







GLocalKD
《Deep Graph-level Anomaly Detection by Glocal Knowledge Distillation》
2022 WSDM 会议
作者是Rongrong Ma、Guansong Pang、Ling Chen 和 Anton van den Hengel
论文地址见文末
摘要
图级异常检测( GAD )描述了与其他图相比,检测在其结构和/或其节点特征上异常的图的问题。GAD中的一个挑战是设计图表示,使其能够检测局部和全局异常的图,即分别在细粒度(节点级)或整体(图级)属性中异常的图。为了应对这一挑战,我们引入了一种新颖的GAD深度异常检测方法,该方法通过对图和节点表示的联合随机蒸馏来学习丰富的全局和局部正常模式信息。随机蒸馏是通过训练一个GNN来预测随机初始化网络权重的另一个GNN来实现的。在来自不同领域的16个真实世界图数据集上的大量实验表明,我们的模型显著优于7个最先进的模型。
代码和数据集 :https://git.io/GLocalKD
1、引言
图级异常检测( Graph-level Anomaly Detection,GAD )旨在识别与集合中大多数图显著不同的图。记录不同实体之间复杂关系的能力使得图成为现实世界应用中必不可少且广泛使用的表示方法。因此,图的异常检测在识别具有严重副作用的药物[ 18 ],从化合物图中识别有毒分子[ 1 ],以及破坏毒品走私网络[ 39 ]等方面有着广泛的应用。
尽管图数据的普遍存在以及图数据中异常检测的重要性,但与其他类型数据[ 2、28 ]中的异常检测相比,GAD很少受到关注。GAD中的一个主要挑战是学习具有表达能力的图表示,以捕获图结构和属性(例如,节点的描述性特征)中的局部和全局正常模式。
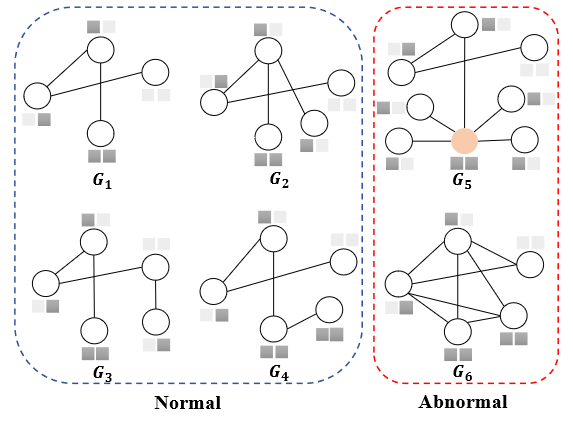
图1:一组有两个异常图表示的图形。节点上方/下方的正方形表示节点特征。
G5是一个局部反常图,因为它的橘色节点具有不寻常的局部性质(例如,结构),
G6是一个全局反常图,因为它不符合G1到G4的整体图性质。
这对于检测与单个节点及其**局部邻域(图1中G5)相关的局部异常图和与整体图特征(图1中G6)**相关的全局异常图都是必不可少的。
一个相关的研究路线是从单个图的时间演化序列中探索识别图结构的异常变化,其中不同时间步的大多数节点和结构都不改变[ 9、21、37、46、47、52]。相比之下,GAD需要在一组缺乏时间顺序进展的内聚性且具有多样化结构和节点特征的图中识别图异常,并且它的探索明显较少。
深度学习已经在各种表示学习任务中显示出巨大的成功,包括最近出现的基于图神经网络( GNN )的方法[ 43 ]。此外,基于自编码器( autoencoder,AE )的方法[ 7、11、54]、基于生成对抗网络( Generative adversarial network,GAN )的方法[ 24、34 ]和单类分类器[ 31、32、53]等深度异常检测模型在不同类型的数据(例如,表格数据,图像数据和视频数据)上表现出了良好的性能[ 28 ]。然而,将GNN用于GAD任务的工作非常有限。许多基于GNN的模型已经被引入图数据中的异常检测[ 8、13、16、41、51],但它们主要关注单个大图中的异常节点/边检测。
将基于AE和GAN的检测方法应用于GAD的一个挑战是它们依赖于基于重构误差的异常度量。这是因为从一个潜在的向量表示中忠实地重建(或生成)图仍然具有挑战性[ 43 ]。如文献[ 50 ]的对比研究表明,基于深度支持向量数据描述( Deep SVDD )的单类模型[ 32 ]可以通过在基于GNN的图表示之上直接优化SVDD目标来适应GAD,但它只专注于检测全局异常图。此外,SVDD的单类超球体假设在很大程度上限制了其性能,因为在现实世界的数据集中,正常类中往往存在更复杂的分布。
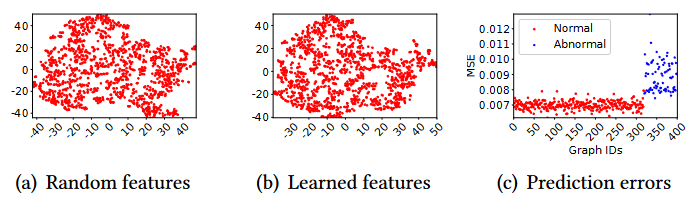
图2:GLocalKD在流行数据集AIDS上的演示。
( a )随机目标网络输出的训练图的表示。
( b )预测器网络学习到的训练图的表示。
( c ) GLocalKD在测试图上的预测误差(异常分数)。
( a ) 和 ( b )中的可视化是基于t - SNE的。
在本文中,我们提出了一种新颖的GAD深度异常检测方法,该方法通过联合随机蒸馏图和节点表示来学习全局和局部的正常模式- -全局和局部(即glocal )图表示蒸馏。随机表示蒸馏是通过训练一个GNN来预测一个随机GNN,它的神经网络权重固定为随机初始化,即预测网络学习产生与随机网络中相同的表示,如图2 ( a )和( b )所示。为了准确地预测这些固定的随机投影表示,预测器网络被强制用于学习训练数据中的所有主要模式。通过在图和节点表示上应用这种随机蒸馏,我们的模型在给定的训练图上学习glocal图模式。当训练数据由唯一(或大部分)正常图组成时,学习到的模式是多尺度图正则性/正态性信息的总结。因此,给定一个图显示节点/图级不规则/异常的这些学习到的模式,该模型不能准确地预测其表示,导致比正常图的预测误差大得多,如图2 ( c )所示。因此,可以将这种预测误差定义为异常得分来检测上述两种类型的图形异常。
据此,本文做出以下主要贡献:
我们将GAD问题建模为检测局部或全局异常图的任务( Sec.3.1 ),并在真实世界数据集中经验地验证了这两类图异常的存在( Sec.5.8 )。
我们介绍了一种新颖的深度异常检测框架,该框架对局部图正则性进行建模,并以端到端的方式学习图异常得分(步骤3.2 )。这导致了第一种方法专门设计来有效地检测这两种类型的异常图。
进一步从该框架中实例化出一个新的GAD模型,即全局和局部知识蒸馏( GLocalKD )。GLocalKD通过最小化逼近随机图卷积神经网络的图和节点级预测误差来实现图和节点表示的联合随机蒸馏( Sec.4 )。GLocalKD易于实现,不需要有挑战性的图生成,并且可以在小训练数据下有效地学习多样化的glocal正则模式。它对异常污染也表现出显著的鲁棒性,表明其在无监督(异常污染的无标签训练数据)和半监督(专属于正常训练数据)设置中的适用性。
在来自化学、医学和社交网络领域的16个真实世界数据集上的大量实验结果表明,( i ) GLocalKD显著优于7个最先进的竞争方法( Sec.5.4 );( ii ) GLocalKD比其他深度检测器具有更高的样本利用率( Sec.5.5 ),例如,它可以使用更少的95 %的训练样本来达到比竞争方法更高的准确率;( iii ) GLocalKD使用单一默认的GNN架构,在不同的异常污染率( Sec.5.6 )和表示的维度( Sec.5.7 )下表现非常稳定。
2、相关工作
随机目标网络(Random Target Network)
随机目标网络是一个图神经网络(GNN),其权重参数在初始化后被固定不变。这个网络的目的是提供一个随机的图和节点表示的基准。
目标网络通常是一个预先训练或固定权重的网络,用作其他网络的参考或目标。在一些深度学习技术中,目标网络的目的是提供一个稳定的参考,以便在训练过程中减少过拟合,并提高模型的鲁棒性。
预测网络(Predictor Network)
预测网络是另一个图神经网络,它的结构与随机目标网络相同,但是权重参数在训练过程中会被优化更新。预测网络的目标是学习如何预测随机目标网络的输出表示。
所以目标网络相当于是Teacher Model 预测网络相当于是Student Mode。
2.1 图层面异常检测
基于图的异常检测在最近几年引起了极大的关注[ 2 ],特别是最近出现的基于GNN的方法[ 8、13、16、41、51],但大多数研究集中在异常(例如:异常节点或边)在单个大图中的检测。下面我们对GAD的相关工作进行综述。
时间演化图。大多数现有的GAD研究都是识别时间演化图[ 9、17、21、37、46、47、52]序列中的异常图变化。然而,这些方法旨在处理具有非常相似结构的时间依赖图,难以推广到结构和/或描述特征变化较大的图。
静态图。在一组静态图中进行异常图检测的工作明显较少。一个研究方向是利用强大的图表示方法或图核进行GAD。最近的一些研究[ 25、50 ]通过应用现成的异常度量,如孤立森林(孤立森林) [ 20 ],局部离群因子( LOF ) [ 4 ],单类支持向量机( OCSVM ) [ 35 ],在高级图核(如Weisfeiler - Leman核( WL ) ) [ 36 ]和传播核( PK ) [ 23 ]学习的向量化图表示或图表示学习方法(如Graph2Vec 和InfoGraph )的基础上,显示出良好的GAD性能。这些方法的关键问题是独立于异常检测器学习图表示,从而导致次优的表示。另外,也有针对GAD的图级模式提取的研究[ 25 ]。然而,这些方法的性能受到限制,因为在来自不同领域或应用场景的图中,图级模式可能存在显著差异。
基于深度学习的方法。尽管深度异常检测在不同类型的数据中取得了巨大成功[ 28 ],但在GAD方面所做的工作非常有限。深度图学习技术,如图卷积网络( GCN ) [ 15 ]和图同构网络( GIN ) [ 45 ],已经成为强大的图表示学习工具,为多样化的下游任务[ 43、49 ]赋能。现有的大多数深度异常检测方法[ 7、11、27、29、31、32、34、53、54]严重依赖于数据重建/生成模型。因此,重建/生成图的困难在很大程度上阻碍了这些深度GAD方法的发展。Zhao等人[ 50 ]对GAD进行了大量的评估研究,表明Deep SVDD目标[ 32 ]可以应用在基于GNN的图表示之上,从而使GAD成为可能。然而,它只关注于高层的图异常,其性能也受到SVDD度量的限制。
2.2 知识蒸馏
知识蒸馏( Knowledge Distillation,KD ),最初的目标是训练一个简单的模型,在保持与大模型相似精度的情况下提取大模型的知识,首先在[ 12 ]中被引入,然后在一些研究中扩展到异常检测[ 3、10、19、33、44]。所有这些方法都训练了一个简单的学生网络,以便在大规模数据上提取预训练的教师网络的知识,如在ImageNet [ 3,33 ]上预训练的ResNet / VGG网络。
然而,对于图级数据上的学习任务,目前还没有这种通用的预训练教师网络可用;此外,不同领域的图数据库之间存在显著差异,这也阻碍了该类方法在GAD任务中的应用。随机知识蒸馏最初是在[ 5 ]中引入的,用于解决深度强化学习( DRL )中的稀疏奖励问题。它采用随机蒸馏法将衡量状态新颖性的误差作为一些额外的奖励信号,以鼓励DRL代理在稀疏奖励环境下的探索。这种思想在[ 40 ]中也被用来正则化无监督的表示学习,从而能够更好地在表格数据上进行异常检测。受此启发,我们设计了GLocalKD模型来联合学习全局和局部敏感的图正规性。据我们所知,这是第一个专门为深度图级异常检测而设计的方法,并用于检测两种类型的图异常。
3、框架
3.1 问题陈述
这项工作解决了端到端的图级异常检测问题。具体来说,给定一组M个正常图G = { G1,…,GM },我们旨在学习一个以Θ为参数的异常得分函数f:G→R,使得当( G ^ \hat{G} G^j比( G ^ \hat{G} G^i更符合G )时,f ( G ^ \hat{G} G^i ; Θ) > f ( G ^ \hat{G} G^j ; Θ)。
哪个子图更符合G,谁的异常得分就低,反之就高。
在图 G 中,每个图记为 G = ( VG、EG),其顶点/节点集合为VG,边集合为EG。每个图G的图结构可以用一个邻接矩阵 A∈RN×N 来表示,其中N是图G中的节点数,如果节点vi和vj之间存在一条边 ( vi , vj)∈EG,则 A(i , j) = 1,否则 A( i , j ) = 0。
邻接矩阵
如果图G是一个属性图,则图G的每个节点 vi∈VG 进一步与一个特征向量 xi∈Rn 相关联。否则为平面图。
属性图多一个特征矩阵
实验表明,我们的方法可以灵活地处理两种类型的图数据(见表1,在后面的实验结果部分),并且在无监督的情况下也表现良好,其中G是异常污染的并且包含一些未知的异常图( Sec.5.6 )。
图集中的反常图可以分为两类,即局部反常图和全局反常图,分别定义如下。
定义1 (局部异常图)。给定一个图数据集G = { Gi } Mi,其中每一个图G∈G都记为G = ( VG、EG),如果图 G ^ \hat{G} G^中存在一些异常点v,使得Vu∈V G ^ \hat{~G~} G ^与图G中的相似点明显偏离,则称图 G ^ \hat{G} G^是一个局部异常图.

定义2 (全局-异常图)。给定一个图数据集G = { Gi } Mi,如果图 G ^ \hat{~G~} G ^的全图性质与图G中的图不一致,则称图 G ^ \hat{~G~} G ^是一个全局反常图。

我们旨在训练一个能够检测这两类异常图的检测模型。值得注意的是,局部异常图的检测不同于[ 8、13、16、41]中的异常节点检测,因为前者是通过评估一组独立且独立的图中的节点/边来检测图,而后者是给定一组从单个图中独立的节点和边来检测节点/边。
- 局部异常图检测关注的是多图数据集中每个图的局部特征或子结构是否与数据集中的其他图存在显著差异。
- 异常节点检测则是在一个单一图的上下文中,根据节点之间的依赖关系来识别那些行为异常的节点。
3.2 提出的框架
为了解决上述问题,我们提出了一个端到端的评分框架,该框架综合了两个图神经网络,并联合图和节点表示的随机知识蒸馏来训练一个深度异常检测器。由此得到的模型可以有效地检测出两类异常图。
3.2.1 框架概述
我们的框架联合提取每个图的图级和节点级表示,以学习全局和局部的图正规性信息。它由两个图神经网络组成- -一个固定的随机初始化目标网络和一个预测器网络- -具有完全相同的体系结构和两个蒸馏损失。它通过训练预测器网络来预测随机目标网络产生的图(节点)级表示,从而学习整体(细粒度)的图正规性。
设 hG 和 h ^ \hat{~h~} h ^G分别是由预测网络和目标网络生成的图表示,hi 和 h ^ \hat{~h~} h ^i 分别是由这两个网络生成的图 G 中节点 vi 的节点表示,我们的方法的总体目标可以表示为
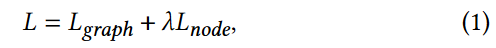
其中 λ 是平衡两个损失函数重要性的超参数,Lgraph和Lnode分别是图级和节点级蒸馏损失函数:
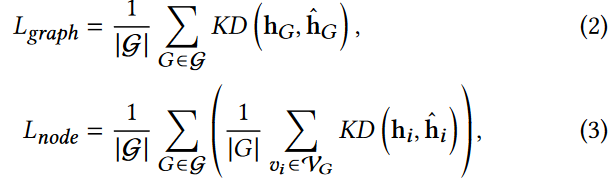
其中KD( · , ·)是度量两个特征表示之间差异的蒸馏函数,|  |是
|是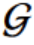 中的图的个数。
中的图的个数。
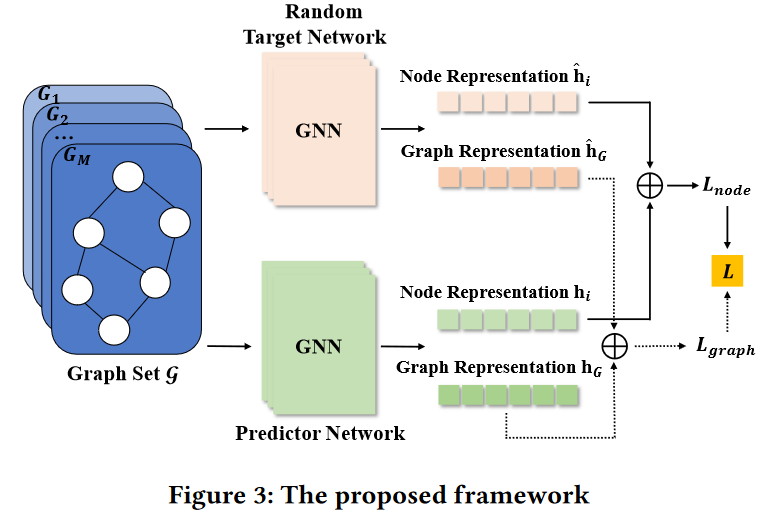
图3:提出的框架
==我们的框架的训练阶段的整体过程==如图3所示,其工作如下:
- 我们首先随机初始化一个图网络 ∅ ^ \hat{∅} ∅^ 为目标网络,并固定其权重参数 Θ ^ \hat{Θ} Θ^ 。对于每个给定的图G,它将产生一个图级表示 h ^ \hat{~h~} h ^G和在图 G 中每个节点 Vi 的节点级表示 h ^ \hat{~h~} h ^i。
- 一个与 ∅ ^ \hat{∅} ∅^ 具有相同结构的预测网络 ∅ ^ \hat{∅} ∅^ 被 Θ 参数化,并被训练来预测目标网络 ∅ ^ \hat{∅} ∅^ 的表示输出。也就是说,对于任意给定的图 G,它给出了图的层次表示hG和节点的层次表示hi,∀Vi∈VG .
- 最后,对于图G,将 h ^ \hat{~h~} h ^G,h G, h ^ \hat{~h~} h ^i 和 hi 整合到一个损失函数L中,通过最小化损失函数来训练预测网络 𝜙。
在评估阶段,给定图G的异常得分定义为:
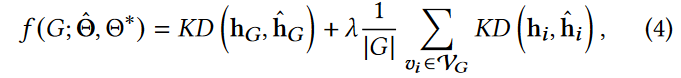
其中**Θ∗**是预测器网络的学习参数。
3.2.2 关键直觉
图的图级和节点级表示由GNNs学习得到,其强大的捕捉图结构和语义信息的能力已在各种学习任务和应用中得到证明。我们的框架中的联合随机蒸馏迫使预测网络的图表示和节点表示都尽可能地接近固定随机目标网络在正常图数据上的对应输出。这类似于(或频繁或不频繁)中提出的不同模式的提取分别对图和节点进行随机表示。如果一个模式频繁地出现在随机表示空间中,那么该模式就会被更好地提取出来,即公式中的预测误差。公式 2 或 3 由于模式样本量较大而较小;反之,预测误差较大。**因此,我们的联合随机蒸馏从图和节点表示中学习这种规律性信息。**对于一个给定的测试图G,如果它在图或节点级别上不符合嵌入在训练图集中的正则信息,例如图1中的 G5 和 G6 ,那么它的异常分数f ( G ;
Θ
^
\hat{Θ}
Θ^ , Θ∗)将会很大;否则,f ( G ;
Θ
^
\hat{Θ}
Θ^ , Θ∗)很小,如图1中的G1 - G4 。
- 样本量大,误差小:当某个模式或特征在训练数据中有大量的样本时,模型有更多的机会学习到这个模式,从而使得预测误差较小。这是因为模型可以通过观察多个样本来“学习”到一个模式的共性。
- 样本量小,误差大:相反,如果某个模式在训练数据中出现的频率较低,即样本量小,模型可能无法充分学习到这个模式,导致预测误差较大。
差异大的节点,分数大,差异小的节点分数小。
4、图和节点表示的联合随机蒸馏
提出的框架被实例化为全局和局部知识蒸馏( GLocalKD )的方法,其中我们使用广泛使用的图卷积网络( GCN )来学习节点和图表示,联合蒸馏由两个基于均方误差的损失函数驱动。
4.1 图神经网络架构
4.1.1 随机目标网络
我们首先建立一个随机初始化权重的目标网络,以获得随机空间中的图和节点级别的表示。可以使用不同的图表示方法来生成所需的表示,作为预测器网络的预测目标。理论上,各种深度图网络,如 GCN,GAT 和 GIN,都可以用作图表示学习模块。在我们的工作中,使用了一个标准的GCN,因为GCN及其变体已经证明了它们学习图的表达特征的能力和良好的计算效率[ 43、49 ]。
具体来说, ∅ ^ \hat{∅} ∅^( · , Θ ^ \hat{Θ} Θ^):G = ( VG、EG) → RN×k 是具有固定随机初始化权重 Θ ^ \hat{Θ} Θ^ 的GCN。(也就是说, GCN在随机权重初始化后被冻结),其中 N 是 G 中的节点数,k 是预先定义的节点表示的维度大小。对于图 G 中的每个图 G = ( VG、EG), ∅ ^ \hat{∅} ∅^( · ) 以邻接矩阵 A 和特征矩阵 X 为输入,并将每个节点 vi∈VG 用 Θ ^ \hat{Θ} Θ^ 映射到表示空间。设 h ^ \hat{~h~} h ^ Li 为第 L 层的节点 vi的隐藏表示,其形式化计算如下:
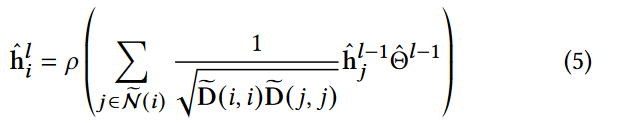
简单来说,这个公式通过聚合来自其邻居的信息,并应用一个非线性激活函数,来更新节点在图卷积网络中的表示。这种方法允许网络捕捉到图中的结构信息,并用于学习节点的高级特征表示。
其中 h ^ \hat{~h~} h ^ L-1i表示节点 vj 在第 L-1 层的隐表示,ρ ( a ) = max ( 0 , a )为ReLU激活函数。 N ( i )表示v~的1阶邻居, N ^ \hat{~N~} N ^ ( i ) = N ( i )∪{ vi },D是一个对角度矩阵,且D( i , i) = Σ j A( i , j ) 。 D ^ \hat{~D~} D ^ = D + I ( I 为单位矩阵),第0层的输入表示为vi, h ^ \hat{~h~} h ^ 0i,由其在 X 中的特征向量初始化,即 h ^ \hat{~h~} h ^ 0i= X( i , 😃。因此,节点 vi 的输出随机节点表示 h ^ \hat{~h~} h ^i可以写成:

公式 (6) 在提供的文档中定义了节点在图卷积网络(GCN)中的最终表示。这个表示是通过随机初始化的目标网络(target network)计算得到的,用于后续的训练和预测。
这为模型提供一个基准,即在没有任何训练数据偏差的情况下的节点表示,这些表示将作为训练预测器网络的参考。通过最小化预测器网络输出和这些随机目标表示之间的差异,预测器网络被迫学习到能够准确反映图结构和节点特征的表示。
式中:K为 ∅ ^ \hat{∅} ∅^ (.)的层数。特征矩阵 X 由属性图的节点属性组成。对于平面图,根据文献[ 48 ],我们使用节点度作为节点特征来构造一个简单的 X,因为节点的度是节点和图可区分性的关键信息之一。
接下来,对节点表示进行READOUT操作,得到图G的图级表示。这里引入了大量的READOUT操作,如maxing、average、sum和连接[ 43、49 ]。考虑到我们的目标是检测异常,我们需要在节点表示中聚合极端特征。因此,在READOUT操作中使用了最大池化:
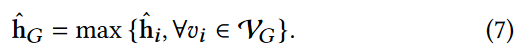
在图神经网络(Graph Neural Networks, GNNs)的上下文中,Readout 是一个操作,它将图中所有节点的表示聚合起来,以生成整个图的单一表示。
Readout 操作有多种不同的方法,以下是一些常见的 Readout 策略:
- 和(Sum):将所有节点的表示向量逐元素相加,得到图级别的表示。
- 平均(Mean):计算所有节点表示的元素平均值,以生成图的表示。
- 最大池化(Max Pooling):从所有节点表示中选取最大的值,这有助于捕获图中最显著的特征。
- 拼接(Concatenation):将所有节点的表示向量串联起来,形成一个长向量。
- 加权和(Weighted Sum):给每个节点的表示分配一个权重,然后计算加权求和。
- 注意力机制(Attention Mechanism):使用注意力机制来为每个节点的表示分配不同的权重,这些权重基于节点的重要性动态计算。
4.1.2 预测网络
预测器网络是用于预测目标网络的输出表示 h ^ \hat{~h~} h ^i 和 h ^ \hat{~h~} h ^G 的图网络。我们采用与目标网络结构完全相同的 GCN 作为预测网络,记为 ∅( · , Θ):G = ( VG、EG) → RN×k,其中权重参数为Θ。然后,类似于 ∅ ^ \hat{∅} ∅^,∅( · , Θ)通过下面的公式得到节点 vi 的节点表示 hi :
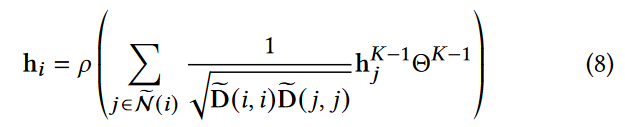
经过与 ∅ ^ \hat{∅} ∅^相同的READOUT操作后,图表示hG计算如下:
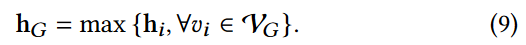
因此,随机目标网络 ∅ ^ \hat{∅} ∅^ ( · , Θ ^ \hat{Θ} Θ^) 与预测网络 ∅( · , Θ)的唯一区别在于 Θ ^ \hat{Θ} Θ^在随机初始化后是固定的,而Θ需要通过接下来的局部知识蒸馏来学习。
4.2 局部规则蒸馏
我们进一步通过最小化预测器网络和目标网络产生的(图级和节点级)表示之间的距离来进行glocal正则化蒸馏。具体来说,图级和节点级蒸馏损失定义为:
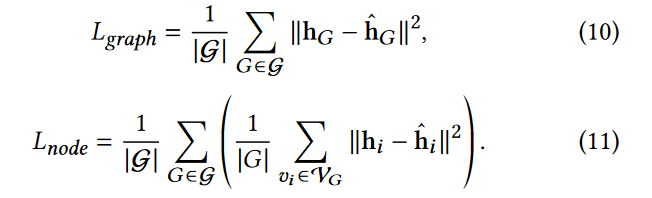
为了同时学习全局和局部的图正则性信息,我们的模型通过联合最小化上述两个损失来优化:

也就是说, λ(在公式 (1) 中以 λ ^ \hat{λ} λ^表示)。在公式12中, λ ^ \hat{λ} λ^被设置为1,因为人们认为检测局部异常图和全局异常图是同等重要的。我们将在第二节中讨论。4.4节更详细地说明了为什么我们的模型可以学习到全局和局部的图正则性。
4.3 利用Glocalkd进行异常检测
通过联合全局和局部随机蒸馏,我们的预测器网络中的学习表示在图和节点层面都捕获了规律性信息。具体来说,给定一个测试图样本G,其异常得分由图和节点级表示中的预测误差定义:
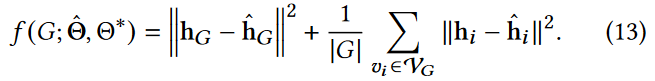
这表明,在我们的异常评分中,局部和全局异常的图形异常被视为同等重要,与方程12中的总体目标具有相同的初衷。
4.4 Glocalkd的理论分析
下面我们证明了GLocalKD对于一个异常图可以产生一个比正常图更大的异常分数。具体来说,考虑一个数据分布为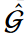 = { Gi,yi } i ( yi是回归的目标) )的回归问题,并考虑一个关于GCN ∅ ( · , Θ★)参数的先验p ( Θ★)的贝叶斯设定。目的是对数据进行迭代更新后计算后验。根据[ 5 ],我们的任务可以表述为下面的优化问题:
= { Gi,yi } i ( yi是回归的目标) )的回归问题,并考虑一个关于GCN ∅ ( · , Θ★)参数的先验p ( Θ★)的贝叶斯设定。目的是对数据进行迭代更新后计算后验。根据[ 5 ],我们的任务可以表述为下面的优化问题:
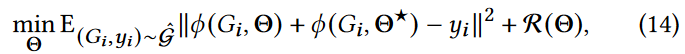
其中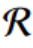 ( Θ )是来自先验[ 26 ]的正则化项.令 F 为函数f Θ = ∅ ( · , Θ) + ∅ ( · , Θ★)上的分布,其中Θ为方程14的解,并且Θ★是由p ( Θ★)画出的,则集合F可以看成是后验的近似[ 26 ]。
( Θ )是来自先验[ 26 ]的正则化项.令 F 为函数f Θ = ∅ ( · , Θ) + ∅ ( · , Θ★)上的分布,其中Θ为方程14的解,并且Θ★是由p ( Θ★)画出的,则集合F可以看成是后验的近似[ 26 ]。
当我们从相同的分布中选择图,并将标签 yi 设置为零时,优化问题
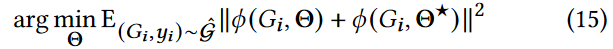
这个公式是公式 (14) 的一个特殊情况,它能够代表图 G 的结构信息,而不考虑任何特定的标签。
相当于从先验中提取一个随机抽取的函数。从这个角度来看,目标和预测网络的表示输出的每个条目都将对应一个集合的一部分,而预测误差将是在假设集合无偏的情况下对集合预测方差的估计,如文献[ 5 ]所述。如果我们把 ∅ ( · , Θ★) 作为随机初始化 Θ★ 的目标网络,把 ∅ ( · , Θ) 作为预测网络,预测网络中的节点表示和图表示的预测误差将是两个网络结果的预测方差的估计。也就是说,我们的训练过程旨在训练一个预测器网络,使得两个网络在每个训练样本上的节点表示和图表示尽可能接近。然后,对于与许多其他训练图具有相似模式的图,公式10 和11的预测误差是较小的,公式14中的预测方差小。因为有足够的这样的样本来训练预测模型;相比之下,异常图来自于训练图的不同分布,并且与大多数训练数据不相似,导致公式14的预测方差较大。因此,我们的联合随机蒸馏中的预测误差可以区分局部和全局异常图与正常图。
简而言之,公式 14 和公式 15 提供了一个理论框架,用于解释 GLocalKD 模型是如何通过学习图的表示来检测异常的。通过这种方式,模型能够捕捉到图数据中的全局和局部模式,并将这些模式用于异常检测任务。
5 实验和结果
5.1 数据集
如表1所示,我们使用了16个公开可用的真实世界数据集
除hERG来自https://tdcommons.ai/外,其余数据均通过http://graphkernels.cs.tu-dortmund.de访问
这些数据集来自不同的关键领域[ 14 ]。表1中的前6个数据集是属性图,即每个节点都有一些描述特征;其余为平面图。HSE、MMP、p53和PPAR - γ是具有真实异常的数据集。其他12个数据集取自图分类基准,并通过将少数类视为异常来转换为异常检测任务,遵循[ 6、20、29 ]。这些数据集的选择主要是因为所选择的异常类中的图样本满足异常的一些关键语义,例如,图在表示空间中分散或稀疏分布。
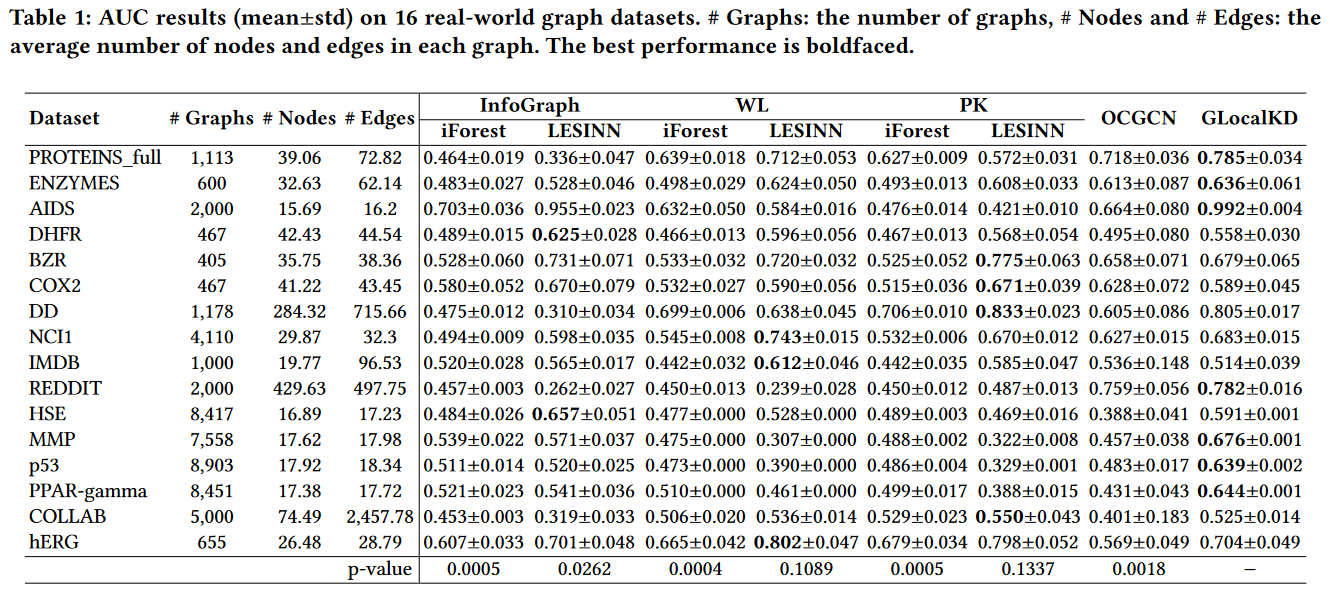
表1:在16个真实世界图数据集上的AUC结果( mean ± std )。# Graphs:图的数量,# Nodes和# Edges:每个图中节点和边的平均数量。性能最好的是黑体的。
5.2 竞争方法
使用了两种类型的七种竞争方法。
两步法
该方法首先使用最先进的基于图表示的方法来获得向量化的图表示,然后在这些表示的基础上使用先进的现成的浅层异常检测器来计算异常得分。实验中使用了InfoGraph [ 38 ],WL [ 36 ]和PK图核[ 23 ]。采用异常检测器,包括孤立森林[ 20 ]和kNN集合( LESINN ) [ 30 ]。这些嵌入方法和检测器的结合导致了六个两步法。
端到端方法
我们还与基于单类GCN的方法OCGCN [ 50 ]进行了比较,OCGCN可以像GLocalKD一样以端到端的方式进行训练。OCGCN在基于GCN的表示学习的基础上,使用SVDD目标进行优化。
5.3 实施与评价
GLocalKD中的目标网络和预测网络具有相同的网络架构- -一个具有3个GCN层的网络。隐含层的维度为512,输出层有256个神经单元。通过网格搜索选择学习率,从10-1到10-5不等。除最大的4个数据集HSE、MMP、p53和过氧化物酶增殖体激活受体 -γ 的批处理大小为2000外,其他数据集的批处理大小均为300。对于竞争方法,OCGCN的网络结构和优化方法与我们的模型相同。其他方法取自他们的作者。我们在孤立森林和LESINN中都探索了广泛的超参数设置。我们发现,孤立森林的性能随着超参数设置的改变变化不大,而LESINN可以通过使用一个子采样大小设置来获得比其他(见附录E表4)更大的改进。由于这些观察,默认使用下采样大小和树的数量分别设置为256和100的孤立森林,而使用在大多数数据集上表现最好的下采样大小设置的LESINN。更多的实现细节可以在附录B中找到。
在评估方面,我们使用了流行的异常检测评估指标- -接收者操作特征曲线下面积( Area Under Receiver Operating Characteristic Curve,AUC )。AUC越高,表明性能越好。我们报告了所有数据集基于5折交叉验证的平均AUC和标准差,除了HSE,MMP,p53和PPAR - γ具有广泛使用的训练和测试分裂。对于这4个数据集,结果是基于不同随机种子的5次试验。
5.4 与现有方法的比较
GLocalKD及其7种竞争方法的AUC结果见表1。
我们的GLocalKD模型在7个数据集上表现最好,与每个数据集的最佳竞争者相比,在其中许多数据集上实现了1 %至12 %的改进,例如,AIDS ( 3.7 % ),PROTEINS _ full ( 6.7 % ),过氧化物酶增殖体激活受体-γ ( 10.3 % ),MMP ( 10.5 % ),p53 ( 11.9 % );并且其性能在一些其他数据集上非常接近最佳竞争者,如DD和COLLAB。GLocalKD的一致性优势主要源于其同时学习全局和局部图正则性的能力。
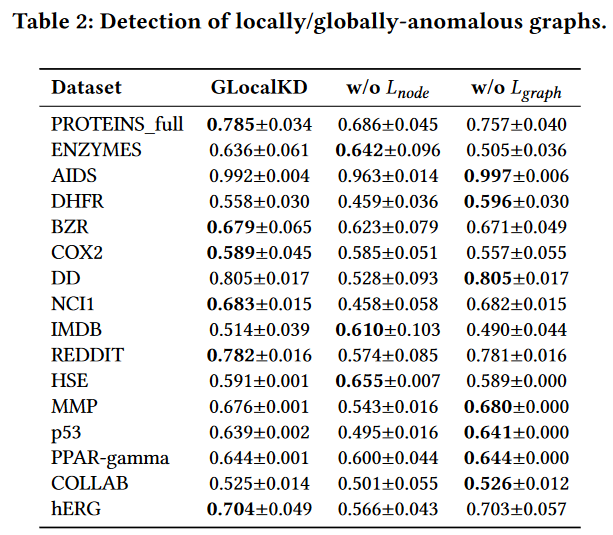
表2:局部/全局异常图的检测。
如果只有一个模式被捕获到(见表2),它的性能可能会显著下降,例如,降低到与随机检测器相当的性能。这七种相互竞争的方法在许多数据集中失效,主要是因为它们的图表示只捕获了部分局部/全局模式信息。
我们还进行了配对Wilcoxon符号秩检验[ 42 ],以检验GLocalKD在16个数据集上对每个竞争方法的显著性。如表1中的p值所示,在99 %的置信水平下,GLocalKD显著优于基于孤立森林的方法和OCGCN。GLocalKD相对于基于LESINN的方法的优越性的置信水平在85 %和95 %之间。但需要注意的是,LESINN严重依赖于其子样本量(附录E中InfoGraph - LESINN、WL - LESINN和PK - LESINN的完整结果见表4)。与一些竞争者相比,GLocalKD在COLLAB上的效果较差,这可能是由于异常图与正常图的不可分离性导致的,因为竞争者在COLLAB上的表现也不好。
在计算效率方面,如附录C中表3的结果所示
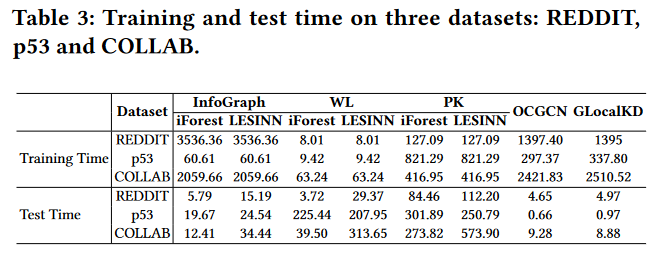
表3:在REDDIT、p53和COLLAB三个数据集上的训练和测试时间。
GLocalKD和OCGCN具有相似的时间复杂度,并且在在线检测中的运行速度远远快于其他方法,因为孤立森林/ LESINN方法需要在图表示的顶部增加额外的步骤来计算异常分数。另一方面,GLocalKD和OCGCN的计算成本通常比基于WL和PK的方法高,因为GLocalKD和OCGCN通常需要多次迭代才能表现出良好的性能。
5.5 样本效率
5.5.1 实验设置
该部分使用深度竞争方法OCGCN作为基准,通过训练数据量,即样本效率来检验我们模型的性能。分别使用原始训练样本的5 %、25 %、50 %、75 %和100 %对模型进行训练,并在相同的测试数据集上进行性能评估。我们只报告了在属性图数据集上的结果。在其他数据集上也可以找到类似的结果。
5.5.2 调查结果
AUC结果如图4所示。
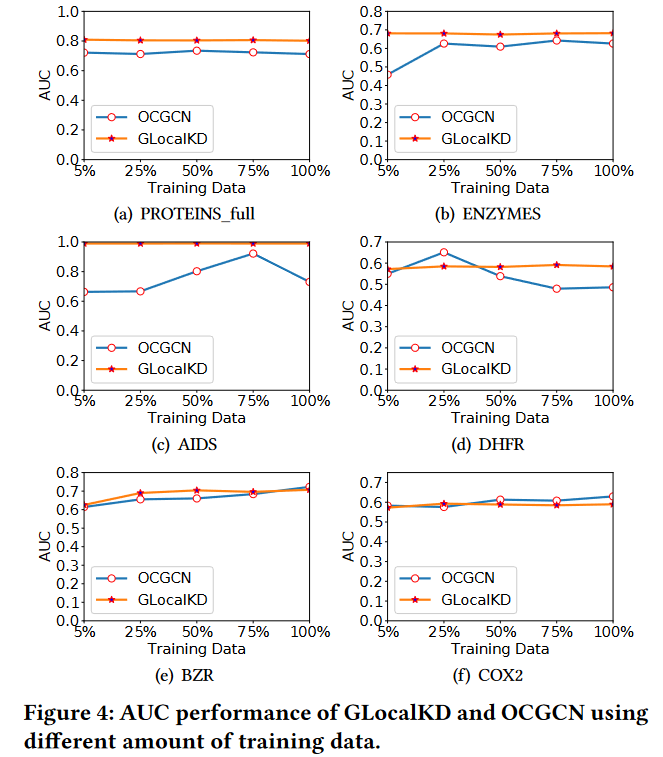
图4:不同训练数据量下GLocalKD和OCGCN的AUC性能。
令人印象深刻的是,即使在使用较少的95 %的训练数据的情况下,GLocalKD在几乎所有的6个数据集上都能保持同样好的性能。相比之下,如果减少相同数量的训练数据,OCGCN在一些数据集上的性能会显著下降,如ENZYMES和AIDS。因此,即使在这样的数据集上,GLocalKD使用的训练数据比OCGCN少95 %,GLocalKD也能比OCGCN有更大的性能提升。
5.6 稳健性W . R . T .异常污染
5.6.1 实验设置
回想起来,我们解决了只有正常训练样本的半监督异常检测设置。然而,在实际应用中收集到的数据可能会被一些异常或数据噪声所污染。本节考察GLocalKD对训练数据中不同异常污染程度的鲁棒性。我们将污染率从0 %变化到16 %。再次,仅限于篇幅,我们报告了6个属性图数据集上的结果;OCGCN作为基线。
5.6.2 调查结果
不同异常污染率的GLocalKD和OCGCN的AUC结果如图5所示。
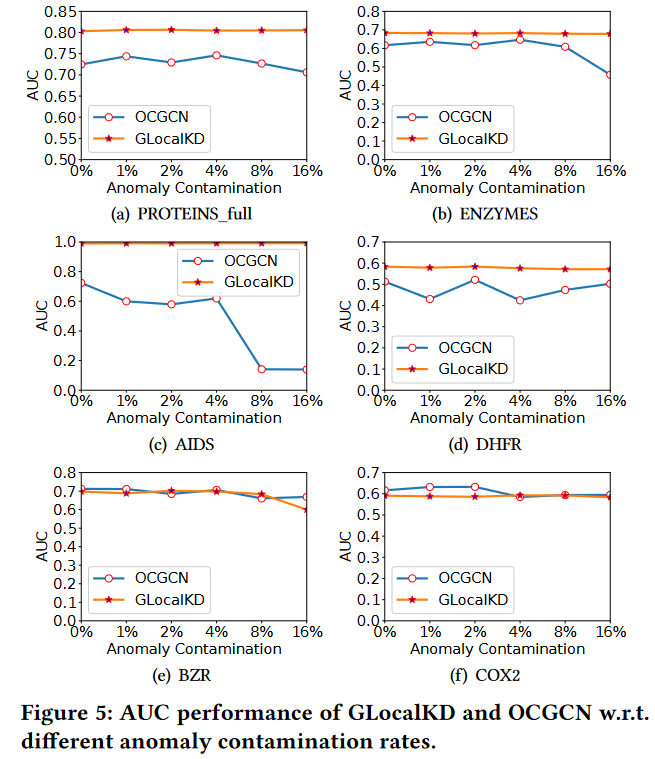
图5:GLocalKD和OCGCN在不同异常污染率下的AUC性能。
GLocalKD几乎不受污染的影响,在所有数据集上表现非常稳定,而OCGCN在ENZYMES和AIDS数据集上的性能随着污染率的增加而大幅下降。这主要是因为GLocalKD本质上是通过随机蒸馏学习训练数据中的所有类型的模式,只要这些异常模式不像训练数据中的正常模式那样频繁,GLocalKD就能够检测出异常;而OCGCN是敏感的,因为它的异常测度SVDD对异常污染很敏感。
5.7 敏感性试验
5.7.1 实验设置
本节测试GLocalKD对表征维度和GCN深度的敏感性。对于第一个测试,我们将GCN的输出维度调整为{ 32,64,128,256,512 };对于GCN深度,我们使用k个GCN层来评估GLocalKD的性能,其中k∈{ 1,2,3,5 }。结果见附录D中的图6和图7。
5.7.2 敏感性
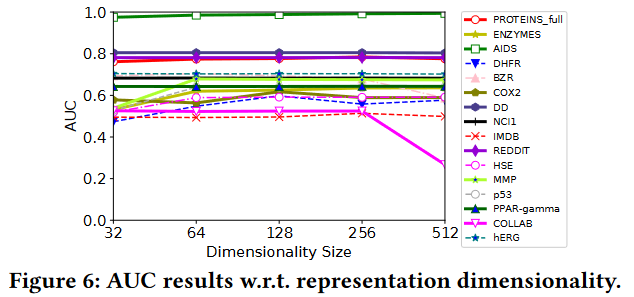
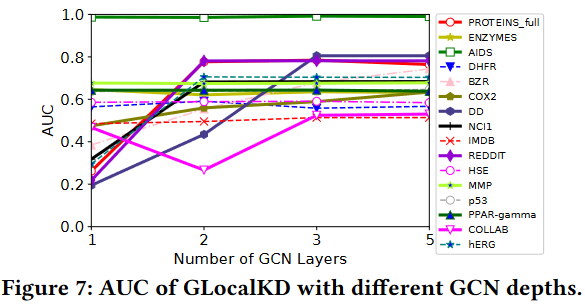
图6:AUC结果w . r . t表示维度。
图7:不同GCN深度的GLocalKD的AUC。
从结果可以看出,GLocalKD在大多数数据集上使用不同的表示维度大小表现稳定。通常推荐维度大小为256,因为这样的设置使得GLocalKD在不同的数据集上表现良好。
5.8 消融实验
5.8.1 实验设置
在这一部分,我们考察了Lgraph和Lnode这两个组件在我们的模型中的重要性。为此,我们推导了GLocalKD的两个变体,包括GLocalKD w/o Lnode表示仅在图表示上使用随机蒸馏,GLocalKD w/o Lgraph表示仅在节点表示上使用随机蒸馏。
5.8.2 调查结果
GLocalKD及其两个变体的结果见表2。
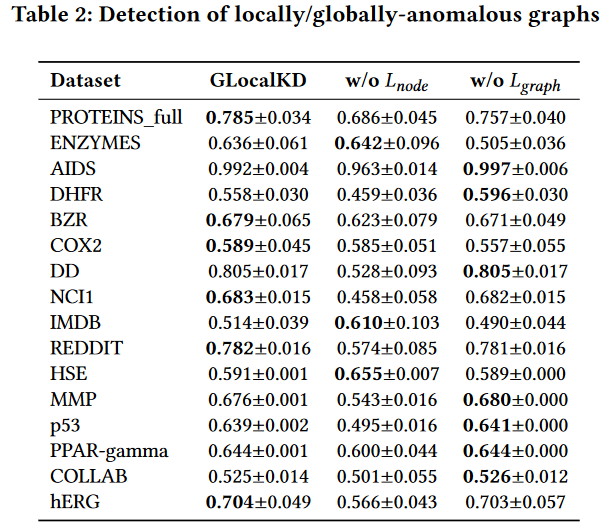
表2:局部/全局异常图的检测。
显然,与GLocalKD相比,使用Lgraph (或Lnode )仅在某些数据集上可以获得更好的性能,而在其他数据集上则可能表现较差。同时使用Lgraph和Lnode的联合随机蒸馏可以实现很好的折衷,并且在所有数据集上的表现一般都很好。
有趣的是,GLocalKD w/o Lgraph在AIDS,DHFR,DD,MMP,p53,过氧化物酶增殖体激活受体-γ和hERG等数据集上的表现明显优于GLocalKD w/o Lnode,表明这些数据中局部反常图的存在;另一方面,逆例出现在ENZYMES,IMDB和HSE上,表明全局反常图在这三个数据集中占主导地位。这些结果表明,在GAD任务中,建模细粒度的图正则性与整体图正则性同等重要,甚至更为重要,因为这两种类型的图异常都可以出现在图数据集中。
6、结论
本文提出了一个新颖的框架及其实例化GLocalKD来检测一组图中的异常图。如我们的实验结果所示,图数据集可以包含不同类型的异常- -局部异常图和全局异常图。据我们所知,GLocalKD是第一个被设计用于检测这两种类型的图异常的模型。大量实验表明,与先进的GLocalKD相比,GLocalKD的AUC性能显著提高,并且可以更有效地训练样本。我们还表明,即使在训练数据中存在较大的异常污染时,GLocalKD也能获得较好的AUC性能,这表明GLocalKD不仅可以应用于半监督环境(专属于正常训练数据),也可以应用于无监督环境。


















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











