







目录
前言
环境什么就不在赘述,可以参考其他文章,也可以在线运行
CSDN在线运行地址:InsCode - 让你的灵感立刻落地
Python基础 - 从数据类型到面向对象_for var in vartuple-CSDN博客
python入门-从安装环境配置(Anaconda)到做一个下班打卡提醒.exe小工具_开发电脑软件提醒下班-CSDN博客
数据结构
数字、字符串、列表、元组、字典
数字
Python Number 数据类型用于存储数值,包括整型、长整型、浮点型、复数。
数学运算
import math
print("1.1向上取整:", math.ceil(1.1)) # 返回数字的上入整数
print("1.9向下取整:", math.floor(1.9)) # 返回数字的下舍整数
print("-2:的绝对值:", math.fabs(-2)) # 返回数字的绝对值
print("3的平方根:", math.sqrt(3)) # 返回数字的平方根
# math.exp(1) 会打印出自然数 e(约等于 2.71828)的指数值,因为 math.exp() 函数用于计算一个数的自然指数(以 e 为底)。当参数为 1 时,它计算的就是 e 的 1 次方,即 e 本身。
print("返回e的x次幂:", math.exp(1)) # 返回e的x次幂(自然指数)
print("3的2次方:", math.pow(3, 2)) # 返回 x 的 y 次方。
print("2的阶乘:", math.factorial(2)) # 返回数字的阶乘
print("78和186的最大公约数:", math.gcd(78, 186)) # 返回 x 和 y 的最大公约数
print("是否是无穷数:", math.isinf(3.1415926)) # 如果数字是正无穷或负无穷,返回 True。
print("是否是NaN:", math.isnan(33)) # 如果 x 是 NaN(不是一个数字),返回 True。
print("π 的值:", math.pi) # math.pi:π 的值。
print("角度转换弧度:", math.radians(30)) # 将角度转换为弧度
print("弧度转换角度:", math.degrees(1)) # 弧度转换为角度。1.1向上取整: 2
1.9向下取整: 1
-2:的绝对值: 2.0
3的平方根: 1.7320508075688772
返回e的x次幂: 2.718281828459045
3的2次方: 9.0
2的阶乘: 2
78和186的最大公约数: 6
是否是无穷数: False
是否是NaN: False
π 的值: 3.141592653589793
角度转换弧度: 0.5235987755982988
弧度转换角度: 57.29577951308232
随机数
import random
print(random.random()) # 生成一个 [0.0, 1.0) 之间的随机浮点数
print(random.randint(1,20)) # 生成一个指定范围内的随机整数,范围在1-20 之间
# 0.346862053678905
# 18更多
random.uniform(1, 10) # 生成一个指定范围内的随机浮点数,范围在 [1, 10) 之间。 random.randrange(10) # 生成一个从0到9(包含0但不包含10)的随机整数 random.randrange(1, 10) # 生成一个从0到9(包含0但不包含10)的随机整数 random.randrange(0, 100, 2) # 生成一个从0到99(包含0但不包含100)的随机整数,步长为2(每次增加的数量)本示例会跳过非 2 的倍数的整数 seq = ['apple', 'banana', 'cherry', 'date', 'elderberry'] random.choice(seq) # 从序列 seq 中随机选择一个元素。 random.shuffle(seq) # 将序列seq随机打乱顺序 random.sample(seq, 3) # 从seq中随机选择3个元素,返回一个列表。 random.seed(a=None) # 设置随机数生成器的种子值。如果是None或者未提供,则使用当前系统时间。 random.getrandbits(5) # 生成一个5位长的随机无符号整数。它的范围是从 0 到 2**k - 1, 0 到 2 的 k 次方减 1 之间的随机整数。 random.expovariate(0.5) # 生成一个指数分布的随机浮点数,其中0.5是分布的参数。越大,分布就越向右倾斜,意味着事件发生的频率越高。 random.gammavariate(alpha, beta) # 生成一个伽马分布的随机浮点数,其中alpha和beta是分布的参数。 random.gauss(mu, sigma) # 生成一个正态(高斯)分布的随机浮点数,其中mu是均值,sigma是标准差。
字符串
# 字符串连接:+
print("Hello " + "World ")
# 重复输出字符串:*
print('a ' * 3)
# 首字母大写,其余字母小写
print("hello World".capitalize())
# 所有大写字母转换为小写
print("HELLO WORLD".lower())
# 所有小写字母转换为大写
print("hello world".upper())
# 将字符串中的大写字母转换为小写,小写字母转换为大写。
print("Hello World".swapcase()) # 输出 "hELLO wORLD"
# 将字符串中每个单词的首字母大写,其余字母小写。
print("hello world".title()) # 输出 "Hello World"
# 通过索引获取字符串中字符[]
print("Hello"[0])
# 字符串截取[:] :左闭右开
print("Hello"[1:3])
# 判断字符串中是否包含给定的字符: in, not in
print('e' in 'Hello')
print('e' not in 'Hello')
# join():以字符作为分隔符,将字符串中所有的元素合并为一个新的字符串
print('-'.join('Hello'))
# 字符串单引号、双引号、三引号(纯文本,包括引号和特殊字符串)
print('Hello World!')
print("Hello World!")
print('''I'm going to the movies''')
# 转义字符 \
print("The \t is a tab")
# 返回字符串的长度
print(len("hello")) # 输出 5
# 计算子字符串 substr 在字符串中出现的次数。
print("banana".count("a")) # 输出 3
# 查找子字符串在字符串中首次出现的位置。如果未找到,find() 返回 -1,而 index() 会引发 ValueError 异常
print("banana".find("a")) # 输出 1
print("banana".index("a")) # 输出 1
# 字符串替换
print("banana".replace("a", "o")) # 输出 "bonono"
# 以 , 为分隔符将字符串分割成一个列表。如果 maxsplit 指定了,则最多分割 maxsplit 次。
print("apple,banana,cherry".split(",")) # 输出 ['apple', 'banana', 'cherry']
# 移除字符串开头和结尾的空白字符
print(" hello ".strip()) # 输出 "hello"
# 仅移除左侧的空白字符、仅移除右侧的空白字符。
print(" hello ".lstrip()) # 输出 "hello "
print(" hello ".rstrip()) # 输出 " hello"
# 检查字符串是否以指定的前缀或后缀开始或结
print("banana".startswith("ban")) # 输出 True
print("banana".endswith("ana")) # 输出 True
# 格式化字符串
name = "Alice"
age = 25
print("My name is {} and I am {} years old.".format(name, age))
列表
类似其他语言中的数组
# 声明一个列表
names = ['jack', 'tom', 'tonney', 'superman', 'jay']
# 通过下标或索引获取元素
print(names[1]) # tom
# 获取最后一个元素
print(names[-1]) # jay
print(names[len(names) - 1]) # jay
# 获取第一个元素
print(names[-5]) # jack
# 遍历列表,获取元素
for name in names:
print(name)
# 列表元素添加
names.append('杨超越')
# 一次添加多个。把一个列表添加到另一个列表 ,列表合并。
models = ['刘雯', '奚梦瑶']
names.extend(models)
print(names)
# 列表元素修改
names[-1] = 'strawberry'
# 列表元素删除
del names[0]
names.remove('杨超越')
names.pop(0)
# 列表切片,根据下标切取列表,返回列表
print(names) # ['tonney', 'superman', 'jay', '刘雯', 'strawberry']
print(names[-1:]) # ['strawberry']
print(names[2:5]) # ['jay', '刘雯', 'strawberry']
list = [0, 10, 3, 5, 8]
# 默认升序
print(sorted(list))
# 降序
print(sorted(list, reverse=True))
# 在指定索引处插入一个元素
list.insert(1, 100)
# 返回列表中某个元素的出现次数
list.count(1)
# 反转列表中的元素
list.reverse()
# 将可迭代对象转换为列表
list(iterable)
# 移除列表中的所有元素
list.clear()
元组
与列表类似,元组中的内容不可修改,元组类型提供了一些常用的内置函数来操作元组
# 相连
t1 = (1, 2, 3) + (4, 5)
print(t1) # (1, 2, 3, 4, 5)
# 乘2
t2 = (1, 2) * 2
print(t2) # (1, 2, 1, 2)
# 将可迭代对象转换为元组。
t = tuple([1, 2, 3]) # 从列表转换为元组
# 返回元组中的元素个数。
t = len((1, 2, 3))
# 返回元组中的最大值
t = (1, 3, 2)
print(max(t)) # 输出 3
# 返回元组中的最小值。
t = (1, 3, 2)
print(min(t)) # 输出 1
# 返回元组中所有元素的和(仅适用于数值类型元素)。
t = (1, 2, 3)
print(sum(t)) # 输出 6
# 返回元组中某个值出现的次数。
t = (1, 2, 3, 2, 1)
print(t.count(2)) # 输出 2
# 返回元组中第一个匹配值的索引,如果没有找到则引发ValueError。
t = (1, 2, 3)
print(t.index(2)) # 输出 1
# 使用切片操作从元组中获取子序列。
t = (0, 1, 2, 3, 4, 5)
print(t[1:4]) # 输出 (1, 2, 3)
字典
# list可以转成字典,但前提是列表中元素都要成对出现
dict3 = dict([('name', '杨超越'), ('weight', 45)])
# clear(): 移除字典中的所有项。
my_dict = {'a': 1, 'b': 2}
my_dict.clear() # {}
# 返回字典的一个浅复制。
my_dict = {'a': 1, 'b': 2}
copy_dict = my_dict.copy() # {'a': 1, 'b': 2}
# 返回指定键的值,如果键不存在则返回默认值。
my_dict = {'a': 1, 'b': 2}
print(my_dict.get('a')) # 输出 1
print(my_dict.get('c')) # 输出 None
print(my_dict.get('c', 0)) # 输出 0
# 返回字典中所有键值对的视图。
my_dict = {'a': 1, 'b': 2}
items_view = my_dict.items()
print(items_view) # dict_items([('a', 1), ('b', 2)])
# 返回字典中所有键的视图。
my_dict = {'a': 1, 'b': 2}
keys_view = my_dict.keys() # keys_view现在是dict_keys(['a', 'b'])
# 移除并返回指定键的值,如果键不存在则返回默认值。
my_dict = {'a': 1, 'b': 2}
print(my_dict.pop('a')) # 输出 1
print(my_dict.pop('c', 0)) # 输出 0
# my_dict现在是{'b': 2}
# 移除并返回字典中的最后一个键值对(随机)。
my_dict = {'a': 1, 'b': 2}
print(my_dict.popitem()) # 输出 ('b', 2) 或 ('a', 1),取决于Python实现
# my_dict现在是{'a': 1} 或 {'b': 2}
# 如果键在字典中,返回它的值;否则,插入键和默认值,并返回默认值。
my_dict = {'a': 1, 'b': 2}
print(my_dict.setdefault('a', 0)) # 输出 1
print(my_dict.setdefault('c', 0)) # 输出 0,且'c': 0被添加到字典中
# my_dict现在是{'a': 1, 'b': 2, 'c': 0}
# 使用另一个字典更新当前字典。
my_dict = {'a': 1, 'b': 2}
my_dict.update({'b': 3, 'c': 4})
# my_dict现在是{'a': 1, 'b': 3, 'c': 4}
# 返回字典中所有值的视图。
my_dict = {'a': 1, 'b': 2}
values_view = my_dict.values()
# values_view现在是dict_values([1, 2])
面向对象
class Animal:
# init()定义构造函数,与其他面向对象语言不同的是,Python语言中,会明确地把代表自身实例的self作为第一个参数传入
# init()方法接收参数,使用点号 . 来访问对象的属性
def __init__(self, name):
self.name = name
print('动物名称实例化', name)
# 创建一个实例化对象 cat,
def eat(self):
print(self.name + '要吃东西啦!')
def drink(self):
print(self.name + '要喝水啦!')
cat = Animal('dog')
print(cat.name)
cat.eat()
cat.drink()动物名称实例化 dog
dog
dog要吃东西啦!
dog要喝水啦!
class Dog(Animal): # 定义子类
def __init__(self, name):
super().__init__(name)
print('调用子类构造方法')
def study(self):
print('调用子类方法')动物名称实例化 旺财
调用子类构造方法
调用子类方法
旺财要吃东西啦!
JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。
import json
# Python 对象编码成 JSON 字符串
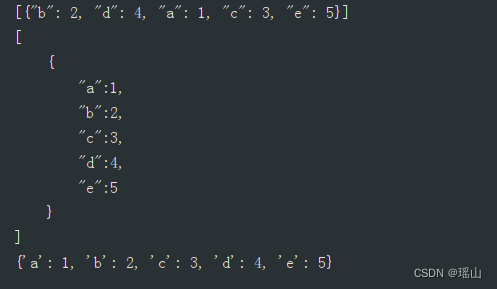
data = [{'b': 2, 'd': 4, 'a': 1, 'c': 3, 'e': 5}]
jsonStr = json.dumps(data)
print(jsonStr)
# sort_keys=True表示按照字典排序(a到z)输出。
# indent参数,代表缩进的位数
# separators参数的作用是去掉,和:后面的空格,传输过程中数据越精简越好
jsonStr = json.dumps(data, sort_keys=True, indent=4, separators=(',', ':'))
print(jsonStr)
# 将string转换为dict
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}'
text = json.loads(jsonData)
print(text)
文件操作
# 打开一个文件并返回文件对象。filename 是文件名,mode 是文件访问模式,默认为 'r'(只读)。其他常见的模式包括 'w'(写入,如果文件已存在则覆盖)、'a'(追加,如果文件已存在则在文件末尾添加内容)、'r+'(读写)等。
import os
f = open("test1.py", mode='r')
# 读取文件内容。size 参数指定读取的字节数,如果为负数或省略,则读取整个文件。
f.read(size=-1)
# 读取文件的一行。size 参数指定读取的字节数。
f.readline(size=-1)
# 读取文件的所有行并返回一个包含每行内容的列表。sizehint 参数是一个可选参数,用于指定读取的行数。
f.readlines(sizehint=-1)
# 将字符串写入文件。
f.write("string")
# 将一个字符串列表写入文件。
f.writelines(["1", "2", "3"])
# 改变文件对象的当前位置。offset 参数表示偏移的字节数,whence 参数指定起始位置,默认为 0(文件开头),其他可选值包括 1(当前位置)和 2(文件末尾)。
f.seek(offset, whence=0)
# 返回文件对象的当前位置。
f.tell()
# 刷新文件对象的缓冲区,确保所有待写入的数据都被写入文件。
f.flush()
# 关闭一个打开的文件。
f.close()
os.path.exists(path) # 检查文件或目录是否存在。
os.path.isfile(path) # 检查指定路径是否为文件。
os.path.isdir(path) # 检查指定路径是否为目录。
os.path.getsize(path) # 返回文件的大小(以字节为单位)。
os.remove(path) # 删除文件。
os.rename(src, dst) # 重命名文件或目录。
os.makedirs(path, exist_ok=False) # 递归创建目录。如果 exist_ok 为 True,则当目录已存在时不会引发异常。
os.rmdir(path) # 删除目录(必须为空)。
# 使用 with 语句可以自动处理文件的打开和关闭,避免忘记关闭文件。例如:
with open('file.txt', 'r') as f:
content = f.read()
扩展
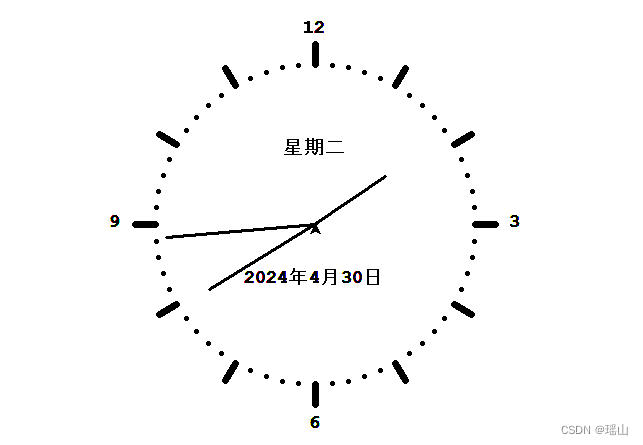
制作一个简易时钟
import turtle
import datetime
# 悬空移动
def move(distance):
turtle.penup()
turtle.forward(distance)
turtle.pendown()
# 创建表针turtle
def createHand(name, length):
turtle.reset()
move(-length * 0.01)
turtle.begin_poly()
turtle.forward(length * 1.01)
turtle.end_poly()
hand = turtle.get_poly()
turtle.register_shape(name, hand)
# 创建时钟
def createClock(radius):
turtle.reset()
turtle.pensize(7)
for i in range(60):
move(radius)
if i % 5 == 0:
turtle.forward(20)
move(-radius - 20)
else:
turtle.dot(5)
move(-radius)
turtle.right(6)
def getWeekday(today):
return ['星期一', '星期二', '星期三', '星期四', '星期五', '星期六', '星期日'][today.weekday()]
def getDate(today):
return '%s年%s月%s日' % (today.year, today.month, today.day)
def startTick(second_hand, minute_hand, hour_hand, printer):
today = datetime.datetime.today()
second = today.second + today.microsecond * 1e-6
minute = today.minute + second / 60.
hour = (today.hour + minute / 60) % 12
# 设置朝向
second_hand.setheading(6 * second)
minute_hand.setheading(6 * minute)
hour_hand.setheading(12 * hour)
turtle.tracer(False)
printer.forward(65)
printer.write(getWeekday(today), align='center', font=("Courier", 14, "bold"))
printer.forward(120)
printer.write('12', align='center', font=("Courier", 14, "bold"))
printer.back(250)
printer.write(getDate(today), align='center', font=("Courier", 14, "bold"))
printer.back(145)
printer.write('6', align='center', font=("Courier", 14, "bold"))
printer.home()
printer.right(92.5)
printer.forward(200)
printer.write('3', align='center', font=("Courier", 14, "bold"))
printer.left(2.5)
printer.back(400)
printer.write('9', align='center', font=("Courier", 14, "bold"))
printer.home()
turtle.tracer(True)
# 100ms调用一次
turtle.ontimer(lambda: startTick(second_hand, minute_hand, hour_hand, printer), 100)
def start():
# 不显示绘制时钟的过程
turtle.tracer(False)
turtle.mode('logo')
createHand('second_hand', 150)
createHand('minute_hand', 125)
createHand('hour_hand', 85)
# 秒, 分, 时
second_hand = turtle.Turtle()
second_hand.shape('second_hand')
minute_hand = turtle.Turtle()
minute_hand.shape('minute_hand')
hour_hand = turtle.Turtle()
hour_hand.shape('hour_hand')
for hand in [second_hand, minute_hand, hour_hand]:
hand.shapesize(1, 1, 3)
hand.speed(0)
# 用于打印日期等文字
printer = turtle.Turtle()
printer.hideturtle()
printer.penup()
createClock(160)
# 开始显示轨迹
turtle.tracer(True)
startTick(second_hand, minute_hand, hour_hand, printer)
turtle.mainloop()
if __name__ == '__main__':
start()

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











