







04 深度学习预训练与MMPretrain
记录时间:2023年6月6日
MMPretrain算法库
基于MMEngine(基础深度学习训练框架)、MMCV(计算机视觉基础库)
是一个预训练的开源算法框架,旨在提供各种预训练主干网络,并支持不同预训练策略,同时支持多模态功能。
推理API

openmmlab的配置文件
需要配置的信息如下图所示

代码框架

数据流过程
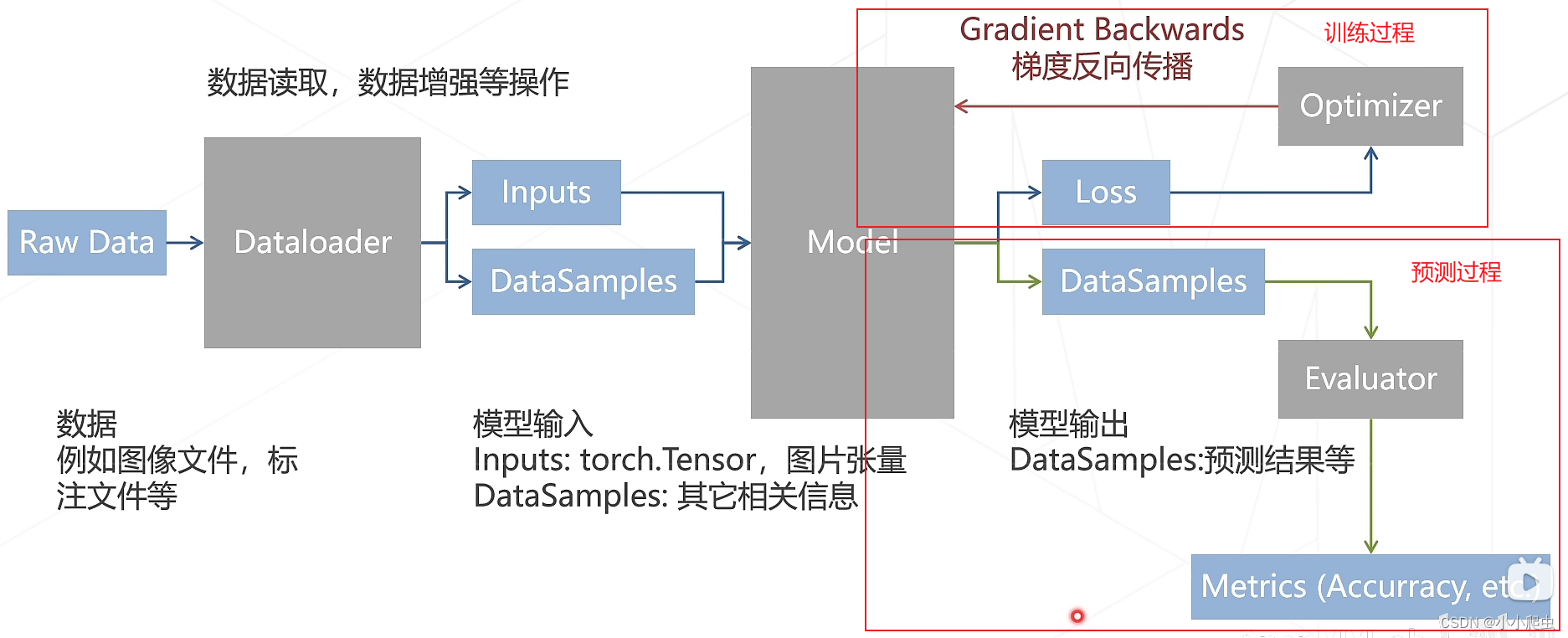
配置文件运行方式
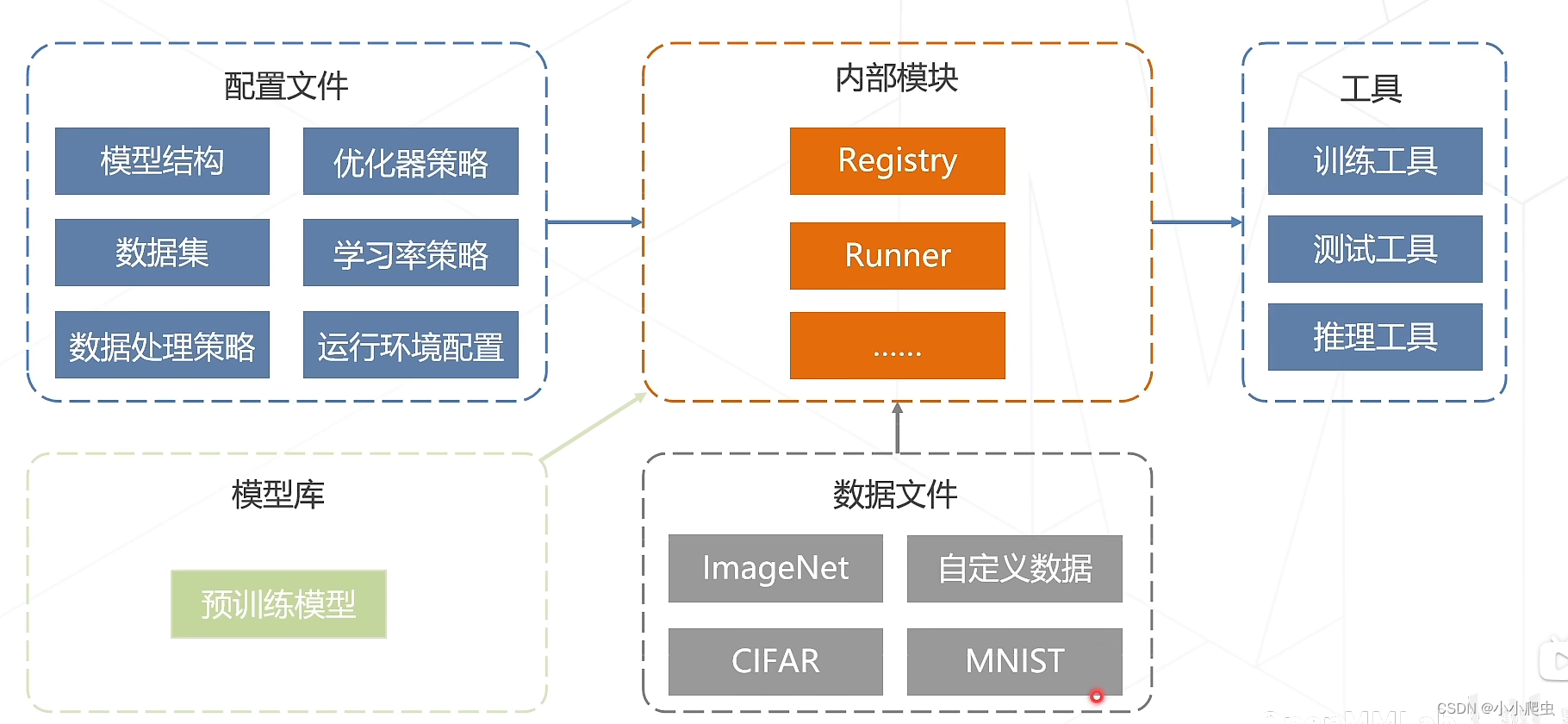
通过以上的学习,可以参考该算法库的整体框架,为以后自己的开发工作作相应的准备
经典主干网络
ResNet
论文:Deep residual learning for image recognition(CVPR2016)
第一阶段:堆叠网络层数
- AlexNet(2012)——8层
- VGG(2014)——16、19层
- GoogLeNet(2014)——22层
然而,人们发现模型层数增加到一定数目后,分类正确率不增反降
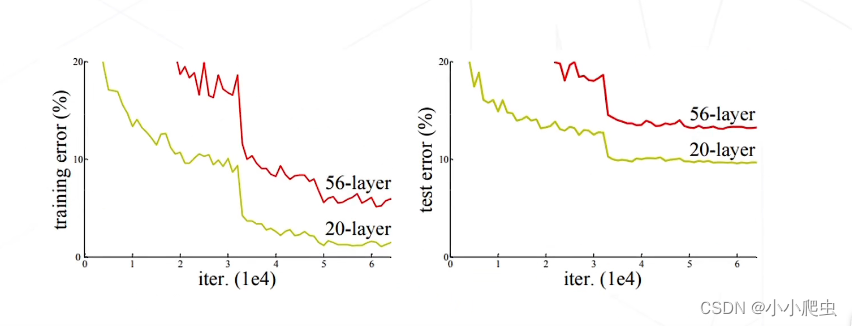
猜想:虽然深层网络有潜力达到更高的精度,但常规的优化算法难以找到这个更优的模型,即,让新增加的卷积层拟合一个近似恒等映射,恰好可以让浅层网络变好一点。(具体细节建议看原视频)原视频
第二阶段:残差学习
发展思路:
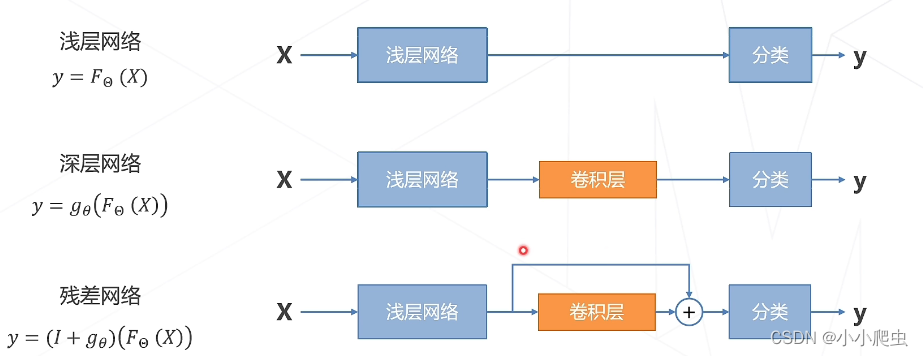
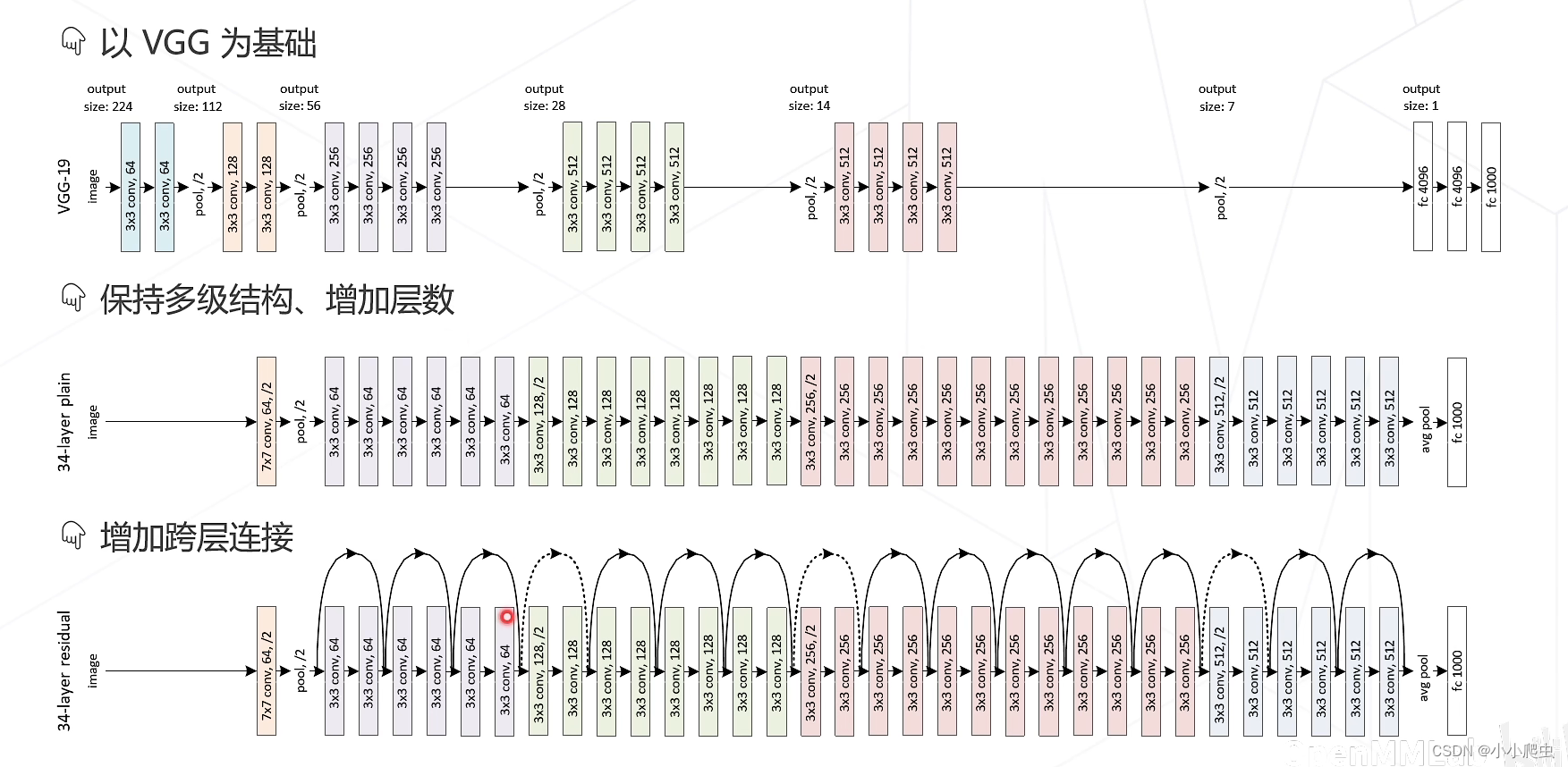
由上述思路,引出了ResNet
但引出了问题:为什么这样处理就可以使得效果更好?(暂时不理解)
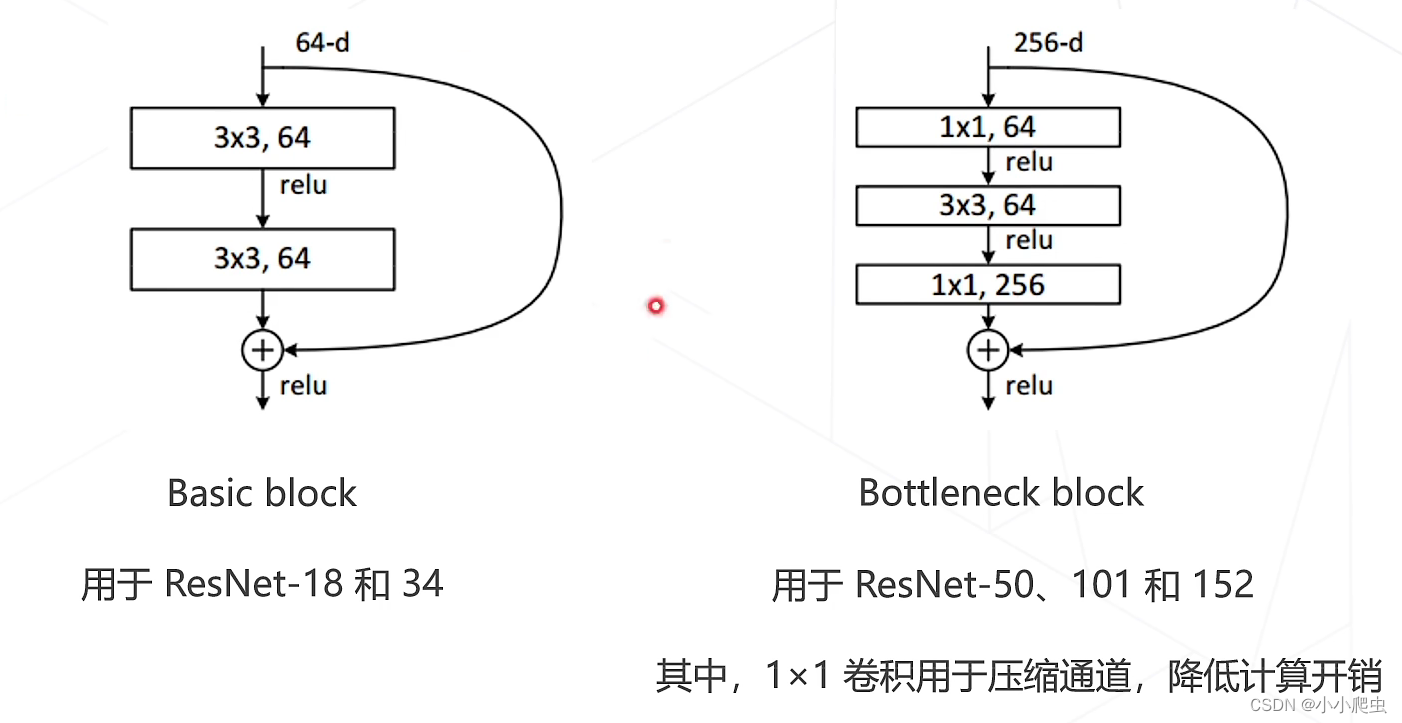
ResNet的两种残差模块:
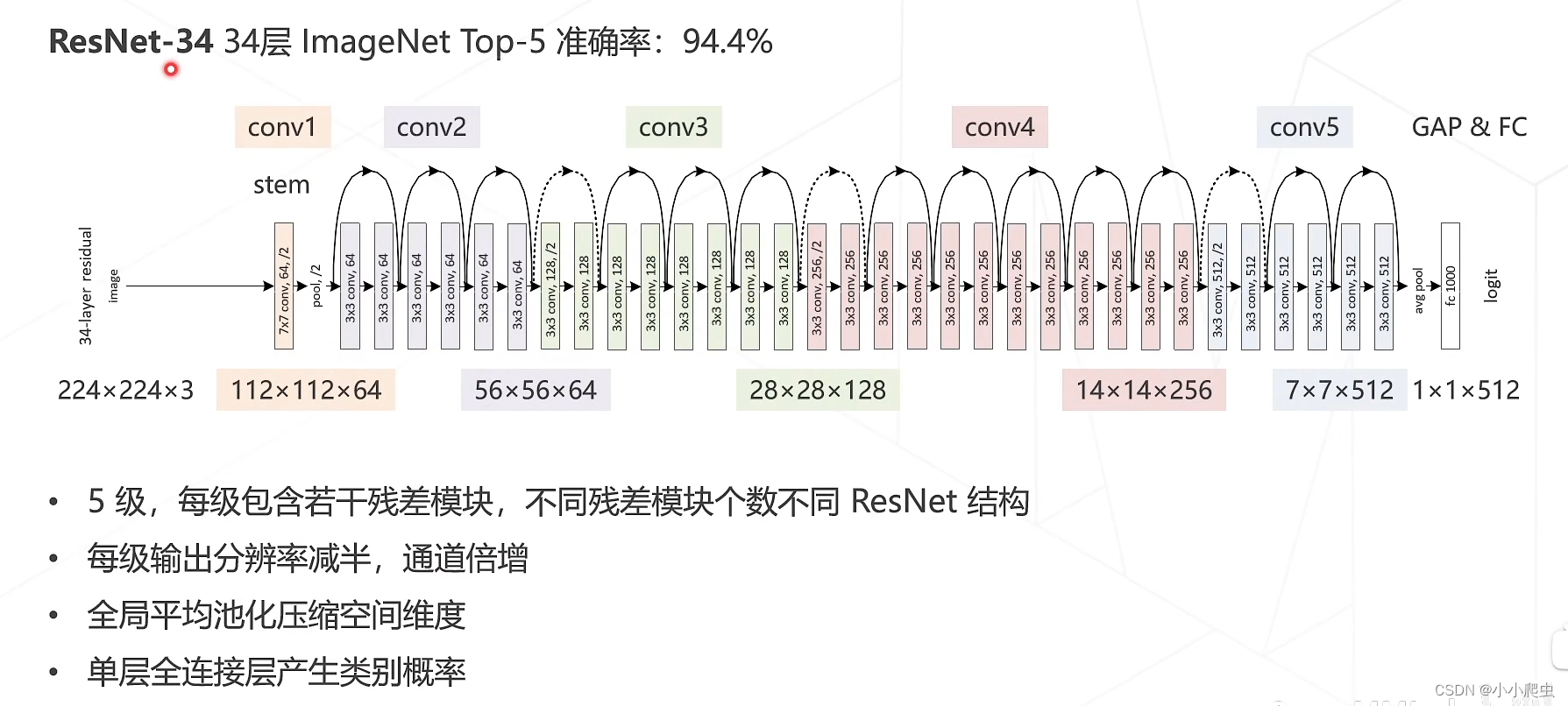
ResNet网络整体结构
Vision Transformer
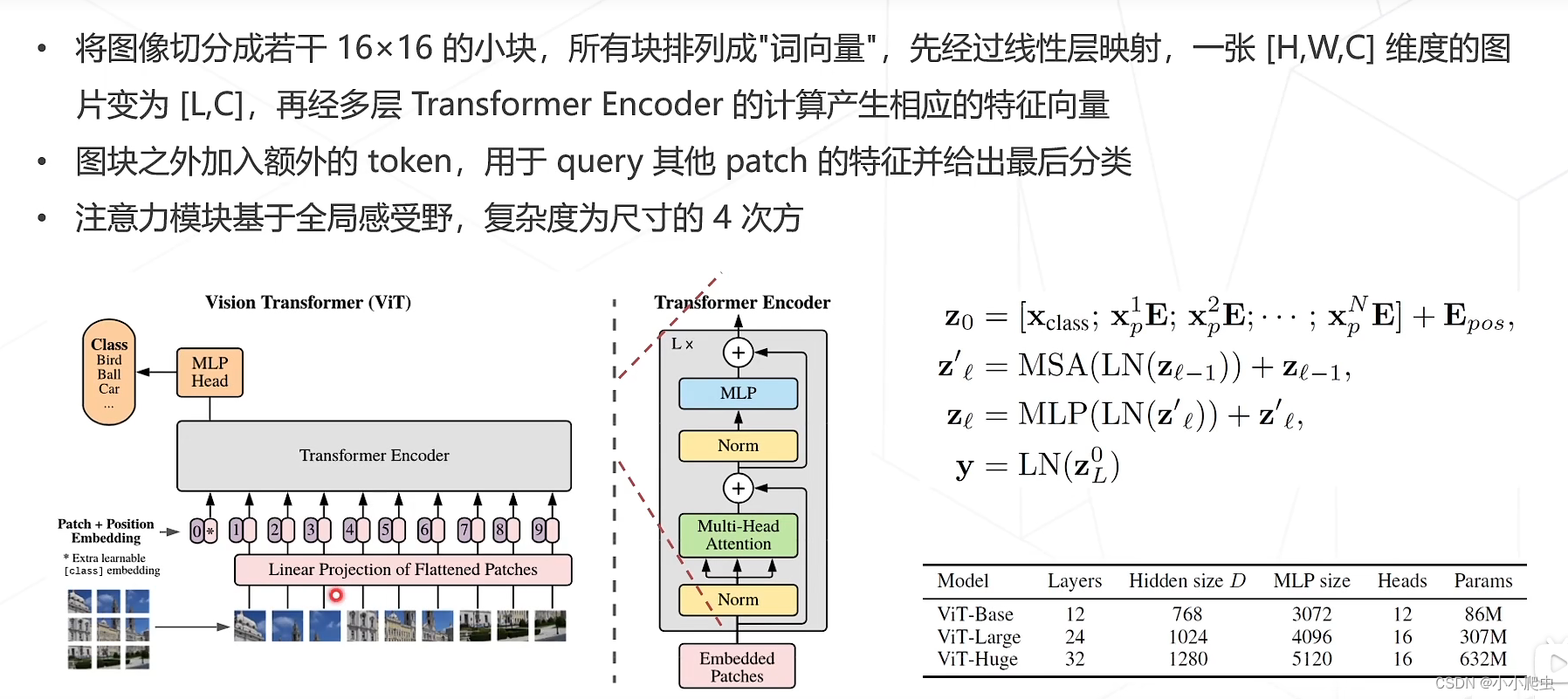
论文:An image is worth 16✖16 words: Transformers for image recognition at scale
整体结构
注意力机制使用举例
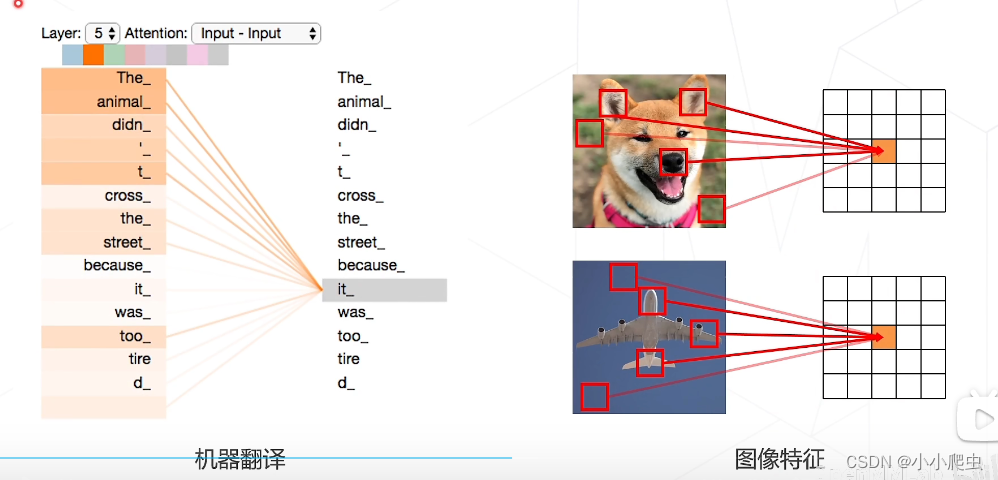
注意力机制
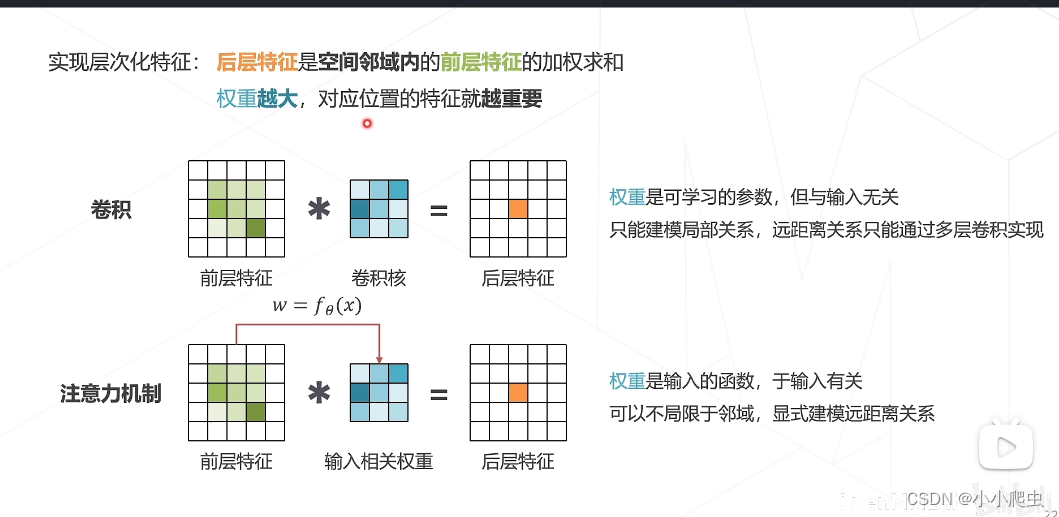
注意到在卷积当中,权重只与前层特征的局部关系相关;而在注意力机制中,权重将前层特征作为一个输入,可以更好的、显示的(相比卷积)建模远距离关系。(个人理解,不知对否)
一维数据的注意力机制的计算的逻辑图
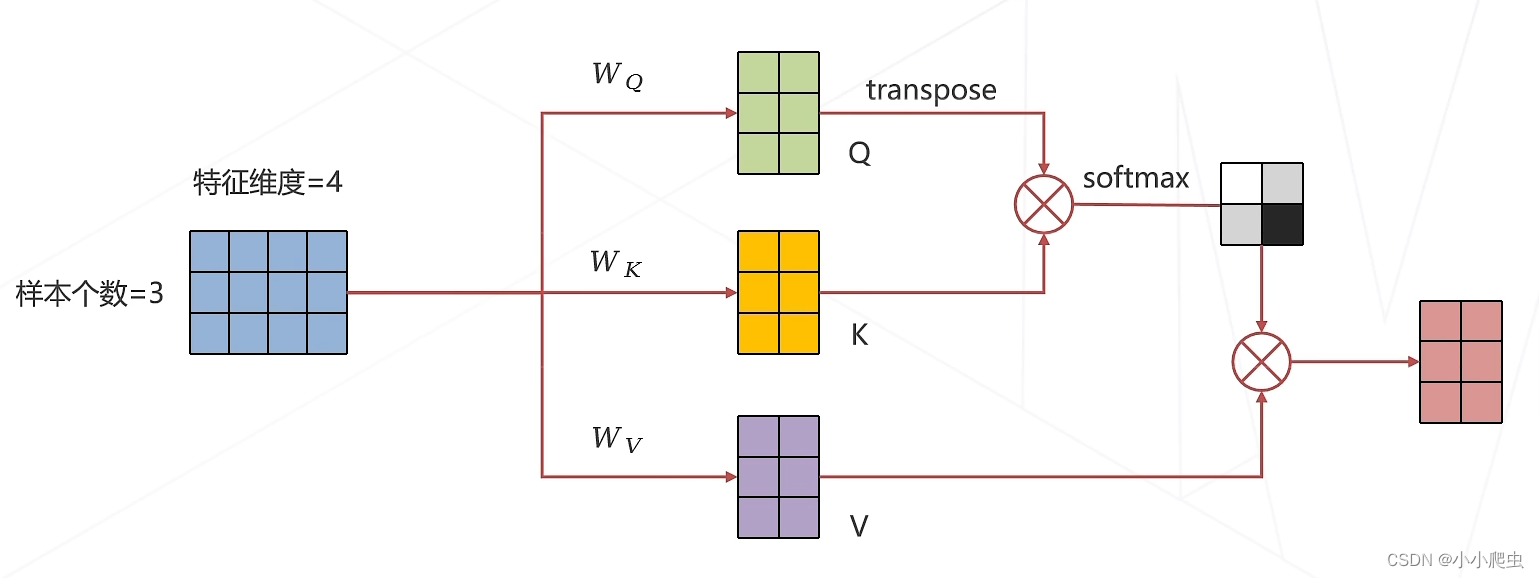
在该逻辑图中,我没听明白注意力机制的运行过程,此处需要更进一步的了解注意力机制的细节与计算逻辑。由于通过自身输入产生Q、K、V向量,被称为self-attention。
问题1:注意力机制的细节(Q、K、V的计算过程)
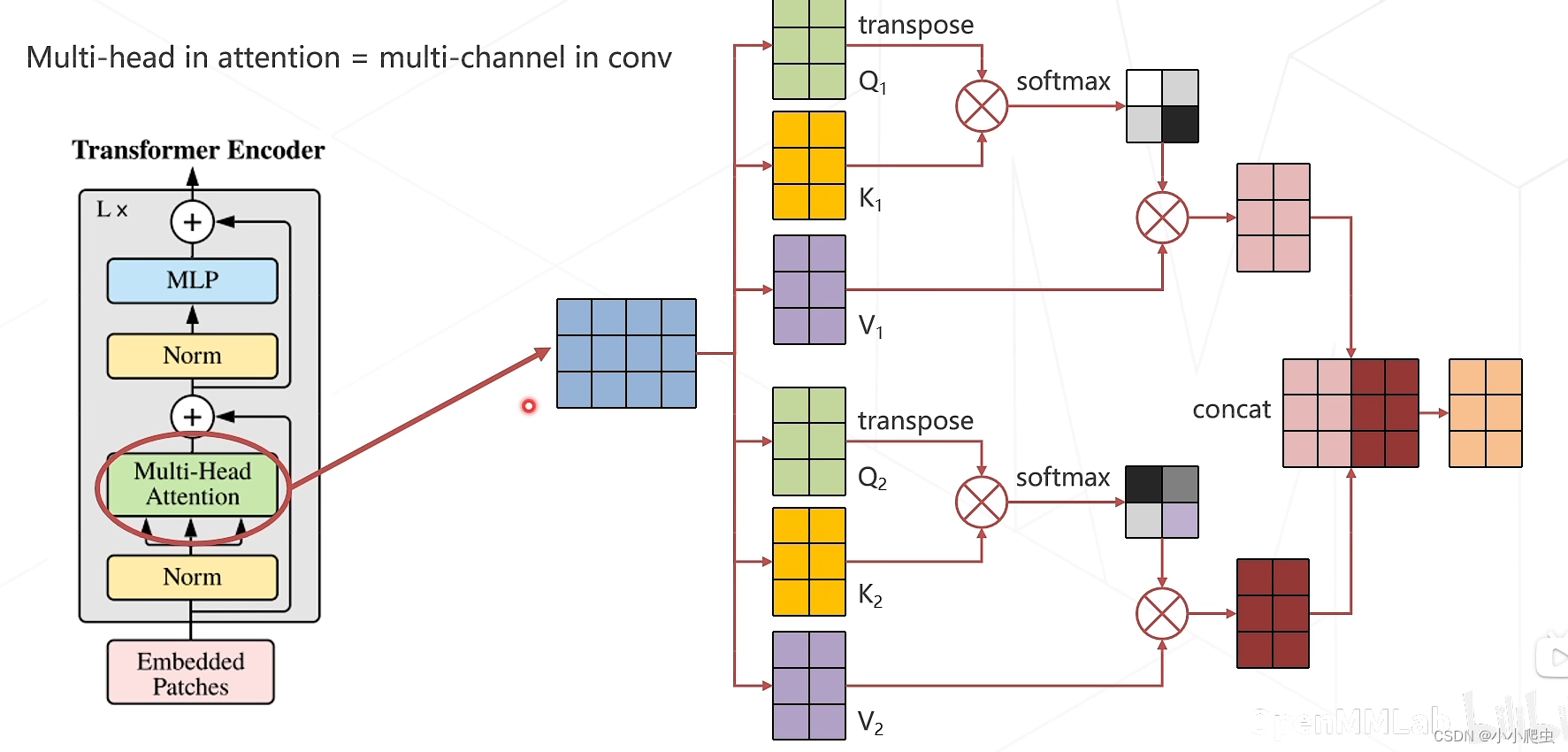
Multi-head Attention(多头注意力机制)
multi-head in attention = multi-channel in conv
优点:在计算过程中,不同头的注意力可以对不同的特征进行提取,从而提升网络性能
自监督学习
互联网上有海量的数据,但是有标注的数据却少之又少,为了利用这些海量数据而不依赖人工标注,让深度神经网络能够从数据本身去学到对应的特征表达,因此发展了自监督学习。
分类
基于各种代理任务
-
图像上色

-
图像排序(拼图)

基于对比学习
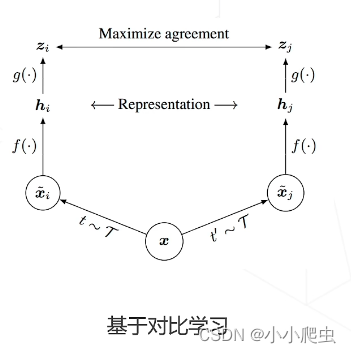
SunCLR
论文:A simple framework for contrastive learning of visual representations(ICML 2020)
基本假设:如果模型能很好地提取图片内容的本质,那么无论图片经过什么样的数据增强操作,提取出来的特征都应该极为相似。
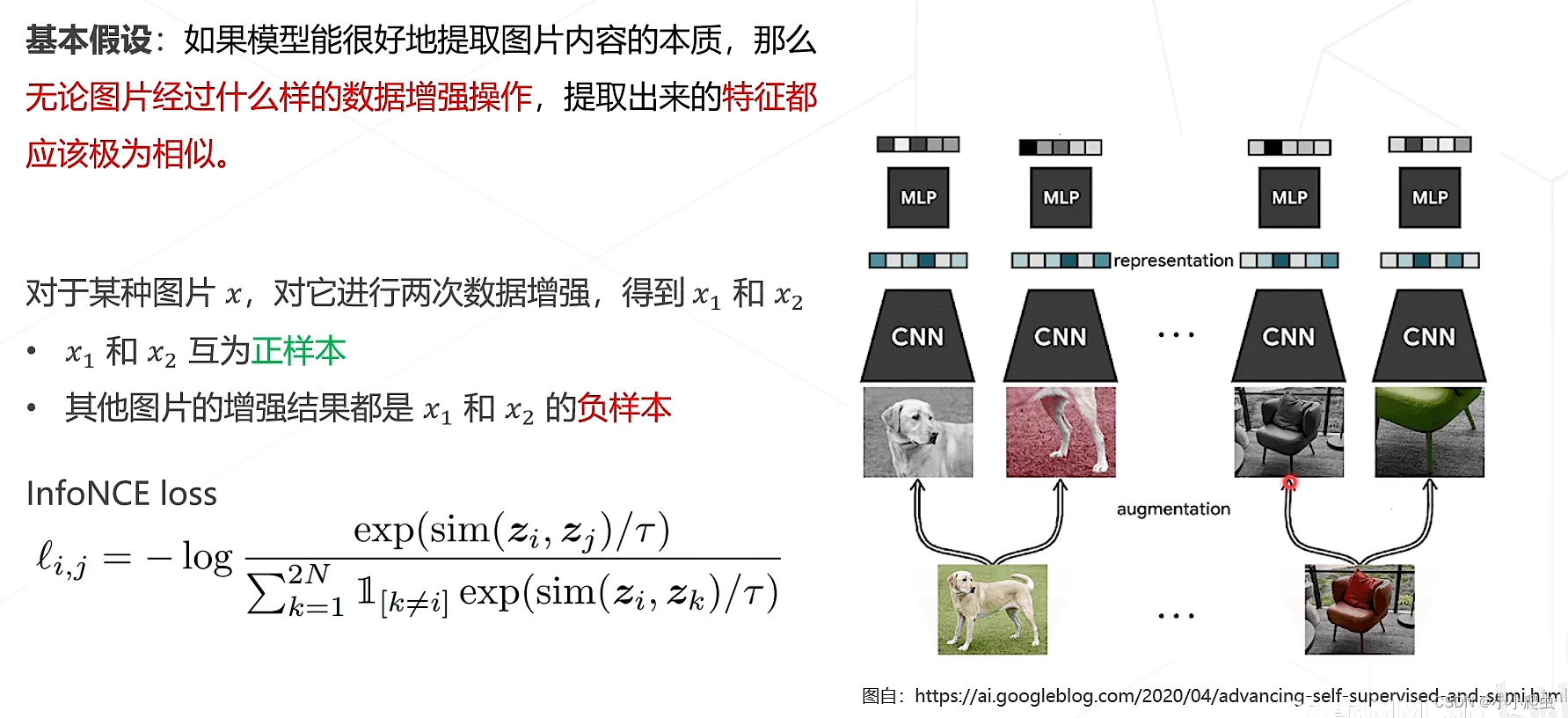
训练的目的是使目标图像的正样本与其他图像的负样本之间的差异越来越大——拉近正样本之间的距离,推远正负样本之间的距离。(对比学习的思路)
基于掩码学习
掩码学习的逻辑:
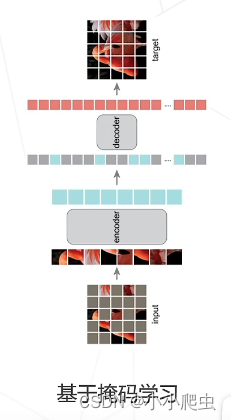
Masked Autoencoders(MAE)
论文:Masked autoencoders are scalable wision learners(CVPR 2022)
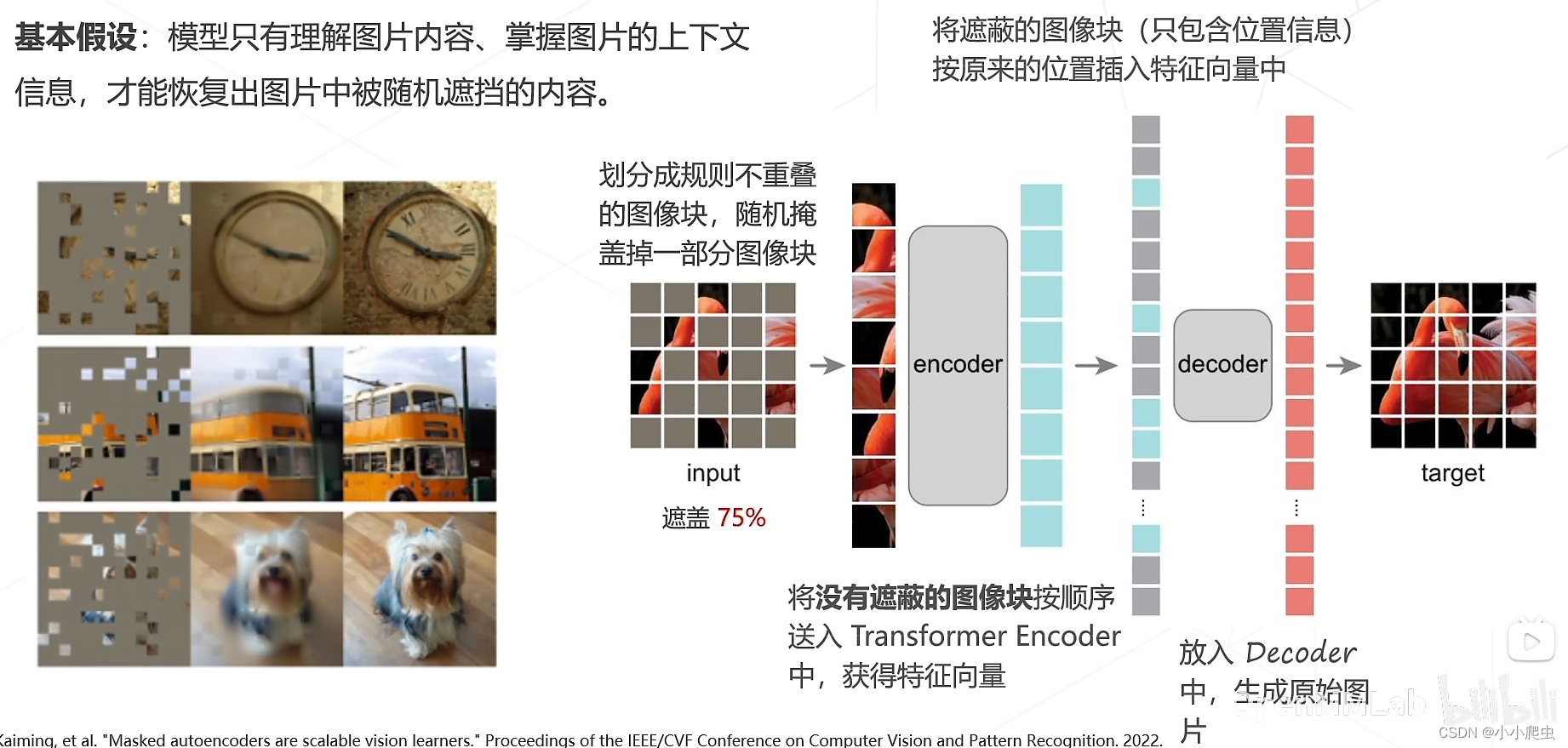
基本假设:模型只有理解图片内容、掌握图片的上下文信息,才能恢复出图片中被随机遮挡的内容。
对比、掩码结合起来的方式
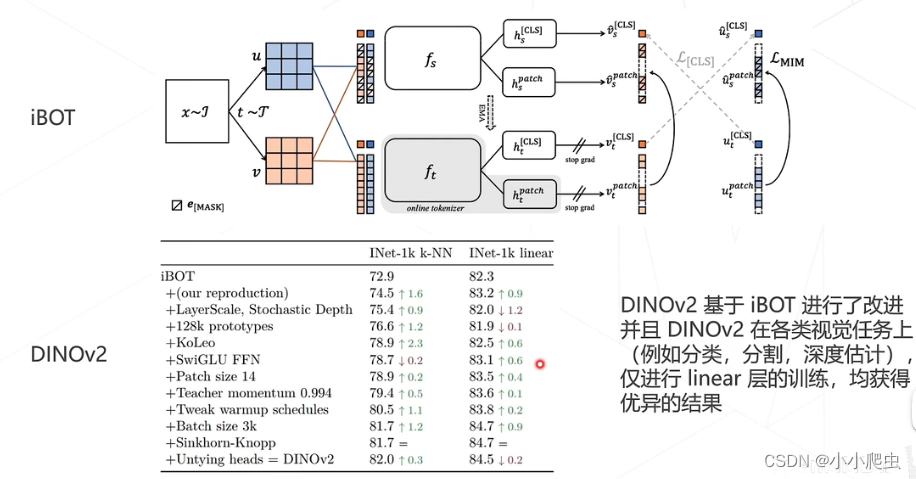
多模态算法
多模态定义参考:链接
CLIP
论文:Learning Transferable Visual Models from Natural Language Supervision(ICML 2021)
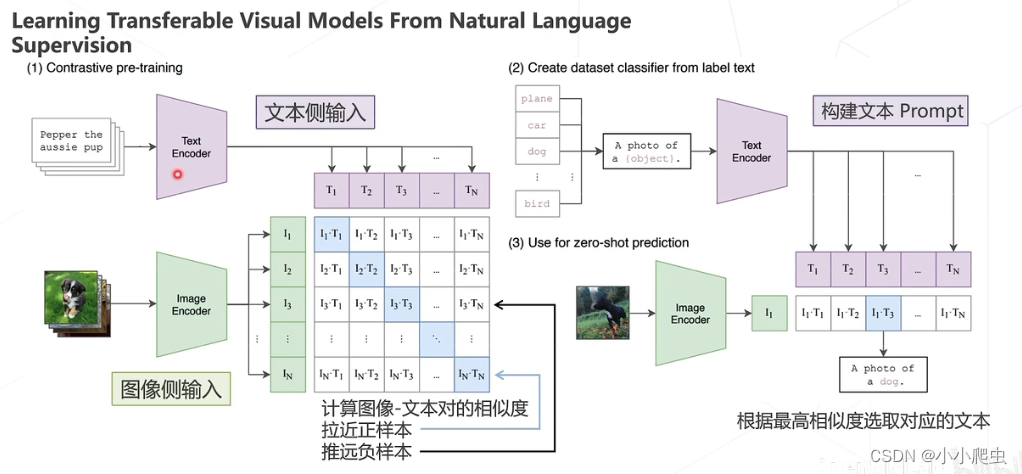
CLIP的测试结果:
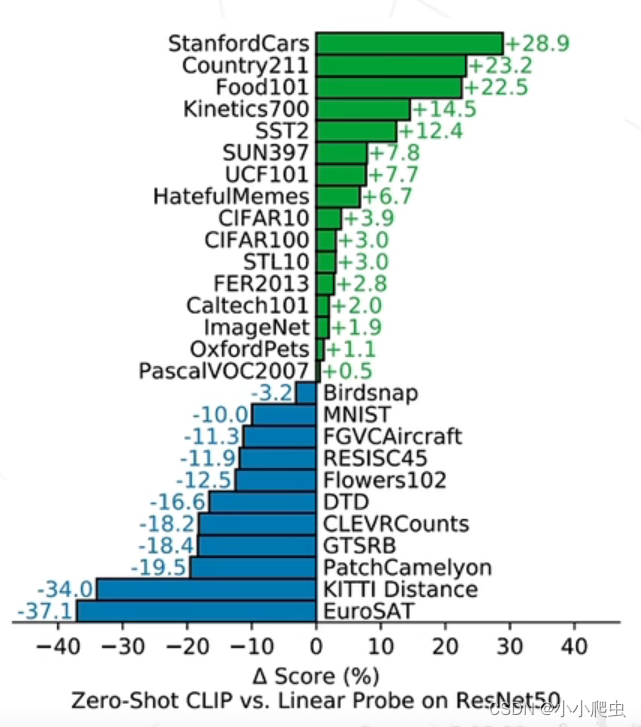
结论:
- 在大规模数据集上使用NLP监督预训练图像分类器,证明了简单的预训练任务,即预测图像和文本描述是否相匹配,是一种有效的、可扩展的方法。
- 用4亿对来自网络的图文数据对,将文本作为图像标签,进行训练。进行下游任务时,只需提供和图像对应的文本描述,就可以进行zero-shot transfer,并取得可观的结果。
问题:什么是zero-shot transfer?
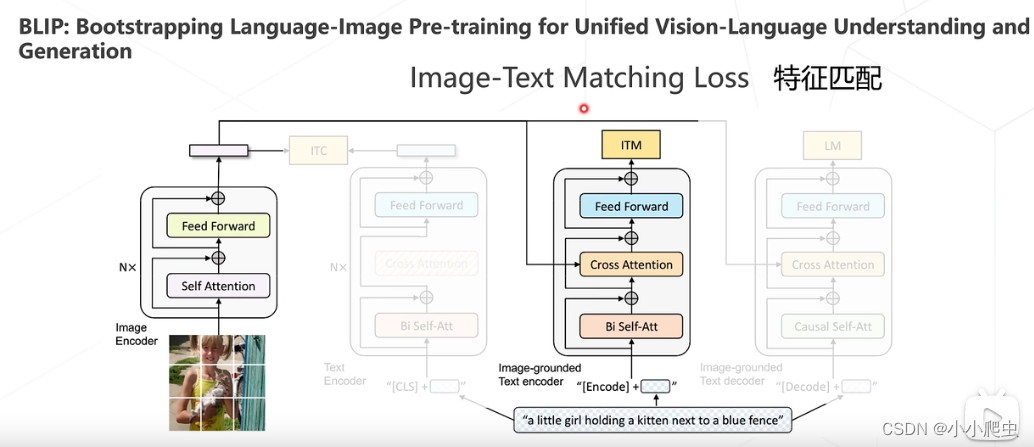
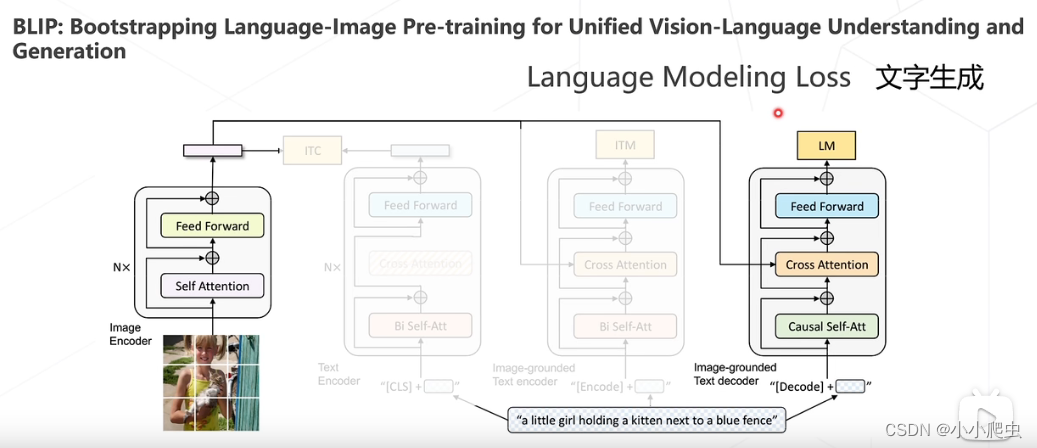
BLIP
论文:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation(ICML 2022)
特征区分
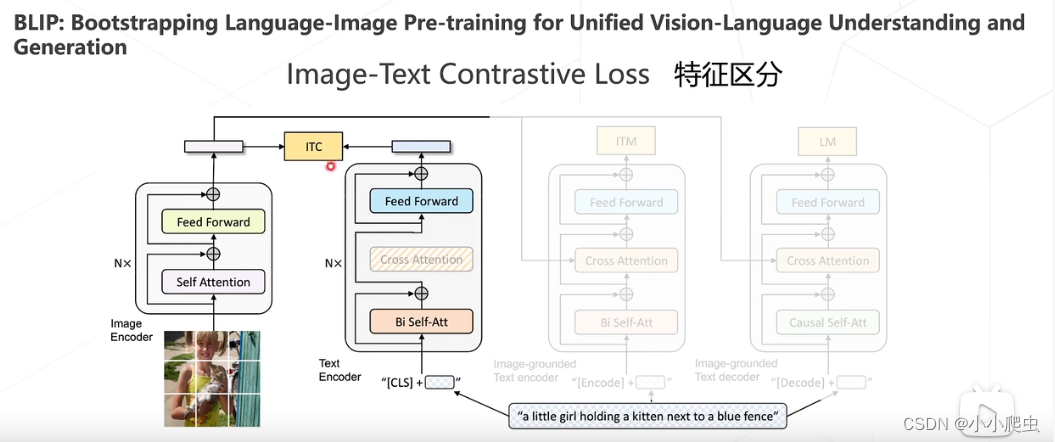
特征匹配
文字生成

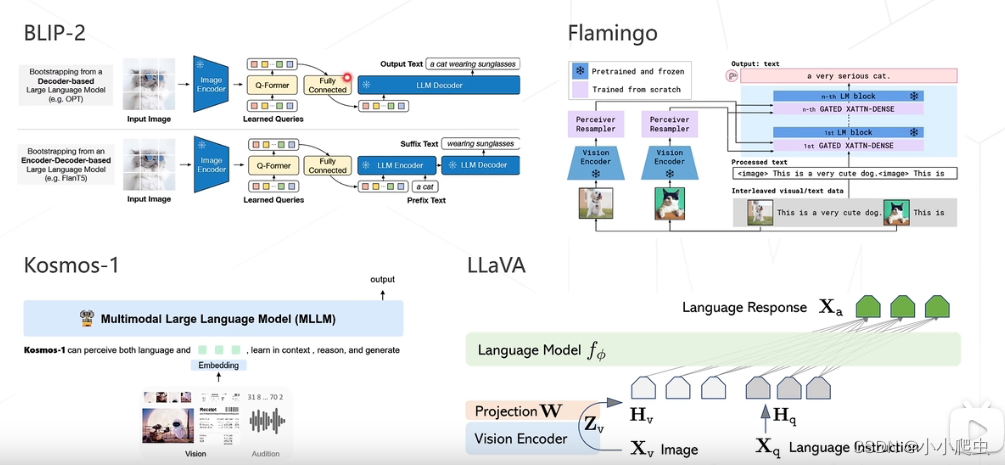
其他多模态算法














 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









