






criterion = torch.nn.CrossEntropyLoss()torch.nn.CrossEntropyLoss(input, target)中的标签target使用的不是one-hot形式,而是类别的序号。形如 target = [1, 3, 2] 表示3个样本分别属于第1类、第3类、第2类。(单标签多分类问题) torch.nn.CrossEntropyLoss(input, target)的input是没有归一化的每个类的得分,而不是softmax之后的分布。 "input:预测值,(batch,dim),这里dim就是要分类的总类别数" "target:真实值,(batch),这里为啥是1维的?因为真实值并不是用one - hot形式表示,而是直接传类别id"。
#数据集包含1167张图片:皮卡丘:234,超梦:239,杰尼龟:223,小火龙:238,妙蛙种子:234
import torch
import os,glob
import random,csv
from torch.utils.data import Dataset ,DataLoader
from PIL import Image
from torchvision import transforms
from torch import nn
picture_resize = 32
batch_size = 32
#自定义数据加载类
class Pokemon(Dataset):
def __init__(self,root,resize,mode): #root:文件所在目录,resize:图像分辨率调整一致,mode:当前类何功能
super(Pokemon,self).__init__()
self.root = root
self.resize = resize
self.name2label = {} #对每个加载的文件进行编码:'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4
for name in sorted(os.listdir((os.path.join(root)))):#对指定root中的文件进行排序
if not os.path.isdir(os.path.join(root,name)):
continue
self.name2label[name] = len(self.name2label.keys())#keys返回列表当中的value,len计算列表长度
print(self.name2label)#根据文件顺序,以idx:文件名,vlaue:0,1,2,3,4,生成列表
#images labels
self.images,self.labels = self.load_csv('images.csv') #load_csv要么先创建images.csv,要么直接读取images.csv,
if mode=='train':#train dataset 60% of ALL DATA
self.images = self.images[:int(0.6*len(self.images))]
self.labels = self.labels[:int(0.6*len(self.labels))]
elif mode=='validation':#val dataset 60%-80% of ALL DATA
self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else :#test dataset 80%-100% of ALL DATA
self.images = self.images[int(0.8*len(self.images)):int(len(self.images))]
self.labels = self.labels[int(0.8*len(self.labels)):int(len(self.labels))]
# images[0]: D:\python pycharm learning\清华大佬课程\fisrt\pokemon\mewtwo\00000081.png
# #labels[0]:2
#images 还是图片的地址列表,需要__getitem__继续转换
# image,label 不能把所有图片全部加载到内存,可能会爆内存
def load_csv(self,filename):#生成,读取filename文件
#filename 不存在:生成filename
if not os.path.exists(os.path.join(self.root,filename)):
images = []
for name in self.name2label.keys():
# .../pokemen/mewtwo/00001.png 加载进images列表
# 实际上是加载每张图片的地址
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
print(len(images), images[0])
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images: # .....\bulbasaur\00000000.png
name = img.split(os.sep)[-2] # 指:bulbasaur 图片真实类别
label = self.name2label[name]#在name2label列表根据name找出对应的value:0,1...
# .....\bulbasaur\00000000.png , 0
writer.writerow([img, label])
print('writen into csv file:', filename)
#filename 存在:直接读取filename
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
# '...pokemon\bulbasaur\00000000.png', 0
img, label = row
label = int(label)
images.append(img)
labels.append(label)
assert len(images) == len(labels)
return images,labels
def __len__(self):
return len(self.images)
def denormalize(self,x_hat):#对已经进行规范化处理的totensor,去除规范化
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
#x_hat = (x-mean)/std
#x = x_hat*std +mean
#x:[c,h,w]
#mean:[3]=>[3,1,1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
x = x_hat * std + mean
return x
def __getitem__(self, idx):
pass
#idx~[0~len(images)]
# self.iamges,self.labels
#images[0]: D:\python pycharm learning\清华大佬课程\fisrt\pokemon\mewtwo\00000081.png
# #labels[0]:2
img, label = self.images[idx],self.labels[idx]
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'),#string image => image data
transforms.Resize((int(self.resize*1.25),int(self.resize*1.25))),#压缩到稍大
transforms.RandomRotation(20),#图片旋转,增加图片的复杂度,但是又不会使网络太复杂
transforms.CenterCrop(self.resize), #可能会有其他的底存在
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
#R mean:0.854,std:0.229
])
img = tf(img)
label = torch.tensor(label)
#Pokemon类根据一个索引每次返回一个img(三位张量),一个label(0维张量)
return img,label #img,label打包成元组返回
#定义模型
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.conv_uint = nn.Sequential(
#x:[b,3,32,32]>>[b,6,28,28] # x:[b,6,28,28]>>[b,6,14,14]
nn.Conv2d(3,6,5,1,0),
nn.AvgPool2d(2,2,0),
# x:[b,6,14,14]>>[b,16,10,10] # x:[b,16,10,10]>>[b,16,5,5]
nn.Conv2d(6, 16, 5, 1, 0),
nn.AvgPool2d(2, 2, 0),
)
self.fc_unit = nn.Sequential(
nn.Linear(400,120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 20),
nn.ReLU(),
nn.Linear(20, 5),
nn.ReLU(),
)
def forward(self,x):
"""
:param x:[b,3,32,32]
return:[b,3,32,32]=>[b,16,5,5]
"""
batch_size = x.size(0)
x = self.conv_uint(x)
x = x.view(batch_size,-1)
#[b,16*5*5]=>[b,5]
x = self.fc_unit(x)
return x
def train():
db = Pokemon('D:\python pycharm learning\清华大佬课程\\fisrt\pokemon',picture_resize,'train')
loader = DataLoader(db,batch_size=batch_size,shuffle=True)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cuda:0')
model = Model()
model = model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
time = 0
for x,y in loader:
x,y = x.to(device),y.to(device) #x.shape=[batch_size,3,picture_resize,picture_resize]=[32,3,32,32],#y.shape=[32]
optimizer.zero_grad()
y_pred = model(x) #y_pred.shape=[32,5]
cost = criterion(y_pred,y)
cost.backward()
optimizer.step()
time += 1
#print('time:',time,'cost[]:',cost)
print("cost[%d]:%f"%(time,cost))
if __name__=='__main__':
train()使用卷积神经网络+交叉熵损失函数+SGD优化器得到的效果很一般,所有图像跑一遍,每一个batch得到的交叉熵损失值大致在1.5左右,梯度跟新后,损失值也没太大变化,而且图像当中有个别几张没有被转化成RGB图像导致报错。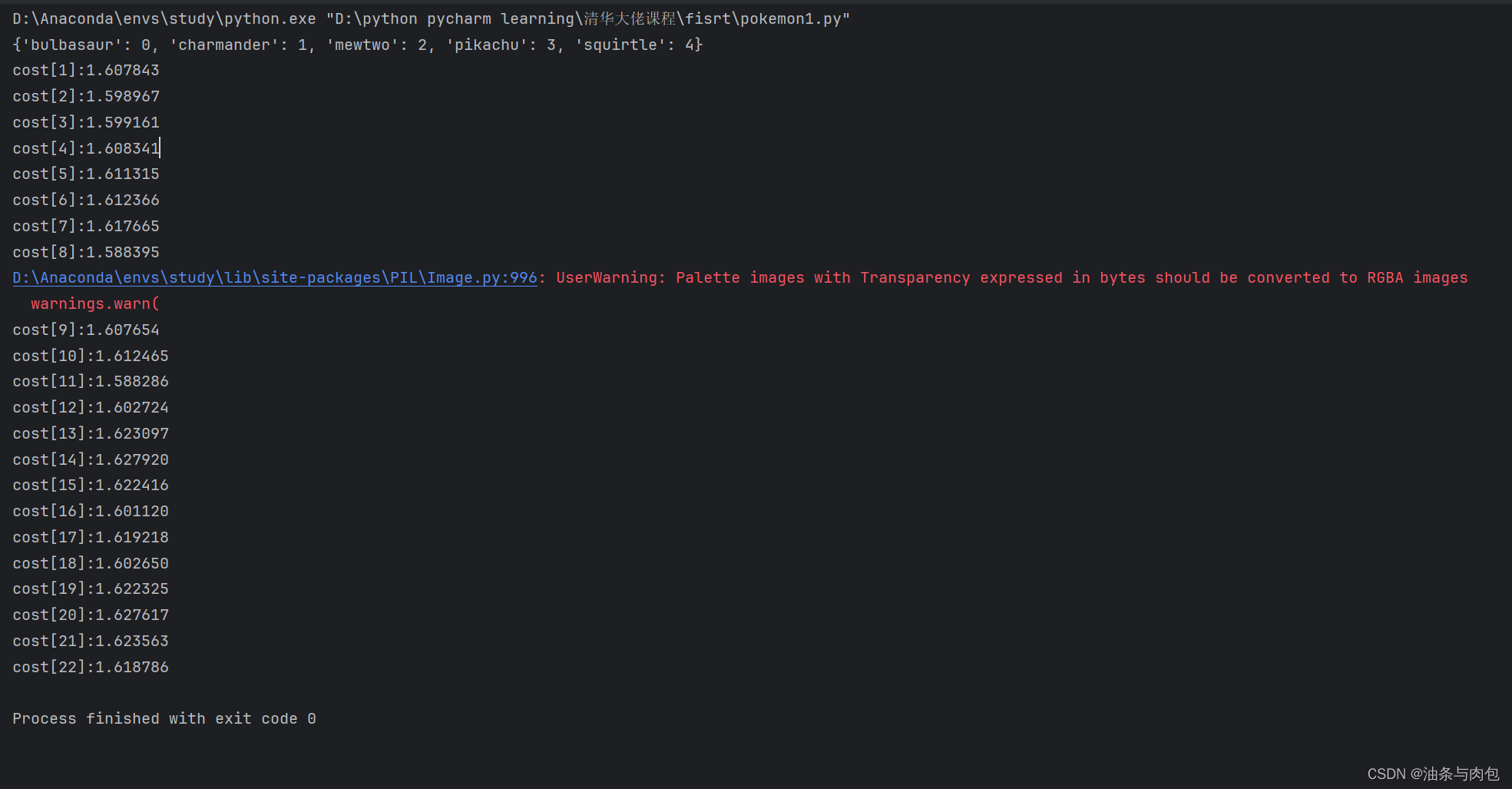
尝试换一个模型,更改图像的某些参数
#数据集包含1167张图片:皮卡丘:234,超梦:239,杰尼龟:223,小火龙:238,妙蛙种子:234
import torch
import os,glob
import random,csv
from torch.utils.data import Dataset ,DataLoader
from PIL import Image
from torchvision import transforms
from torch import nn
from resnet import ResNet18
picture_resize = 224
batch_size = 32
epochs = 10
#自定义数据加载类
class Pokemon(Dataset):
def __init__(self,root,resize,mode): #root:文件所在目录,resize:图像分辨率调整一致,mode:当前类何功能
super(Pokemon,self).__init__()
self.root = root
self.resize = resize
self.name2label = {} #对每个加载的文件进行编码:'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4
for name in sorted(os.listdir((os.path.join(root)))):#对指定root中的文件进行排序
if not os.path.isdir(os.path.join(root,name)):
continue
self.name2label[name] = len(self.name2label.keys())#keys返回列表当中的value,len计算列表长度
#print(self.name2label)#根据文件顺序,以idx:文件名,vlaue:0,1,2,3,4,生成列表
#images labels
self.images,self.labels = self.load_csv('images.csv') #load_csv要么先创建images.csv,要么直接读取images.csv,
if mode=='train':#train dataset 60% of ALL DATA
self.images = self.images[:int(0.6*len(self.images))]
self.labels = self.labels[:int(0.6*len(self.labels))]
elif mode=='validation':#val dataset 60%-80% of ALL DATA
self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else :#test dataset 80%-100% of ALL DATA
self.images = self.images[int(0.8*len(self.images)):int(len(self.images))]
self.labels = self.labels[int(0.8*len(self.labels)):int(len(self.labels))]
# images[0]: D:\python pycharm learning\清华大佬课程\fisrt\pokemon\mewtwo\00000081.png
# #labels[0]:2
#images 还是图片的地址列表,需要__getitem__继续转换
# image,label 不能把所有图片全部加载到内存,可能会爆内存
def load_csv(self,filename):#生成,读取filename文件
#filename 不存在:生成filename
if not os.path.exists(os.path.join(self.root,filename)):
images = []
for name in self.name2label.keys():
# .../pokemen/mewtwo/00001.png 加载进images列表
# 实际上是加载每张图片的地址
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
print(len(images), images[0])
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images: # .....\bulbasaur\00000000.png
name = img.split(os.sep)[-2] # 指:bulbasaur 图片真实类别
label = self.name2label[name]#在name2label列表根据name找出对应的value:0,1...
# .....\bulbasaur\00000000.png , 0
writer.writerow([img, label])
print('writen into csv file:', filename)
#filename 存在:直接读取filename
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
# '...pokemon\bulbasaur\00000000.png', 0
img, label = row
label = int(label)
images.append(img)
labels.append(label)
assert len(images) == len(labels)
return images,labels
def __len__(self):
return len(self.images)
def denormalize(self,x_hat):#对已经进行规范化处理的totensor,去除规范化
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
#x_hat = (x-mean)/std
#x = x_hat*std +mean
#x:[c,h,w]
#mean:[3]=>[3,1,1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
x = x_hat * std + mean
return x
def __getitem__(self, idx):
pass
#idx~[0~len(images)]
# self.iamges,self.labels
#images[0]: D:\python pycharm learning\清华大佬课程\fisrt\pokemon\mewtwo\00000081.png
# #labels[0]:2
img, label = self.images[idx],self.labels[idx]
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'),#string image => image data
transforms.Resize((int(self.resize*1.25),int(self.resize*1.25))),#压缩到稍大
transforms.RandomRotation(20),#图片旋转,增加图片的复杂度,但是又不会使网络太复杂
transforms.CenterCrop(self.resize), #可能会有其他的底存在
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
#R mean:0.854,std:0.229
])
img = tf(img)
label = torch.tensor(label)
#Pokemon类根据一个索引每次返回一个img(三位张量),一个label(0维张量)
return img,label #img,label打包成元组返回
#定义模型
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.conv_uint = nn.Sequential(
#x:[b,3,32,32]>>[b,6,28,28] # x:[b,6,28,28]>>[b,6,14,14]
nn.Conv2d(3,6,5,1,0),
nn.AvgPool2d(2,2,0),
# x:[b,6,14,14]>>[b,16,10,10] # x:[b,16,10,10]>>[b,16,5,5]
nn.Conv2d(6, 16, 5, 1, 0),
nn.AvgPool2d(2, 2, 0),
)
self.fc_unit = nn.Sequential(
nn.Linear(400,120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 20),
nn.ReLU(),
nn.Linear(20, 5),
nn.ReLU(),
)
def forward(self,x):
"""
:param x:[b,3,32,32]
return:[b,3,32,32]=>[b,16,5,5]
"""
batch_size = x.size(0)
x = self.conv_uint(x)
x = x.view(batch_size,-1)
#[b,16*5*5]=>[b,5]
x = self.fc_unit(x)
return x
def train(epoch):
db = Pokemon('D:\python pycharm learning\清华大佬课程\\fisrt\pokemon',picture_resize,'train')
train_loader = DataLoader(db,batch_size=batch_size,shuffle=True,num_workers=4)
device = torch.device('cuda:0')
model = ResNet18(5).to(device)
model = model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.5)
for step,loader in enumerate(train_loader):
x,y = loader
x,y = x.to(device),y.to(device) #x.shape=[batch_size,3,picture_resize,picture_resize]=[32,3,32,32],#y.shape=[32]
optimizer.zero_grad()
y_pred = model(x) #y_pred.shape=[32,5]
cost = criterion(y_pred,y)
cost.backward()
optimizer.step()
#print('time:',time,'cost[]:',cost)
if step %10 ==0:
print("epoch:%d cost[%d]:%f"%(epoch,step,cost))
if __name__=='__main__':
for epoch in range(epochs):
train(epoch)import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self, num_class):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(16)
)
# followed 4 blocks
# [b, 16, h, w] => [b, 32, h ,w]
self.blk1 = ResBlk(16, 32, stride=3)
# [b, 32, h, w] => [b, 64, h, w]
self.blk2 = ResBlk(32, 64, stride=3)
# # [b, 64, h, w] => [b, 128, h, w]
self.blk3 = ResBlk(64, 128, stride=2)
# # [b, 128, h, w] => [b, 256, h, w]
self.blk4 = ResBlk(128, 256, stride=2)
# [b, 256, 7, 7]
self.outlayer = nn.Linear(256*3*3, num_class)
def forward(self, x):
"""
:param x:
:return:
"""
x = F.relu(self.conv1(x))
# [b, 64, h, w] => [b, 1024, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print(x.shape)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128)
tmp = torch.randn(2, 64, 224, 224)
out = blk(tmp)
print('block:', out.shape)
model = ResNet18(5)
tmp = torch.randn(2, 3, 224, 224)
out = model(tmp)
print('resnet:', out.shape)
p = sum(map(lambda p:p.numel(), model.parameters()))
print('parameters size:', p)
if __name__ == '__main__':
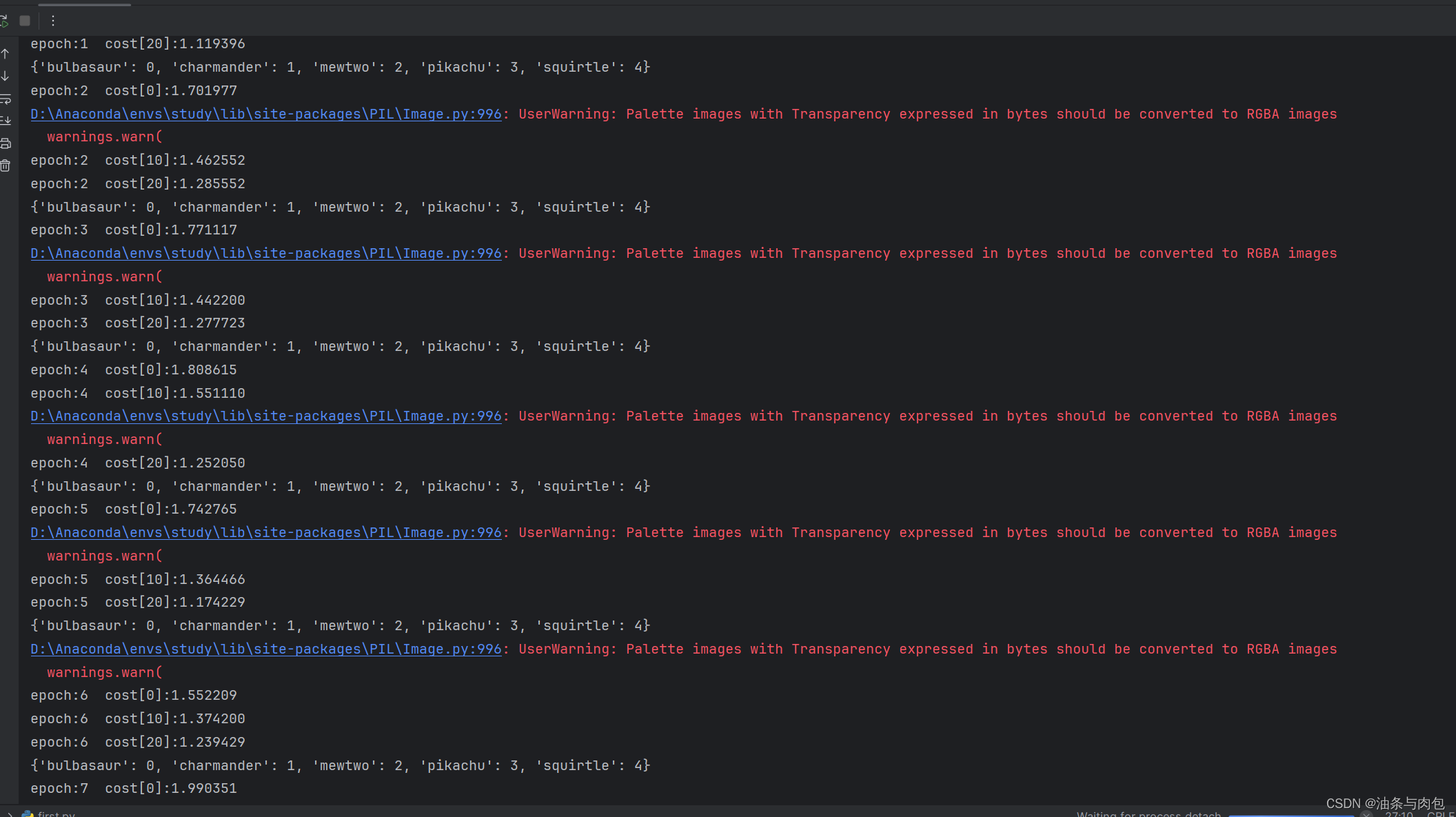
main()利用Resnet 网络模型,每个周期内loss损失会从1.7左右降低到1.2左右,但是还是高于1.0,并且上一个周期的参数用于下一个周期,损失值又会重新变高,模型的泛化能力比较差















 2068
2068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









