







ControlStyle: Text-Driven Stylized Image Generation Using Diffusion Priors
公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
最近,多媒体社区目睹了在大规模多模态数据上训练的扩散模型的崛起,特别是在文本到图像生成领域。在这篇论文中,我们提出了一个新的任务,即 “文本驱动的艺术风格图像生成”,以进一步提高内容创作的可编辑性。给定输入文本提示和风格图像,该任务旨在生成既在语义上与输入文本提示相关,同时又在风格上与风格图像一致的艺术风格图像。为了实现这一目标,我们提出了一个新的扩散模型(ControlStyle),通过升级一个预训练的文本到图像模型,配备一个可训练的调制网络,使其能够处理更多的文本提示和风格图像条件。此外,同时引入了扩散风格和内容正则化,以促进学习这个调制网络,利用这些扩散先验,追求高质量的艺术风格文本到图像生成。大量实验证明了我们的 ControlStyle 在生成更具视觉吸引力和艺术性的结果方面的有效性,超过了简单组合文本到图像模型和传统风格转移技术。
1. 方法
一个传统的文本驱动艺术风格图像生成的解决方案是简单地级联一个预训练的文本到图像扩散模型(文本⇒内容图像)和一个传统的风格迁移技术(内容图像 + 风格图像⇒风格化图像)。然而,这种两阶段方法未充分利用扩散模型中固有的图像先验来进行内容创作,同时忽略了内容图像生成与风格化过程之间的交互作用。为了缓解这些问题,我们提出了一个新的框架,即 ControlStyle,这是一个升级的扩散模型,配备一个可训练的调制网络,共同实现了对文本提示和风格图像的多重条件。
1.1 背景
扩散概率模型(Diffusion probabilistic model,DDPM):
![]()
随机噪声 x_T ∼ N(0, I)。
潜在扩散模型(Latent Diffusion Model,LDM):
![]()
图像 x 由编码器映射到潜在空间 Z 的潜在编码 z,最终由译码器映射回图像。
1.2 ControlStyle
为了追求高质量的文本驱动艺术风格图像生成,我们设计了 ControlStyle,将文本到图像生成和图像风格化统一到一个端到端的框架中。请注意,这里我们使用公开发布的稳定扩散作为预训练的文本到图像扩散模型,以提高训练效率和可重复性。简而言之,稳定扩散包括一个自动编码器,一个文本编码器和一个 U-Net [34],分别用于图像编码/解码(512 × 512 ⇔ 64 × 64)、文本编码和噪声预测。受到 ControlNet [44] 的启发,ControlStyle 被设计为使用可训练的调制网络对预训练的稳定扩散模型进行风格化。调制网络利用输入文本 𝑐_𝑡𝑒𝑥𝑡,风格图像 𝑐_𝑠𝑡𝑦𝑙𝑒 以及噪声潜在编码 𝑧_𝑡 来生成既在结构上又在语义上与输入相关的风格特征。这些风格特征被用来调制预训练的稳定扩散模型,以实现文本驱动的艺术风格图像生成。在学习过程中,仅训练调制网络,而不调整预训练稳定扩散模型的参数,以保留从数十亿的图像文本数据中学到的强大文本到图像的能力。
具体而言,可训练的调制网络是从稳定扩散中的 U-Net 的编码器和中间块初始化的,并通过零卷积层连接到 U-Net 的解码器块。值得一提的是,零卷积层是一种特殊的卷积层,其权重和偏置初始化为零。在整个训练过程中,这些层的参数逐渐从零过渡到优化的值,以避免过拟合。以一个只有一个神经网络块的简单预训练模型 𝑓(·) 为例,输出可以表示为:
![]()
在将 𝑓(·) 与一个可训练的调制块耦合,使其具有附加条件 𝑐 后,新的输出可以推导为:
![]()
其中 𝜓^0 和 𝜓^1 是两个零卷积层,而 𝑓′(·) 是从 𝑓(·) 复制并训练得到的。ControlStyle 中的调制网络也以类似的方式制定。设 𝜖^𝑒𝑛𝑐_𝜃(𝑖) 为 U-Net 中的第 𝑖 个编码器块,𝜖^𝑑𝑒𝑐_𝜃(𝑗) 为 U-Net 中的对称解码器块,解码器块的输出最初计算为:
![]()
在 ControlStyle 中,输出经过额外的样式图像条件(𝑐_𝑠𝑡𝑦𝑙𝑒 )调制,表示为:
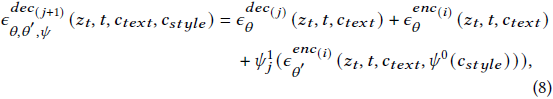
其中,𝜓^0 是位于调制网络之前的零卷积层,而 𝜓^1_ j 是连接调制块与稳定扩散中的冻结 U-Net 解码器块的第 𝑗 个零卷积层。此外,为了匹配 U-Net 的卷积大小,设计了一个样式嵌入网络,将样式图像从 512×512 转换为 64×64。ControlStyle 的整体框架如图 2 所示。
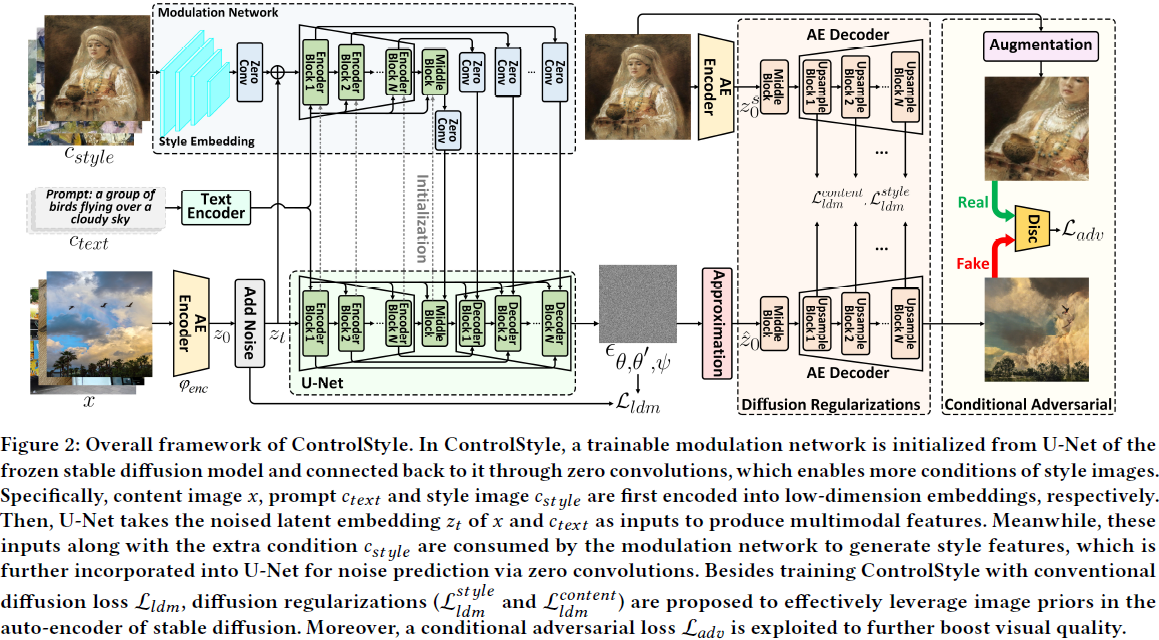
为确保调制输出符合预训练稳定扩散的分布,ControlStyle 使用等式 (4) 中描述的传统扩散损失进行训练,使用包含图像文本对的数据集(例如,MS-COCO)。
1.3 扩散正则化
对于文本驱动的艺术风格图像生成,训练好的模型需要生成既在语义上与输入文本提示相关,同时又在风格上与风格图像一致的图像。为了实现这两个目标,我们设计了扩散内容和风格正则化,以促进 ControlStyle 的学习,这个过程巧妙地利用了预训练稳定扩散模型中自动编码器的图像先验。在执行这两种扩散正则化之前,我们通过以下逼近重构的干净样本 ˆz_0:
![]()
扩散风格正则化。扩散风格正则化旨在鼓励合成图像与输入的风格图像具有相似的风格。具体而言,我们首先将 ˆz_0 馈送到自动编码器的解码器中生成中间特征。对于目标风格,我们首先将输入的风格图像 𝑐_𝑠𝑡𝑦𝑙𝑒 通过自动编码器的编码器,编码成一个 64×64 的潜在编码
![]()
然后类似地计算解码器特征。接下来,提出的扩散风格正则化旨在使 ˆz_0 和 z^s_0 每个上采样块的中间特征之间的全局统计匹配。
设 𝜑_𝑑𝑒𝑐(·) 为自动编码器中的解码器,𝜑^𝑗_𝑑𝑒𝑐(·) 为第 𝑗 个上采样块。因此,扩散风格正则化可以制定为:
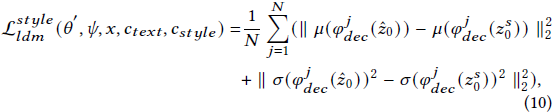
其中,𝑁 是上采样块的数量,𝜇(·) 和 𝜎(·) 分别表示输入的均值和标准差。
扩散内容正则化。尽管传统的扩散损失鼓励生成的图像与文本提示在语义上对齐,但在训练过程中仅使用扩散风格正则化时,空间结构可能无法得到很好的保留。因此,另一种正则化(扩散内容正则化)被设计用于防止由调制网络的风格特征对结构造成过大破坏。类似地,我们从解码器 𝜑_𝑑𝑒𝑐(·) 获取 𝑧₀(训练期间输入内容图像 𝑥₀ 的潜在编码)的中间特征,如扩散风格正则化中所述。然后,扩散内容正则化强制使 ˆ𝑧₀ 的解码器特征在空间上与 𝑧₀ 的特征匹配,可以定义为:
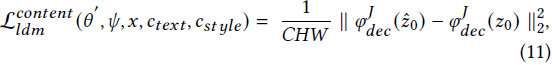
其中,𝐽 表示解码器中的特定上采样块(例如,𝑈𝑝𝐵𝑙𝑜𝑐𝑘_3),𝐶𝐻𝑊 是特征图中元素的总数。
1.4 训练
遵循稳定扩散模型中的传统训练策略,需要一个包含图像文本对的数据集(在本文中为 MS-COCO)来优化 ControlStyle。此外,还需要另一组样式图像(可以是任意样式),用于调制预训练的稳定扩散模型以进行文本驱动的艺术风格图像生成。除了典型的扩散损失和提出的扩散正则化之外,还利用了条件对抗损失 L_𝑎𝑑𝑣 [27] 来进一步改善风格学习:
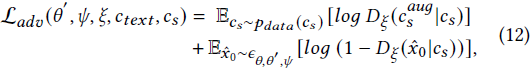
其中,𝑐_𝑠 是 𝑐_𝑠𝑡𝑦𝑙𝑒 的缩写,𝑐^𝑎𝑢𝑔_𝑠 是从 𝑐_𝑠 中得到的一个增强样本,而 ˆ𝑥₀ 是通过将 ˆ𝑧₀ 输入到 𝜑_𝑑𝑒𝑐 得到的重构图像。最终的训练目标是:
![]()
在这种不配对的设置中,一旦我们训练好了 ControlStyle,就可以根据输入的文本提示和样式图像生成所需内容和风格的图像。
2. 结果
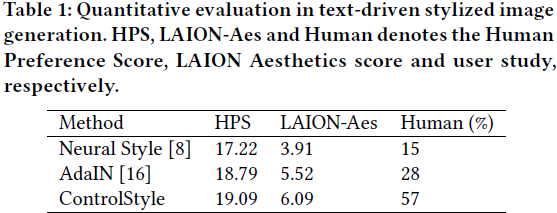

良好的生成质量。
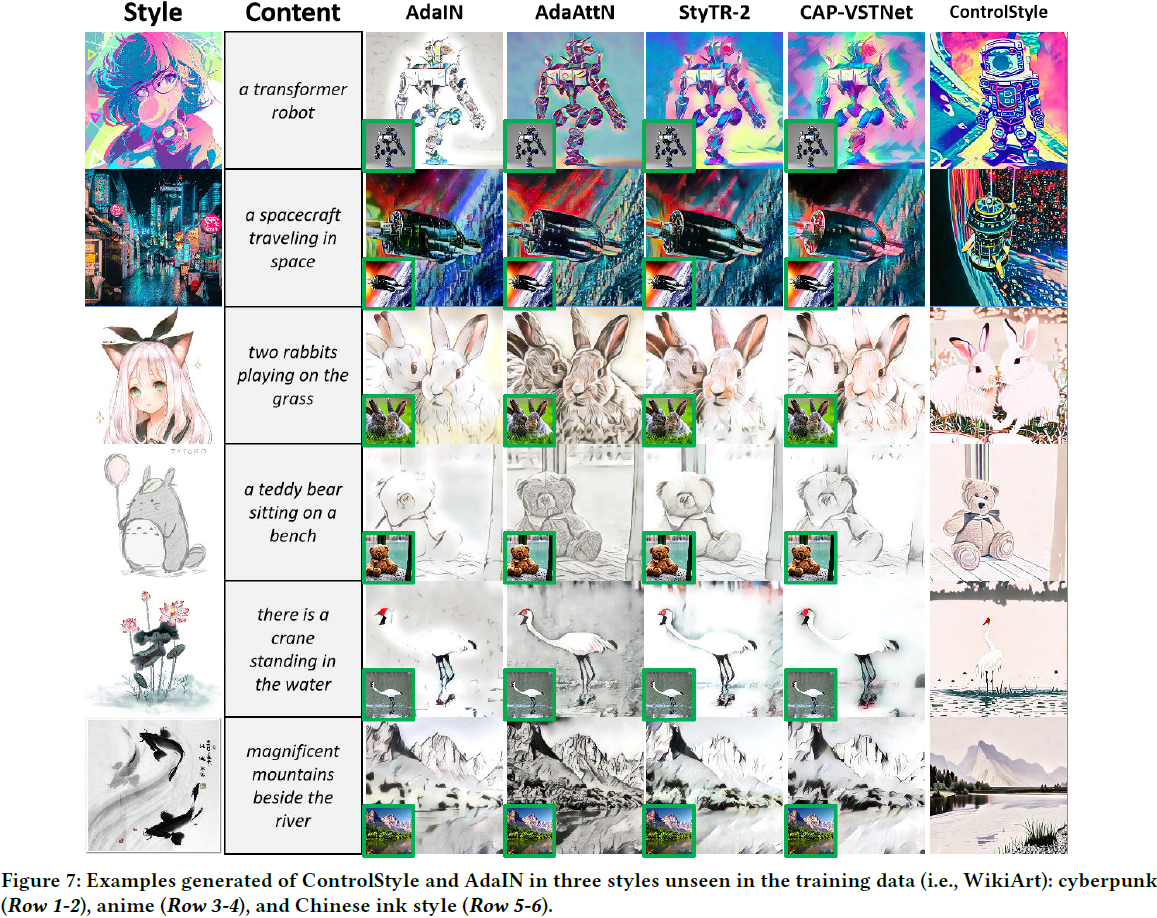
良好的泛化能力。
S. 总结
S.1 主要贡献
本文提出 ControlStyle,通过升级一个预训练的文本到图像模型(例如,稳定扩散),配备一个可训练的调制网络,提升其泛化能力。同时引入扩散风格和内容正则化,以促进学习调制网络,利用扩散先验,改进文本到图像生成。
S.2 架构和方法
ControlStyle 的架构如图 2 所示。
- 它使用预训练的稳定扩散模型作为主干(参数冻结),包括一个自动编码器,一个文本编码器和一个 U-Net,分别用于图像编码/解码、文本编码和噪声预测。
- 它使用可训练的调制网络对预训练的稳定扩散模型进行风格化。
- 调制网络利用输入文本,风格图像以及噪声潜在编码来生成既在结构上又在语义上与输入相关的风格特征。
- 这些风格特征被用来调制预训练的稳定扩散模型,以实现文本驱动的艺术风格图像生成。
- 调制网络是从稳定扩散中的 U-Net 的编码器和中间块初始化的,并通过零卷积层连接到 U-Net 的解码器块。
为提升生成质量,本文为目标 loss 添加了扩散内容和风格正则化项,流程如图 2 右所示。
扩散风格正则化旨在鼓励合成图像与输入的风格图像具有相似的风格。
- 将模型重建的嵌入送到自动编码器的解码器生成中间特征。
- 将输入的风格图像送到自动编码器的编码器生成潜在编码。
- 扩散风格正则化旨在使每个上采样块的中间特征和潜在编码之间的全局统计(均值,方差)匹配。
扩散内容正则化用于防止由调制网络的风格特征对结构造成过大破坏。
- 从自动编码器的解码器获取输入内容图像的中间特征。
- 扩散内容正则化强制使重建的特征在空间上与输入内容图像的特征匹配。















 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









