







 本文介绍了一种名为LaCoL的方法,通过结合弱增强和强增强的数据策略,利用噪声数据中的负相关性进行潜在对比学习。该方法在标签空间中采用高置信样本的分类损失,在度量空间中进行弱监督学习,并通过一致性正则化连接两个空间。实验证明LaCoL在处理带标签噪声的数据上效果显著,尤其在合成和实际数据集上的对比实验中表现出优势。
本文介绍了一种名为LaCoL的方法,通过结合弱增强和强增强的数据策略,利用噪声数据中的负相关性进行潜在对比学习。该方法在标签空间中采用高置信样本的分类损失,在度量空间中进行弱监督学习,并通过一致性正则化连接两个空间。实验证明LaCoL在处理带标签噪声的数据上效果显著,尤其在合成和实际数据集上的对比实验中表现出优势。
文献阅读:Noise Is Also Useful: Negative Correlation-Steered Latent Contrastive Learning
Abstract
论文提出了一种新的有效方法,称为潜在对比学习(LaCoL),以利用噪声数据中的负相关性。
在标签空间中,利用弱增强数据来过滤样本,并在所选样本集的强增强上采用分类损失。
在度量空间中,利用弱监督对比学习来挖掘隐藏在噪声数据中的负相关性。
此外,还提供了跨空间相似一致性正则化来约束标签空间和度量空间之间的间隙。
Introduction

负相关:
对于每个锚定样本,随机选择与锚定图像不属于同一类别的K个其他样本作为负样本,并使用这些负相关对构造负相关。
Methodology
overview

LaCoL通过两种不同的数据增强
(即弱增强𝐴_𝑤(·)和强增强𝐴_s(·))
联合学习编码器g(·)、分类头h(·)以及嵌入头f(·)。
给定噪声训练数据D={(𝑥_𝑖,𝑦_𝑖 )}_(i=1)^𝑁,其中𝑦_𝑖 ∈ {0,1}𝐶是C类上对应于xi的一个热标签向量,一个弱增广𝐴_𝑤(𝑥_𝑖);每个样本𝑥_𝑖执行两个强增广,如𝐴_𝑠(𝑥_𝑖)和𝐴_𝑠′(𝑥_𝑖) 。
标签空间中选定高置信度数据强增广的监督分类损失ℒ_𝐿𝑆;
度量空间中学习的成对负相关弱监督的潜在对比学习损失ℒ_𝑀𝑆;
跨空间相似性一致性损失ℒ_𝑆𝐶 。
Latent Contrastive Learning-Pairwise Negative Correlation
对于𝑥_𝑖,用K个样本随机构造一个负集:
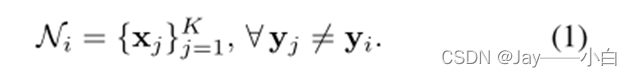
导出的负对构成了样本负相关。使得它对错误分配具有鲁棒性。
Latent Contrastive Learning- Weakly-supervised Contrastive Learning
LaCoL学习由度量空间中学习到的负相关性进行弱监督。引入锚样本的不同增强作为自监督正相似关系。
将弱增广输入𝐴_𝑤(𝑥_𝑖)和强增广𝐴_𝑠(𝑥_𝑖)投影到度量空间中,并推导出特征嵌入
𝑧 ̃_𝑖=𝑓∘ℎ(𝐴_𝑤 “(” 𝑥_𝑖 “)”)和𝑧 ̂_𝑖=𝑓∘ℎ(𝐴_𝑠 “(” 𝑥_𝑖 “)”) 。
在自监督正相似关系和弱监督负相似关系中,度量空间中的潜在对比学习损失定义为:
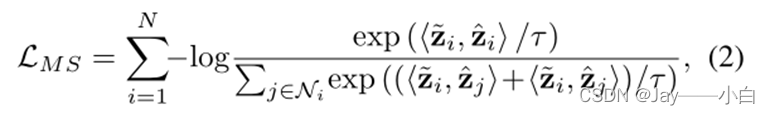
Divergence Preserving
进一步充分利用弱增强和强增强,并将这些增强策略扩展到训练分类头:
将预测与给定标签一致的样本视为高置信度样本。高置信度样本集可以如下导出:
𝑝 ̃_𝑖=h∘𝑔(𝐴_𝑤 “(” 𝑥_𝑖 “)”)
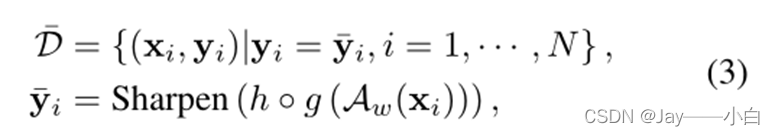
在获得高置信度数据集后,采用高置信度样本的强增强𝑆 ̅={𝐴_𝑠 “(” 𝑥_𝑖 “)” ├|├ (𝑥_𝑖,𝑦_𝑖 )∈𝐷 ̅ ┤┤}对于具有加权分类损失的标签空间中的训练:
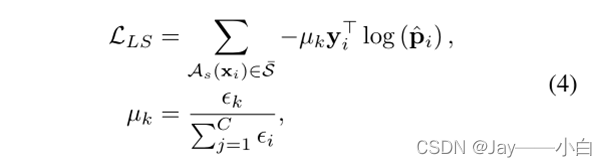
𝑝 ̂_𝑖=h∘𝑔(𝐴_𝑠 “(” 𝑥_𝑖 “)”)
Cross-Space Similarity Consistency
为了使潜在对比学习更好地指导分类任务,提出了一种跨空间相似度一致性正则化,因为它可以保证分类概率和特征嵌入相互指导。
为了保证这种跨空间相似性一致性,最小化了标签空间和度量空间中相似矩阵之间的交叉熵。
给定弱增广数据{𝐴_𝑤 “(” 𝑥_𝑖 “)” }(i=1)^𝑁及其输出概率{𝑝 ̃_𝑖 }(i=1)^𝑁 ,标签空间中的相似矩阵可以构造如下:
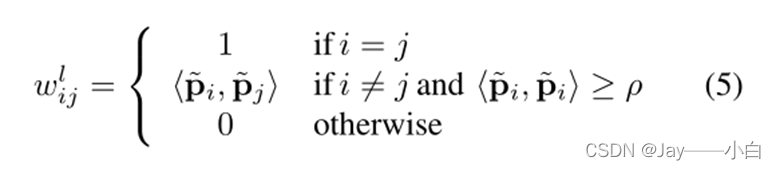
为了获得度量空间中的相似矩阵,在标签空间中进行了两个强增广{𝐴_𝑠 “(” 𝑥_𝑖 “)” }(i=1)𝑁和{𝐴_𝑠′ “(” 𝑥_𝑖 “)” }(i=1)^𝑁 。它们的特征嵌入可以表示为{𝑧 ̂_𝑖 }(i=1)^𝑁和{𝑧 ̂_𝑖^′ }(i=1)^𝑁 。然后,在标签空间中构建相似矩阵,如下所示:

基于两个相似矩阵,跨空间相似性一致性损失定义为:
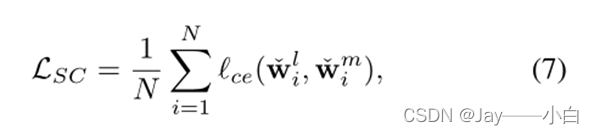
总体目标函数为:
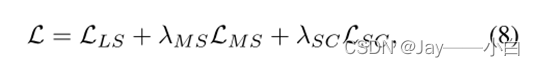


Experiments
Comparison on synthetic datasets


Comparison on real-world dataset

通过应用由成对负相关弱监督的潜在对比学习, LaCoL更有效地处理此类真实噪声问题。
Ablation Study
所有组件都提高了模型的性能,尤其是ℒ_𝑀𝑆对模型的性能最为关键。

中间图像和右侧图像中的学习表示比左侧图像更具区分性,这表明所提出方法的组件都可以提高带标签噪声的训练的性能。

不同数量的负样本的影响:
K的最佳值为15

















 854
854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









