







MustaD:采用多阶段知识蒸馏压缩深度图卷积网络
《Compressing deep graph convolution network with multi-staged knowledge distillation 》 2021
作者是 Junghun Kim、Jinhong Jung和U. KangID
论文地址和代码在文末
摘要
给定一个训练好的深度图卷积网络( GCN ),我们如何能够有效地将其压缩为一个紧凑的网络而不会显著地损失精度? 将训练好的深度GCN压缩成一个紧凑的GCN,对于在移动或嵌入式系统等计算资源有限的环境中实现该模型具有重要意义。然而,以往压缩深层GCN的工作并没有考虑深层GCN的多跳聚合,尽管这是其多个GCN层的主要目的。在这项工作中,我们提出了MUSTAD(多阶段知识蒸馏),一种通过多级知识蒸馏( KD )将深层GCN压缩为单层GCN的新方法。
MUSTAD提取了:
1 )来自多个GCN层的聚合以及
2 )保存时的任务预测的知识。
在4个真实数据集上的大量实验表明,与其他基于KD的方法相比,MUSTAD提供了最先进的性能。具体来说,MUSTAD的准确率比第二个最好的KD模型提高了4.21 %。
1、引言
给定一个训练好的深度图卷积网络,如何将其压缩为一个紧凑的网络,而不会出现明显的精度下降? 图卷积网络( Graph Convolution Network,GCN ) 学习图数据中的潜在节点表示,在联合训练模型学习节点特征和执行特定任务时,作为特征提取器发挥着至关重要的作用。由于GCN能够使研究人员轻松有效地分析图,因此受到了研究界的广泛关注。各种GCN模型已经被提出来以提高在真实世界图上的任务的性能,如节点和图分类,链接预测,关系推理等。
最近,关于深层GCNs的研究正在迅速发展,以提取大型复杂图中复杂的节点特征。这些深度GCN模型有许多层来更好地理解大图的模式并提高它们的性能。然而,随着层数的增加,需要训练的参数数量也随之增加,这导致模型规模的增加是不可忽略的。因此,在移动或嵌入式系统等计算资源有限的环境中很难使用这些大型模型。
模型压缩的目的是在不显著损失预测精度的情况下,为低能耗和资源受限的设备学习压缩的轻量级深度网络。为此,许多研究者提出了参数剪枝、低秩分解、权重量化、知识蒸馏等多种策略。其中,知识蒸馏( Knowledge Distillation,KD )由于其基于学生-教师模式的简单性而备受欢迎;KD将知识从一个大的教师模型提炼成一个小的学生模型,使学生表现得和教师一样好。在此背景下,Yang等人最近提出了一种称为LSP (局部结构保持)的压缩GCN模型的KD方法。然而,LSP处理的是较浅的模型,并且只提取了有限的关于教师特征聚合的知识,而忽略了当网络变深时需要考虑的各个方面。具体来说,LSP并没有考虑教师关于多跳特征聚合的知识,尽管这个过程本质上涉及到一个深层的GCN;因此,它在保持精度方面的性能是有限的,特别是在压缩深度GCN时。
在本文中,我们提出了MUSTAD (多阶段知识蒸馏),一种通过多阶段知识蒸馏( KD )将深层GCN压缩为单层GCN的新方法,同时保留了深层GCN的多跳特征聚合。基于知识蒸馏的理念,MUSTAD旨在训练一个特征维度与受训教师GCN相同甚至更低的单层学生GCN。MUSTAD框架如图1所示。
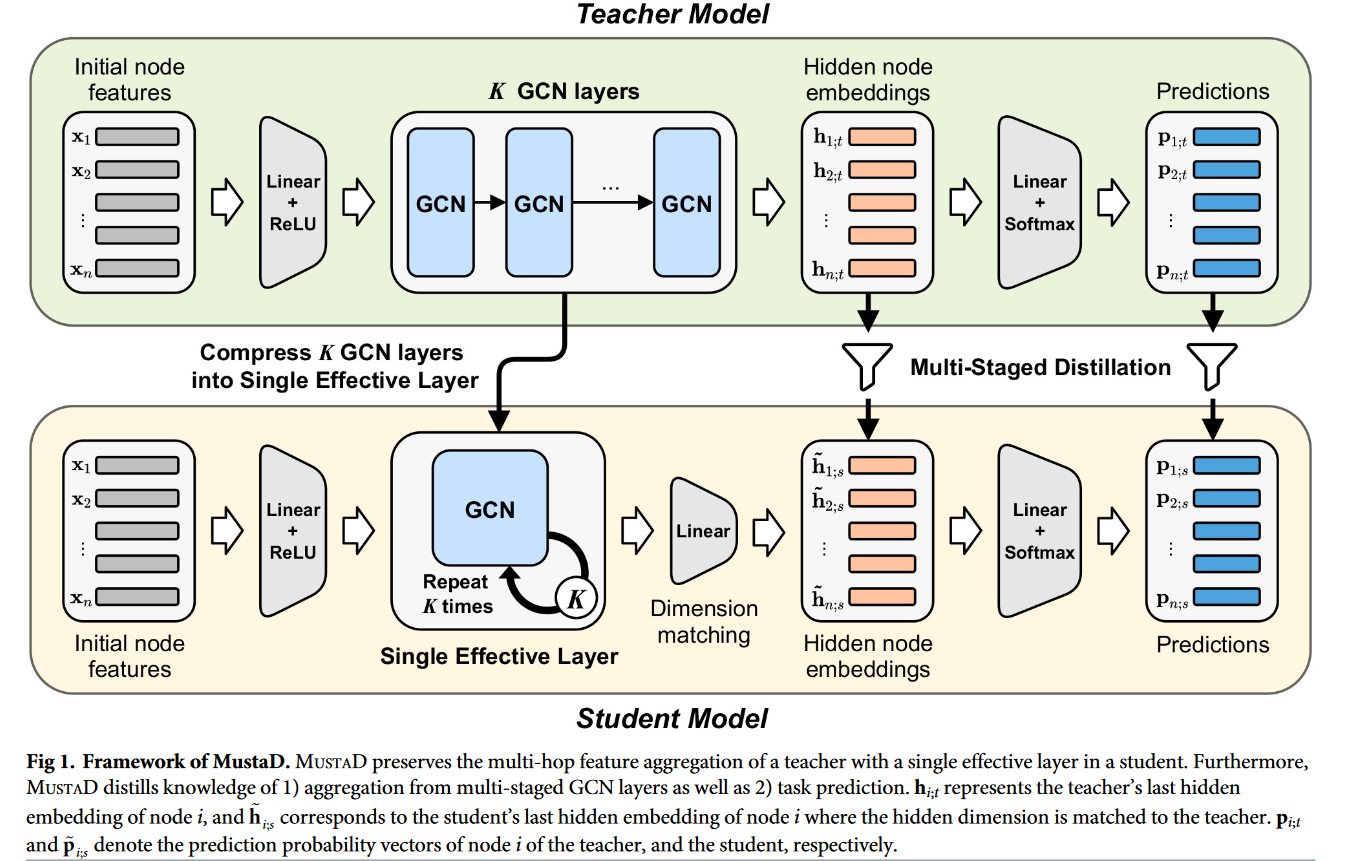
图1 . Musta D框架。MUSTAD保留了学生中单个有效层的教师的多跳特征聚合。此外,MUSTAD还提取了
1 )多阶段GCN层的聚合以及
2 )任务预测
hi;T表示教师对节点i的最后一次隐藏嵌入,
hi;S对应于节点i的学生的最后一个隐藏嵌入,其中隐藏维度与教师匹配
;T和~ Pi;S分别表示教师和学生节点i的预测概率向量。
我们的主要思想是从多个GCN层中提取多跳特征聚合的知识,以及任务预测的知识。具体来说,单层学生通过
1 )匹配来自教师的隐藏特征嵌入
2 )以单个有效层模仿教师的多个GCN层来学习教师的多跳特征聚合知识。
通过传递教师的概率预测向量,将任务预测的知识灌输给学生。这些多阶段的知识蒸馏引导学生以显著更少的参数获得与深层教师相似的聚合特征和预测。
我们的贡献总结如下:
方法
我们提出了MUSTAD,一种通过提取特征聚合和特征表示两方面的知识来压缩深层GCN的新方法。我们提出了一种简单但强大的方法,以显著较少的参数来保持教师的多跳特征聚合。
理论
我们对所提出的MUSTAD进行了理论分析,并证明了MUSTAD的学生模型在谱域上的表达能力与深层GCN的表达能力相似。
实验
与其他基于蒸馏的GCN压缩方法相比,我们在四个数据集中的两个训练好的深度GCN模型上验证了MUSTAD。特别地,我们在Cora、Citeseer和Pubmed上分别比次优KD模型提高了3.95 % p、3.77 % p、4.21 % p。在ogbn -蛋白质中,MUSTAD在AUC - ROC方面比次优KD模型提高了1.55 %。
2、相关工作
许多复杂的深度网络被提出来解决现实世界的任务,例如文本分类,恶意软件检测,车载入侵攻击检测和网页文档分类。特别地,提出了几种深度图卷积网络( GCNs )来处理真实世界的图。然而,这些模型很难在计算资源有限的环境中使用。因此,许多知识蒸馏( Knowledge Distillation,KD )方法被研究,通过提取紧凑且有用的信息,将一个大的教师模型压缩为一个小的学生模型。这些方法虽然提高了压缩效率,但都是针对网格域的数据设计的;它们很难直接应用于图等非网格领域的数据。
在这一部分,我们讨论了深度GCN和KD方法的相关工作。表1总结了本文所用到的符号。
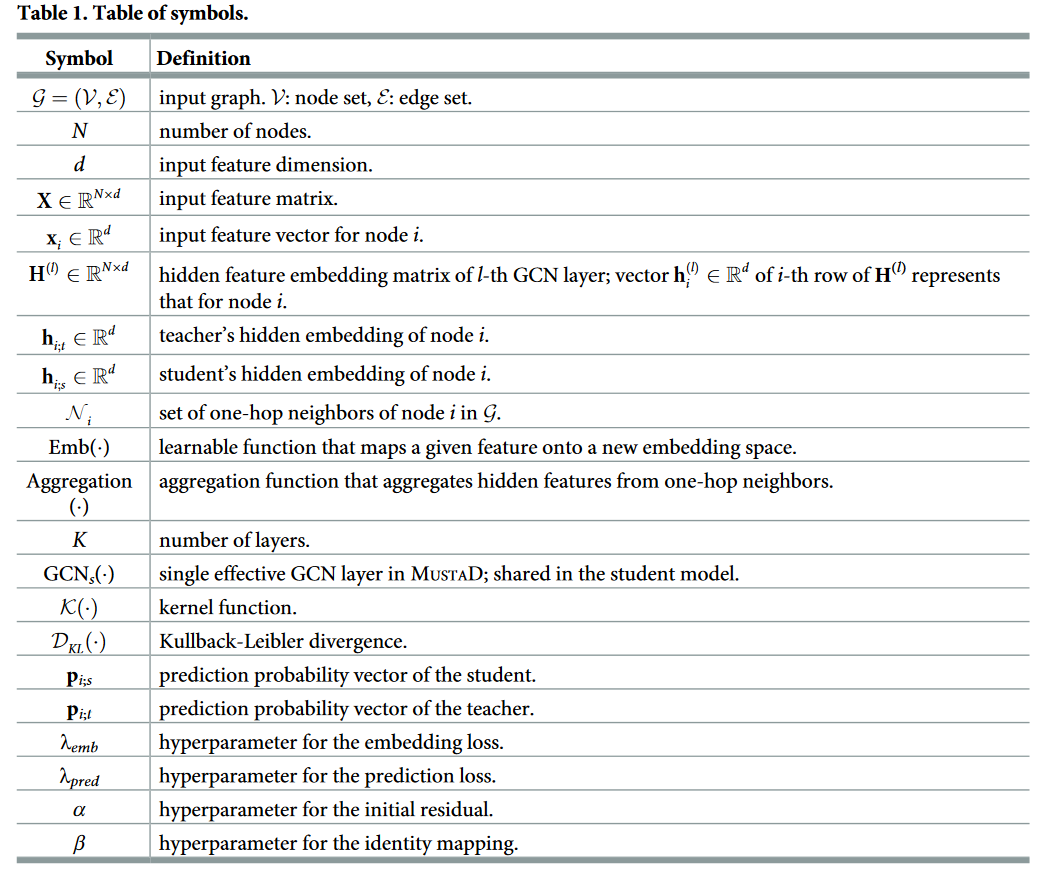
表1:符号表。
深度图卷积网络
自从第一个 GCN 在中被提出以来,许多基于卷积的图神经网络被提出。在 GCNs 中,一个卷积层聚合来自一跳邻居的特征信息,多个卷积层聚合来自多跳邻居的特征信息。最近,许多深度GCN被研究来考虑多跳特征信息。
ResGCN 从卷积神经网络中借用残差/密集连接和空洞卷积,并将其适应于 GCN 架构。GEN 是的补充版本。该模型使用了一种改进的图跳跃连接,它是 ResGCN 中残差连接的预激活版本。
GCNII 扩展了 vanilla GCN 模型,以克服中提出的过度平滑问题;文献观察到给定归一化图卷积矩阵 P ~ \widetilde{P} P 和一个输入特征矩阵 X,一个 K 层 vanilla GCN 模拟一个固定的 K 阶多项式滤波器 P ~ \widetilde{P} P KX ,当 P ~ \widetilde{P} P KX 收敛到一个不携带 X 信息的分布时,会引起过平滑问题。为了克服过平滑问题,GCNII 在 vanilla GCN 的基础上引入了初始残差和恒等映射技术。初始残差从输入层开始构建索普连接,从而保证每个节点的最终表示至少保留 X 的一部分。身份映射只是将聚合后的特征传递到下一个 GCN 层,不需要任何参数化的嵌入过程。每个 GCNII 层的特征为:
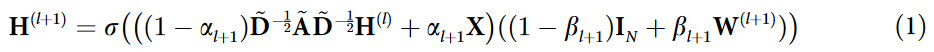
其中 H ( l ) 对应第 l 个隐特征表示, A ~ \widetilde{A} A 表示归一化邻接矩阵, D ~ \widetilde{D} D 表示 A ~ \widetilde{A} A 的度矩阵,IN 表示单位矩阵,σ 表示激活函数。αl+1 和 βl+1 是两个超参数,其中 αl+1 控制初始特征 X 到第 ( l + 1 ) 个 GCN 层的连接强度,βl+1 控制仅将聚合特征转移到下一个 GCN 层的程度,而不进行任何参数化嵌入。
虽然许多深度GCN模型通过考虑图中的多跳特征来加速其性能,但由于其模型规模较大,很难在移动或嵌入式系统等计算资源有限的环境中使用。在本文中,我们致力于将深层GCN压缩为浅层GCN,同时保留深层GCN的多跳特征聚合特性。
知识蒸馏
知识蒸馏( Knowledge Distillation,KD ) 将知识从一个大的教师模型转移到一个较小的学生模型,使学生表现得和教师一样好。在该方法中,教师的任务预测通过 softmax 函数进行平滑。知识的提炼是通过让学生的任务预测与教师的任务预测相似来完成的。几种 KD 方法不仅提取了教师的输出,还提取了中间隐含层的信息。从教师的隐藏层引入中间层暗示,引导学生学习教师的中间层表征。然而,这些方法旨在将一个宽而浅的教师模型压缩为一个细而浅的学生模型;也就是说,他们并不专注于将深层的教师 GCN 模型压缩为浅层的 GCN 模型。因此,它们在将多个 GCN 层压缩为少数几个 GCN 层时存在局限性。
最近,据我们所知,文献[ 21 ]提出了第一个基于局部结构保持( Local Structure Preserving,LSP )模块的 GCNs 上的 KD 方法。在该模块中,教师和学生的拓扑语义都被提取为分布,并通过最小化这些分布之间的距离来实现拓扑感知的知识迁移。然而,LSP只传递中间知识,没有考虑任务预测,而任务预测是专门为目标任务设计的。此外,LSP 并没有考虑教师关于学生多跳特征聚合的知识,尽管这个过程本质上涉及到一个深层的 GCN。因此,其在保持精度方面的性能有限,尤其是对深层 GCN 的压缩。
3、提出的试验方法
在这一部分中,我们提出了MUSTAD (多阶段知识蒸馏),一种通过提取教师的多阶段知识来有效压缩深层GCN的新方法。
我们总结了在保留深层教师多跳特征聚合的同时开发蒸馏方法所面临的挑战和我们的想法。
1、通过从教师模型中提取知识,将深度教师 GCN 模型压缩为小规模学生 GCN 模型时,需要保留深度模型的多跳特征聚合,因为聚合是堆叠多个 GCN 层的关键目的。我们提出使用单个有效层,在保留多跳特征聚合过程的同时,将教师模型中的 K 个 GCN 层模仿为学生中的单个 GCN 层,显著降低模型规模。
2、同样重要的是,决定要提取哪些知识来保持教师模型在学生模型中的表现。我们提出了多阶段的知识蒸馏,不仅提取了教师模型的任务预测的知识,而且还提取了其对学生模型的最终隐藏嵌入。通过提取最终隐藏嵌入的知识,学生模型生成与教师模型类似的最终表示;因此,多阶段知识蒸馏有助于单个有效层模仿多个 GCN 层。
首先,基于对深层 GCNs 基本机制的观察,我们描述了如何在单个有效的学生网络中保留教师模型的多跳特征聚合。然后,我们描述了嵌入的知识蒸馏以及任务预测,接着解释了最终的损失函数,用于联合训练所有的嵌入用于节点分类任务。最后,在提取 GCNII 教师模型的知识时,我们给出了 MUSTAD 的谱分析,以加强我们方法的理论背景。
保留多跳特征聚合
我们描述了 MUSTAD 如何在学生的单个 GCN 层中保留教师深层 GCN 层的特征聚合过程。深度 GCN 的主要目的是使用多个 GCN 层来考虑多跳邻居。令 G = (V , E) 表示一个输入图,其中 V 和 E 分别表示节点和边的集合。给定图 G,一个 GCN 层表示为

其中 hi(k) 表示第 k 层 GCN 中节点 i 的隐特征嵌入,Ni 表示节点 i 在 G 中的一跳邻居集合,Embk ( · ) 是一个可学习的函数,它将给定的特征映射到一个新的嵌入空间,并在第 k 层 GCN 中使用。根据Eq ( 2 ),一个 GCN 层通过聚合 Aggregation( · ) 从一跳邻居中聚合隐藏特征以获得新的隐藏特征。因此,当一个模型使用 K 个 GCN 层时,它将隐藏的特征从最多到 K 跳邻居聚集。
其中 GCNs ( · ) 表示学生模型中的一个共享 GCN 层,而 hi(k) 表示学生模型中第 k 次迭代时节点 i 的隐嵌入。换句话说,MUSTAD 在学生模型中重复 GCNs ( · ) K次,以模拟教师的多跳聚集,如图1所示。因此,我们的模型通过将多个 GCN 层压缩为单层来减少模型参数的数量,同时有效地考虑了多跳特征聚合。
从训练好的深层GCN中提取知识
如图1所示,MUSTAD提取了教师对学生的嵌入和任务预测的多阶段知识。
嵌入知识的提取
MUSTAD提取教师对学生进行 K 跳聚合后的最后一个隐藏嵌入。这种升华引导学生更加谨慎地遵从教师的行为。蒸馏的主要思想是通过最小化下面的损失函数使得教师和学生的嵌入相似:

式中 hi;t 为教师对节点 i 的最后一次隐藏嵌入, h ~ \widetilde{h} h i;s = Wshi;s ,其中 hi;s 是学生对节点 i 的最后一次嵌入,Ws 是一个可学习的权重矩阵,用于匹配教师和学生之间的维度。如果它们具有相同的隐藏维数,则隔离匹配层。K(·) 是度量两个给定嵌入向量之间距离的核函数,可以使用任意的距离度量。在这项工作中,我们研究了核函数在以下指标中的作用:

式中:h’i,j;t 和 h’i,j;s 分别表示 h’i;t = Softmax( hi;t ) 和 h’i;s = Softmax( hi;s ) 的第 j 个元素。
预测知识的提取
任务预测知识的提取遵循文献[ 17 ]中提出的最小化如下损失函数的过程:

其中 DKL = (·) 为库尔贝克-莱布勒的散度,Pi;S 表示学生通过一个 softmax 函数后的预测概率向量,Pi;T 表示教师经过一个以温度 T 为条件的 softmax 函数后的温度。任务预测的升华引导学生获得与教师相似的预测输出。
节点分类的最终损失函数
学生模型旨在解决像教师模型那样的节点分类任务。
因此,学生模型通过最小化以下交叉熵损失直接学习任务和上述蒸馏:

式中 V* 为带标签的节点集合,C 为标签集合,yij 为指标,若节点 i 属于标签 j ,则为 1,否则为0 ;S 为节点 i 属于某个标签 j 的概率,由学生预测。注意,式( 7 ) 假设每个节点只属于一类。如果一个节点有多个标签(即,多标记节点分类),我们使用二进制交叉熵损失来代替。
为了对上述所有方面进行联合训练,MUSTAD最小化以下最终损失:

其中 λ pred 和 λ emb 是平衡所提出的损失项的超参数。
MustaD的谱分析
谱图方法已经成为分析大型网络的基本工具。GCN 由于其成功地将定义在谱域上的图卷积实现为简单的矩阵乘法,从而获得了比其他模型更优越的性能,因此吸引了大量的关注。在这一部分中,我们首先给出了 K 层 GCN 在谱域上的简要解释。在提取 GCNII 教师模型的知识时,我们给出了 MUSTAD 的谱分析,比较了我们的 MUSTAD 与 K 层 GCN 在谱域上的表达能力。
思考为自环图的邻接矩阵 A ~ \widetilde{A} A ∈ RN*N,图信号 x ∈ RN 为节点集合上的值,其中 N 为节点数。图信号 x 上的一个 K 阶多项式滤波器定义为:
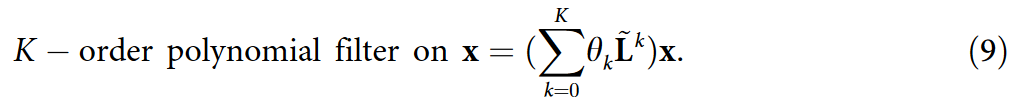
其中 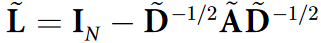 是
A
~
\widetilde{A}
A
的标准化拉普拉斯矩阵,θl ∈ R是多项式系数.
D
~
\widetilde{D}
D
和 IN ∈ RN*N 分别表示
A
~
\widetilde{A}
A
的度矩阵和单位矩阵.文献[ 31 ]证明了一个 K 层 GCN 模拟了一个依赖系数为 θl 的 K 阶多项式滤波器,这是对 K 层 GCN 在谱域上的解释。我们证明了由我们提出的 MUSTAD 蒸馏出来的学生也只用一个线性变换层和一个有效层来模拟具有相互依赖系数的 K 阶多项式滤波器,因此具有与 K 层 GCN 相似的表达能力。
是
A
~
\widetilde{A}
A
的标准化拉普拉斯矩阵,θl ∈ R是多项式系数.
D
~
\widetilde{D}
D
和 IN ∈ RN*N 分别表示
A
~
\widetilde{A}
A
的度矩阵和单位矩阵.文献[ 31 ]证明了一个 K 层 GCN 模拟了一个依赖系数为 θl 的 K 阶多项式滤波器,这是对 K 层 GCN 在谱域上的解释。我们证明了由我们提出的 MUSTAD 蒸馏出来的学生也只用一个线性变换层和一个有效层来模拟具有相互依赖系数的 K 阶多项式滤波器,因此具有与 K 层 GCN 相似的表达能力。
使用 GCNII 架构的每一层教师表示如下:
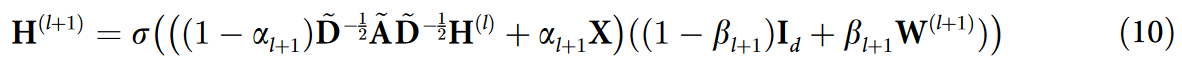
其中 X ∈ RN*d 和 σ 分别表示输入特征矩阵和激活函数( ReLU )。αl+1 ∈ R 和 βl+1 ∈ R 是两个超参数。在第 ( l + 1 ) 个 GCN 层中,W(l+1) ∈ Rd*d 表示一个可学习的权重矩阵。H(l) ∈ RN*d 对应第 l 个隐藏特征表示;也就是说,每个节点都有一个长度为 d 的隐藏特征向量。通过对 X 进行线性变换得到初始隐藏表示 H(0) ,表示为 H(0) = XW(0)。值得注意的是,由于与输入特征矩阵 X 存在残差连接,每个 GCN 层的隐藏表示的维度与初始特征向量的维度相同。
当我们处理图信号 x ∈ RN 而不是输入特征矩阵X时,式( 10 )变为
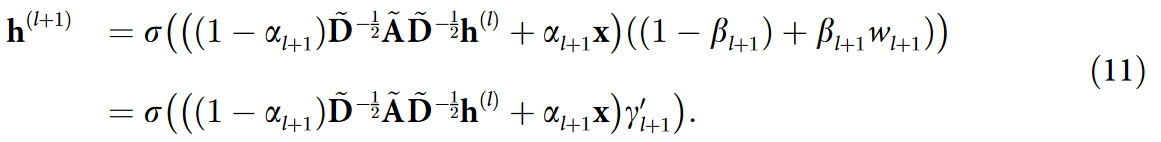
其中 wl+1 ∈ R 为可学习参数,γ‘l+1 = (1 - βl+1) + βl+1wl+1 , 并且 h(l) ∈ RN 表示第 l 个隐藏特征表示;也就是说,每个节点都有一个长度为 1 的隐表示。初始隐式表示 h(0) 是通过对 x 进行线性变换得到的,其表达式为 h(0) = x w0 。
定理1
考虑一个 K 层的 GCNII 教师模型。由 MUSTAD 提取的教师的学生用下面的简单形式表示一个 K 阶多项式滤波器 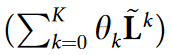 ,其相互依赖的系数 θk 的 k ∈ {0,…,K} 有如下简单形式:
,其相互依赖的系数 θk 的 k ∈ {0,…,K} 有如下简单形式:
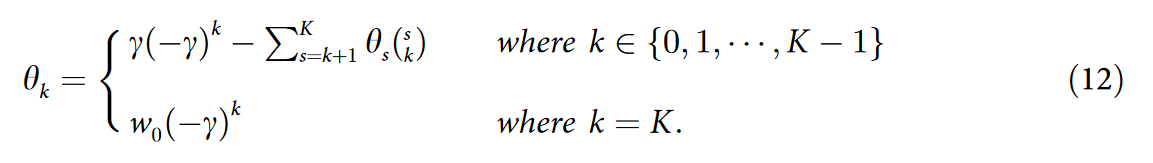
证明
我们考虑文献[ 13 ]中使用的教师模型的一个弱形式,假设信号向量 x 非负且 αl+1 = 1 / 2 .进一步,由于输入特征 x 是非负的,因此去掉 ReLU 操作,如文献[ 13 ]所示。因此,方程( 11 )简化为下面的形式:
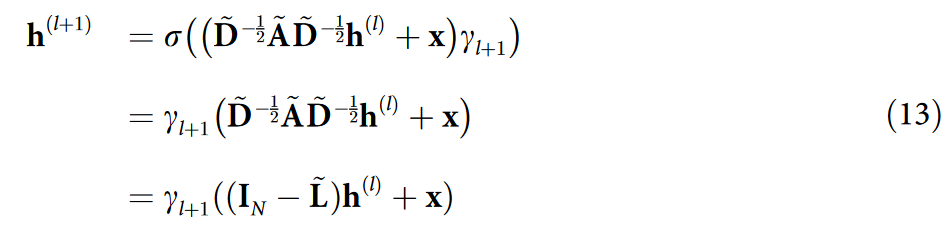
其中 γl+1 = γ‘l+1 / 2 ,并且 L ~ \widetilde{L} L 是邻接矩阵 A ~ \widetilde{A} A 的正规化拉普拉斯矩阵。由于 MUSTAD 使用了重复的单个有效层而不是 K 个离散的 GCN 层,我们将 γl+1 设置为 l ∈ {0,…,K-1} 的单个参数 γ。因此,对方程( 13 )的递归计算可以得到单有效层的最终表示 h(K):
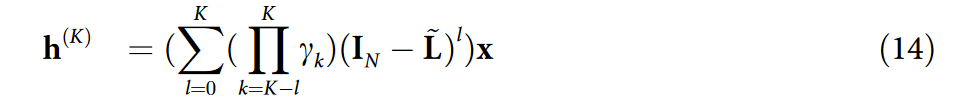
其中 γk = γ, k ∈ {0,…,K} ,并且 γ0 = w0 。
另一方面,图信号 x 上邻接矩阵 A ~ \widetilde{A} A 的 K 阶多项式滤波器由下式表示:
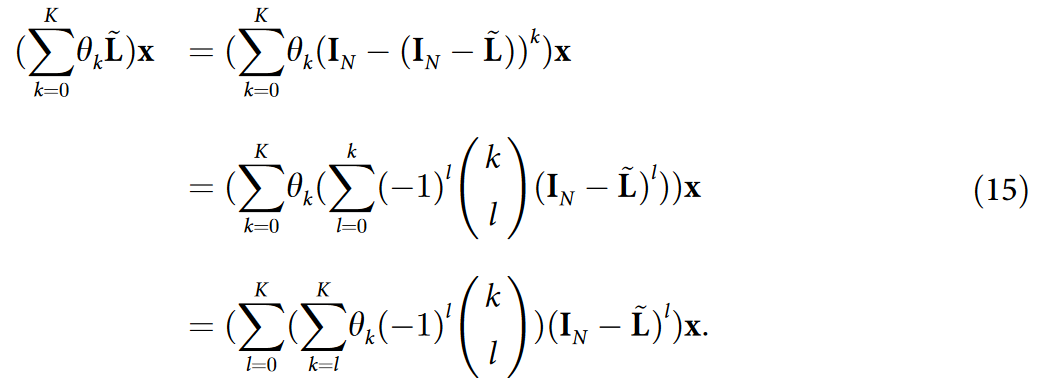
为了证明 MUSTAD 提取的 K 层 GCNII 教师的学生表达了一个具有相互依赖系数的 K 阶多项式滤波器,我们证明了方程中 k ∈ {0,…,K} 的所有 θk 如下式:
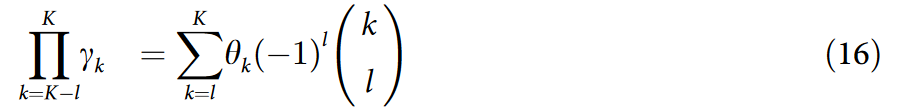
对于所有的 k ∈ {0,…,K} ,用 w0 和 γ 表示,其中 γk = γ 对于 k ∈ {0,…,K} ,γ0 = w0,和 l ∈ {0,…,K} .当 l = K 时,θK 由 w0 和 γ 表示如下:

递推计算表示所有 θk 的 w0 和 γ 如下:
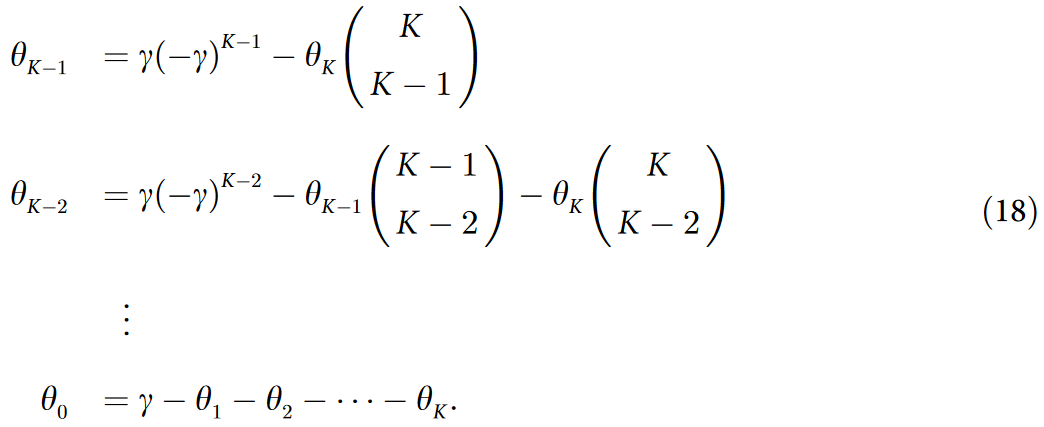
最后,得到了方程( 16 )中 θk 的一般表达式为
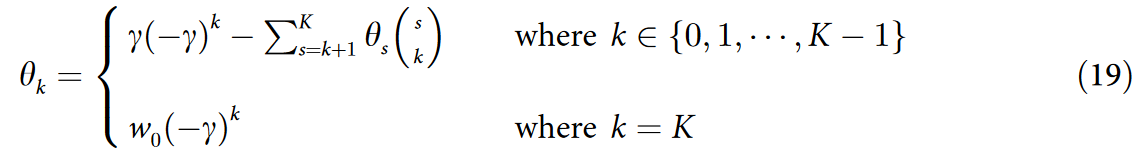
这是我们所期望的目标。
4、实验
我们进行实验来回答以下问题。
Q1 : 预测准确性。与其他KD方法相比,我们的MUSTAD很好地保留了深度教师模型的多跳特征聚合?
Q2 : 参数 vs 性能。在学生模型中,参数的数量和准确性之间的权衡是什么?
Q3 : 消融研究。如何有效地进行多级蒸馏和单一有效层,帮助学生保存教师的表现?
实验设置
数据集
我们使用了4个图数据集,如表2所示。

表2:数据集统计
Cora、Citeseer 和 Pubmed 是引文数据集,其中节点和边分别代表文献和引文。每个节点特征表示一个单词是否包含在每个文档中。ogbn - proteins 数据集是一个无向加权图,其中节点表示蛋白质,边表示蛋白质之间不同类型的生物学关联。图中的一条边具有 8 维特征,一个节点具有8 维独热特征,表示对应的蛋白质来自哪个物种。
教师模型
我们从两个不同的教师模型中进行蒸馏。第一个教师模型,GCNII 使用了初始残差和恒等映射技术,并在 Cora,Citeseer 和 Pubmed 中取得了最先进的性能。我们对训练好的 GCNII 教师在这 3个数据集中进行了压缩。第二个教师模型,GEN 提出了广义消息聚合器和预激活残差连接;GEN在 ogbn - proteins 数据集上取得了较好的性能。我们从 ogbnproteins 数据集中的训练有素的 GEN教师进行蒸馏。在重现教师模型时,数据分割、优化器、正则化、激活函数和超参数等实验设置遵循[ 8,13 ]的设置,除非明确说明。
竞争者 我们将MUSTAD与以下竞争者进行了比较:
KD [ 17 ]是知识蒸馏的模型。它对教师的任务进行密集的预测,并将课堂知识提炼给学生。我们将这种方法蒸馏出来的学生记为 Student _ KD,最终损失为:

LSP方法[ 21 ]提取了教师的嵌入拓扑结构,并在图结构数据集上取得了最好的性能。我们将用这种方法训练的学生记为 Student _ LSP,最终的损失函数为:

所有方法均由 PyTorch和 PyTorch Geometric [ 38 ] 实现。我们使用 Intel E5-2630 v4 2.2GHz CPU 和精视 2080 Ti 的单片机进行实验。
半监督节点分类
Cora、Citeseer和Pubmed
我们在 Cora、Citeseer 和 Pubmed 上对训练好的 GCNII 模型进行蒸馏。特别地,我们从不同层数的教师中执行 KD,以显示 MUSTAD 如何很好地保留教师的多跳特征聚合。在重现教师模型时,我们使用与[ 13 ]相同的设置。在训练学生时,将早期停止耐心从 100 个历元增加到 200 个历元,以获得更稳定的结果。Student _ Base 是在没有教师的情况下,用真实标签训练出来的模型。 Student _ MUSTAD 是我们蒸馏出来的与教师具有相同隐藏特征维度的学生。我们在 Cora、Citeseer 和 Pubmed 上分别训练了 λ pred 为 0.1、0.1 和 100 的 Student _ KD。对于 Student _ LSP,我们在 Cora 和 Citeseer 上都将 λ LSP 设置为 10。Student _ LSP不能在Pubmed中训练,因为每个训练节点只有一个邻居,这意味着没有局部结构可以提取[ 13 ]。对每个竞争者的其他超参数进行调整,以在验证集上获得最佳结果。对于 Student _ MUSTAD,我们在 Cora,Citeseer 和 Pubmed 中分别设置 λ pred 为 1,0.1 和 100,λ emb为 0.01,0.01 和 10,核函数为 KL 散度。
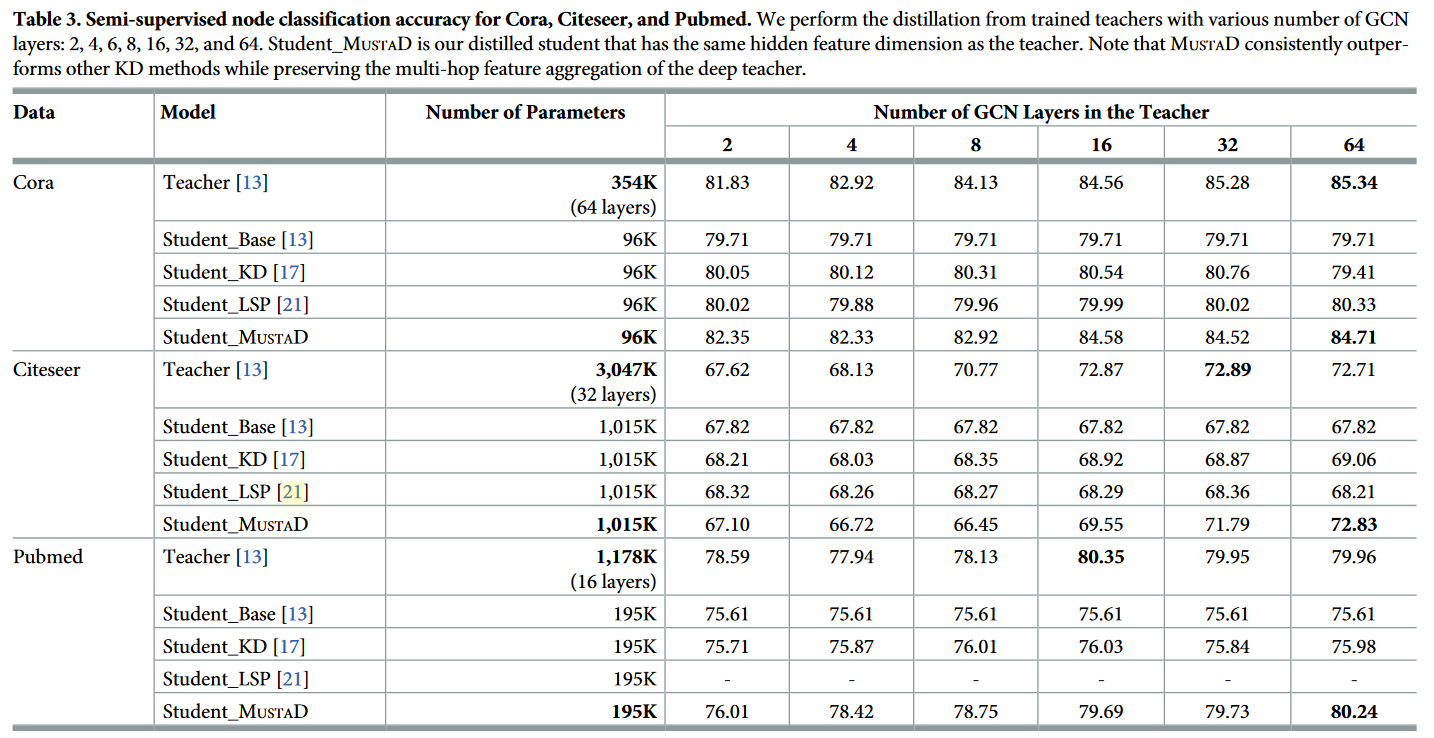
表3:半监督节点分类准确率为Cora、Citeseer和Pubmed。我们对不同GCN层数( 2、4、6、8、16、32、64 )的受训教师进行蒸馏。Student _ MUSTAD是我们的蒸馏学生,与教师具有相同的隐藏特征维度。值得注意的是,MUSTAD在保持深度教师的多跳特征聚合的同时,始终优于其他KD方法。
表3显示了 50 次运行后节点分类的平均准确率的总体结果。值得注意的是,我们的MUSTAD在准确性方面给出了最好的性能。特别地,Student _ MUSTAD 以 3.00 ~ 6.04 × 比最佳教师更小的模型大小,为次优模型提供了3.77 ~ 4.21 % 的改进。此外,与其他 KD 方法不同,所提出的 MUSTAD 的性能随着教师的层数增加而增加。这表明 MUSTAD 成功地保留了聚集过程,而其他的则没有。这也意味着,当教师使用更多的 GCN 层时,MUSTAD 从给定的输入特征中获得了更多的知识。
在 Citeseer 和 Pubmed 中,当学生模仿教师的 64 个 GCN 层时,MUSTAD 取得了最好的表现。然而,当堆叠层数分别超过 32 层和 16 层时,教师的性能下降。这表明 MUSTAD 可以使学生比教师从更远的节点收集信息。如果教师的准确性太低,我们的学生就不容易持续地表现出卓越的表现,因为 MUSTAD 旨在保留深层教师的准确性。然而,MUSTAD 从比教师更远的节点收集信息的能力缓解了学生对教师表现的强烈依赖。
ogbn-蛋白质
我们在ogbn - proteins数据集中使用训练好的GEN教师模型进行知识蒸馏。由于ogbn - proteins数据集密集且庞大,全批训练并非易事。我们应用一个随机节点采样器来生成批,用于小批量训练和测试。根据[ 8 ],我们将每个批的大小设置为一个子图。因此,随着批数量的增加,每个批中的子图的大小减小,从而导致性能下降。通过实验,我们在GPU (精视2080Ti具有11GB的内存)中增加了从10到40的批次来拟合大图,而[ 8 ]使用了内存为32GB的NVIDIA V100。因此,尽管[ 8 ]达到了112层,但转写教师以28层达到了最好的性能。不失一般性,我们对再现的教师进行蒸馏,并与其他方法进行比较,验证我们的MUSTAD。
我们在半监督的情况下评估了每种方法在多标记节点分类任务上的性能。我们训练 λ pred 为 0.1的 Student _ KD 和 λ LSP为 10 的 Student _ LSP。对于竞争者,每个超参数都进行了调整,以在验证集上获得最佳结果。对于我们的模型,我们将 λ pred 设置为 0.1,λ emb 设置为 0.01,核函数设置为 KL 散度。
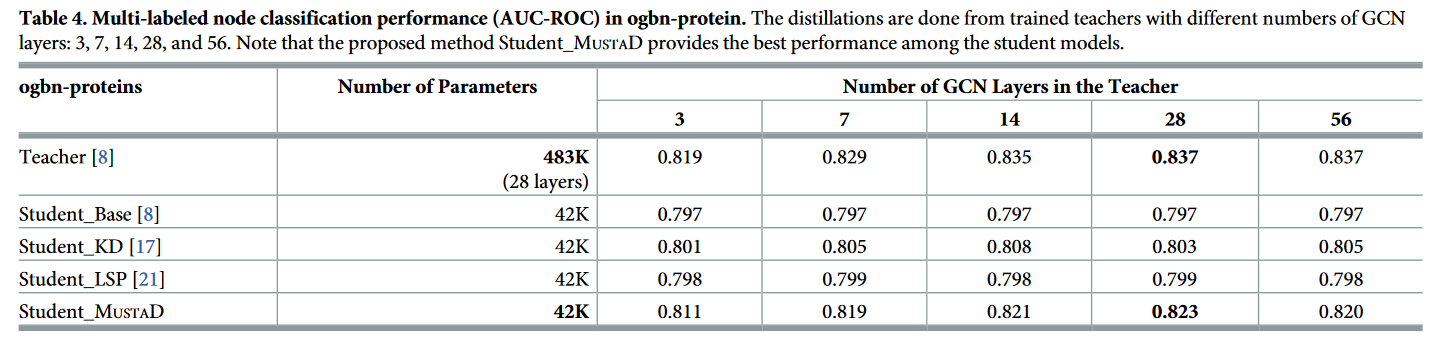
表4:ogbn蛋白的多标记节点分类性能( AUC-ROC )。蒸馏是由经过培训的教师完成的,GCN层数分别为3,7,14,28和56。值得注意的是,所提出的方法Student _ MUSTAD在学生模型中提供了最好的性能。
表4总结了 AUC - ROC 的结果。MUSTAD 比次优 KD 模型的 AUC - ROC 提高了 1.55 % p,但需要的参数比教师少 11.41 ×。表3和表4显示,我们的 MUSTAD 在各种教师模型中达到了最先进的性能。
参数与性能
我们进行了一个参数研究,以显示参数数量和准确性之间的权衡。我们通过改变隐藏特征维度和学生中有效层的数量来改变参数的数量。此外,我们改变了用于提取多跳特征表示知识的核函数,并对其性能进行了评估。我们与经过培训的 64 层 GCNII 教师一起分析科拉。
隐藏特征维度
我们将学生的隐藏特征维度设置为与上一节中教师的相同;它限制了模型的压缩程度。我们在表5中研究了隐藏特征维度和准确率之间的权衡。特别地,我们将特征维度从 16 变化到 128。

表5:隐藏特征维度与准确率之间的权衡。值得注意的是,提出的隐藏特征维度为 64 的MUSTAD显示出最佳的性能。
从表中可以看出,隐藏特征维度为 64 的 Student _ MUSTAD 取得了最好的性能。值得注意的是,为学生设置与教师相同的特征维度,即使在使用明显较小的层数时,也显示出最佳的性能。值得注意的是,在表3所示的 KD 方法中,隐藏特征维度为 32 的 Student _ MUSTAD 仍然表现出最好的性能,同时需要比竞争对手少 1.96 × 的参数,比教师少 7.22 × 的参数。当特征维数设置为 128 时,由于过拟合的原因,MUSTAD 的性能低于特征维数为 64 的 MUSTAD。
有效层数
我们提出的 MUSTAD 将教师的隐藏 GCN 层压缩为学生的单个有效层。我们研究了 MUSTAD 的精度是如何随着有效层数的增加而变化的。然而,为了增加有效层的数量,我们必须设置学生中每个有效层所模仿的教师层的数量。令 M 表示学生中有效层的个数。我们调整了由教师层的数量组成的集合 L,其中每个有效层在学生模仿的
[ { 1 , 63 } , { 32 , 32 } , { 63 , 1 }] ( M = 2 )
[ { 1,22,41 } , { 21,22,1 } , { 41,22,1 }] ( M = 3 )
[ { 1 , 11 , 21 , 31 } , { 16 , 16 , 16 } , { 31 , 21 , 11 , 1 }] ( M = 4 )中。
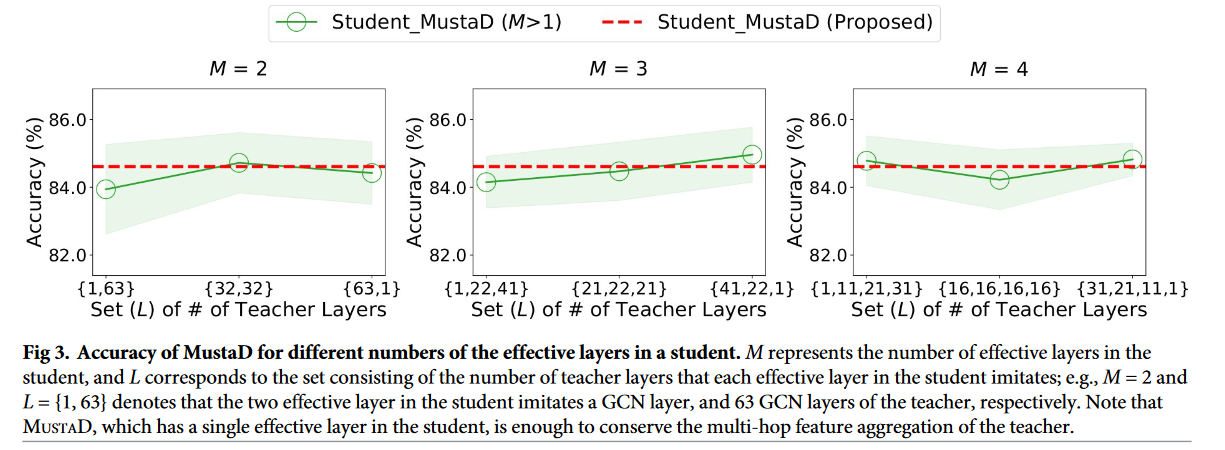
图3:一名学生不同有效层数的 Musta D 的精度。M 代表学生中有效层的数量,L 对应学生中每个有效层模仿的教师层数组成的集合;例如,M = 2,L = { 1,63 } 分别表示学生的两个有效层模仿教师的一个 GCN 层和 63 个 GCN 层。值得注意的是,MUSTAD 在学生中具有单一的有效层,足以保存教师的多跳特征聚合。
从图 3 可以看出,拥有多个有效层的学生表现出与拥有单个有效层的学生相似的表现。这表明学生中的单个有效层足以保存教师的多跳特征聚合过程。
核函数
MUSTAD 使用各种核函数(式5 )从教师那里提取多跳特征表示的知识。我们在 Cora 中比较了不同核函数的学生,并在表6中展示了结果。

表6:不同核函数在 Cora 数据集上的准确率。值得注意的是,KL 基于散度的核提供了最好的准确性,而没有嵌入蒸馏的学生’ None '表现出了较差的性能。
对于基于距离的核,我们将 p 设置为 2。对于多项式核,c 和 d 分别设置为 2 和 0。对于 RBF 核,σ 设为 1。表6 中,"无"代表未经过多阶段知识蒸馏的学生模型;也就是说,它只提取了任务预测,而不是嵌入。
值得注意的是,"无"学生的表现比用核函数提取嵌入的学生差。在核函数中,KL 散度表现出最好的准确性。
5、消融研究
我们对教师的多阶段知识蒸馏效果和学生的单一有效层效果进行了消融研究。研究在三个引文数据集中进行;Cora、Citeseer、Pubmed。
多阶段知识蒸馏
MUSTAD以多阶段的方式提取教师的知识,以保持准确性。我们在图4中展示了多阶段知识蒸馏的效果。值得注意的是,Student _ MUSTAD (无需多级KD)是在不提取多跳特征表示知识的情况下进行训练的;也就是说,教师只向学生提取任务预测的知识。
如果只提取任务预测的知识,教师的预测错误直接传播给学生。然而,多跳特征的蒸馏弥补了误差,因此,与没有蒸馏的MUSTAD相比,具有蒸馏的MUSTAD表现出更优越的性能,如图4所示。
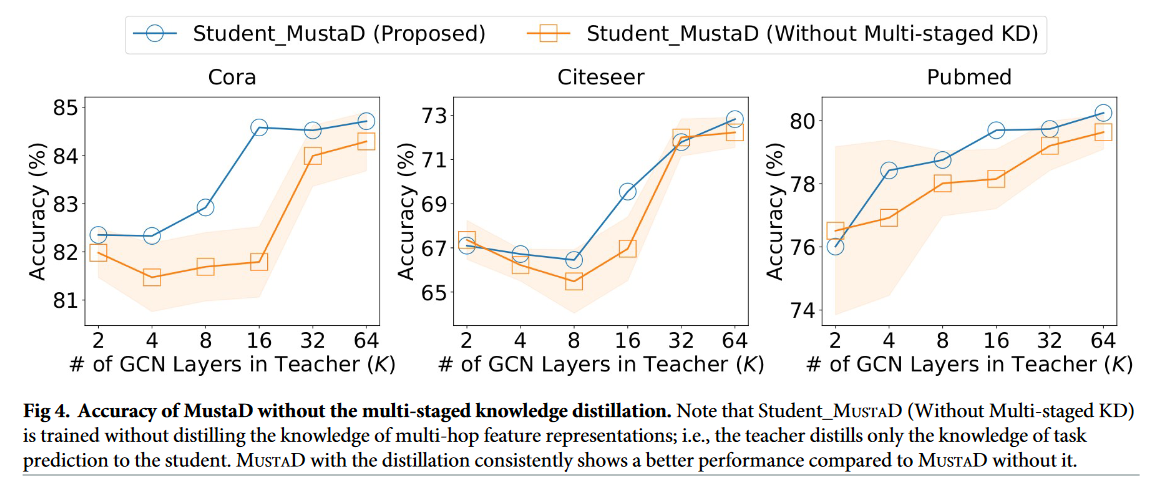
图4:未经多阶段知识蒸馏的Musta D准确性。值得注意的是,Student _ MUSTAD ( UnMulti-staged KD )是在不提取多跳特征表示知识的情况下进行训练的;也就是说,教师只向学生提取任务预测的知识。有蒸馏的MUSTAD始终表现出比无蒸馏的MUSTAD更好的性能。
也就是说,多阶段的知识升华对于从教师那里获得适当的知识起着至关重要的作用。
单一有效层
MUSTAD 通过单个有效层来模拟教师的多跳特征聚合过程。我们通过将提出的 MUSTAD 与一个具有单一朴素 GCN 层的学生进行比较来考察单一有效层的效果。
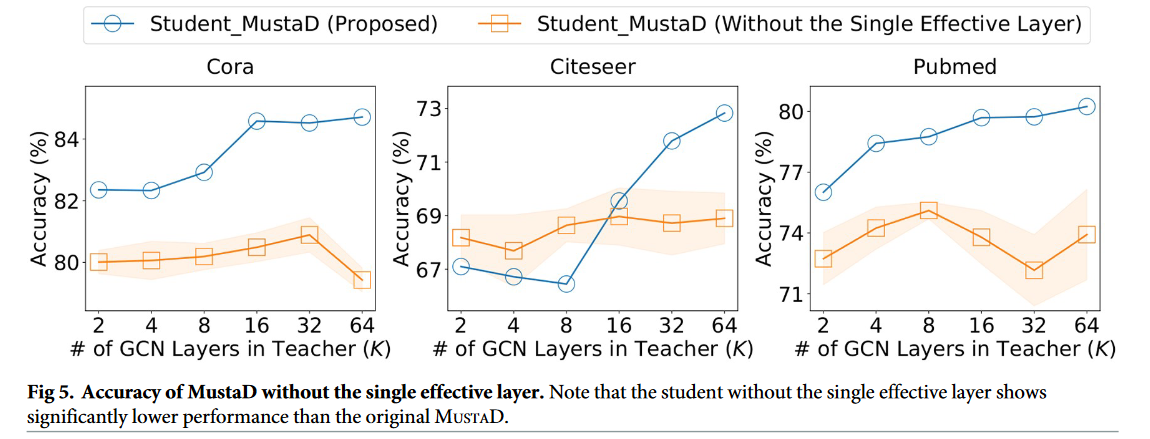
图5:不含单一有效层的 Musta D 精度。值得注意的是,没有单个有效层的学生表现出明显低于原始 MUSTAD 的性能。
从图5可以看出,不含单一有效层的 MUSTAD 性能明显低于原始 MUSTAD。此外,没有有效层的 MUSTAD 的准确率不会随着教师中 GCN 层数 K 的增加而提高,而有有效层的 MUSTAD 的性能会随着 K 的增加而提高。这是因为该方法保留了教师的多跳特征聚合,其主要目的是在教师的多个层中,由单一的有效层组成。
6、结论
在这项工作中,我们提出了 MUSTAD,一种通过从教师中提取多阶段知识来压缩深度图卷积网络( GCNs )的精确方法。MUSTAD 通过在一个学生中使用单个有效层来模仿多个 GCN 层来提取教师的多跳特征聚合知识,显著降低了模型大小,并通过将教师的最终隐藏特征嵌入传递给学生。MUSTAD 还通过传递教师的预测来提取任务预测的知识。我们给出了 MUSTAD 的理论分析,比较了所提方法与多层 GCN 在谱域上的表达能力。与其他基于蒸馏的 GCN 压缩方法相比,MUSTAD 在四个真实世界数据集中取得了最先进的性能,保留了教师的多跳特征聚合。未来的工作包括扩展 MUSTAD 以考虑特征的语义。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











