







⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要10分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
⏰个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
基于模型的协同过滤电影评分预测模型
基于模型的协同过滤电影评分预测模型
实验目录
- 基于模型的协同过滤电影评分预测模型
实验内容
- 基于模型的协同过滤电影评分预测模型
知识点
- 协同过滤通过寻找“相近”的偏好来进行推荐
2). 基于模型的协同过滤可以克服基于记忆的协同过滤带来的稀疏问题
实验目的
- 学习建立基于SVD的协同过滤模型进行推荐
实验环境
- Oracle Linux 7.4
- Python 3
任务实施过程
1.打开Jupyter,并新建python工程
-
桌面空白处右键,点击Konsole打开一个终端
-
切换至
/experiment/jupyter目录
cd experiment/jupyter
- 启动Jupyter,root用户下运行需加
–allow-root
jupyter notebook --ip=127.0.0.1 --allow-root

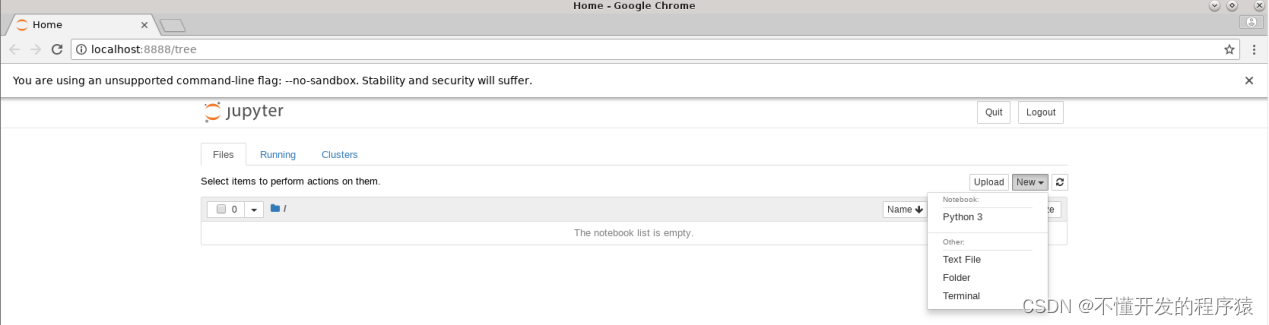
- 依次点击右上角的 New,Python 3新建python工程
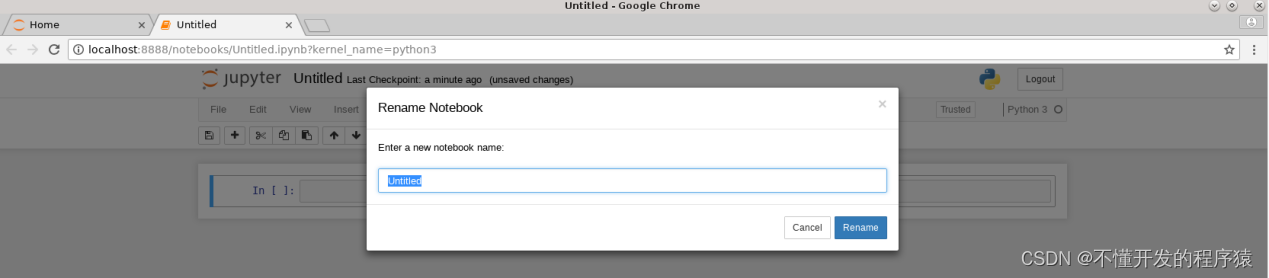
- 点击Untitled,在弹出框中修改标题名,点击Rename确认
2.数据准备
- Jupyter输入代码后,使用shift+enter执行,下同。
- 这是一个跨国数据集,其中包含了2010年12月1日至2011年12月12日期间在英国和注册的非商店在线零售之间发生的所有交易。字段说明:
- InvoiceNo: Invoice number. Nominal, a 6-digit integral number uniquely assigned to each transaction. If this code starts with letter ‘c’, it indicates a cancellation.
- StockCode: Product (item) code. Nominal, a 5-digit integral number uniquely assigned to each distinct product.
- Description: Product (item) name. Nominal.
- Quantity: The quantities of each product (item) per transaction. Numeric.
- InvoiceDate: Invice Date and time. Numeric, the day and time when each transaction was generated.
- UnitPrice: Unit price. Numeric, Product price per unit in sterling.
- CustomerID: Customer number. Nominal, a 5-digit integral number uniquely assigned to each customer.
- Country: Country name. Nominal, the name of the country where each customer resides.
- 读取数据
import pandas as pd
df = pd.read_csv('/root/experiment/datas/ratings.csv')
df.head()
3.数据预处理
- 将数据集转化为需要的格式
from surprise import Dataset, Reader
reader = Reader(rating_scale=(0.5, 5))
data = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)

- 划分训练集和测试集
from surprise.model_selection import train_test_split
tr_set,ts_set = train_test_split(data)

4.建立模型
- 建立基于SVD的协同过滤模型
from surprise import SVD
algo = SVD()
algo.fit(tr_set)

5.预测与评估
- 对用户id87,项id337进行预测
y_pred = algo.predict(uid=87,iid=337)
y_pred.est

- 对预测结果可视化(绘图时,由于jupyter的问题,执行时可能需重复执行才能显示绘图结果,下同)
tmp = pd.DataFrame(algo.test(ts_set))
import matplotlib.pyplot as plt
import numpy as np
jitter1 = np.random.randn(tmp.shape[0])/20
jitter2 = np.random.randn(tmp.shape[0])/40
plt.scatter(tmp['r_ui']+jitter1,round(tmp['est']*2,0)/2+jitter2,alpha=0.003)
plt.show()
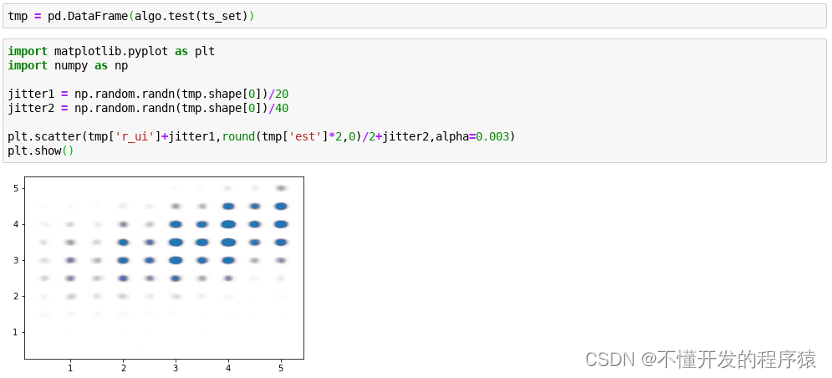
6.实验结论
- 对用户ID为87、电影ID为337预测打分为3.67分。
- 观察预测结果,有明显的对角线趋势,绝大部分预测得分偏差±0.5以内。
数据集资源
链接: https://pan.baidu.com/s/1449wigKQrd2BrWUgrI90jw?pwd=2024
提取码: 2024
–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我
















 8683
8683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











