







Hadoop的基础操作
- HDFS是Hadoop的分布式文件框架,它的实际目标是能够在普通的硬件上运行,并且能够处理大量的数据。
- HDFS采用主从架构,其中由一个NameNode和多个DataNode
- NameNode负责管理文件系统的命名空间和客户端的访问
- DataNode负责存储实际的数据块
HDFS的基本操作包括文件的上传,下载,删除,重命名等
文件操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lM0WhMnI-1684976584539)(E:\Java笔记\大数据\Hadoop\Hadoop的基础操作\Hadoop的基础操作.assets\image-20230522092333144.png)]](https://i-blog.csdnimg.cn/blog_migrate/50f5b0d64ba38b9051763787e6d15e4d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EOfiOqXm-1684976584540)(E:\Java笔记\大数据\Hadoop\Hadoop的基础操作\Hadoop的基础操作.assets\image-20230522092349584.png)]](https://i-blog.csdnimg.cn/blog_migrate/01063fffe7b65098a4d6bd70e408e628.png)
手动创建文件夹:
语法:
hadoop fs -mkdir <HDFS文件路径>
示例:
# 创建文件夹(根目录创建名为input的文件夹)
[root@master ~]# hadoop fs -mkdir /input
# 创建文件夹(根目录创建名为user的文件夹)
[root@master ~]# hdfs dfs -mkdir /user
# 创建多级目录
[root@master ~]# hdfs dfs -mkdir -p /user/resource/example
手动上传文件
语法:
hadoop fs -put <本地文件路径> <HDFS文件路径>
示例:
# 将本地/usr/text.txt 文件上传到input文件下
[root@master ~]# hadoop fs -put /usr/text.txt /input
# 将本地/usr/text.txt 文件上传到input文件下。-copyFromLocal:本地复制
[root@master ~]# hdfs dfs -copyFromLocal /usr/text.txt /user
# 将本地/usr/text.txt 文件上传到input文件下
[root@master ~]# hdfs dfs -put /usr/text.txt /input
# 将本地/usr/text.txt 文件上传到input文件下。-moveFromLocal:本地迁移
[root@master ~]# hdfs dfs -moveFromLocal /usr/text.txt /user
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9osLRhW3-1684976584541)(E:\Java笔记\大数据\Hadoop\Hadoop的基础操作\Hadoop的基础操作.assets\image-20230522094753675.png)]](https://i-blog.csdnimg.cn/blog_migrate/96c6850af61f895692e83f83d58b588b.png)
查看文件
[root@master ~]# hadoop fs -ls /
[root@master ~]# hdfs dfs -ls /
下载文件
语法:
hadoop fs -get <HDFS文件路径> <本地路径>
hadoop fs -copyToLocal <HDFS文件路径> <本地路径>
示例:
# 将user/text.txt文件下载到本地/usr/local/下 -copyToLocal:复制到本地
[root@master ~]# hadoop fs -copyToLocal /user/text.txt /usr/local/
[root@master ~]# cd /usr/local/
[root@master local]# ll
-rw-r--r--. 1 root root 0 5月 22 09:51 text.txt
[root@master ~]# hdfs dfs -copyToLocal /user/text.txt /usr/local/
[root@master ~]# cd /usr/local/
[root@master local]# ll
-rw-r--r--. 1 root root 0 5月 22 09:51 text.txt
# 将user/text.txt文件下载到本地/usr/local/下
[root@master local]# hadoop fs -get /user/resource/text.txt /usr/local
[root@master local]# ll
-rw-r--r--. 1 root root 0 5月 22 09:54 text.txt
# 将user/text.txt文件下载到本地/usr/local/下
[root@master local]# hdfs dfs -get /user/resource/text.txt /usr/local
[root@master local]# ll
-rw-r--r--. 1 root root 0 5月 22 09:54 text.txt
查看文件内容
语法:
hdfs dfs -cat <HDFS文件路径>
示例:
[root@master local]# hdfs dfs -cat /input/text.txt
hello ,hadoop
[root@master local]# hdfs dfs -tail /input/text.txt
hello ,hadoop
删除文件
语法:
hadoop fs -rm <HDFS文件路径>
示例:
# 删除文件夹
[root@master ~]# hdfs dfs -mkdir /user/resource
[root@master ~]# hdfs dfs -rmdir /user/resource
[root@master ~]# hadoop fs -rm -f /user/resource
# 删除文件
[root@master ~]# hdfs dfs -rm /user/resoure/text.txt
[root@master ~]# hadoop fs -rm -r /user/resource/text.txt
文件重命名
语法:
hadoop fs -mv <HDFS文件路径> <HDFS文件路径>
示例:
[root@master ~]# hadoop fs -mv /input/test.txt /input/demo.txt
文件修改权限
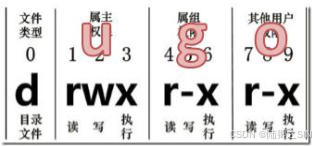
1)第一种方式:使用符号方式
HDFS 中可以通过符号模式来修改文件或目录的权限。这种方式与 Linux 中的 chmod 命令相似,能够通过指定用户、组、其他人(u、g、o)和权限(rwx)来修改文件权限。
语法:
hadoop fs -chmod [选项] 模式 文件或目录
-
选项
- R:递归处理,适用于目录及其所有子文件和子目录。
-
模式:
{ugoa}{+-=}{rwx}u:代表所属者(user)。g:代表所属组(group)。o:代表其他人(others)。a:代表所有人(all,即u、g、o的总和)。+:添加权限。-:删除权限。=:设置明确的权限。
例如:
u+x:给所属者添加执行权限。g-w:给所属组去掉写权限。a=r:给所有人设置为只读权限。
示例:
-
给所属者添加执行权限:
hadoop fs -chmod u+x /user/hadoop/myfile.txt -
给所有人添加读权限:
hadoop fs -chmod a+r /user/hadoop/myfile.txt -
递归给所有文件和目录添加读写权限:
hadoop fs -chmod -R a+rw /user/hadoop/mydir
2)第二种方式:使用八进制模式
八进制模式(数字模式)来修改权限,这种方式同样是 Linux 中常见的方式。在 HDFS 中,使用八进制模式时,数字代表特定的权限值。
chmod [选项] [八进制模式] 文件或目录
- 选项
- R:递归处理
- 八进制模式
r(读权限)= 4w(写权限)= 2x(执行权限)= 1- wx=2+1=3
- rx=4+1=5
- rw=4+2=6
- rwx=4+2+1=7
示例:
-
设置文件
myfile.txt的权限为755:hadoop fs -chmod 755 /user/hadoop/myfile.txt这表示:
- 所有者有读、写、执行权限(7)。
- 所属组和其他人有读、执行权限(5)。
-
设置目录
mydir的权限为777:hadoop fs -chmod 777 /user/hadoop/mydir这表示所有人都具有读、写和执行权限。
-
递归设置所有文件和子目录权限为
644:hadoop fs -chmod -R 644 /user/hadoop/mydir
查看集群的基本信息
[root@master ~]# hdfs fsck /
Connecting to namenode via http://192.168.184.130:50070/fsck?ugi=root&path=%2F
FSCK started by root (auth:SIMPLE) from /192.168.184.130 for path / at Tue May 23 10:42:27 CST 2023
/input/text.txt: Under replicated BP-399935676-192.168.184.130-1684307575827:blk_1073741825_1001. Target Replicas is 3 but found 1 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
Status: HEALTHY
Number of data-nodes: 1
Number of racks: 1
Total dirs: 6
Total symlinks: 0
Replicated Blocks:
Total size: 13 B
Total files: 3
Total blocks (validated): 1 (avg. block size 13 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (100.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 1.0
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 2 (66.666664 %)
Blocks queued for replication: 0
Erasure Coded Block Groups:
Total size: 0 B
Total files: 0
Total block groups (validated): 0
Minimally erasure-coded block groups: 0
Over-erasure-coded block groups: 0
Under-erasure-coded block groups: 0
Unsatisfactory placement block groups: 0
Average block group size: 0.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0
Blocks queued for replication: 0
FSCK ended at Tue May 23 10:42:27 CST 2023 in 18 milliseconds
The filesystem under path '/' is HEALTHY
在Hadoop的集群的基本信息主要包含分布式文件系统HDFS和分布式资源管理YARN
分布式文件系统HDFS主要包含文件系统的状态,是否有块丢失,备份丢失等,同时包含集群节点状态等。
分布式资源管理YARN主要包含集群节点状态,节点资源(内存,CPU等),队列状态等
Hadoop安全模式
-
安全模式是保证系统保密性,完整性及可使用性的一种机制,一定程度上可以防止系统里的资源遭到破坏,更改和泄露,使得整个系统持续,可靠的正常运行。
-
Hadoop集群也有安全模式,在安全模式下可保证Hadoop集群中数据块的安全性。对Hadoop集群可以进行查看安全模式,解除和开启安全模式的操作,
查看namenode是否处于安全模式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XDZd0DrY-1684976584541)(E:\Java笔记\大数据\Hadoop\Hadoop的基础操作\Hadoop的基础操作.assets\image-20230523105942500.png)]](https://i-blog.csdnimg.cn/blog_migrate/e270810ab6776135f1e60a5fb7848542.png)
[root@master ~]# hdfs dfsadmin -safemode get
Safe mode is OFF
进入安装模式
[root@master ~]# hdfs dfsadmin -safemode enter
Safe mode is ON
解除安全模式
[root@master ~]# hdfs dfsadmin -safemode leave
Safe mode is OFF
执行MapReduce任务
语法:
hadoop jar <jar包名称> <MapReduce程序类名> <输入路径> <输出路径>
示例:
[root@master ~]# hadoop jar wordcount.jar WordCount /user/hadoop/input /user/hadoop/output
启动集群
启动hadoop集群需要先启动NameNode和DataNode
start-dfs.sh
start-yarn.sh
停止集群
停止hadoop集群需要先停止YARN和HDFS
stop-dfs.sh
start-yarn.sh


















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











