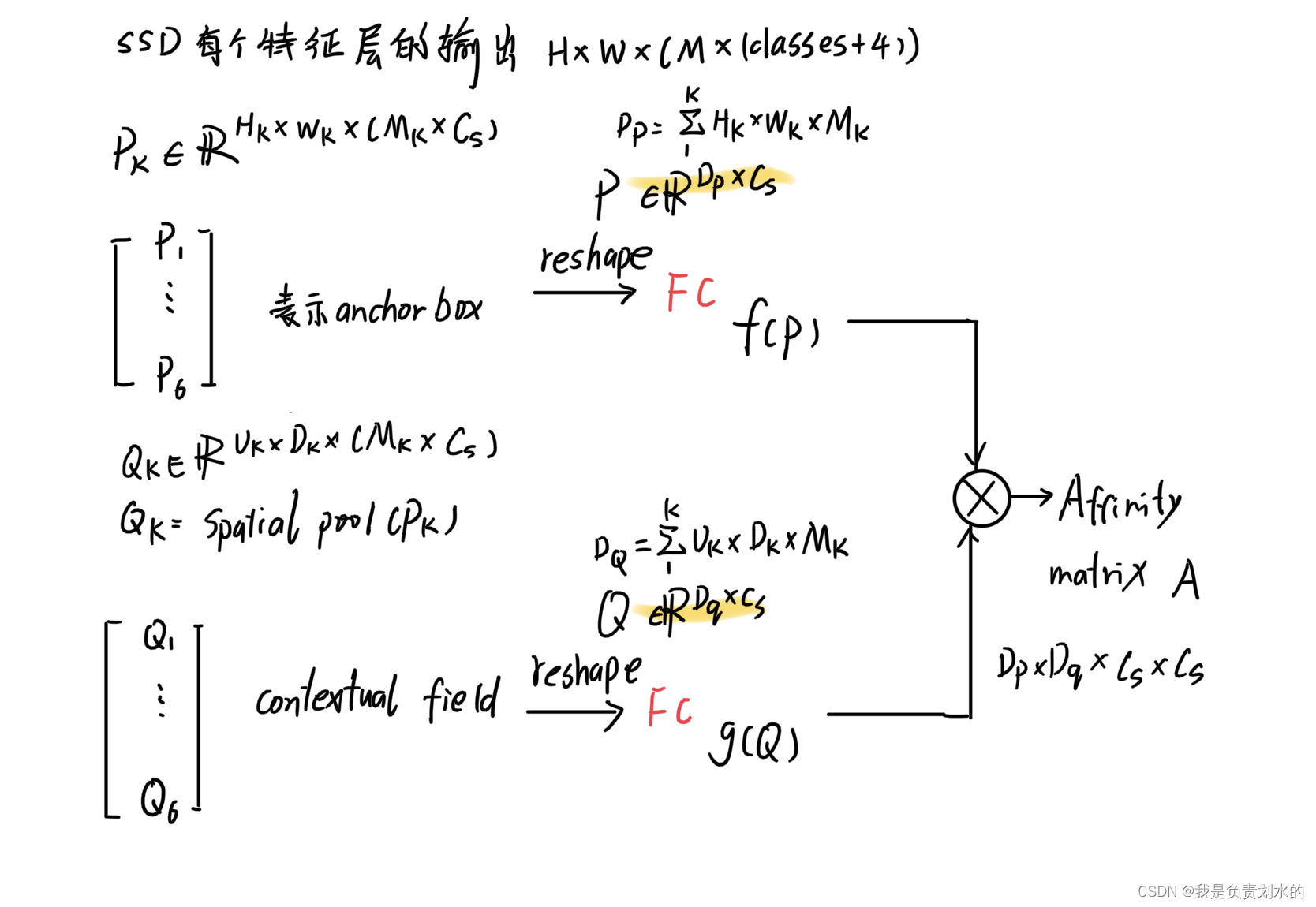
Model
M表示该层中anchor数量,K表示空间尺度数量(K=6)。
SSD每个特征层的输出:H x W x (M x (classes+4))
对于anchor的表示如下式:

通过池化构造contextual field:
spatial pool(比如max pooling)
使得同等感受野的数据特征维度减低,减少计算开销(相比于直接将anchor box用作contextual field)
reshape操作后接全连接层(增强非线性表示能力)

相似度(余弦相似度),论文中采用点乘(越“相似”,点乘越大)
softmax归一化
与h(Q)点乘,值大的表示该上下文对于当前这个anchor重要性高(相关性强)。

将加权上下文矩阵聚集到原始的矩阵P中

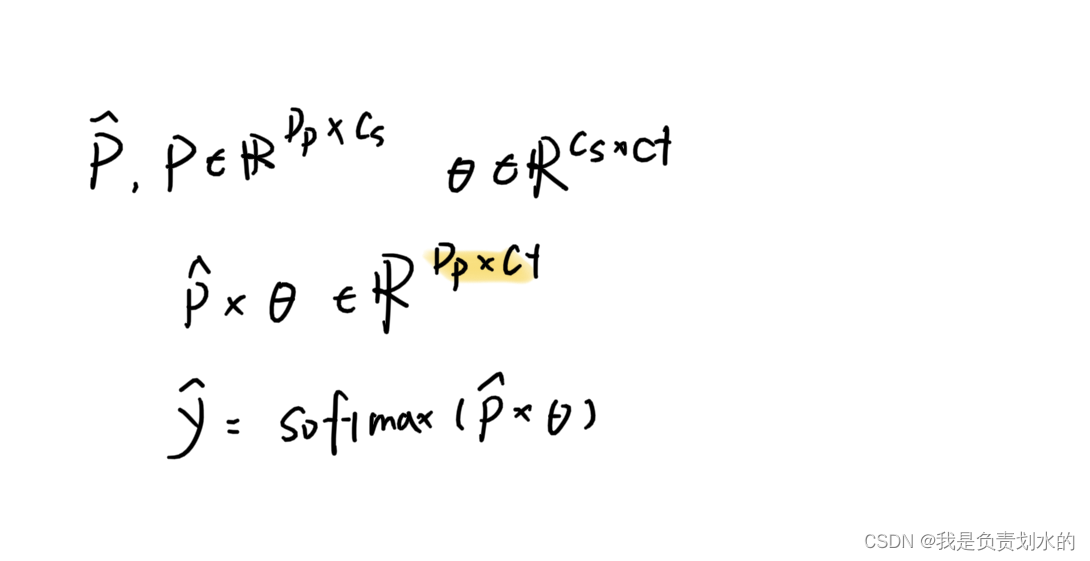
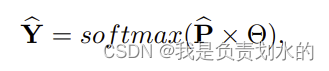
实验部分
重点关注了下消融实验
baseline:traditional fine-tuning with target-domain OBJ
论文中结果:
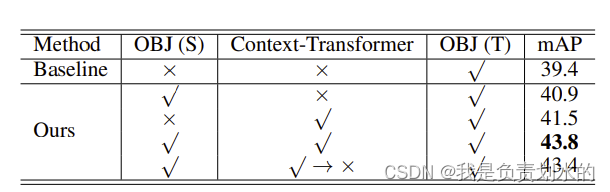
保留源OBJ可以缓解few-shot学习的过拟合问题。其次,通过将目标OBJ添加到上下文转换器之上,性能优于基线。实验结果表明,Conext-Transformer通过上下文学习可以有效地减少混淆。上下文转换器可以充分利用源域知识来增强目标OBJ。
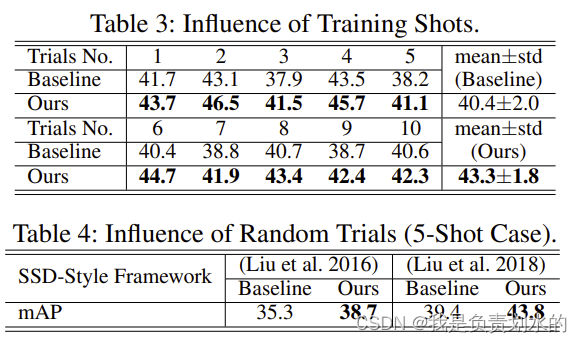
上下文转换器更适合区分由于数据多样性较低而导致的对象混淆。当目标领域中的训练样本数量增加时,混淆将被缓解。
结论
context-transformer。通过在一个简洁的转换框架内利用多尺度的contextual field,可以有效地缓解由于标注稀缺而导致的对象混淆。大量的实验结果证明了该方法的有效性。















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









