






计算模型大小的方法
卷积 时间复杂度 与 空间复杂度 的计算方式:
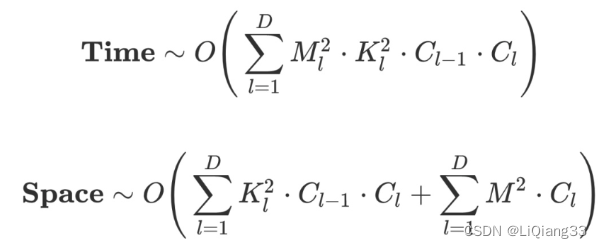
C 通道的个数,K卷积核大小,M特征图大小,C_l-1是输入通道的个数,C_l是输出通道的个数
1 模型大小 MB
计算模型的大小的原理就是计算保存模型所需要的存储空间的大小,一般以字节为单位,由于模型常常较大,通常使用 MB (million byte)为单位,在算法层面是就是空间复杂度。
NOTE: 有的地方算 参数量 or 模型大小 会x4,因为模型参数一般都是FP32存储的,FP32是单精度,占4个字节
计算方式:
# 计算了
total_params = sum(p.numel() for p in model.parameters())
total_params += sum(p.numel() for p in model.buffers())
print(f'{total_params:,} total parameters.')
print(f'{total_params/(1024*1024):.2f}M total parameters.')
total_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print(f'{total_trainable_params/(1024*1024):.2f}M training parameters.')
2 计算量 FLOPs
算法的时间复杂度,每秒浮点数运算的次数
- 计算量的要求是在于芯片的floaps(指的是gpu的运算能力)
- 参数量取决于显存大小
3 相关第三方库
3.1 torchstat
安装
pip install torchstat
用法
from torchstat import stat
model = CNN()
stat(model, (3, 224, 224))
版本报错解决:https://blog.csdn.net/u013963578/article/details/133672751
输出:
- params: 网络的参数量
- memory: 节点推理时候所需的内存
- Flops: 网络完成的浮点运算
- MAdd网络完成的乘加操作的数量。一次乘加=一次乘法+一次加法,所以可以粗略的认为Flops ≈2*MAdd
- MemRead: 网络运行时,从内存中读取的大小
- MemWrite: 网络运行时,写入到内存中的大小
- MemR+W: MemR+W = MemRead + MemWrite
torchstat存在的问题:
1.torchstat bug
版本问题输入为None
解决:修改源码 torchstat/reporter.py
df = df._append(total_df)
2.不能计算含有Transformer结构的模型大小
3.2 torchsummary
安装
pip install torchsummary
使用
model.to(torch.device("cuda:0"))
torchsummary.summary(model, input_size, batch_size=-1, device="cuda")
BUG修复
修改torchsummary.py源码
# 注销源码
# summary[m_key]["input_shape"] = list(input[0].size())
# summary[m_key]["input_shape"][0] = batch_size
# input 为 None的时候等于input
if len(input) != 0:
summary[m_key]["input_shape"] = list(input[0].size())
summary[m_key]["input_shape"][0] = batch_size
else:
summary[m_key]["input_shape"] = input
torchsummary支持对Transformer模型大小的计算
3.3 thop
安装:
pip install thop
使用:
from thop import profile
input_size = (1, 3, 512, 512)
a = torch.randn(input_size)
flops, params = profile(model=model, inputs=(a, )) # 注意 逗号
print(f"flops: {flops / 1e9} GFlops")
print(f"params: {params / 1e6} MB")
参考:
计算原理:https://blog.csdn.net/hxxjxw/article/details/119043464
计算Param 和 GFlops https://blog.csdn.net/qq_41573860/article/details/116767639
torchstat 输出参数解析 https://blog.csdn.net/m0_56192771/article/details/124672273
torchsummary bug 解决 tuple out of index https://blog.csdn.net/onermb/article/details/116149599
thop:https://blog.csdn.net/qq_21539375/article/details/113936308
参数大小与计算量:https://blog.csdn.net/qq_40507857/article/details/118764782
总结:https://blog.csdn.net/qq_41573860/article/details/116767639















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









