







目录
目录
为什么使用卡尔曼滤波器?
卡尔曼滤波器是一种优化估计算法。通过优化估计,卡尔曼滤波器能够提供对系统状态的最佳估计,并具有较小的估计误差,可以提高系统的性能和鲁棒性。
卡尔曼滤波自从1960被Kalman发明并应用到阿波罗登月计划之后一直经久不衰,直到现在也被机器人、自动驾驶、飞行控制等领域应用。
这里通过讨论两个例子来解释卡尔曼滤波器的常见用途。
例一:当系统状态无法直接被测量时,卡尔曼滤波器如何用来估计系统状态。
星际旅行是人类步入现代文明后一直想实现的梦想。如图所示,假设我们乘坐一艘太空飞船从地球飞往火星,这艘太空飞船的发动机能够在超高的温度下燃烧燃料,那么产生的推力就可以让我们飞往火星。
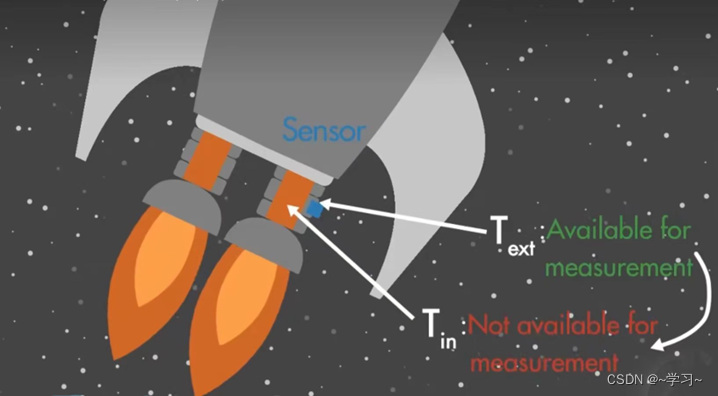
根据国家航天航空局的说法,液氧甲烷轻且性能强大,使用成本低廉,综合特性非常适合可回收复用火箭技术的发展潮流,液氧甲烷火箭燃烧温度可达到约3000°C。所以超高的温度可能会使发动机的机械部件失效,为了避免这种情况,我们的密切监控燃烧室内部温度。(PS:北京时间2023年7月12日9时00分,以液氧甲烷为推进剂的朱雀二号遥二运载火箭在中国酒泉卫星发射中心成功发射。这是人类首次成功入轨飞行的液氧甲烷火箭,标志着中国航天在新型低成本液体推进剂运载火箭应用方面取得了重大突破。)
但是,传感器如果放在发动机燃烧室内会被熔化掉,所以需要把传感器放在燃烧室附近温度较低的地方。这样会产生一个问题:我们无法直接测量发动机燃烧室内部温度,只能测量外部温度。这种情况下,我们就可以用到卡尔曼滤波器,利用间接测量值,计算内部温度的最优估计值。
例二:如何使用卡尔曼滤波器组合各种可能受到噪音影响的数据源来估计系统状态。

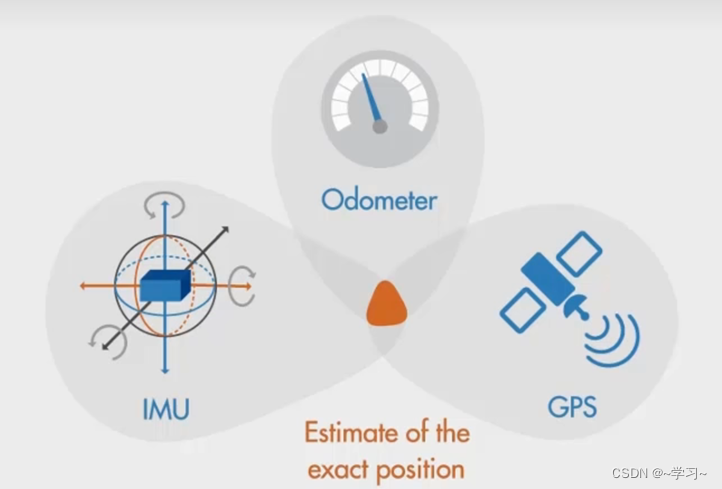
假如你正在驾驶汽车打算从A地到B地,使用汽车的导航系统进行导航。那些得到当前位置并导航你到B地的车载传感器一般有:
- 惯性测量单元(IMU):使用加速度计和陀螺仪来测量汽车的加速度和角速度。
- 里程表:测量汽车行驶的相对距离。
- GPS:接收器接收来自卫星的信号,并定位汽车在地球表面的位置。
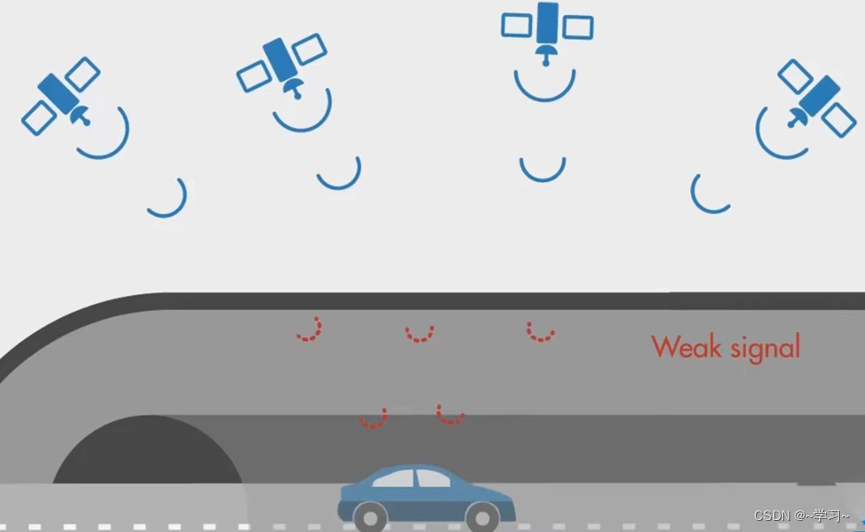
假设从A地到B地需要进行一条很长的隧道,而在隧道里GPS信号很弱,很难用GPS来估计位置。
为了能更准确的估算位置,结合使用IMU测量值和里程表读数可以测量汽车的相对位置,它可以快速更新,但同时也很容易漂移;GPS接收器提供您的绝对位置,但它更新没那么快,而且可能会有噪音。这时,我们就可以使用卡尔曼滤波器,结合三个测量值,得到汽车最合适的估算位置。
卡尔曼滤波器基础知识及公式理解
1、卡尔曼滤波器是什么以及它是如何工作的?
这里将通过上面的例一来讨状态观测器, 这个过程有助于解释卡尔曼滤波器是什么和它是如何工作的(卡尔曼滤波器是一种状态观测器)。
假设我想知道发动机的内部温度![]() 有多高, 因为它告诉我应该如何去调节火箭的燃料流量
有多高, 因为它告诉我应该如何去调节火箭的燃料流量![]() ,但是我无法直接测量
,但是我无法直接测量![]() ,不过我可以测量发动机外部温度
,不过我可以测量发动机外部温度![]() 。因此,我们可以使用的已知信号量有
。因此,我们可以使用的已知信号量有![]() 、
、![]() ,那么如何估算
,那么如何估算![]() 呢?这时我们可以利用数学知识,得到真实系统的数学模型,然后把已知信号量为
呢?这时我们可以利用数学知识,得到真实系统的数学模型,然后把已知信号量为![]() 作为输入,输入到数学模型中,由于我们知道所有的系统方程,所以我们可以得到输出的估计状态
作为输入,输入到数学模型中,由于我们知道所有的系统方程,所以我们可以得到输出的估计状态![]() ,包括我们想知道的内部温度估计状态
,包括我们想知道的内部温度估计状态![]() 。
。
如果这是有一个理想数学模型,没有任何不确定性,当真实系统和数学模型具有相同的初始条件时,测量值和估算值能相互匹配,因此估算的内部温度也会与真实的内部温度吻合,但在现实生活中,这是不太可能的。现实中![]() 不吻合
不吻合![]() ,那么
,那么![]() 肯定也不吻合
肯定也不吻合![]() 。
。
这里需要设置一个目标:让输出的估计状态![]() 与输出
与输出![]() 吻合。如果这两者相等,那么表示数学模型收敛到了真实系统,因此内部温度估计状态
吻合。如果这两者相等,那么表示数学模型收敛到了真实系统,因此内部温度估计状态![]() 也能收敛到真实的内部温度
也能收敛到真实的内部温度![]() 。
。
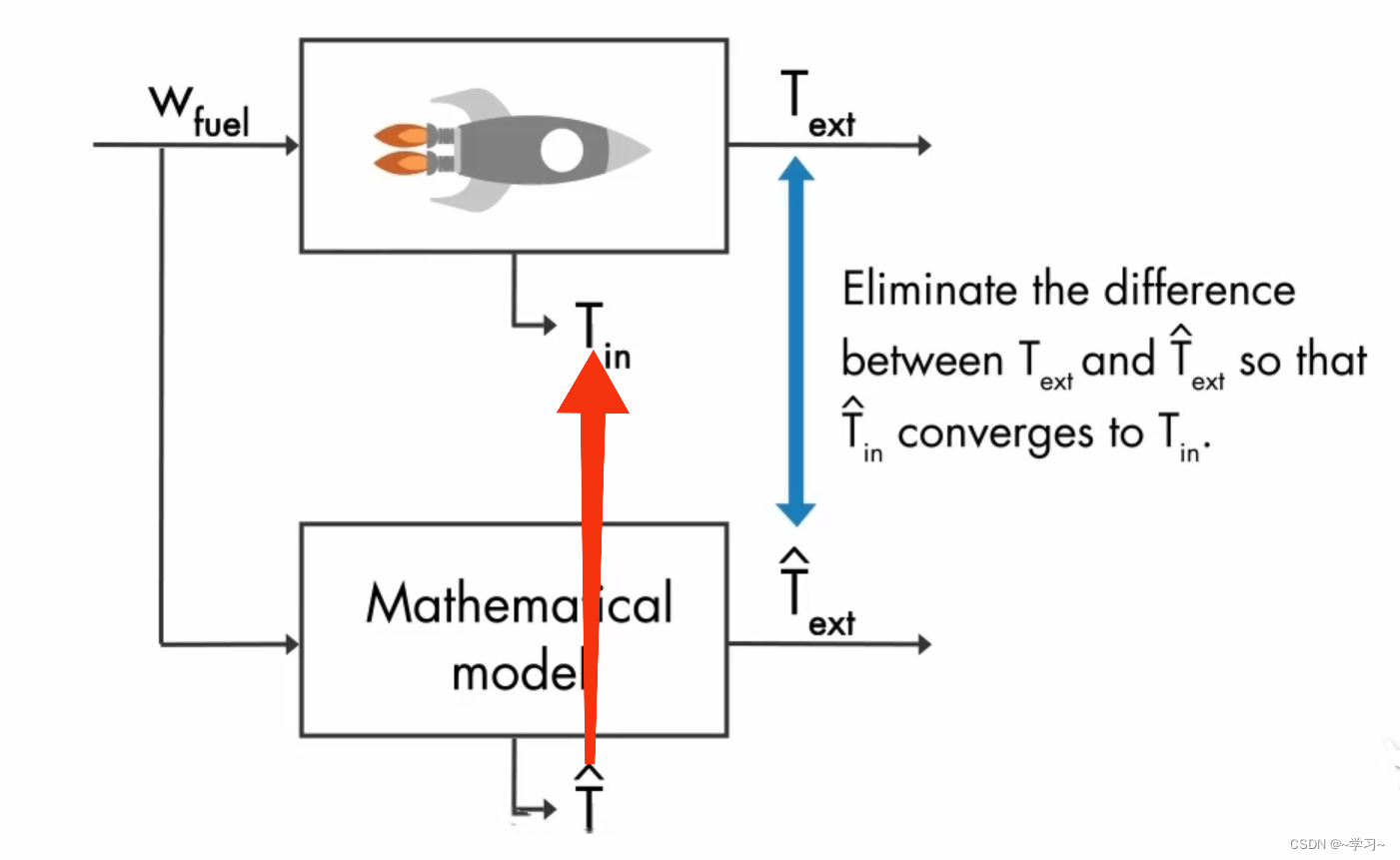
如下图所示,我们需要使用控制器K控制测量外部温度![]() 和估计外部温度
和估计外部温度![]() 之间的误差(error =
之间的误差(error = ![]() )近似为0,所以如何选择控制器K增益是关键。
)近似为0,所以如何选择控制器K增益是关键。
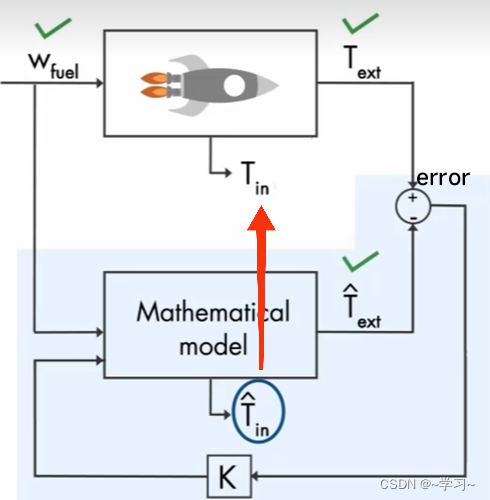
我们可以用数学方式来解释上述内容, 设输入为u,输出为y,想要估计的状态为x,目标是:让输出估计值![]() 与输出真实值y的误差逼近为0,进而得到收敛于真实系统的数学模型,最终使估计状态
与输出真实值y的误差逼近为0,进而得到收敛于真实系统的数学模型,最终使估计状态![]() 逼近真实状态x。如下图所示(通常是用差分方程来描述,这里使用微分方程来表示,看看估计状态变量思路就行):
逼近真实状态x。如下图所示(通常是用差分方程来描述,这里使用微分方程来表示,看看估计状态变量思路就行):

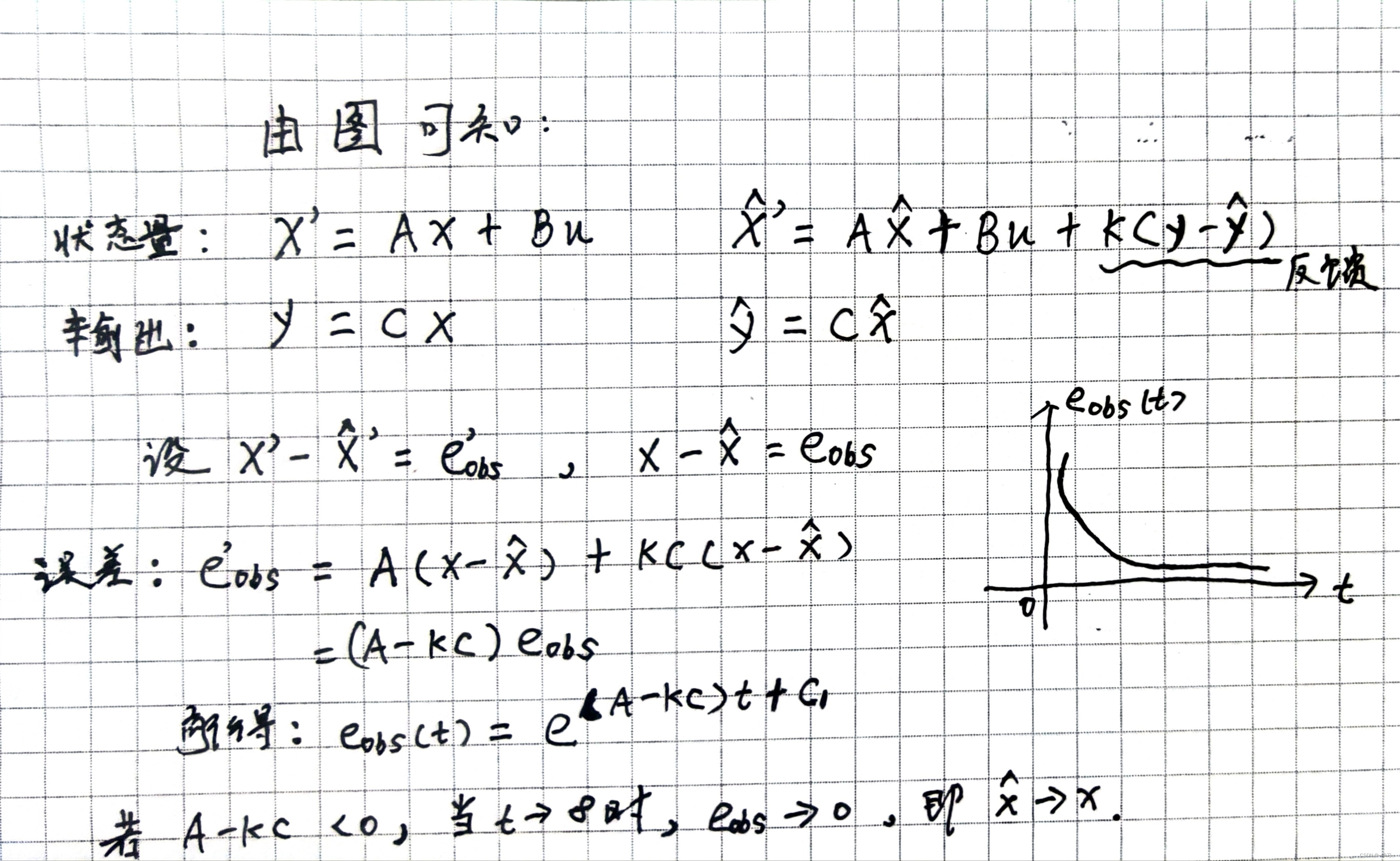
从上面的数学推导可以看出控制器K增益是关键,而选择增益K的最佳方法,也就是使用卡尔曼滤波器,因此也可K叫做卡尔曼增益。使用反馈控制器K可以更好地控制这些方程,控制误差衰减的速度,从而确保更快地消除错误,使估算状态![]() 收敛到真实状态x的速度越快。
收敛到真实状态x的速度越快。
2、卡尔曼滤波器核心公式理解
状态观测器(State observer)公式和卡尔曼滤波公式非常相似,因为卡尔曼滤波器是一种状态观测器,上面也对状态观测器进行了分析。
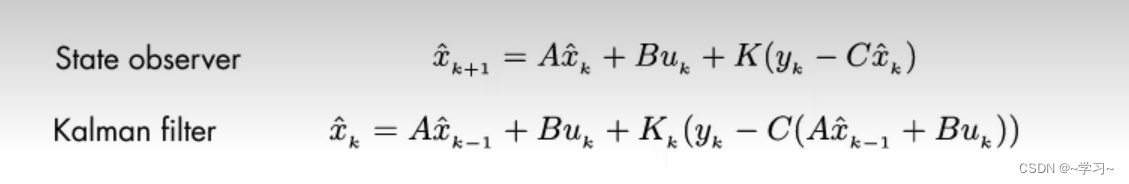
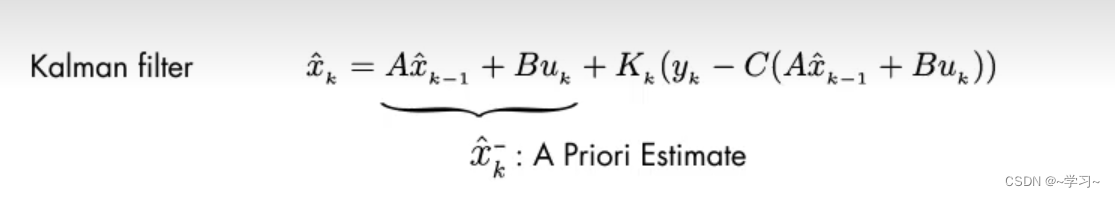
:先验估计,数学模型根据上一时刻的状态值预估的当前时刻的状态值。
:后验估计,是结合估计值和测量值后得到的最优结果值。
:卡尔曼增益,是权重项,可大可小。比如它的值为0,表示传感器的值不可信,或者它的值为100表示数学模型的预估值不是很准确。
:传感器的测量值,测量方程为:y(k) = Cx(k) + V(k),V(k)为测量噪声。
这里可以将卡尔曼滤波公式更新为:

从上式可以看出,后验估计是通过卡尔曼增益来权衡先验估计和测量值与先验估计的差值后,得到的最优值。
预测和更新两大核心步骤公式:
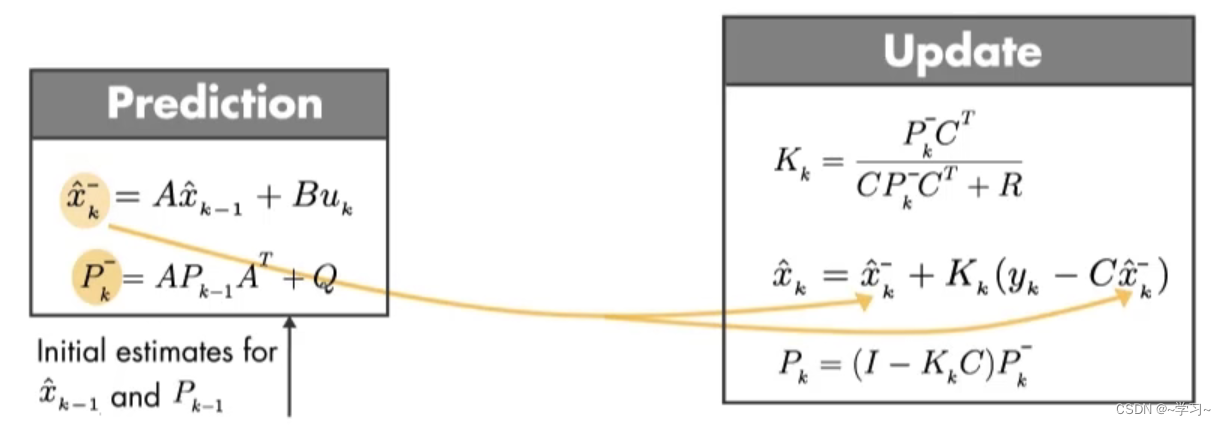
:协方差矩阵,表示观测的这些状态值之间的关系,若在单状态中,协方差矩阵就是方差。
Q:过程噪声协方差矩阵,w(k)过程噪声,通常假设为零均值的高斯白噪声,是预测步骤不确定性的度量。
R:测量噪声协方差矩阵,v(k)测量噪声,通常假设为零均值的高斯白噪声,由于传感器本身的不确定性、环境干扰和测量误差等因素引起的。
A:状态转移矩阵,描述系统状态在时间上演变规律的关键矩阵,例如,一个简单的一维运动系统,状态转移矩阵可以是一个1×1的矩阵,其元素为系统的速度更新率,表示每个时间段内速度的变化量。
B:卡尔曼控制矩阵,它将控制输入与状态之间的关系进行映射。例如,对于一个简单的运动系统,卡尔曼控制矩阵 B 可以表示为一个 n×p 的矩阵,其中每一列对应于对应控制输入对系统状态的影响。
C:状态观测矩阵,描述系统状态与传感器测量之间的线性关系,例如,如果系统状态表示位置和速度,而传感器测量只包含位置信息,则状态观测矩阵将是一个2×2的矩阵,将系统状态的位置映射为传感器测量的位置。
通过运行上面的五个公式,可以得到最优状态估计矩阵。卡尔曼滤波器分为三步,实现过程如下:
| 第一步:状态预测 | 根据系统模型,利用输入、上一时刻的状态估计值、 |
| 第二步:状态修正 | 基于Prediction步骤的结果( |
| 第三步:状态更新 | 将修正后的状态值和协方差矩阵作为当前时刻的最优状态估计。这一步骤还包括对状态估计的初始条件的设置。 |
卡尔曼的核心就是求取卡尔曼增益,也就是加权。卡尔曼增益作为状态修正的权重,影响了状态估计的准确性。增益越大,测量值的影响越大,修正量将更多地受到测量的影响;增益越小,预测的值影响越大,修正量将更多地受到预测的影响。
实现思路总结如下:
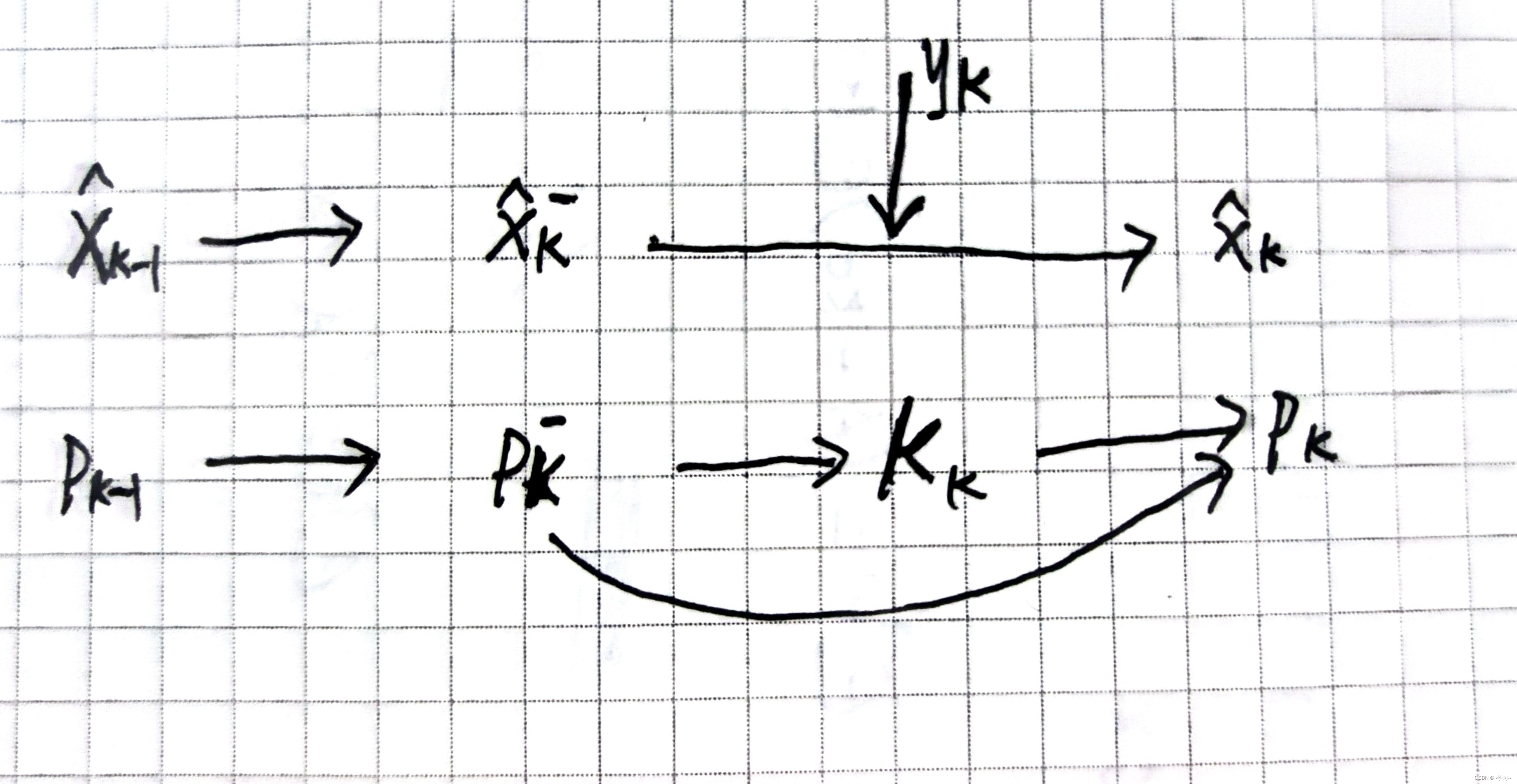
根据上面卡尔曼预测和更新五大公式,写一下具体实现步骤:

卡尔曼滤波器应用实例
1、基础卡尔曼算法
import numbers
import numpy as np
import matplotlib.pyplot as plt
import math
# 卡尔曼滤波器需要调用的矩阵类
class Matrix(object):
# 构造矩阵
def __init__(self, grid):
self.g = np.array(grid)
self.h = len(grid)
self.w = len(grid[0])
# 单位矩阵
def identity(n):
return Matrix(np.eye(n))
# 矩阵的迹
def trace(self):
if not self.is_square():
raise(ValueError, "Cannot calculate the trace of a non-square matrix.")
else:
return self.g.trace()
# 逆矩阵
def inverse(self):
if not self.is_square():
raise(ValueError, "Non-square Matrix does not have an inverse.")
if self.h > 2:
raise(NotImplementedError, "inversion not implemented for matrices larger than 2x2.")
if self.h == 1:
m = Matrix([[1/self[0][0]]])
return m
if self.h == 2:
try:
m = Matrix(np.matrix(self.g).I)
return m
except np.linalg.linalg.LinAlgError as e:
print("Determinant shouldn't be zero.", e)
# 转置矩阵
def T(self):
T = self.g.T
return Matrix(T)
# 判断矩阵是否为方阵
def is_square(self):
return self.h == self.w
# 通过[]访问
def __getitem__(self,idx):
return self.g[idx]
# 打印矩阵的元素
def __repr__(self):
s = ""
for row in self.g:
s += " ".join(["{} ".format(x) for x in row])
s += "\n"
return s
# 加法
def __add__(self,other):
if self.h != other.h or self.w != other.w:
raise(ValueError, "Matrices can only be added if the dimensions are the same")
else:
return Matrix(self.g + other.g)
# 相反数
def __neg__(self):
return Matrix(-self.g)
#减法
def __sub__(self, other):
if self.h != other.h or self.w != other.w:
raise(ValueError, "Matrices can only be subtracted if the dimensions are the same")
else:
return Matrix(self.g - other.g)
# 矩阵乘法:两个矩阵相乘
def __mul__(self, other):
if self.w != other.h:
raise(ValueError, "number of columns of the pre-matrix must equal the number of rows of the post-matrix")
#return Matrix(np.dot(self.g, other.g))
return Matrix(self.g.dot(other.g))
# 标量乘法:变量乘以矩阵
def __rmul__(self, other):
if isinstance(other, numbers.Number):
return Matrix(other * self.g)
# 生成汽车行驶的真实数据
# 汽车从以初速度v0,加速度a行驶10秒钟,然后匀速行驶20秒
# x0:initial distance, m
# v0:initial velocity, m/s
# a:acceleration,m/s^2
# t1:加速行驶时间,s
# t2:匀速行驶时间,s
# dt:interval time, s
def generate_data(x0, v0, a, t1, t2, dt):
a_current = a
v_current = v0
t_current = 0
# 记录汽车运行的真实状态
a_list = []
v_list = []
t_list = []
# 汽车运行的两个阶段
# 第一阶段:加速行驶
while t_current <= t1:
# 记录汽车运行的真实状态
a_list.append(a_current)
v_list.append(v_current)
t_list.append(t_current)
# 汽车行驶的运动模型
v_current += a * dt
t_current += dt
# 第二阶段:匀速行驶
a_current = 0
while t2 > t_current >= t1:
# 记录汽车运行的真实状态
a_list.append(a_current)
v_list.append(v_current)
t_list.append(t_current)
# 汽车行驶的运动模型
t_current += dt
# 计算汽车行驶的真实距离
x = x0
x_list = [x0]
for i in range(len(t_list) - 1):
tdelta = t_list[i+1] - t_list[i]
x = x + v_list[i] * tdelta + 0.5 * a_list[i] * tdelta**2
x_list.append(x)
return t_list, x_list, v_list, a_list
# 生成雷达获得的数据。需要考虑误差,误差呈现高斯分布
def generate_lidar(x_list, standard_deviation):
return x_list + np.random.normal(0, standard_deviation, len(x_list))
# 获取汽车行驶的真实状态
t_list, x_list, v_list, a_list = generate_data(100, 10, 5, 5, 20, 0.1)
# 创建激光雷达的测量数据
# 测量误差的标准差。为了方便观测,这里把标准差设置成一个很大的值。一般是0.15.
standard_deviation = 0.15
# 雷达测量得到的距离
lidar_x_list = generate_lidar(x_list, standard_deviation)
# 雷达测量的时间
lidar_t_list = t_list
# 可视化.创建包含2*3个子图的视图
fig, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(2, 3, figsize=(20, 15))
# 真实距离
ax1.set_title("truth distance")
ax1.set_xlabel("time")
ax1.set_ylabel("distance")
ax1.set_xlim([0, 21])
ax1.set_ylim([0, 1000])
ax1.set_xticks(range(0, 21, 2))
ax1.set_yticks(range(0, 1000, 100))
ax1.plot(t_list, x_list)
# 真实速度
ax2.set_title("truth velocity")
ax2.set_xlabel("time")
ax2.set_ylabel("velocity")
ax2.set_xlim([0, 21])
ax2.set_ylim([0, 50])
ax2.set_xticks(range(0, 21, 2))
ax2.set_yticks(range(0, 50, 5))
ax2.plot(t_list, v_list)
# 真实加速度
ax3.set_title("truth acceleration")
ax3.set_xlabel("time")
ax3.set_ylabel("acceleration")
ax3.set_xlim([0, 21])
ax3.set_ylim([0, 8])
ax3.set_xticks(range(0, 21, 2))
ax3.set_yticks(range(8))
ax3.plot(t_list, a_list)
# 激光雷达测量结果
ax4.set_title("Lidar measurements VS truth")
ax4.set_xlabel("time")
ax4.set_ylabel("distance")
ax4.set_xlim([0, 21])
ax4.set_ylim([0, 1000])
ax4.set_xticks(range(0, 21, 2))
ax4.set_yticks(range(0, 1000, 100))
ax4.plot(t_list, x_list, label="truth distance")
ax4.scatter(lidar_t_list, lidar_x_list, label="Lidar distance", color="red", marker="o", s=2)
ax4.legend()
# plt.show()
# 使用卡尔曼滤波器
# 初始距离。注意:这里假设初始距离为0,因为无法测量初始距离。
initial_distance = 0
# 初始速度。注意:这里假设初始速度为0,因为无法测量初始速度。
initial_velocity = 0
# 状态矩阵的初始值
x_initial = Matrix([[initial_distance], [initial_velocity]])
# 误差协方差矩阵的初始值
P_initial = Matrix([[5, 0], [0, 5]])
# 加速度方差
acceleration_variance = 50
# 雷达测量结果方差
lidar_variance = standard_deviation**2
# 观测矩阵,联系预测向量和测量向量
H = Matrix([[1, 0]])
# 测量噪音协方差矩阵。因为测量值只有位置一个变量,所以这里是位置的方差。
R = Matrix([[lidar_variance]])
# 单位矩阵
I = Matrix.identity(2)
# 状态转移矩阵
def F_matrix(delta_t):
return Matrix([[1, delta_t], [0, 1]])
# 外部噪音协方差矩阵
def Q_matrix(delta_t, variance):
t4 = math.pow(delta_t, 4)
t3 = math.pow(delta_t, 3)
t2 = math.pow(delta_t, 2)
return variance * Matrix([[(1/4)*t4, (1/2)*t3], [(1/2)*t3, t2]])
def B_matrix(delta_t):
return Matrix([[delta_t**2 / 2], [delta_t]])
# 状态矩阵
x = x_initial
# 误差协方差矩阵
P = P_initial
# 记录卡尔曼滤波器计算得到的距离
x_result = []
# 记录卡尔曼滤波器的时间
time_result = []
# 记录卡尔曼滤波器得到的速度
v_result = []
for i in range(len(lidar_x_list) - 1):
delta_t = (lidar_t_list[i + 1] - lidar_t_list[i])
# 预测
F = F_matrix(delta_t)
Q = Q_matrix(delta_t, acceleration_variance)
# 注意:运动模型使用的是匀速运动,汽车实际上有一段时间是加速运动的
# 如果使用匀加速运动模型,会不会更加准确?
# 测试发现,几乎没有区别。。。
#B = B_matrix(delta_t)
#u = a_list[i]
#x_prime = F * x + u * B
x_prime = F * x
P_prime = F * P * F.T() + Q
# 更新
# 测量向量和状态向量的差值。注意:第一个时刻是没有测量值的,
# 只有经过一个脉冲周期,才能获得测量值。
y = Matrix([[lidar_x_list[i + 1]]]) - H * x_prime
S = H * P_prime * H.T() + R
K = P_prime * H.T() * S.inverse()
x = x_prime + K * y
P = (I - K * H) * P_prime
# Store distance and velocity belief and current time
x_result.append(x[0][0])
v_result.append(x[1][0])
time_result.append(lidar_t_list[i+1])
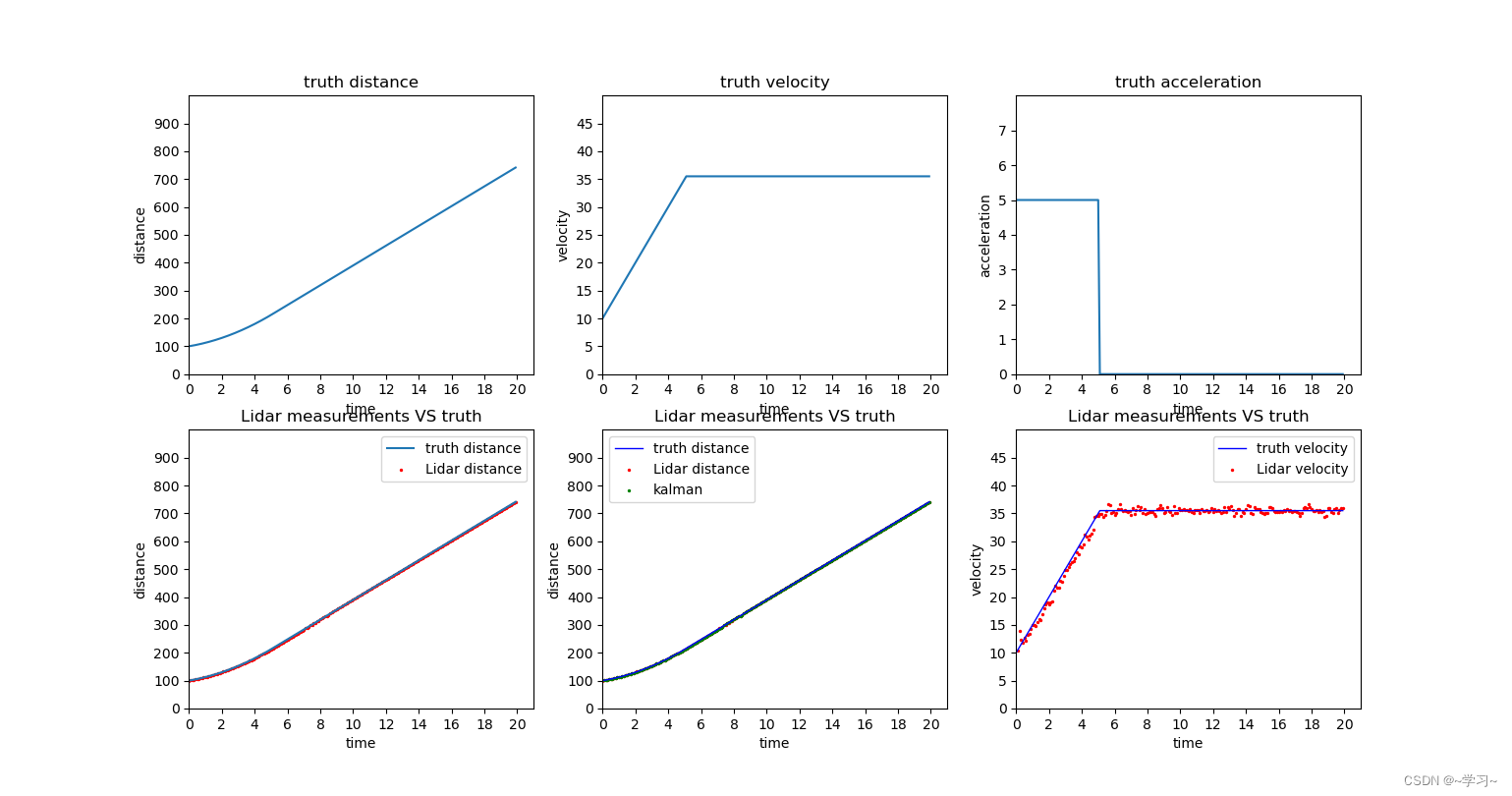
# 把真实距离、激光雷达测量的距离以及卡尔曼滤波器的结果(距离)可视化
ax5.set_title("Lidar measurements VS truth")
ax5.set_xlabel("time")
ax5.set_ylabel("distance")
ax5.set_xlim([0, 21])
ax5.set_ylim([0, 1000])
ax5.set_xticks(range(0, 21, 2))
ax5.set_yticks(range(0, 1000, 100))
ax5.plot(t_list, x_list, label="truth distance", color="blue", linewidth=1)
ax5.scatter(lidar_t_list, lidar_x_list, label="Lidar distance", color="red", marker="o", s=2)
ax5.scatter(time_result, x_result, label="kalman", color="green", marker="o", s=2)
ax5.legend()
# 把真实速度、卡尔曼滤波器的结果(速度)可视化
ax6.set_title("Lidar measurements VS truth")
ax6.set_xlabel("time")
ax6.set_ylabel("velocity")
ax6.set_xlim([0, 21])
ax6.set_ylim([0, 50])
ax6.set_xticks(range(0, 21, 2))
ax6.set_yticks(range(0, 50, 5))
ax6.plot(t_list, v_list, label="truth velocity", color="blue", linewidth=1)
ax6.scatter(time_result, v_result, label="Lidar velocity", color="red", marker="o", s=2)
ax6.legend()
plt.show()结果图:















 4703
4703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









