






Numpy数据分析03——Numpy统计
Numpy能方便地求出统计学常见的描述性统计量。
一、平均值和中位数
1.1 求平均值mean()
m1 = np.arange(20).reshape((4,5))
print(m1)
# 默认求出所有元素的平均值
m1.mean()
运行结果:

若想求某一维度的平均值,设置axis参数,多维数组的元素指定
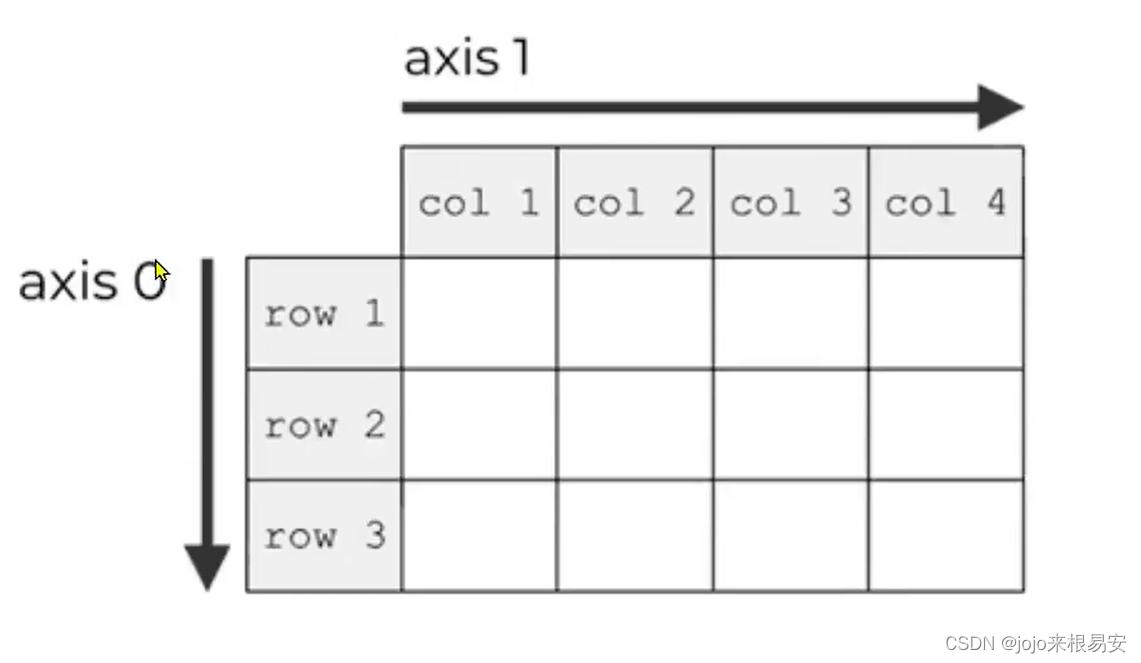
- axis = 0,将从上往下计算
- axis = 1,将从左往右计算

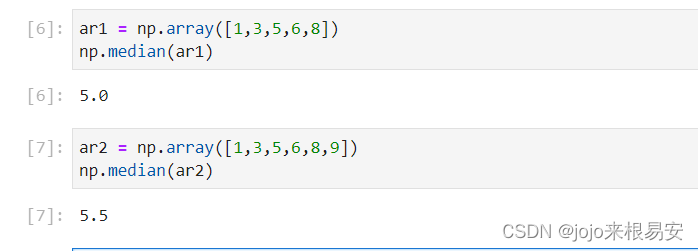
1.2 中位数np.median()
又称为中位数,中值。
是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值。
- 平均数:是一个“虚拟”的数,是通过计算得到的,它不是数据中的原始数据。中位数:是一个不完全“虚拟”的数。
- 平均数:反映了一组数据的平均大小,常用来代表数据的总体“平均水平”。中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的“中等水平”。
二、标准差和方差
2.1 求标准差ndarray.std
在概率统计中最常使用作为统计分布程度上的测量,是反映一组数据离散程度最常用的一种量化形式,是表示
- 标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。
简单来说,标准差是一组数据平均值分散程度的一种度量。
- 一个较大的标准差,代表大部分数值与其平均值之间差异较大
- 一个较小的标准差,代表这些数值较接近平均值
'''
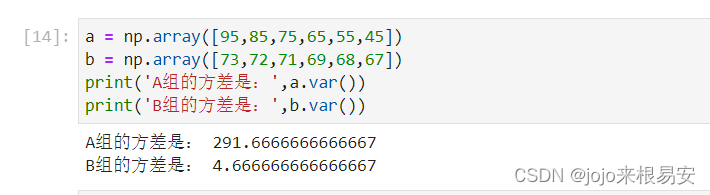
例如,A、B两组各有6位学生参加同一次语文测验,
A组的分数为95、85、75、65、55、45
B组的分数为73、72、71、69、68、67
分析哪一组学生的差距大?
'''
a = np.array([95,85,75,65,55,45])
b = np.array([73,72,71,69,68,67])
# A组学生成绩的标准差
print(np.std(a))
# B组学生成绩的标准差
print(np.std(b))
运行结果:

标准差应用于投资上,可作为度量回报稳定性的指标。标准差数值越大,代表回报远离过去平均值越不稳定,故风险更高。相反,标准差数值越小,代表回报较为稳定,风险亦较小。
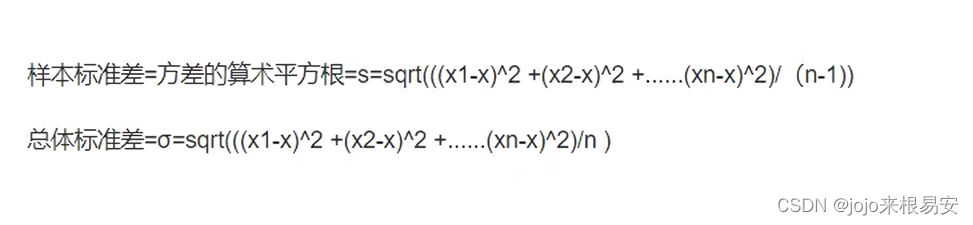
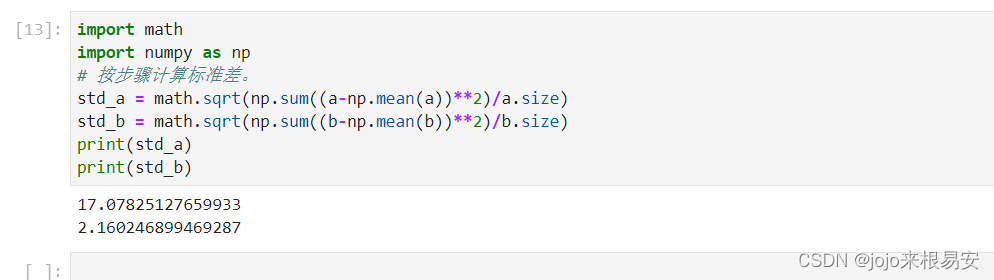
按步骤计算标准差:
2.2 方差ndarray.var()
衡量随机变量或一组数据时离散程度的度量。
标准差有计量单位,而方差无计量单位,但两者的作用一样,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。
三、最大和最小
3.1 求最大值ndarray.max()
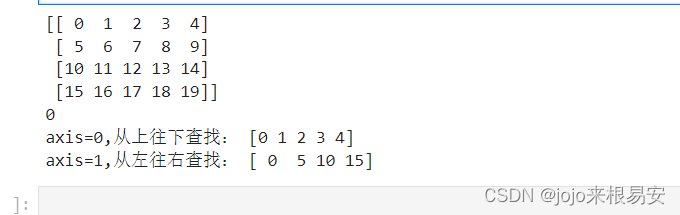
import numpy as np
m1 = np.arange(20).reshape((4,5))
print(m1)
# 求m1的最大值
print(m1.max())
print('axis=0,从上往下查找:',m1.max(axis=0))
print('axis=1,从左往右查找:',m1.max(axis=1))
运行结果:

3.2 求最小值ndarray.min()
import numpy as np
m1 = np.arange(20).reshape((4,5))
print(m1)
# 求m1的最大值
print(m1.min())
print('axis=0,从上往下查找:',m1.min(axis=0))
print('axis=1,从左往右查找:',m1.min(axis=1))
运行结果:
四、加权平均数
加权平均值numpy.average()
即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数
numpy.average(a,axis=None,weights=None,returned=False)
- weights:数组,可选
与a中的值关联的权重数组。a中的每个值都根据其关联的权重对平均值做出贡献。权重数组可以是一维的(在这种情况下,它的长度必须沿给定轴的a的大小)或与a具有相同的形状。如果weights=None,则假定a中的所有数据的权重等于1.一维计算是:
avg=sum(a*weights)/sum(weights)
对权重的唯一限制是sum(weights)不能为0。

实例:
使用"实例-已知"中的数据,对比两位学生的成绩:

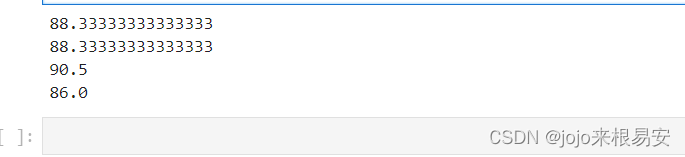
xiaoming = np.array([80,90,95])
xiaogang = np.array([95,90,80])
# 权重:
weights = [0.2,0.3,0.5]
# 分别计算小明和小刚的平均值
print(np.mean(xiaoming))
print(np.mean(xiaogang))
# 分别计算小明和小刚的加权平均值
print(np.average(xiaoming,weights=weights))
print(np.average(xiaogang,weights=weights))
运行结果:
五、股票实例
股票价格的波动是股票市场风险的表现,因此股票市场风险分析就是对股票市场价格波动进行分析。波动代表了未来价格取值的不确定性,这种不确定性一般用“方差”或者“标准差”来刻画。
下表是中国和美国部分时段的股票统计指标,其中中国证券市场的数据由“钱龙”软件下载,美国证券市场的数据取自ECI的“WorldStockExchangeDataDisk”。表2股票统计指标
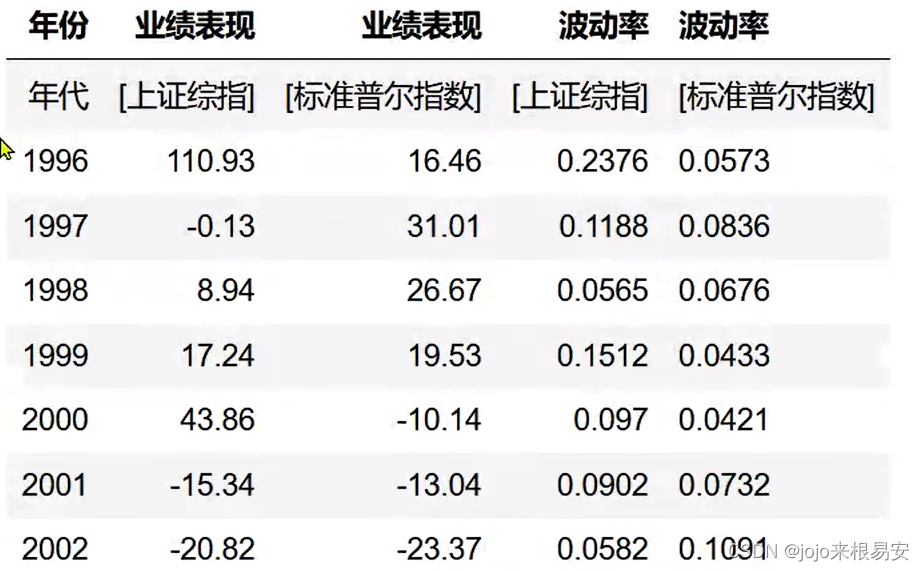
变异系数(Coefficient of Variation):当需要比较两组数据离散程度大小的时候,如果两组数据的测量尺度相差太大,或者数据量纲的不同,直接使用标准差来进行比较不合适,此时就应当消除测量尺度和量纲的影响,而变异系数可以做到这一点,它是原始数据标准差与原始数据平均数的比。
# 股票信息
stock_info = np.array([
[110.93,16.46,0.2376,0.0573],
[-0.13,31.01,0.1188,0.0836],
[8.94,26.67,0.0565,0.0676],
[17.24,19.53,0.1512,0.0433],
[43.86,-10.14,0.097,0.0421],
[-15.34,-13.04,0.0902,0.0732],
[-20.82,-23.37,0.0582,0.1091]
])
# 先计算7年的期望值(平均值)
# 分别计算每支股票业绩表现和波动率的平均值,即从上往下计算平均值
stock_mean = np.mean(stock_info,axis=0)
print('每一列的平均值:',stock_mean)
# 计算7年的标准差
stock_std = np.std(stock_info,axis=0)
print('每一列的标准差:',stock_std)
# 因为标准差是绝对值,不能通过标准差对中美直接进行对比,而变异系数可以直接比较
# 变异系数 = 原始数据标准差 / 原始数据平均数
stock_std / stock_mean
运行结果:

通过变异系数可知,第一支股票的业绩表现的变异系数较小,因此它的业绩表现较第二支股票稳定;第二支股票的波动率的变异系数较小,因此波动率较为稳定。















 5769
5769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









