






Python网页爬虫实例1
1、爬取搜狗指定词条对应的搜索结果页面
功能描述:输入要想搜索的关键字,爬取对应的搜索结果页面
步骤1:确定url
因为我们想要爬取搜索关键词之后的页面,所以我们可以先搜索几个关键词,找出url的规律。


观察其URL中的参数,我们可以发现,不同关键词搜索页面的主要区别在于query参数,尝试只用带有query参数的url访问,可以发现结果相同,所以我们只需要query参数即可。

当然,我们也可以在网页源代码的network下的网页响应包中查看对应的参数。我们确定已经url和其所携带的参数,需要将参数封装在字典中。
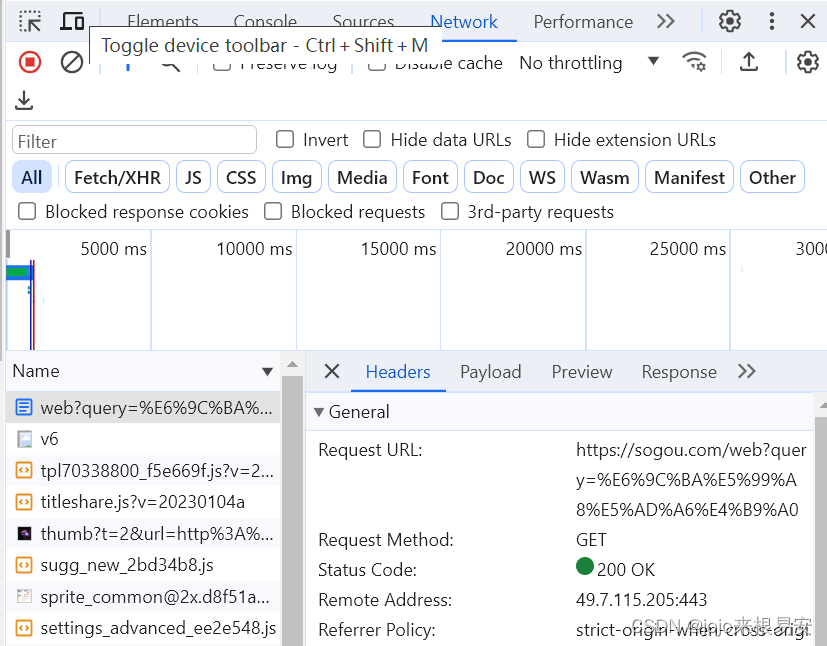
url = 'https://www.sogou.com/web'
param = {"query":keyword}
步骤2:发起请求,获取网页响应
requests发起网页请求有GET和POST两种方法。打开网页源代码,在network下打开网页响应包,在Header下即可查看到网页的请求方法request method为GET。
为了伪装成服务器对网页进行请求,还需要User-Agent,也是在Headers下查看,将其封装在字典中作为我们的请求头。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
接下来就可以使用GET方法对网页发起请求,获取网页响应response。
步骤3:获取响应的内容
response.text:响应体 str类型
response.encoding:二进制转换字符使用的编码
response.content:响应体类型 bytes类型
步骤4:存储数据
我们可以将爬取到的数据存储起来,方便后续使用。由于程序中获取的是html类型数据,因此也将其存储成.html格式。使用with open打开文件,其自带文件的close功能。
程序代码如下:
# 导入模块
import requests
# 指定url
url = 'https://www.sogou.com/web'
# 处理url携带的参数:封装到字典中
keyword = input("请输入搜索关键字:")
# url携带的参数
param = {"query":keyword}
# 请求头,用来伪装成某款浏览器
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
# 发起请求,获取响应
response = requests.get(url=url,params=param,headers=headers)
print(response.status_code) # 检查状态码
print(response.encoding) #查看编码格式
# 获取响应数据
page_text = response.text
# print(response.text)
# 持久化存储数据
file_name = keyword + '.html'
with open(file_name,'w',encoding='utf-8') as f: # with open自带close文件的功能
f.write(page_text)
print(file_name,"保存成功")
2、爬取百度翻译结果
功能:输入一个英文单词或句子,爬取对应的翻译界面
AJAX(Asynchronous Javascript And XML,异步JavaScript和XML),使用Ajax技术网页应用能够快速地将增量更新呈现在上,而不需要重载(刷新)整个页面,这使得程序能够更快地回应用户的操作。其核心是XMLHttpRequest对象(XHR)。XHR为向服务器发送请求和解析服务器响应提供了接口。能够以异步方式从服务器获取新数据。
输入单词之前:
输入单词之后:
输入单词后,只是在当前页面上进行了局部刷新,这就表示在文本框中输入一个单词之后,它就会自动发起AJAX请求,AJAX请求成功之后,会对页面的内容进行局部刷新。我们可以打开抓包工具,捕获输入字符之后发起的AJAX请求,AJAX请求中的数据就是在页面中刷新出来的对应单词的翻译结果。右击页面选择检查——选择NetWork——将选项定位到XHR(XMLHttpRequest对象)——在文本框中输入要翻译的单词——查看XHR下抓取到的每一个请求数据包,找去包含我们需要的数据的包。
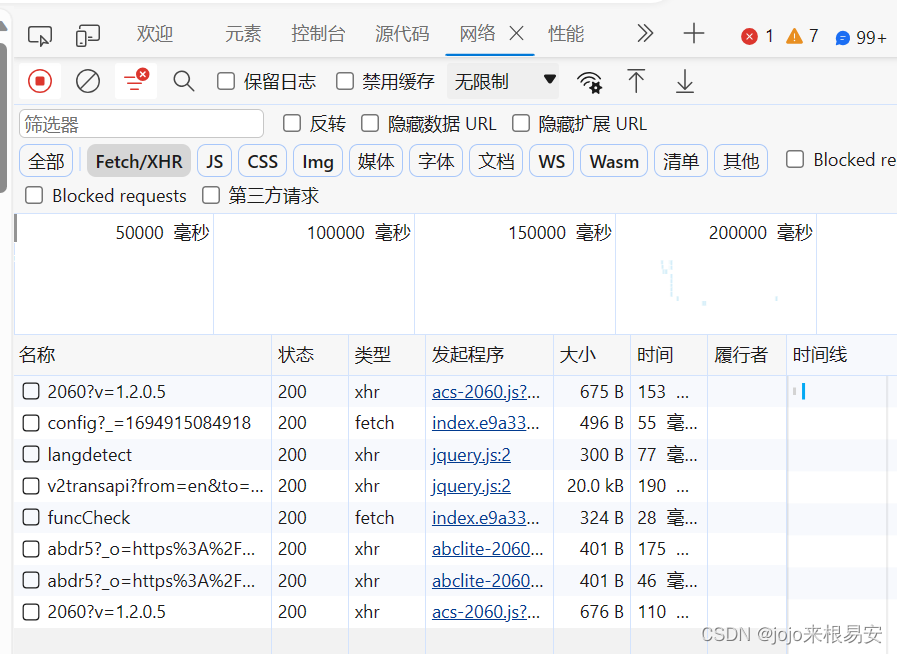
可以发现,发起的是一个POST请求,因为该请求携带了表单数据——输入的文本。在该数据包的响应标头中看到响应的数据类型content-type是application/json,即翻译页面返回的翻译结果是一个json类型的数据,这个json类型的数据可以在预览中看到。所以我们获取响应数据时,可以通过response.json()获取json类型数据。
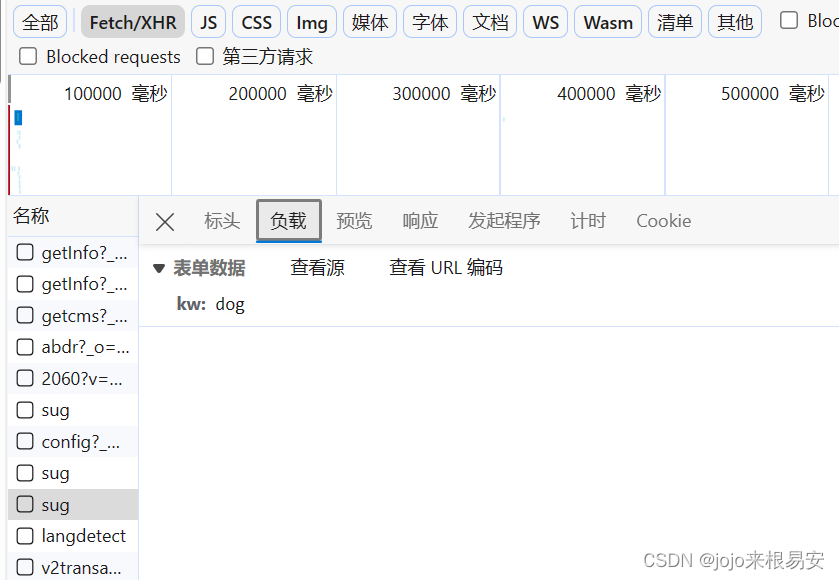
步骤1:确定url
在找到的响应数据包中即可找到请求url
步骤2:发起请求,获取响应
发起的请求是POST请求,需要携带表单数据,将表单数据封装到字典中作为POST请求的data参数。
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81'}
# POST请求携带的表单数据
data = {
'kw':keyword
}
res = requests.post(post_url,headers=headers,data=data)
步骤3: 获取响应数据
我们已知网页响应的数据是json类型数据,则可以通过res.json()获取网页中的json数据串。注意:只有当确定网页响应的数据是json类型时,才可以使用.json()方法。我们通过json方法获取到的是一个object,这个对象的类型是python中的字典类型或者是python中嵌套了字典的列表类型。
data = res.json()
步骤4:持久化存储数据
可以将数据存储为json类型,通过json中的dump或dumps方法可以将上一步中获取的数据转化为json类型数据。
data_json = json.dumps(data,ensure_ascii=False) # dumps方法是将python类型的数据转化为json类型的数据,中文不能使用ascii编码
或者
fp = open(f'./BAfanyi_{keyword}','w',encoding='utf-8')
json.dump(data,fp=fp,ensure_ascii=False) # fp参数表示数据要存入的文件
全部代码如下:
# 导入模块
import requests
import json
# 确定url
keyword = input("请输入一个英文单词或一个英文句子:")
post_url = 'https://fanyi.baidu.com/sug' # 响应数据包中的请求url
# 请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81'}
# POST请求携带的表单数据
data = {
'kw':keyword
}
# 发起请求,获取响应
res = requests.post(post_url,headers=headers,data=data)
data = res.json() # json方法返回的是object,通过json()方法获取字典类型的数据
# 进行持久化存储——将获取的字典类型数据存储为json类型数据
data_json = json.dumps(data,ensure_ascii=False) # dumps方法是将python类型的数据转化为json类型的数据,中文不能使用ascii编码
with open(f'./BDfanyi_{keyword}.json','w',encoding='utf-8') as f:
f.write(data_json)
print("-----------爬取数据结束!------------")
3、爬取豆瓣电影分类排行榜中的电影详情数据
https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
在豆瓣电影中随意选择一个分类,这里选的是剧情片。在该页面拖动滚动条会发现页面会自动加载没有显示出来的电影,即在原页面进行一个局部刷新,我们可以查看其AJAX请求是否携带数据包。
在抓包工具的XHR项可以发现,随着我们不断下滑页面,加载出新的信息,抓到的数据包就会增加。
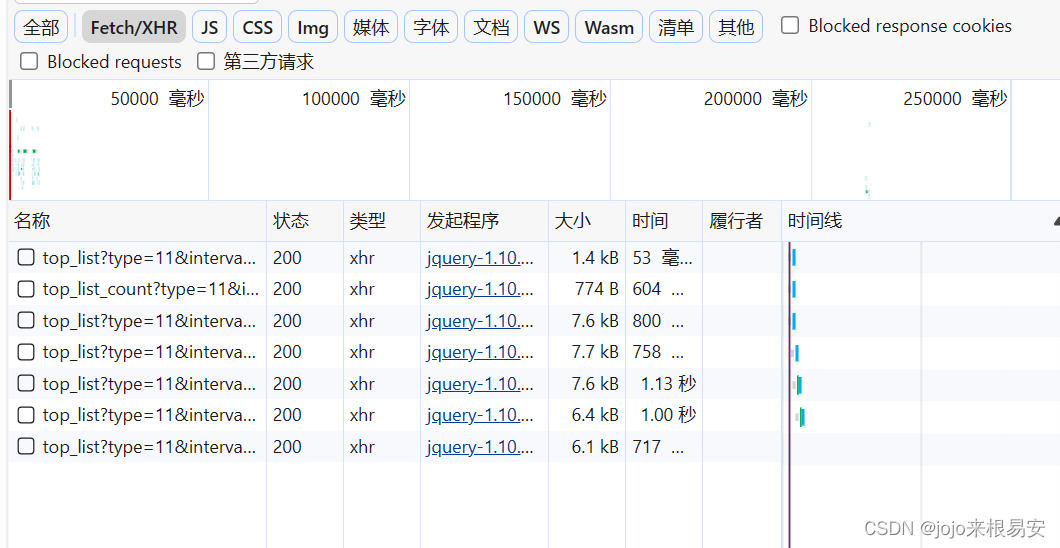
接下来查看数据包的内容。可以发现,XHR下所有数据包的请求方法都是GET方法,其请求URL变化如下:
https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=1
https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20
https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=20&limit=20
https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=40&limit=20
https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=60&limit=20
这些包的url携带参数,并且有些参数是变化的,我们可以查看包的表单数据。
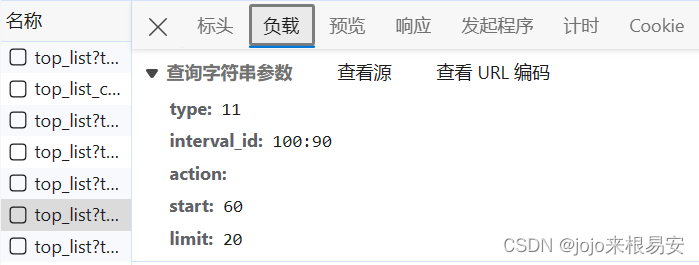
其中start参数表示加载电影的起点,limit表示一次加载限制20部电影,我们可以将url中问号后面的这些参数也就是查询字符串参数,封装到字典中作为get请求的param参数。通过上面不同包的url可以看出,start参数是可以修改的。然后我们可以修改limit参数看是否能请求到页面,如果不可以,就一次只能抓取20条数据,然后通过循环抓取该页面所有的电影数据;如果可以,我们就先获取该页面一共有多少部电影的数据,然后将limit改为总的电影数量,就可以一次性获取这个页面所有的电影数据。
其实在剧情片页面中可以看出该页面共有895部电影,但是当我们需要爬取不同类型,如剧情、爱情、动作等等这些所有的电影时,需要使用循环,就没办法一次次查看一个页面总共有多少部电影数据了。这时我们可以先抓取该页面总电影数量total,再抓取该页面电影的数据。
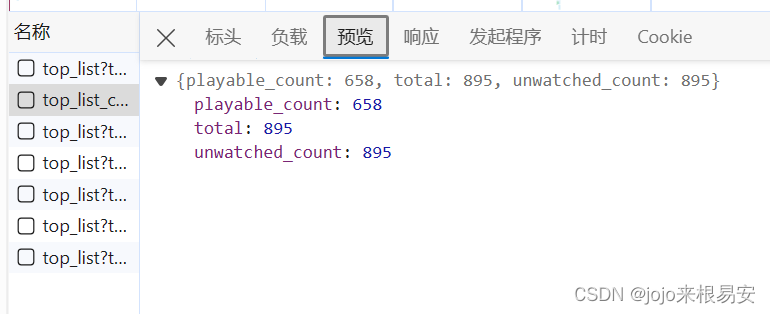
步骤1:指定url
从抓取到的XHR下的响应数据包中可以查看电影数据页面的请求url,我们把url中携带的参数封装到字典中作为GET请求的params参数。
url = 'https://movie.douban.com/j/chart/top_list'
params = {
'type':11,
'interval_id':'100:90',
'action':'',
'start':0, # 从第几部电影开始取
'limit':20, # 限制一次请求显示多少部电影
}
步骤2:发起请求,获取网页响应
在响应数据包的Headers下可以看到请求网页的方法时GET方法,我们需要进行UA伪装,并将GET请求方法的参数传入,对网页发起请求。
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81'}
# 发起请求
response = requests.get(url=url,headers=headers,params=params)
步骤3:获取响应数据
因为在响应包中得知响应数据的类型content-type是application/json,即json类型的数据,因此我们可以用json()方法获取到响应数据对象(object),object的类型是python中嵌套了字典的列表类型。
data = response.json() # 通过json方法获取数据对象,该对象类型是python中的嵌套字典的列表类型
print(type(data)) # 查看数据类型,结果是Python中的嵌套了字典的列表类型
步骤4:持久化存储数据
将获取到的嵌套字典的列表类型数据转化为json类型并存储成.json格式。
f = open('./douban_1.json','w',encoding='utf-8')
json.dump(data,fp=f,ensure_ascii=False)
f.close()
下面是该爬虫案例的全部代码:
'''
爬取豆瓣电影分类排行榜中的电影详细信息
'''
import requests
import json
# 获取该页面一共有多少部电影
url1 = 'https://movie.douban.com/j/chart/top_list_count?type=11&interval_id=100%3A90'
# UA伪装
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81'}
res = requests.get(url1,headers=headers)
data1 = res.json()
print(data1)
total = data1["total"] # 获取该页面电影数量
print(total)
# 确定url
url = 'https://movie.douban.com/j/chart/top_list'
params = {
'type':11,
'interval_id':'100:90',
'action':'',
'start':0, # 从第几部电影开始取
'limit':total, # 限制一次请求显示多少部电影
}
# 发起请求,获取响应数据
response = requests.get(url=url,headers=headers,params=params)
# 获取响应数据
# 在抓取到的响应包中已经知道响应数据的类型content-type是application/json,即json类型数据
data = response.json() # 通过json方法获取数据对象,该对象类型是python中的嵌套字典的列表类型
print(type(data)) # 查看数据类型,结果是Python中的嵌套了字典的列表类型
print(data)
print(len(data)) # 查看一共获取了多少部电影的数据
# 持久化存储数据
f = open('./douban_1.json','w',encoding='utf-8')
json.dump(data,fp=f,ensure_ascii=False)
f.close()
print("-----------爬虫结束了!!!--------------------------")
4、爬取肯德基餐厅中指定地点的餐厅数据
功能描述:输入一个城市,爬取该城市全部肯德基餐厅的数据。
肯德基官网的地址是:http://www.kfc.com.cn/kfccda/index.aspx
在官网首页底部点击餐厅查询,然后在搜索框中输入一个城市,比如:北京。查询前后,可以发现,网页的url并没有发生变化,说明只是在当前页面进行了局部刷新。我们需要打开抓包工具查看查询前后是否发生AJAX请求,如果是,就找到包含我们所需数据的响应数据包。
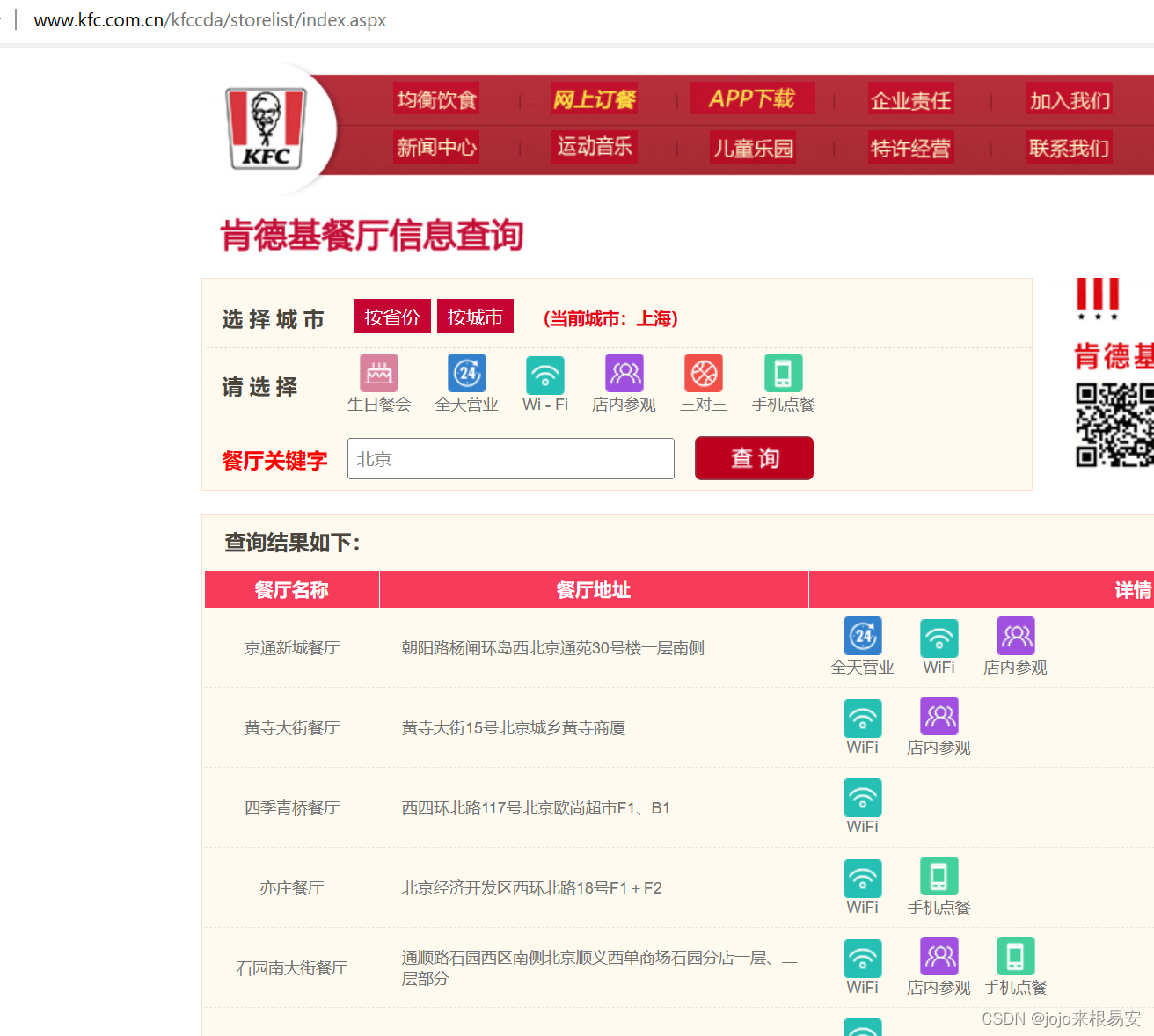
在输入查询的地点之后,XRH下出现一个响应数据包。在原页面中翻页,又会抓到新的包。抓取到的所有的包的请求url都相同,请求方法都为POST方法,响应数据的类型content-type是application/json类型。观察表单数据可以发现,keyword代表我们输入的查询地点,改变keyword的值,可以定位到不同城市。pageIndex表示当前在第几页,不同包的pageIndex不同,说明可以修改pageIndex来达到翻页。pageSize表示一页共显示多少个餐厅的数据。
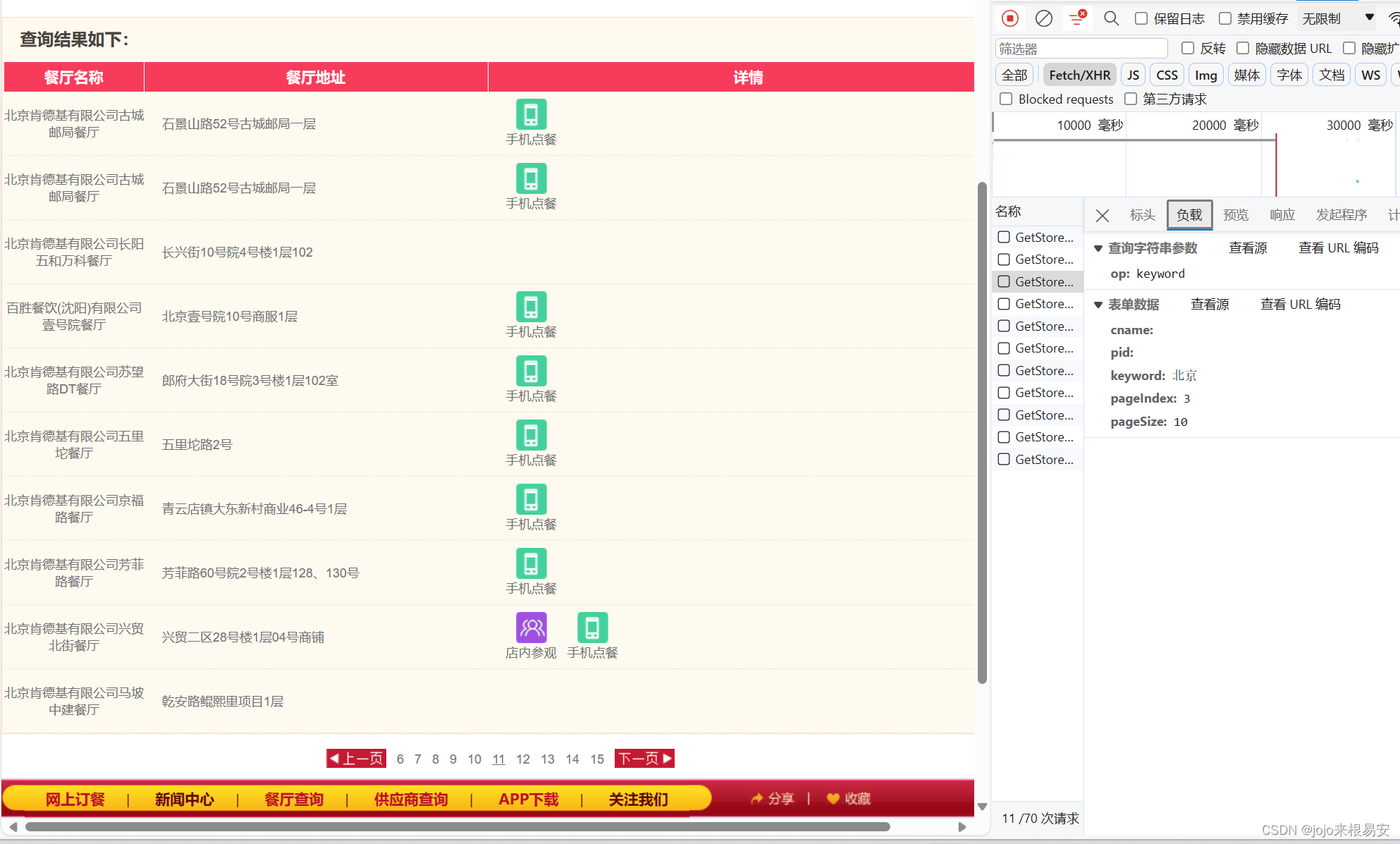
在包的预览项中可以发现我们想要获取的数据,其类型是json数据类型。改json数据串中包含两项,Table和Table1,Table中表示的信息是指定地点的餐厅总数,Table1是当前页中的餐厅信息。
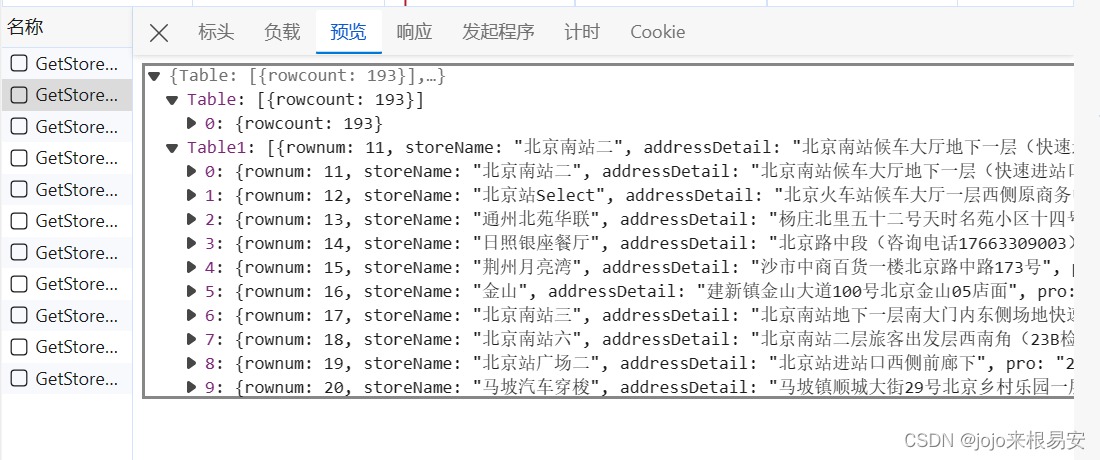
因此就是通过POST方法请求网页,并获取网页中json类型的数据。
步骤1:指定ur
在响应包的Headers下可以获取到请求url。
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
步骤2:发起网页请求,获取响应
准备好url、请求头和POST请求需要的表单数据。
# 表单数据
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': 1,
'pageSize': 20,
}
# UA伪装
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81'}
# 发起网页请求,获取数据
info = requests.post(url,headers=headers,data=data)
步骤3:获取响应数据
在获取到json类型的响应数据之后,查看它的类型发现时字典类型。查看字典的长度发现长度为2,说明其中只有两对键值对。打印字典数据,可以发现第一个键值对中的value是总行数,即指定地点的所有餐厅数。第二个键值对即当前页面的餐厅的信息。
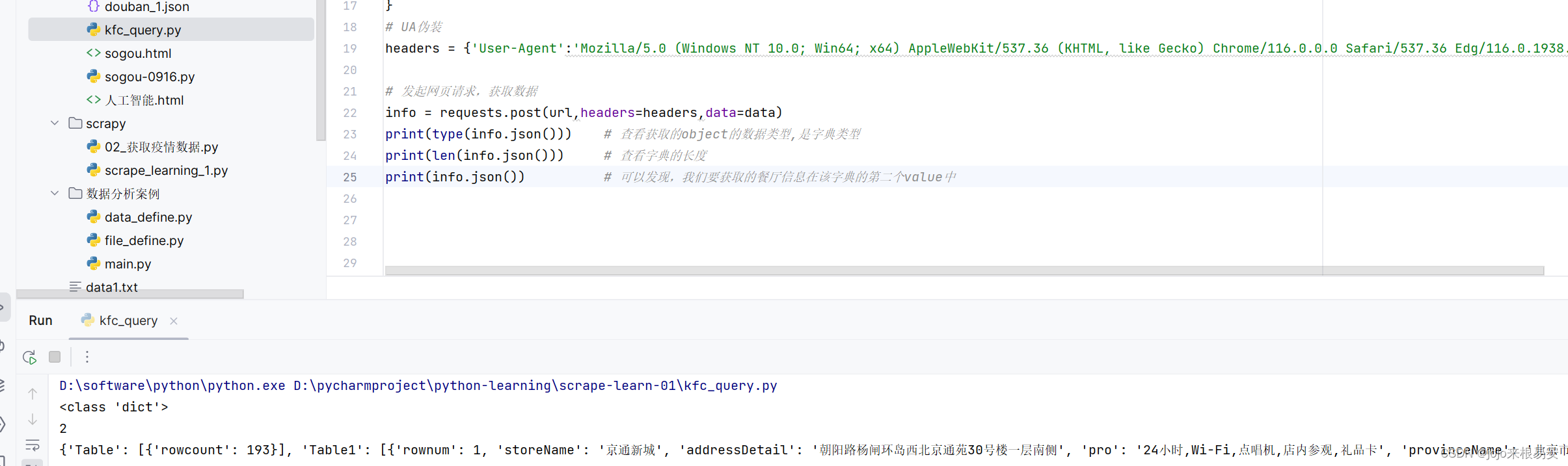
当前页面是第一页,有10个餐厅。通过字典的取值方式获取到第二对键值对中的value,其中就是第一页所有餐厅的数据。输出结果表示,我们从第一页获取到10家餐厅的信息。
我们可以尝试修改pageSize即每一页显示的餐厅数量,看是否可以一次获取更多的数据。将表单数据中的pageSize修改为20,确实可以一次性获取20个餐厅的信息。因此我们可以将pageSize修改为总餐厅数193,一次性获取全部的餐厅信息。当然,我们也可以通过循环,修改pageIndex实现翻页,一次获取10个餐厅的信息。但是,它并没有告诉我们总页数,只告诉我们总行数,为了更方便获取数据,程序中将会先获取总行数,再一次性爬取所有餐厅的数据。
步骤4:持久化存储数据
将获取到的字典类型数据转化为json类型并存储成.json文件。
该爬虫程序的全部代码如下:
'''
爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数
'''
# 导入模块
import requests
import json
# 指定url
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
# UA伪装
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81'}
kw = input("请输入要查询的城市:") # 指定地点
# 表单数据
data = {
'cname': '',
'pid': '',
'keyword': kw,
'pageIndex': 1,
'pageSize': 20,
}
# 获取指定地点的餐厅总数
response = requests.post(url,headers=headers,data=data)
# json对应的字典类型数据中,第一个键值对的键是Table,对应的value是一个只有一个元素的列表,而且这个元素的类型是字典类型。
# response.json()['Table'][0]表示取列表的第一个元素,得到一个字典
# 得到的字典中只有一个键值对,键是rowcount,表示总行数,对应的value就是所有餐厅数
total_row = response.json()['Table'][0]['rowcount']
# print(total_row)
# 将获取的餐厅总数量传入到参数data中
data['pageSize'] = total_row
# print(data)
# 发起网页请求,获取响应
res = requests.post(url,headers=headers,data=data)
print(type(res.json())) # 查看获取的object的数据类型,是字典类型
print(len(res.json())) # 查看字典的长度
print(res.json()) # 可以发现,我们要获取的餐厅信息在该字典的第二个value中
# info.json()该字典中一共有两个键值对,第一个value表示总行数,第二个value是每一个餐厅的信息
list_data = res.json()['Table1'] # 获取嵌套了字典的列表类型的数据
print(type(list_data)) # 查看获取的object的数据类型,是列表类型
print(len(list_data)) # 查看共获取了多少个餐厅的数据
print(list_data) # 查看获取到的餐厅数据
# 持久化存储数据
data_json = json.dumps(list_data,ensure_ascii=False) # 数据中有中文,不能用ascii码
with open(f'./KFC_{kw}.json','w',encoding='utf-8') as f:
f.write(data_json)
print("------------爬虫结束!!------------------")
需要注意的是,有些城市的餐厅数量小于10家,所以它的pageIndex只能是1,即只有一页数据,所以我们在指定页数的时候要注意不要超出范围,否则就获取不到数据。
PS:如果要在一个程序中爬取多个城市的全部肯德基餐厅的数据,可以将城市名封装在一个列表中,通过循环列表,将每一个城市名依次赋值给data参数中的keyword,就可以指定不同地点,不用每次都输入城市名。
示例2-4都不是直接通过对url请求得到响应,而是通过AJAX动态请求获取到响应。

















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









