







Exploring scalable medical image encoders beyond text supervision

目录
1. 引言
当前医疗影像编码器多依赖语言监督进行预训练,但这种方式受限于文本数据的描述性和隐私问题,难以充分捕获图像中的细节特征。获取大规模医疗图像-文本配对数据存在挑战,且文本描述常缺乏细节,限制了编码器的表现。
本文提出 RAD-DINO,一个 基于 DINOv2 自监督学习框架的医疗影像编码器,仅使用图像数据进行训练,在多个医学基准测试中表现出色,甚至超过了部分语言监督模型。
RAD-DINO 在分类、语义分割和报告生成等任务中均取得了优异的表现,并能够更好地提取患者人口统计学信息,显示出其在医疗领域的应用潜力。通过采用影像自监督学习,RAD-DINO 克服了语言监督的局限性,具有良好的可扩展性,为医疗影像分析提供了一种新方法。
1.1 关键词
医疗影像编码器、自监督学习、RAD-DINO、DINOv2、语义分割、图像分类、报告生成、医学图像
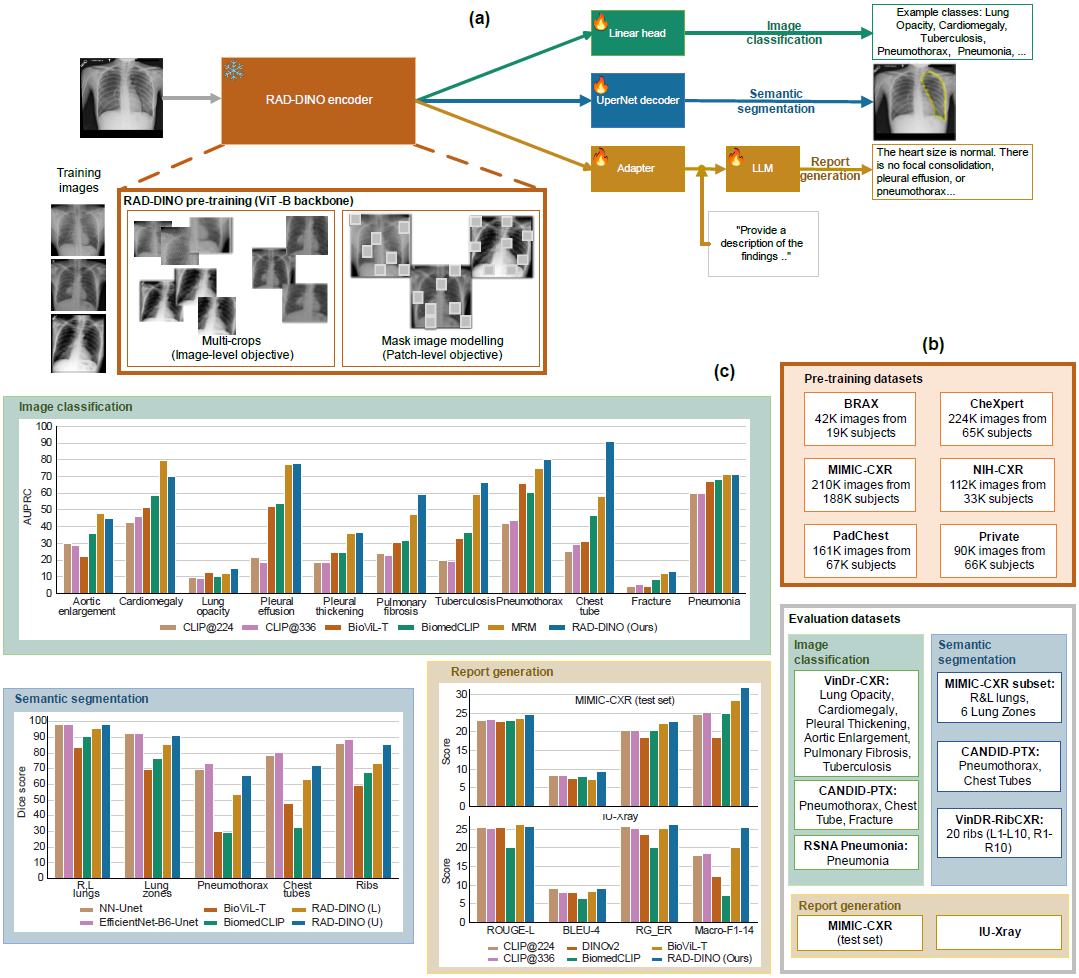
图 1:RAD-DINO 概览。
- (a)模型架构突出显示使用图像级和补丁(patch)级目标的训练过程,以及通过训练特定于任务的头应用于下游任务的预训练 RAD-DINO 编码器。
- (b)预训练和评估数据集摘要。
- (c)图像分类(表 1 a 和 1 b)、语义分割(表 3)和报告生成(表 2)下游任务的结果摘要。RAD-DINO(L)和 RAD-DINO(U)分别指线性和 UPerNet 解码器分割头。
2. 结果
2.1 RAD-DINO 在图像分类基准上的评估
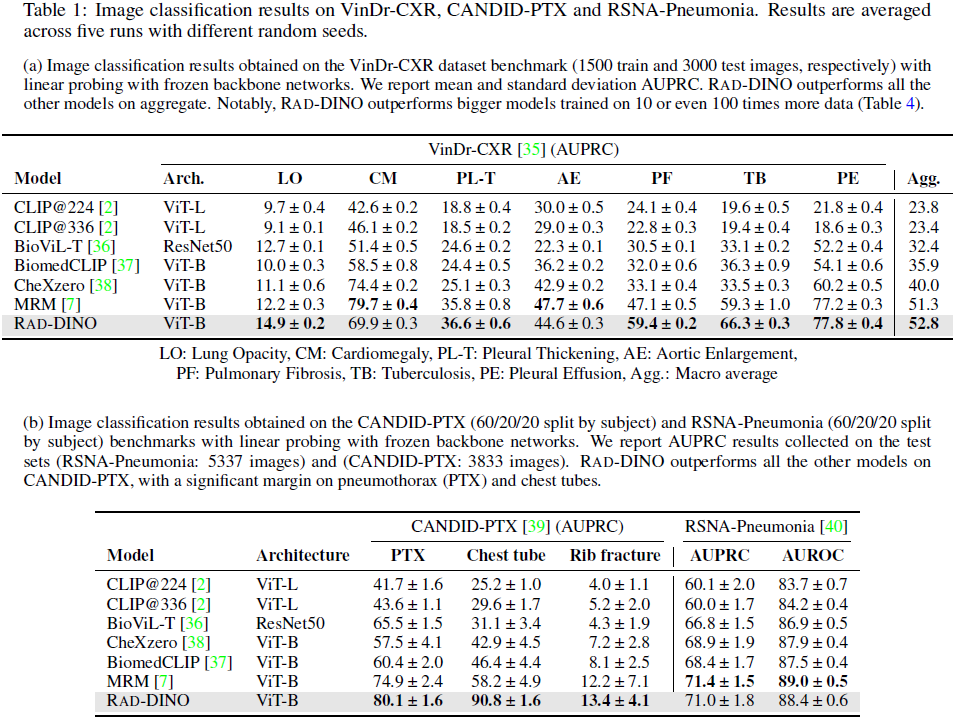
RAD-DINO 在 VinDr-CXR、CANDID-PTX 和 RSNA-Pneumonia 数据集上进行评估。
- 在 VinDr-CXR 数据集中,RAD-DINO 在大多数病理类别中表现优异,仅在心脏肥大(CM)和主动脉扩张(AE)两类中略逊于多模态方法。
- 在 CANDID-PTX 和 RSNA-Pneumonia 中,RAD-DINO 尤其在肺气胸(PTX)和胸管(Chest tube)类别上显著超越其他模型。
2.1.1 侧面 CXR 扫描
之前的分类实验只使用了正面胸部 X 光检查。然而,侧面扫描比正面扫描能更好地捕捉某些异常,因此也常用于消除发现的歧义。两张图像使用相同的文本报告。
许多研究发现在侧面扫描中看不清,这一事实大大减少了相互信息,并在学习过程中增加了噪音,使语言监督方法的效果降低。
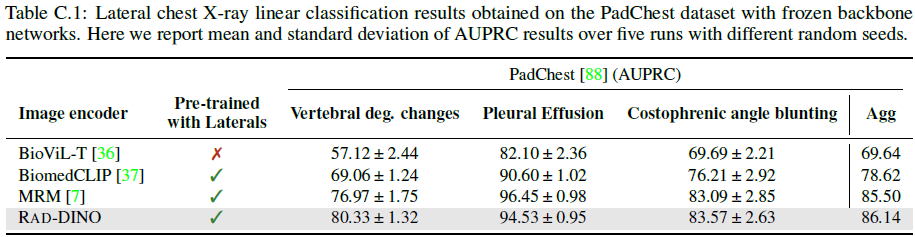
我们通过训练线性分类器来检测仅在侧面扫描中可见的异常来研究这一假设,并观察到 基于 MIM(RAD-DINO 和 Masked Record Modeling / MRM)的方法明显优于 CLIP 样式的模型(表 C.1)。
2.1.2 学习目标的影响
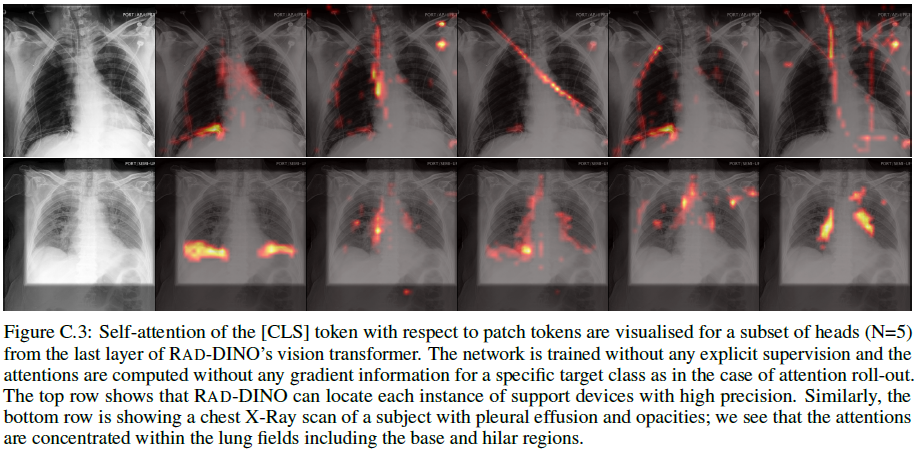
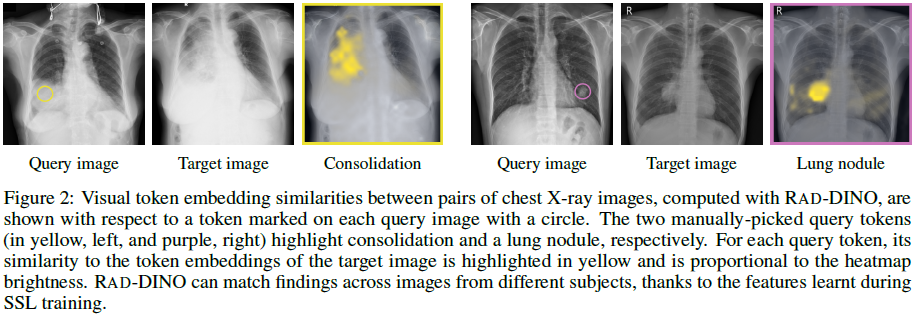
据观察,RAD-DINO 可以拾取局部纹理(参见图 C.3 中的自注意力图),我们将其归因于 掩蔽图像建模(Masked Image Modeling,MIM)和 多裁剪实例判别训练(multi-crop instance discrimination training)。
相似地,RAD-DINO 在训练期间捕获病理语义的不同受试者的扫描之间的补丁嵌入之间的对应关系(图 2)。DINO 受益于其多裁剪训练设置,因为它经过专门训练,可以对结构的局部和全局尺度保持不变,并且 MIM 在学习图像中存在的高频信息方面的重要性,而对比目标则有利于学习全局形状表示。
在肺炎线性探测任务中,我们观察到 CLIP 式主干具有热启动和更快的收敛速度,这可能是由于 肺炎相关图像发现(例如,混浊)在公共基准中广泛存在,且在放射学报告中有详细描述。这种可用性可能有助于缩小不同基线之间的性能差距。
2.2 RAD-DINO 在影像生成报告任务中的评估
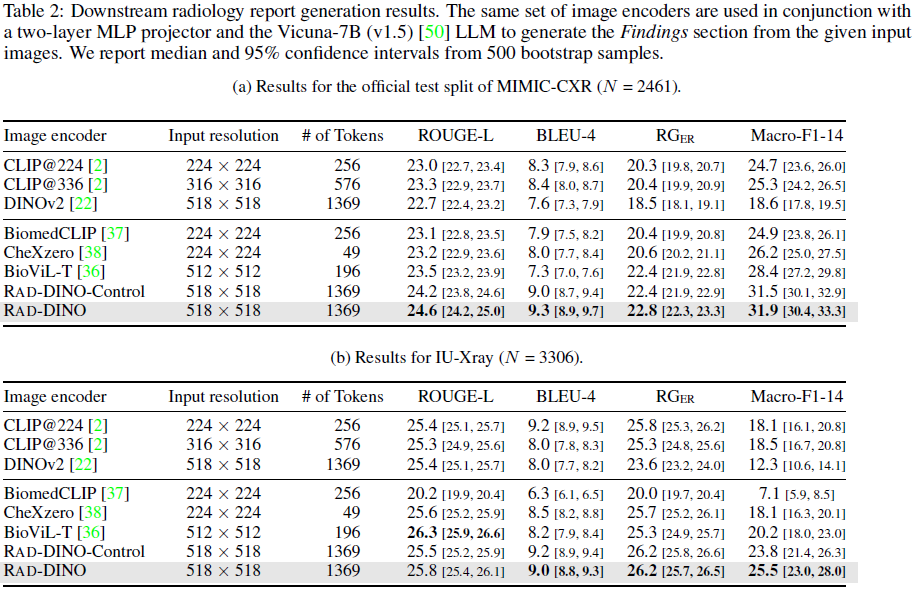
在 MIMIC-CXR 和 IU-Xray 数据集上,RAD-DINO 在所有评估指标上均超越其他编码器,特别是在医学事实准确性指标 Macro-F1-14 上表现突出。
实验还表明,RAD-DINO 在使用更小规模的同域数据训练时,依然优于其他编码器,说明 其性能优势并非仅来源于训练数据的规模。
2.3 RAD-DINO 在语义分割基准上的评估
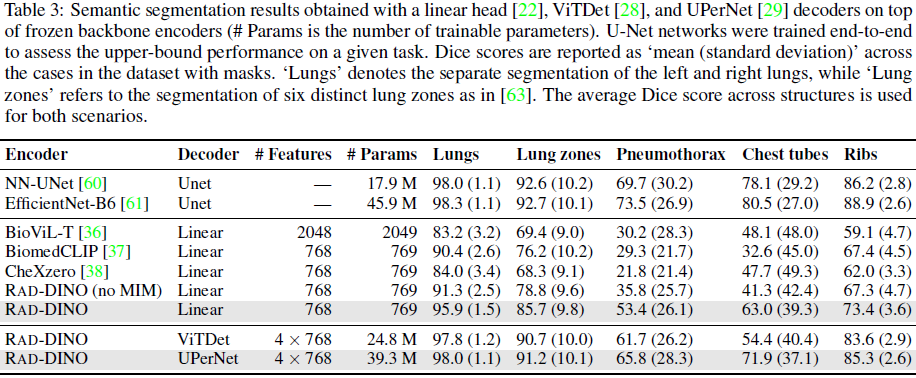
RAD-DINO 在所有分割任务中均取得高 Dice 分数。
- 相比于基于图像-文本的对比学习方法,RAD-DINO 捕捉到更丰富的像素级特征,尤其是在小目标结构(如 Chest tubes)上表现突出。
- 实验还发现,掩码图像建模(MIM)在医学影像分割中至关重要。
3. 方法与实验设置
3.1 DINOv2
RAD-DINO 采用 DINOv2 自监督学习 方法,基于视觉 Transformer(ViTs)进行优化训练。
DINOv2 使用 教师-学生网络结构,教师网络的预测通过指数移动平均 (EMA) 更新学生网络参数,实现图像表征学习。
训练过程中同时应用了 图像级和补丁级目标,前者通过 多视图裁剪 进行全局特征比对,后者通过 遮掩图像建模 (MIM) 训练局部特征。
DINOv2 结合 多裁剪训练,确保了影像编码器在语义分割等密集预测任务中的高性能,避免了传统自监督方法的 “模式坍缩” 问题。
(2021|ICCV,DINO,ViT,自监督学习,知识蒸馏)自监督视觉 Transformer 的新特性
3.2 训练设置
RAD-DINO 在多个大型放射学影像数据集上进行持续训练,总计 60k 训练步,批次大小为 640。与 DINOv2 的低-高分辨率两阶段训练不同,RAD-DINO 训练期间保持固定分辨率,并针对医学影像特点调整了数据增强策略,如增加裁剪尺寸和减少模糊处理,从而保留疾病的纹理和上下文信息,确保了高质量的影像编码器训练。
3.3 基线方法
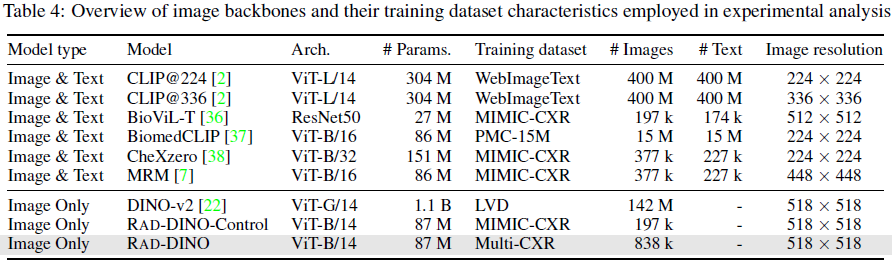
基线包括 CLIP(BioViL-T、BiomedCLIP)、CheXzero 等 图像-文本模型 及 MRM 多模态掩蔽建模 方法。
本文通过与这些基线方法比较,验证了图像自监督学习在医学影像中的可行性和有效性。
此外,评估还考虑了 输入分辨率、训练数据规模和领域特定预训练 等因素,确保了对比分析的多维度性和公平性。
3.4 下游评估任务
评估任务包括图像分类和语义分割,前者通过线性探测验证编码器的全局特征,后者则评估编码器的局部纹理提取能力。同时,本文还在 MIMIC-CXR 数据集上进行影像-文本报告生成任务,使用 Vicuna-7B 语言模型进行微调,以检测影像编码器在多模态任务中的适用性。
3.5 评估数据集和指标
评估使用了多个公开医学影像数据集(如VinDr-CXR、CANDID-PTX、RSNA-Pneumonia),通过精心设计的数据拆分,避免了同一患者数据泄漏。分类评估采用了宏平均 AUPRC,分割评估使用 Dice 系数,报告生成则通过 ROUGE-L、BLEU-4 和 Macro-F1-14 等指标进行量化。
3.6 RAD-DINO 对患者人口统计信息的提取能力
尽管患者的性别、年龄、体重和 BMI 等信息通常不在 X 光报告中明确记录,RAD-DINO 在预测这些人口统计学变量时显著优于基线模型,说明自监督学习捕获了更多成像特征,尤其是全局特征,如纵隔大小、脂肪层宽度等。这种能力对于医学诊断具有重要意义,尤其是在需要综合患者信息进行决策的场景中。

4. 讨论与结论
RAD-DINO验证了仅依赖影像数据即可训练出高质量的医学影像编码器,突破了文本监督方法的局限性。其在分类、分割和报告生成中的优异表现,源于其独立于文本描述而能捕获更丰富的影像特征。
RAD-DINO 为大规模医学影像数据的应用提供了可扩展性路径,尤其在病理学和超声等缺乏文本注释的领域。此外,其对高分辨率输入的良好支持,促进了更精细的影像分析。
未来,RAD-DINO 可能通过与 CLIP 方法结合,弥补在零样本分类和图像-文本检索方面的不足,拓展多模态应用领域。
论文地址:https://arxiv.org/abs/2401.10815
项目页面:https://huggingface.co/microsoft/rad-dino
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









