






文章目录
STFCN: Spatio-Temporal FCN for Semantic Video Segmentation
论文
abstract
This paper presents a novel method to involve both spatial and temporal features for semantic segmentation of street scenes.Current work on convolutional neural networks (CNNs) has shown that CNNs provide advanced spatial features supporting a very good performance of solutions for the semantic segmentation task. We investigate how involving temporal features also has a good effect on segmenting video data. We propose a module based on a long short-term memory (LSTM) architecture of a recurrent neural network for interpreting the temporal characteristics of video frames over time. Our system takes as input frames of a video and produces a correspondingly-sized output; for segmenting the video our method combines the use of three components: First, the regional spatial features of frames are extracted using a CNN; then, using LSTM the temporal features are added; finally, by deconvolving the spatio-temporal features we produce pixel-wise predictions. Our key insight is to build spatio-temporal convolutional networks (spatio-temporal CNNs) that have an end-to-end architecture for semantic video segmentation. We adapted fully some known convolutional network architectures (such as FCN-AlexNet and FCN-VGG16), and dilated convolution into our spatio-temporal CNNs. Our spatio-temporal CNNs achieve state-of-the-art semantic segmentation, as demonstrated for the Camvid and NYUDv2 datasets.
point
1、提出融合时空特征的街景语义分割方法——STFCN
2、STFCN融合LSTM(长短期记忆网络)来解释视频帧随时间变幻的时间特征(Temporal Feature)
3、输入视频帧、端到端输出,整体处理流程包括三步骤:首先,CNN(编码器)提取帧的特征;同时,LSTM提取帧之间的特征;最后反卷积恢复尺寸。
LSTM
RNN
针对于序列问题,RNN提出隐状态h(hidden state),隐状态h可以对序列数据提取特征,接着转为输出。
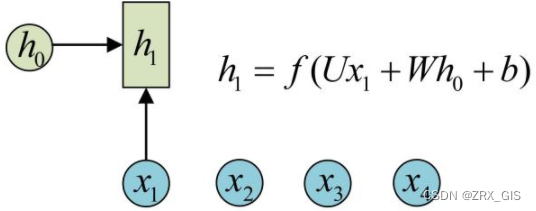
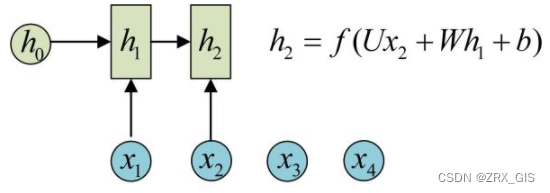
(圆圈或方块表示的是向量。一个箭头就表示对该向量做一次变换。如上图中h_{0}和x_{1}分别有一个箭头连接,就表示对h_{0}和x_{1}各做了一次变换。)
1、在计算时,每步骤使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点,一定要牢记。
2、在计算时,LSTM的权重则不共享,因为他是在两个不同的向量中。而RNN的权重共享原因是在同一个向量中,只是时刻不同
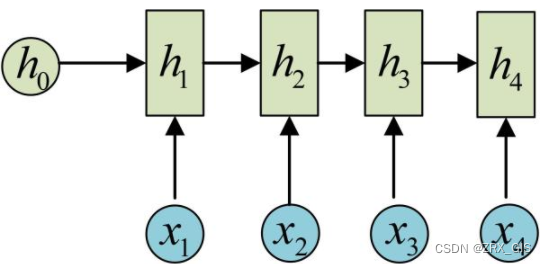
3、方便起见,只画序列长度为4的情况,实际上,这个计算过程可以无线持续下去。我们目前的·RNN还没输出,得到输出值得方法就是直接通过h进行计算
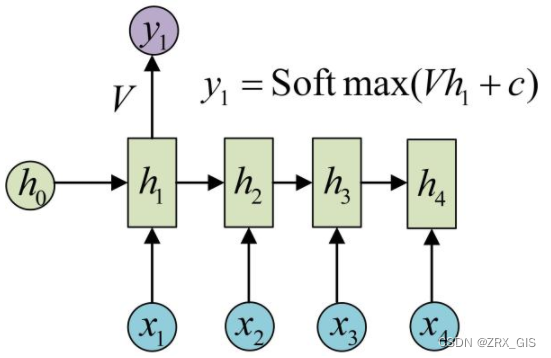
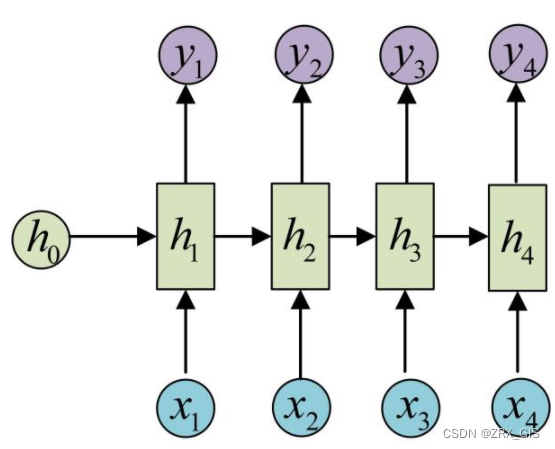
这样RNN就完成了由一个序列{x1,,}生成另一个序列{y1,,},其实这也出现第二的点,就是输入和输出序列必须等长的。
RNN的应用
RNN可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。所以,如果我们将这个循环展开:
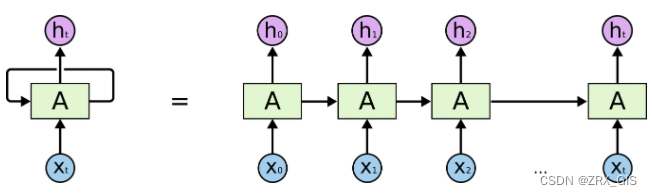
链式的特征揭示了RNN本质上是与序列和列表相关的,它们是对于这类数据的最自然的神经网络架构。
RNN局限性——长期依赖(Long-TermDependies)问题
RNN的关键点之一就是可以用来连接之前的信息到当前的任务上,例如使用过去的视频来推测对当前段的理解。
RNN可以做到这一点,但是他会有很多的依赖因素。比如,有时候,我们仅需要知道先前的信息来执行当前的任务,例如我们有一个语言模型来基于先前的词预测下一个词。如果我们试着预测这句话中“the clouds are in the sky”最后的这个词“sky”,我们并不需要其他的信息,因为显然下一个词应该是sky。当然也会有另一种场景,比如我们试着预测“I grew up in France…I speak fluent French”最后的词“French”,我们就需要间隔较大的信息来实现预测,而不幸的是,在这个间隔不断增大时,RNN丧失学习到如此原的信息的能力,这类问题我们归结为
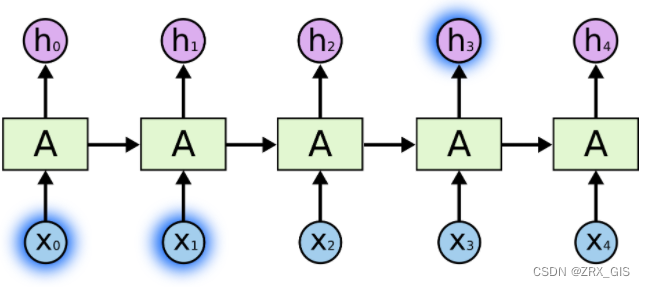
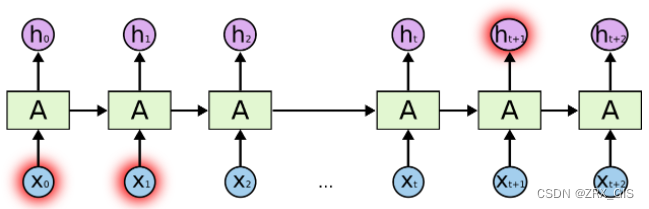
在理论上,RNN绝对可以处理这样的长期依赖问题,人们可以仔细挑选参数来解决这类问题中的最初级形式,但在实践中,RNN则没法太好的学习到这些知识。换句话说,RNN会受到短时记忆(前几个相邻节点)的影响,如果一条序列足够长,那他们将很难将信息从较早的时间传递到当前。
因此,如果你正在尝试处理一段文本进行预测,RNN有可能从一开始就会漏掉重要信息。在方向传播期间(bp是深度学习中很重要的议题,本质上通过不断缩小误差去更新权重,从而不断去修正拟合的函数),RNN可能面临梯度消失。
因为梯度是用来更新神经网络的权重值(新的权重=旧的权重-学习率*梯度),梯度会随着时间的退役不断降低减少,而当梯度很小时,换句话说也就停止了学习。换而言之,对于在递归神经网络中,获得小梯度更新的层会停止学习,由于这些层不学习,RNN会忘记他在较长时间序列中之前看到的内容,因此RNN是一种短时记忆。这是便出现了RNN变式LSTM(Long Short Term)。
LSTM
LSTM长短期记忆网络,设计的目的就是为例可以学习长依赖的信息。当然,LSTM和RNN并没有太大的结构差异,但是它们所采用的计算隐状态的Function是不同的。LSTM的“记忆”我们叫做细胞/cells,你可以直接把它们想做黑盒,这个黑盒的输入为前状态h_{t-1}和当前输入x_{t}。这些“细胞”会决定哪些之前的信息和状态需要保留/记住,而哪些要被抹去。实际的应用中发现,这种方式可以有效地保存很长时间之前的关联信息。
例如我们在网上购物时,一般会查看已购买该商品用户的评价。当你浏览时,大脑会下意识去寻找关键字,而不会去关心助词、副词什么的,就如同在做长难句压缩一般。如果,之后需要回忆这段阅读内容,你也可以通过简短的字符来描述这条评论,而那些无关紧要的信息便会比屏蔽掉。
这就是LSTM和GRU所做的,他们可以学习只保留相关信息进行预测,并忘记不相关的数据。简单地说因记忆能力优先,记住重要的,遗忘不重要的。
LSTM通过刻意的设计来避免长期依赖问题,记住长期的信息在实践中是LSTM的默认行为,而非需要付出巨大代价才可以获得的能力。所有RNN都具有一种重复神经网络模块的链式形式,在标准RNN中重复模块只有一个非常简单的结构(如tanh层)。

激活函数 Tanh 作用在于帮助调节流经网络的值,使得数值始终限制在 -1 和 1 之间。
SLTM同样是这样的结构,但是重复的模块拥有不同的结构。具体来说,RNN是重复单一的神经层,LSTM的重复模块包括四个交互的层,三个sigmod和一个tanh层,并以一种非常特殊的方式进行交互。
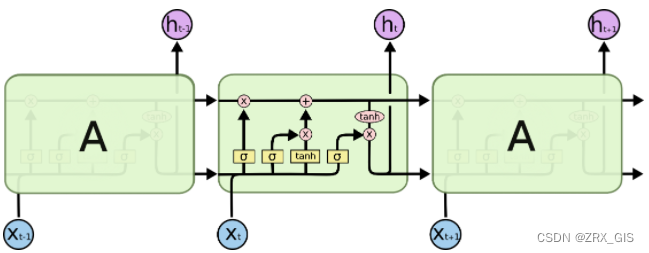
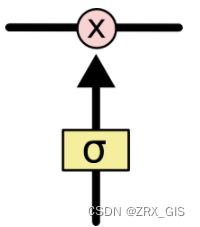
σ表示的Sigmoid 激活函数与 tanh 函数类似,不同之处在于 sigmoid 是把值压缩到0~1 之间而不是 -1~1 之间。这样的设置有助于更新或忘记信息(1、任何一个数乘0都是0,这部分信息就会被剔除掉;2、任何一个数乘1都是本身,这部分信息就被保留),这样便产生SLTM的第一个准则,因为记忆能力有限,记住重要的,忘记无关紧要的,图中,每个黑线传输一整个向量,从一个节点的输出到其他节点的输入。粉色的全代表pointwise操作,注入向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置
SLTM的核心思想是细胞状态(cell),细胞状态类似传送带,直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
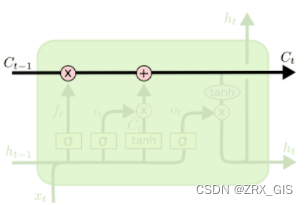
LSTM通过“门”来去除或者增加信息到细胞状态的能力,门是一种让信息选择式通过的方法,他们包含一个sigmod和pointwise的非线性操作。如此,0代表不允许任何量通过,1代表允许任意量通过。从而使得网络就能了解哪些数据是需要遗忘,哪些数据是需要保存。
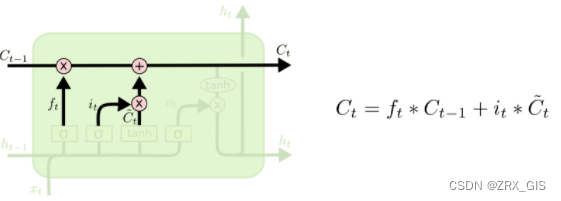
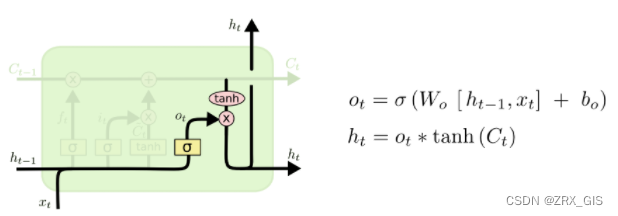
LSTM拥有三种类型的门结构:遗忘门、输入门、输出门。这些门用来保护和控制细胞状态,具体阐述如下:
遗忘门在SLTM中第一步是决定我们会从细胞状态中丢弃什么信息,遗忘门会读取上一个输出一个输出h_{t-1}和当前输入x_{t},然后做一个sigmoid的非线性映射,然后输出一个向量f_{t}(该向量每一个维度的值都在0到1之间,1表示完全保留,0表示完全舍弃,相当于记住了重要的,忘记了无关紧要的),最后与细胞状态C_{t-1}相乘。类比到语言模型的例子中,则是基于已经看到的预测下一个词,在这个问题中细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来,当我们看到新的主语,我们希望以往旧的主语,进而决定丢弃信息。
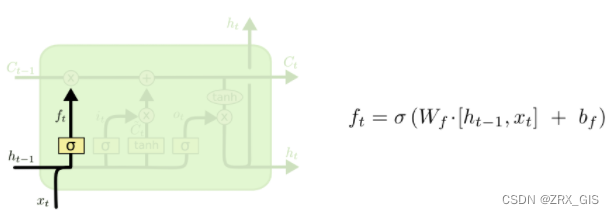
对于上图右侧公式中权值W_{f},准确的说其实是不共享,即是不一样的。
输入门确定什么样的新信息会被存放到细胞状态中,这里大概分为两步:1、sigmoid层为“输入门层”决定什么值我们将要更新;2、一个tanh层创建一个新的候选值向量\tilde{C}{t},会被加入到状态中。在语言模型的例子中,我们希望增加新的主语的性别到细胞状态中来代替旧的需要记住的主语,进而确定更新的信息。
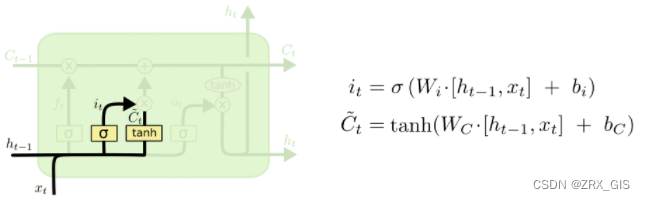
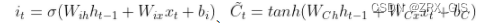
细胞状态现在是更新就细胞状态的时间里,C{t-1}更新为C_{t}。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。我们把旧状态与f_{t}相乘,丢弃掉我们确定需要丢弃的信息,接着加上i_{t} * \tilde{C}_{t}。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方,类似更新细胞状态。
输入门界定我们输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个sigmoid层来确定细胞状态的哪个部分将会输出,接着我们把细胞状态通过tanh进行处理,得到[-1,1]并将他和sigmoid的输出相乘得到最终输出。在语言模型的例子中,因为他就看到一个代词,可能需要输出一个与动词相关的信息,例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化,进而输出信息。
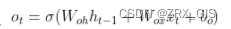
1 Introduction
Semantic segmentation of video data is a fundamental task for scene understanding. For many computer vision applications, semantic segmentation is considered as being (just) a pre-processing task. Consequently, the performance of semantic segmentation has a direct effect on subsequent computer vision solutions which depend on it. Self-driving cars is one of the areas in technology that has received much attention recently. These cars can detect surroundings using advanced driver assistance systems (ADAS) that consist of many different systems such as radar, GPS, computer vision, and in-car networking to bring safety to driving and roads. One of the main processes for the computer vision part of these systems can be identified as being semantic segmentation of all objects in surroundings to transmit accurate and complete information to the ADAS system such that the system can make the best decision to avoid accidents.
Segmentation is typically approached as a classification problem. First, using a set of labeled video frames, the characteristics of all segments (classes) are learned. These characteristics are used for labeling the pixels of test frames [1,51].Recently, deep learning methods, especially CNNs, ensured state-of-the-art performance in different areas of computer vision, such as in image classification [26], object detection [14], or activity recognition [40].
We consider the application of advanced features, extracted by using CNNs, for semantic video segmentation. Semantic segmentation methods use both given image data at selected locations as well as a semantic context. A set of pixels is usually predicted as defining one class (or even one segment) if connected, and also referring to one particular semantic interpretation.
Previous methods for video segmentation have efficiently exploited CNNs, but they did not use temporal features; of course, temporal features can be useful for interpreting a video semantically. For example, the authors of [1,51] represented and interpreted video frames using a deep learning method, but the main disadvantage of their methods is that they consider those frames as being independent from each other. Neglecting the time dimension in video data basically means that the given raw data are down-sampled without using fully given information. Using temporal features can help the system to distinguishing, for example, between two objects of different classes having the same spatial features but showing differences in the time feature dimension.
Consequently, we propose a method which uses a similar paradigm for extracting spatial features (as in the cited papers), but which differs by also using temporal features (i.e. features of a continues sequences of frames). We propose to identify components which can be embedded “on top” of spatially extracted features maps in individual frames. Such a component can be seen as being equipped with a set of memory cells which save the assigned regions in previous frames. This allows us that relations between regions, available in previous frames, can be used to define temporal features. We process the current video frame by using the spatio-temporal output features of our processing modules.
Similar to other segmentation methods, we use then some fully convolutional layers to perform regional semantic classification. In our method, these fully convolutional layers perform spatio-temporal classifications. Finally, we use a deconvolution procedure for mapping (i.e. scaling) the obtained predictions into the original carrier (i.e. the image grid) of the given frames for having a pixel-wise prediction. See Fig. 1.
CNN-based methods usually combine two components, where one is for describing and inferring a class of different regions of a video frame as a feature map, and another one for performing an up-sampling of the labeled feature maps to the size of the given video frames. An advantage of our method is that we can adjust and embed our proposed module into the end of the first component (before inferring the labels) of current CNN-based methods as an end-to-end network. We show that the proposed changes in the network lead to an improvement in the performance of state-of-the-art methods, such as, FCN-8 [32] and dilated convolution [51].
The main contributions of this paper are as follows: – The proposed method can be easily adapted for enhancing already published state-of-the art methods for improving their performance.
– We propose an end-to-end network for semantic video segmentation in respect to both spatial and temporal features.
– We propose a module for transforming traditional, fully convolutional networks into spatio-temporal CNNs.
– We outperformed state-of-the art methods on two standard benchmarks.
The rest of this paper is organized as follows. Top-ranked related work on semantic video segmentation is reviewed in Section 2. Section 3 introduces the proposed method. The performance of our method is shown in Section 4. Section 5 concludes the paper.
point
1、Semantic segmentation研究十分有意义;
2、深度学习的方式是研究热门;
3、当前研究中缺乏对序列数据中时间特征的利用;
4、本文算法通过CNN提取帧的特征、同时用过SLTM提取时序特征
5、提出一个可以将传统卷积网络转换为时空CNN
2 Related Work
There is a wide range of approaches that have been published so far for video segmentation. Some of them have advantages over others. These approaches can be categorized based on the kind of data that they operate on, the method that is used to classify the segments, and the kind of segmentation that they can produce.
Some approaches focus on binary classes such as foreground and background segmentation [2,4]. This field includes also some work that has a focus on anomaly detection [37] since authors use a single-class classification scheme and constructed an outlier detection method for all other categories. Some other approaches concentrate on multi-class segmentation [6,29,30,45].Recently created video datasets provide typically image data in RGB format.
Correspondingly, there is no recent research on gray-scale semantic video segmentation; the use of RGB data is common standard, see [12,23,29,30,48]. There are also some segmentation approaches that use RGB-D datasets [17,18,33].
Feature selection is a challenging step in every machine learning approach.The system’s accuracy is very much related to the set of features that are chosen for learning and model creation. Different methods have been proposed for the segmentation-related feature extraction phase.
2.1 Feature Extraction
We recall briefly some common local or global feature extraction methods in the semantic segmentation field. These feature extraction methods are commonly used after having super-voxels extracted from video frames [30].
Pixel color features are features used in almost every semantic segmentation system [12,23,29,30,33]. Those includes three channel values for RGB or HSV images, and also values obtained by histogram equalization methods. The histogram of oriented gradients (HOG) defines a set of features combining at sets of pixels approximated gradient values for partial derivatives in x or y direction[23,29].
Some approaches also used other histogram definitions such as the hue color histogram or a texton histogram [48].
Further appearance-based features are defined as across-boundary appearance features, texture features, or spatio-temporal appearance features; see [12,23,29,30].
Some approaches that use RGB-D datasets, also include 3-dimensional (3D) positions or 3D optical flow features [18,33]. Recently, some approaches are published that use CNNs for feature extraction; using pre-trained models for feature representation is common in [1,17,49].
After collecting a set of features for learning, a model must be chosen for training a classifier for segmentation. Several methods have been provided already for this purpose, and we recall a few.
2.2 Segmentation Methods
Some researches wanted to propose a (very) general image segmentation approach. For this reason, they concentrated on using unsupervised segmentation.This field includes clustering algorithms such as k-means and mean-shift [31], or graph-based algorithms [12,18,23,47].
A random decision forest (RDF) can be used for defining another segmentation method that is a kind of a classifier composed of multiple classifiers which are trained and enhanced by using randomness extensively [16,36]. The support vector machine (SVM) [43] or a Markov random field (MRF) [38,46] are further methods used for segmentation but not as popular as the conditional random field (CRF) that is in widespread use in recent work[5,29,35].
Neural networks are a very popular method for image segmentation, especially with the recent success of using convolutional neural network in the semantic segmentation field. Like for many other vision tasks, neural networks have become very useful [1,14,17,20,32,49].
Fully convolutional networks (FCNs) are one of the topics that interest researchers recently. An FCN is based on the idea of extending a convolutional network (ConvNet) for arbitrary-sized inputs [32]. On the way of its development, it has been used for 1-dimensional (1D) and 2-dimensional (2D) inputs [34,44], and for solving various tasks such as image restoration, sliding window detection, depth estimation, boundary prediction, or semantic segmentation. In recent years, many approaches use ConvNets as feature extractor [1,17,49]. Some approaches turn ConvNets into FCNs by discarding the final classifier layer, and convert all fully connected layers into convolutions. By this change, authors use a front-end module for solving their vision tasks [1,14,17,20,32,49].
Recently, a new convolutional network module has been introduced by Yu and Fisher [51] that is especially designed for dense prediction. It uses dilated convolutions for multi-scale contextual information aggregation, and achieves some enhancements in semantic segmentation compared to previous methods.
Kundu and Abhijit [27] optimized the mapping of pixels into a Euclidean feature space; they achieve even better results for semantic segmentation than [51] by using a graphical CRF model.
Many approaches that have been introduced in this field have not yet used temporal features, especially in the field of deep CNNs [12,18,23,29,30,48]. These approaches cannot be identified as being end-to-end methods, which points to an essential disadvantage when applying these approaches. Some approaches use deep CNNs [17,27] by introducing an end-to-end architecture for also using spatio-temporal features for semantic labeling. However, none of them can change the size of time windows dynamically.
Long short-term memory (LSTM) is a memory cell module that was introduced by [13,19]. It has many advantages such as the ability to support very large time windows, the ability to change time windows dynamically, the ability to handle noise, distributed representations, continuous values, and so forth. We propose for the first time an approach that uses a deep CNN network with LSTM modules as an end-to-end trainable architecture for semantic video segmentation and labeling.
point
1、根据处理的数据类型,视频语义分割可以分为the method that is used to classify the segments, and the kind of segmentation that they can produce.
2、RGB和RGB-D是常用的数据类型
RGB-D
RGB-D是深度图像,深度图像 = 普通的RGB三通道彩色图像 + Depth Map,Depth Map包含与试点的场景对象的表面的距离有关的信息的图像或图像通道,其中,Depth Map类似灰度图,只是他的每个像素值是传感器距离物体的实际距离划定,RGB可以和深度图配准。
图像深度
图像深度是指存储每个像素所用的位数,也用于度量图像的色彩分辨率;图像深度决定彩色信息的每个像素可能有的颜色数,或者确定灰度图像的每个像素可能有的灰度级,他九鼎彩色图像中可出现的最多色彩书,或灰度图中最大灰度级。例如一幅单色图像,弱每个像素有8位,则最大灰度数目为2^8,即256.一幅彩色图像RGB的像素位数分别为4,4,2则最大颜色数目为2的(4+4+2)次方,就是说像素的深度为10位,每个像素可能是1024种颜色的一种。
3 The Proposed Method
3.1 Overall scheme
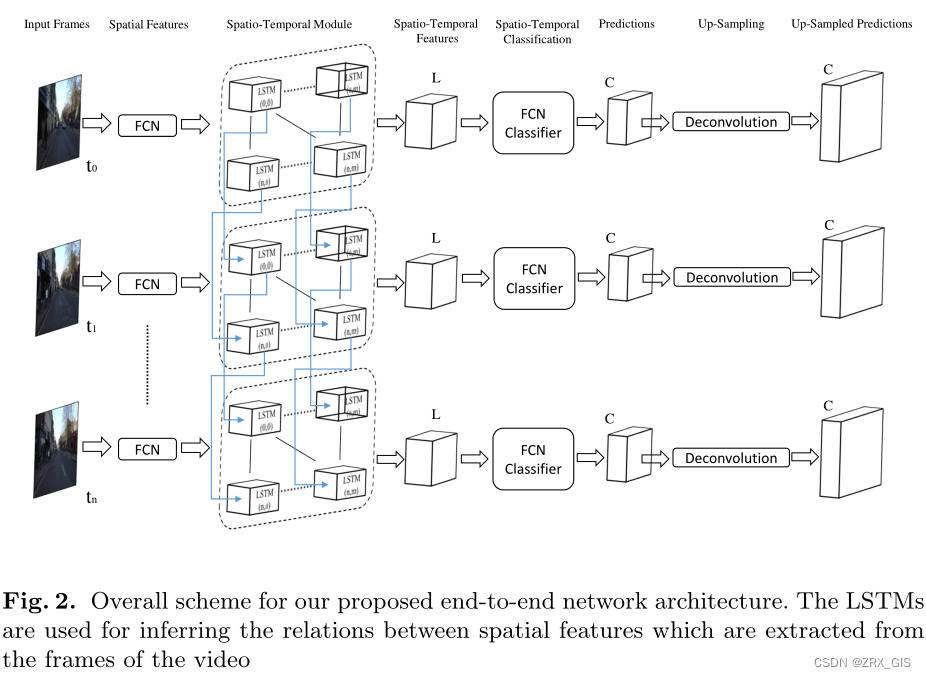
这里原文写的有点太复杂,我们直接对原文进行表述一下
原文在此部分是想交代一下整体数据在本文模型中的流经过程,上面这张图向我们展示了数据处理的过程,左侧图片就是视频的每一帧,帧说白了就是某一时刻的图片,因此单路径上仍然是传统的语义分割,在分割过程中通过FCN的编码器提取特征,然后就是将特征按照向量方式输入到SLTM中,获取附加了时间特征的特征图,再就是走解码器恢复图像尺寸,最后获得每一帧的分割结果。
3.2 Fully Convolutional Network
Convolutional neural networks (CNNs) are applied for a large set of vision tasks.Some researchers improve CNNs by changing its basic architecture and introducing new architectures. Recently, fully convolutional networks (FCNs) have been introduced by discarding the final classifier layer, and by converting all fully connected layers into convolutional layers. We follow this principle.
3.3 LSTM
A long short-term memory (LSTM) network is a special kind of recurrent neural networks (RNNs) that have been introduced by [19] to solve the vanishing gradient problem and for remembering information over long periods. For an example of a basic RNN and an LSTM cell, see Fig. 3. LSTMs are not confined to fixed-length inputs or outputs, and this advantage makes them powerful for solving sequential problems.
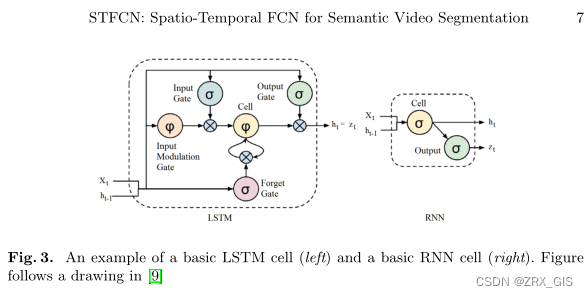
Each LSTM module consists of a memory cell and a number of input and output gates that control the information flow in a sequence and prevent it from loosing important information in a time series. Assuming St as the input of an LSTM module at time t, the cell activation is as formulated in the following equations:
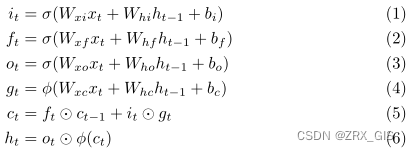
3.4 Spatio-Temporal Module
3.5 Deconvolution
4 Experimental Results
For implementing our spatio-temporal fully convolutional network (STFCN) we use the standard Caffe distribution [21] and a modified Caffe library with an LSTM implementation.1We merged this LSTM implementations into the Caffe standard distribution and released our modified Caffe distribution to support new FCN layers that have been described in [32]. Our code has been tested on NVIDIA TITAN, and NVIDIA TITAN-X GPUs.2To show the performance of our modified version of FCNs we use their implemented models for two cases, with and without our spatio-temporal module.
We tested our STFCN networks on Camvid3 and NYUDv24 datasets. Our evaluation methodology is as in other state-of-the-art semantic segmentation tests, such as in [1,32].
In the following, first we describe the way how we embed our spatio-temporal module into FCNs and dilation convolution networks. Then we describe the metrics used in the evaluation process. After that we report our experiments on CamVid and NYUDv2. Finally, we discuss the performance of our method.
4.1 Embedding the Spatio-Temporal Module in FCN Networks
FCN-8 and FCN-32 [32] are fully convolutional versions of VGG-16 with some modifications to combine features of shallow layers with more precise spatial information with features of deeper layers which have more precise semantic information.
As mentioned in Section 3, it is of benefit to embed the spatio-temporal module on top of the deepest layers. Thus we embed our spatio-temporal module on top of the f c7 layer of FCN-8 and FCN-32. The f c7 is the deepest fully convolutional layer which has large corresponding receptive fields in the input image. This layer extracts features which represent more semantic information in comparison to shallower layers.
An example of this modification of an FCN-Alexnet is shown in Fig. 1. After embedding our spatio-temporal module in FCN-8 and FCN-32 networks, we call them STFCN-8 and STFCN-32. Our spatio-temporal module consists of LSTMs with 30 hidden nodes and 3 time-steps for the CamVid dataset. We fine-tuned our STFCN networks from pre-trained weights on PASCAL VOC [10] provided by [32]. We used a momentum amount of 0.9, and a learning rate of 10e-5.
4.2 Embedding Our Module in Dilated Convolution Networks
A dilated convolution network is an FCN network which benefits from some modifications such as reducing down-sampling layers and using a context module which uses dilated convolutions. This module brings multi-scale ability to the network [51].The dilated8 network [51] consists of two modules, front-end and context.The front-end module is based on a VGG-16 network with some modifications.
The context layer is connected on top of this module. The f c7 layer of the frontend layer provides the main spatial features with 4,096 maps. This network has an input of size 900 × 1, 100. Because of removing some of its down-sampling layers, the f c7 layer has an output of size 66×91 which defines a high dimension for spatio-temporal computations. For overcoming this complexity problem, we down-sampled the output of this layer by a convolution layer to the size of 21×30, and fed it to our spatio-temporal module. Then, the spatio-temporal features are fed to a convolutional layer to decrease their maps to the size of the final layer of the front-end module.
After resizing the maps, features are fed to a deconvolution layer to up-sample them to the size of the final layer output (66 × 91). Finally, we fuse them with the front-end final layer by an element-wise sum operation over all features.
The fused features are fed to the context module. Let STDilated8 be the modified version of dilated8; see Fig. 4. The spatio-temporal module of STDilated8 consists of 30 hidden nodes of LSTMs with a time-step of 3. For training this network, we fixed the front-end module and fine-tuned the spatio-temporal and context modules with dilation8 pre-trained weights on CamVid. We used a momentum amount of 0.9, and a learning rate of 10e-5.
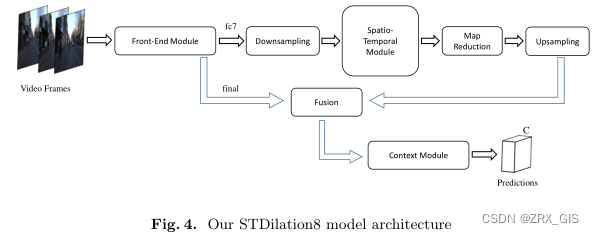
For better performance of the spatio-temporal module, we down-sampled the output of the f c7 layer of the dilation8 front-end module and fed it to the spatiotemporal module. Then we reduced the feature maps by a fully convolutional layer for a better description of the spatio-temporal features and make them the same size as the final layer of the front-end module. Finally we up-sample and fuse the spatio-temporal features with the final layer output and feed them into the context module.
4.3 Quality Measures for Evaluation
There are already various measures available for evaluating the accuracy of semantic segmentation. We describe most commonly used measures for accuracy evaluation which we have used to evaluate our method.
Mean intersection over union. Mean IU is a segmentation performance measure that quantifies the overlap of two objects by calculating the ratio of the area of intersection to the area of unions [24,48]. This is a popular measure since it penalizes both over-segmentation and under-segmentation separately [38].
4.4 CamVid
4.5 NYUDv2
文章使用CamVid和NYUDv2数据集
代码
(无pytorch版本)
















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











