






1 目标检测
目标检测任务=分类+定位

- 目标检测位置信息表示方式(一般图像左上角为0,0):
- 极坐标表示(
xmin,ymin,xmax,ymax)即左上角坐标和右下角坐标 - 中心点表示(
x_center,y_center,w,h)
- 极坐标表示(
2 常用的目标检测数据集
PASCAL VOC数据集 和 MS COCO数据集。
2.1 PASCAL VOC数据集
PASCAL VOC包含约10,000张带有边界框的图片用于训练和验证。常用的是VOC2007和VOC2012两个版本数据,共20个类别,分别是:

其目录结构如下:

-
JPEGImages存放图片文件
-
Annotations下存放的是xml文件,描述了图片信息(每个图片都对应一个xml文件)。如下图所示:
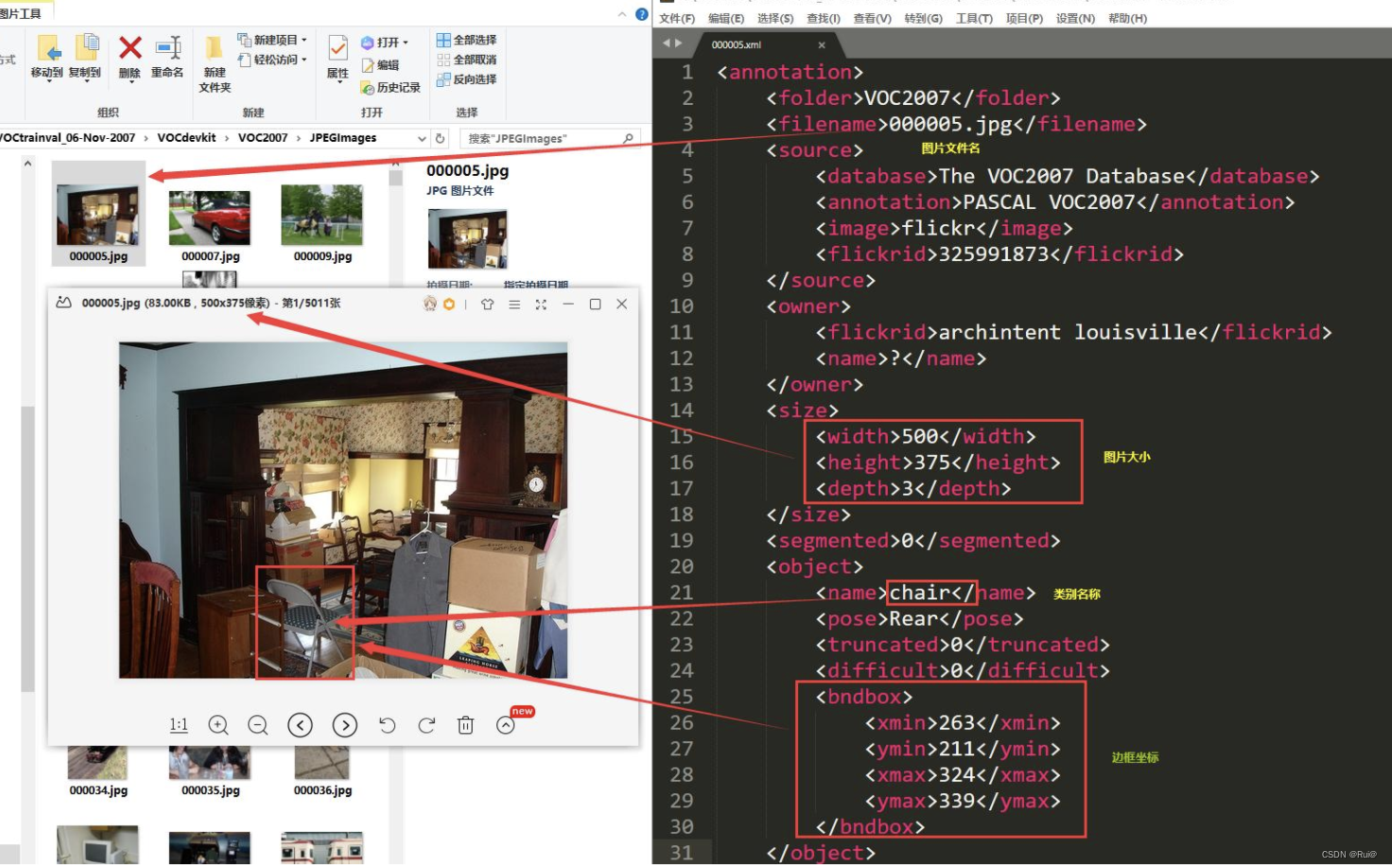
-
ImageSets包含以下4个文件夹:
- Action下存放的是人的动作(例如running、jumping等等)
- Layout下存放的是具有人体部位的数据(人的head、hand、feet等等)
- Segmentation下存放的是可用于分割的数据。
- Main下存放的是图像物体识别的数据,总共分为20类,这是进行目标检测的重点。该文件夹中的数据对负样本文件进行了描述。
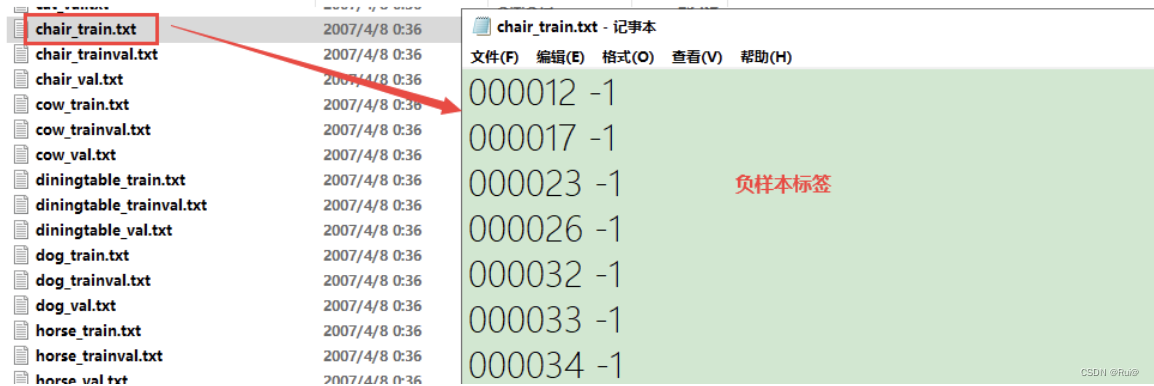
2.2 COCO数据集
全称是Microsoft Common Objects in Context
目前为止目标检测的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。

coco的标签文件:标记每个segmentation+bounding box的精确坐标
{“segmentation”:[[392.87, 275.77, 402.24, 284.2, 382.54, 342.36, 375.99, 356.43, 372.23, 357.37, 372.23, 397.7, 383.48, 419.27,407.87, 439.91, 427.57, 389.25, 447.26, 346.11, 447.26, 328.29, 468.84, 290.77,472.59, 266.38], [429.44,465.23, 453.83, 473.67, 636.73, 474.61, 636.73, 392.07, 571.07, 364.88, 546.69,363.0]], “area”: 28458.996150000003, “iscrowd”: 0,“image_id”: 503837, “bbox”: [372.23, 266.38, 264.5,208.23], “category_id”: 4, “id”: 151109},
3 评价指标
3.1 IOU
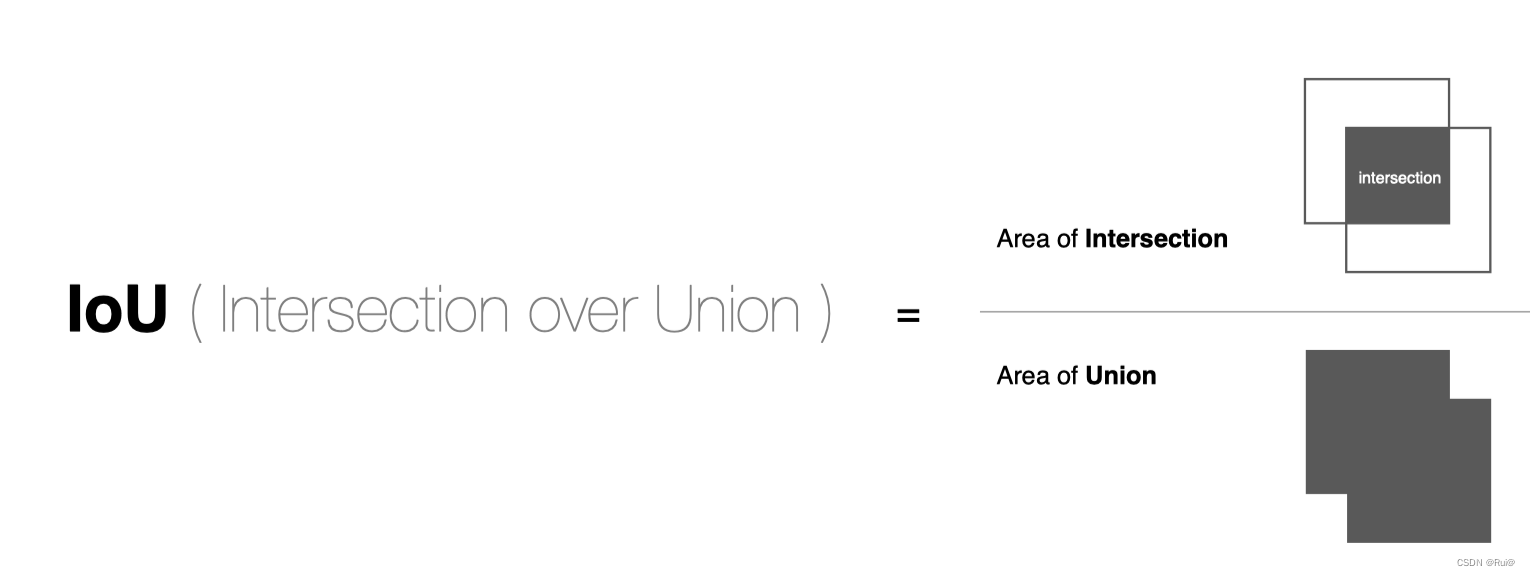
IoU(intersection over union,交并比)是2个矩形框之间相似度:IoU = 两个矩形框相交的面积 / 两个矩形框相并的面积
如图:
实现方法:
def IoU(box1, box2, wh = False):
if wh ==False:
# 当使用的不是中心位置坐标表示,分别获取其左上角和右下角坐标
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
# 当使用的是中心点坐标表示时,换成极坐标表示:左上角:中心点 - 高宽一般,右下角:中心点 + 高宽一半
# 第一个框的转换
xmin1, ymin1 = int(box1[0] - box1[2]/2.0), int(box1[1] - box1[3]/2.0)
xmax1, ymax1 = int(box1[0] + box1[2]/2.0), int(box1[1] + box1[3]/2.0)
# 第二个框转换
xmin2, ymin2 = int(box2[0] - box2[2]/2.0), int(box2[1] + box2[3]/2.0)
xmax2, ymax2 = int(box2[0] + box2[2]/2.0), int(box2[1] + box2[3]/2.0)
# 相交框的左上角坐标和右下角,左上角取大,右下角取小
xx1 = np.max([xmin1, xmin2])
yy1 = np.max([ymin1, ymin2])
xx2 = np.min([xmax1, xmax2])
yy2 = np.min([ymax1, ymax2])
# 计算相交框面积
inter_area = (np.max([0, xx2 - xx1])) * (np.max([yy2 - yy1]))
# 计算并的面积 两个框面积-相交面积
area1 = (xmax1 - xmin1) * (ymax1 - ymin1)
area2 = (xmax2 - xmin2) * (ymax2 - ymin2)
uion_area = area1 + area2 - inter_area
return inter_area / (uion_area + 1e-6)
3.1.1 测试IOU方法
-
现在有一张狗的图片,对其设置真实框和预测框,并显示。
-
import matplotlib.pyplot as plt import matplotlib.patches as patches # 真实框与预测框 True_bbox, predict_bbox = [100, 35, 398, 400], [40, 150, 355, 398] # bbox是bounding box的缩写 img = plt.imread('/tmp/pycharm_project_236/dog.jpeg') fig = plt.imshow(img) # 绘制真实框和预测框 fig.axes.add_patch(plt.Rectangle( xy=(True_bbox[0], True_bbox[1]), width=True_bbox[2]-True_bbox[0], height=True_bbox[3]-True_bbox[1], fill=False, edgecolor="blue", linewidth=2)) # 预测框绘制 fig.axes.add_patch(plt.Rectangle( xy=(predict_bbox[0], predict_bbox[1]), width=predict_bbox[2]-predict_bbox[0], height=predict_bbox[3]-predict_bbox[1], fill=False, edgecolor="red", linewidth=2)) -
调用方法计算IOU
IoU(True_bbox, predict_bbox)
-
3.2 mAP(Mean Average Precision)
上一节中IOU只是对定位进行评估,为了衡量定位+分类用AP
mAP是指多个分类任务的AP平均值,而AP是PR曲线下的面积。
-
TP FP FN TN的概念
- TP(True Positive)机器学习中: 被模型预测为正类的正样本的数量 *目标检测中:*IoU > IoU阈值 的检测框数量
- FP (False Positive) 机器学习中: 被模型预测为正类的负样本的数量 *目标检测中:*IoU <= IoU阈值 的检测框数量
- FN (False Negative) 机器学习中: 被模型预测为负类的正样本的数量 *目标检测中:*没有检测到的GT数量
- TN (True Negative) 机器学习中: 被模型预测为负类的负样本的数量 *目标检测中:*不使用
-
查全率 查准率 (精确率 召回率)
-
查准precision:TP/(TP+FP)
-
查全Recall:TP/(TP+FN)
-
其中
all detections是所有预测框,all ground truths是所有GT框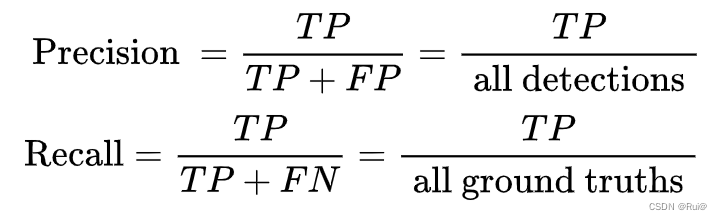
-
-
AP与mAP具体计算过程:
-
初始情况如下:7张图片->15个GT框->24个预测框(A-Y并带有类别置信度)
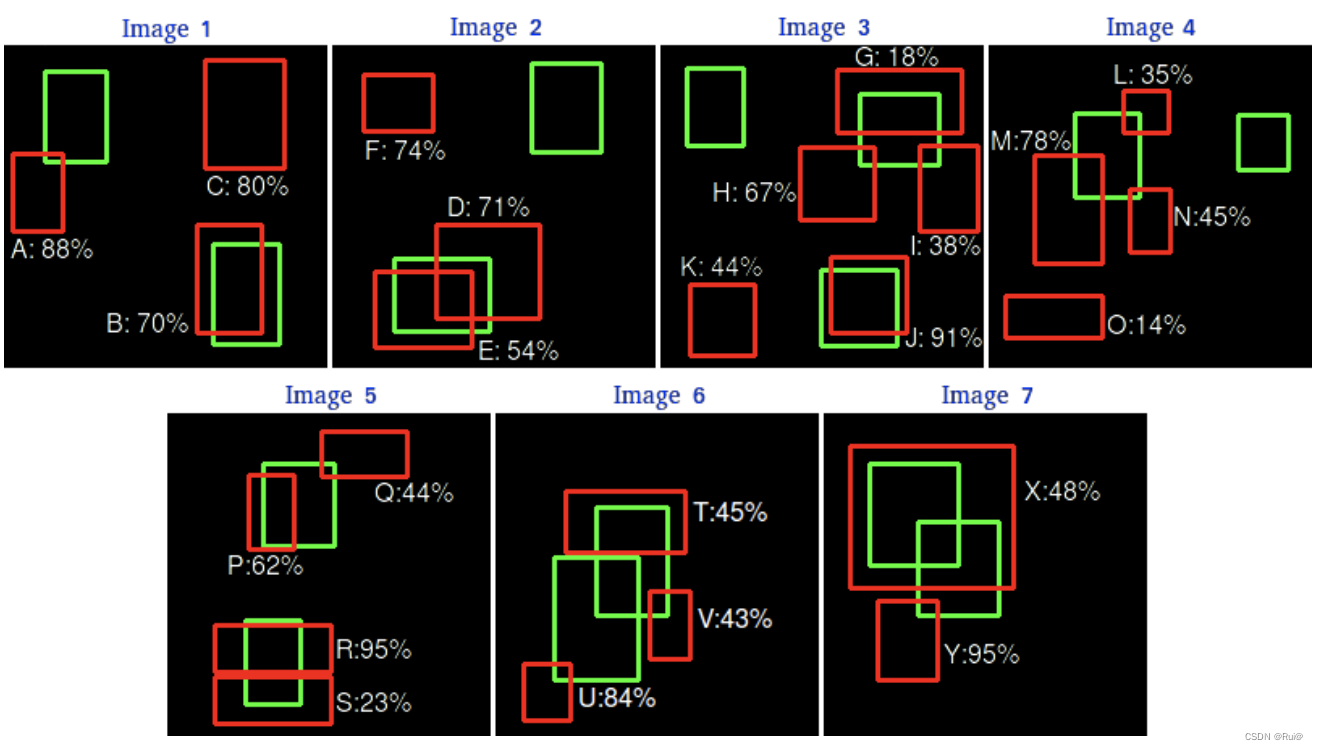
-
定义:预测边框与 GT 的 IOU 值大于等于 0.3 就标记为 TP;若一个 GT 有多个预测边框,则认为 IOU 最大且大于等于 0.3 的预测框标记为 TP,其他的标记为 FP,即一个 GT 只能有一个预测框标记为 TP。第一步:对每张图像每个检测框与GT计算IOU,大于阈值为TP,否则为FP,结果如下图
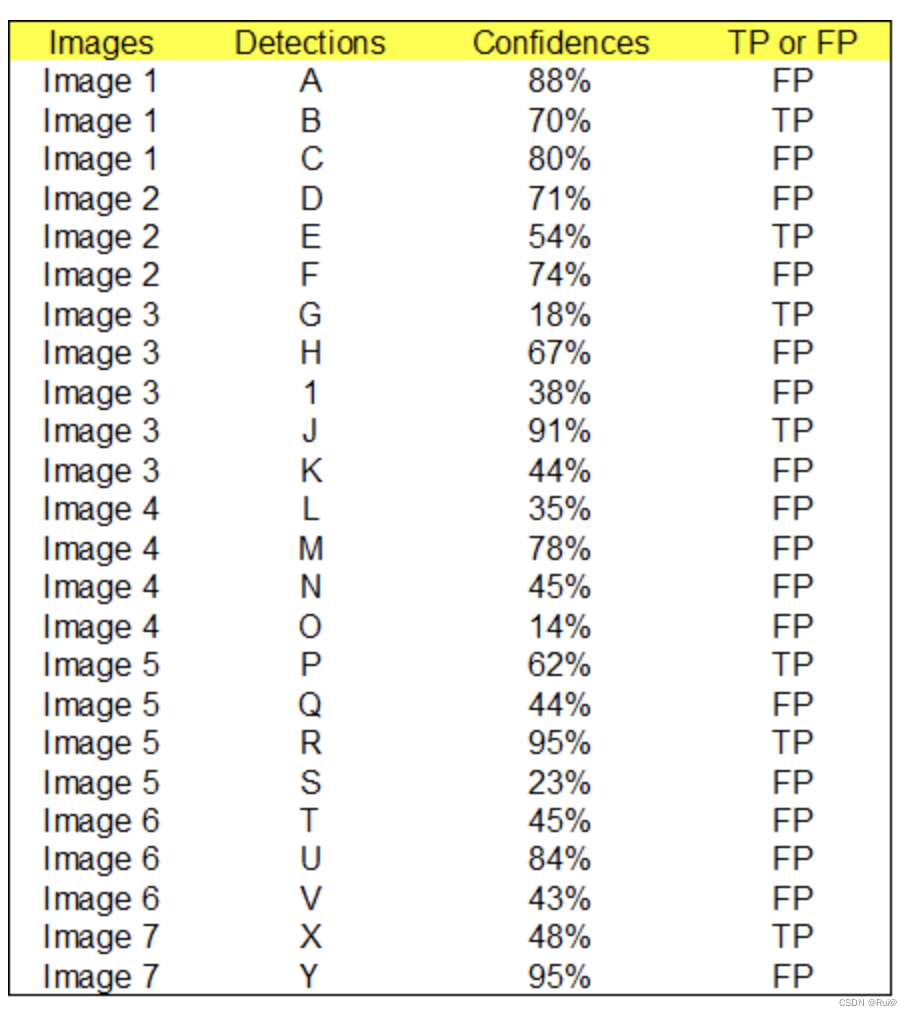
-
第二步,根据类别置信度对预测框进行排序,再逐行计算查准率§和查全率®,如下图
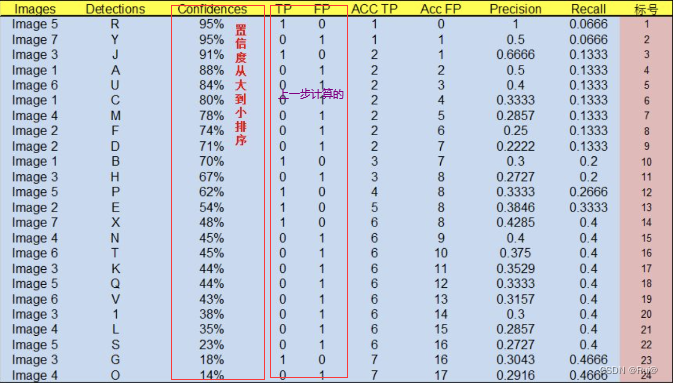
- 第一行的计算:
Precision=TP/(ACC TP+ACC FP)=1/(1+0)=1以及Recall=TP/(TP+FN)=TP/(all ground truths)=1/15=0.0666 - 第二行的计算:
Precision=TP/(TP+FP)=1/(1+1)=0.5以及Recall=TP/(TP+FN)=TP/(all ground truths)=1/15=0.0666 - *其中ACC TP 以及ACC FP的计算:*第一次计算时,R检测框结果为TP,ACC TP累加1为1, ACC FP 不做累加为0。第二次计算时,Y检测框结果为FP,ACC TP不做累加还为1,ACC FP累加为1。依次类推累加,J检测框结果为TP,ACC TP累加为2, ACC FP不做累加还未1。则第三行计算如下
- 第三行的计算:
Precision=TP/(TP+FP)=2/(2+1)=0.6666以及Recall=TP/(TP+FN)=TP/(all ground truths)=2/15=0.1333
- 第一行的计算:
-
第三步,绘制PR曲线,并计算AP(PR曲线下的面积),计算方式有两种,PR曲线绘制如下
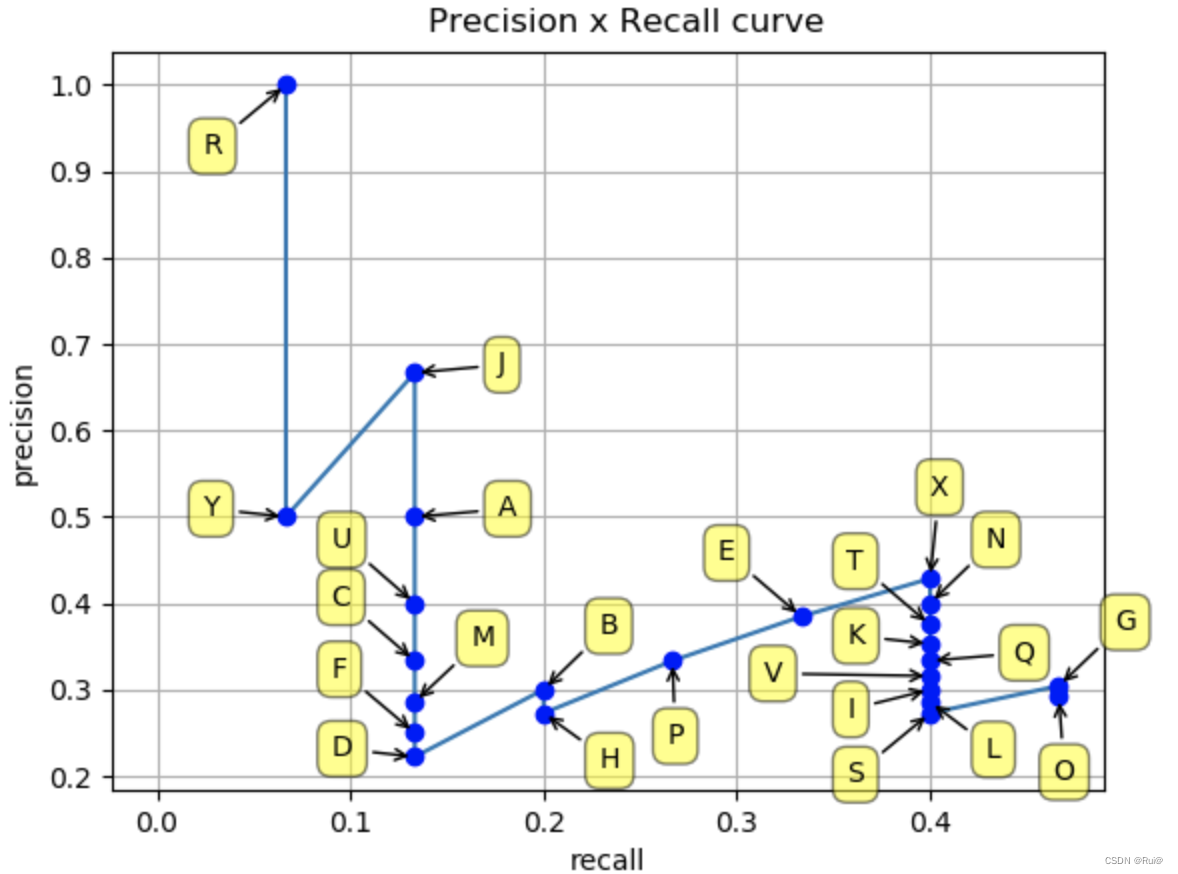
-
VOC2010以前,只需要选取当Recall = 0, 0.1, 0.2, …, 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值,计算结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BNIoXzti-1654485842238)(D:\Desktop\CV_tensorflow笔记\目标检测\图片库\voc10的ap计算结果.png)]](https://i-blog.csdnimg.cn/blog_migrate/ae6c2ead9727a102df37f653ce1c5aed.png)
-
VOC2010以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,通过这类方式选取后PR曲线的变成了如下图的折线(红色部分)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WCUbUocE-1654485842238)(D:\Desktop\CV_tensorflow笔记\目标检测\图片库\VOC10后的折线.png)]](https://i-blog.csdnimg.cn/blog_migrate/d4d57f4f166a0beaaf5a11fddbceef08.png)
然后计算AP变成了计算折线下面积,也变成了计算几个不同长方形的面积和(本例是4个长方形)

-
-
3.3 NMS
目标检测任务中,如RCNN,有2000个预测框,如何得到正确预测的框呢?同时2000个框中也会存在多个框都能表达同一个GT,如何取舍呢?需要用到NMS来筛选出最终的最优结果。
如下图:

-
NMS原理:对于预测框的列表B及其对应的置信度S,选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空。
-
NMS举例:
-
如下图,有A、B、C、D、E 5个候选框

-
进行迭代运算:
- 第一轮:因为B是得分最高的,与B的IoU>0.5删除。则DE被删除,B作为一个预测结果保留到预测结果集合中。
- 第二轮:预测框集合中A得分最高,与A的IoU>0.5删除。则C删除,A最为一个预测结果保留到预测结果集合中。
- 最终筛选出了两个最优结果。
-
-
NMS代码:
import numpy as np def nms(bboxes, confidence_score, threshold): """非极大抑制过程 :param bboxes: 同类别候选框坐标 :param confidence: 同类别候选框分数 :param threshold: iou阈值 :return: """ # 1、传入无候选框返回空 if len(bboxes) == 0: return [], [] # 强转数组 bboxes = np.array(bboxes) score = np.array(confidence_score) # 取出n个的极坐标点 x1 = bboxes[:, 0] y1 = bboxes[:, 1] x2 = bboxes[:, 2] y2 = bboxes[:, 3] # 2、对候选框进行NMS筛选 # 返回的框坐标和分数 picked_boxes = [] picked_score = [] # 对置信度进行排序, 获取排序后的下标序号(argsort返回的下标), argsort默认从小到大排序 order = np.argsort(score) areas = (x2 - x1) * (y2 - y1) while order.size > 0: # 将当前置信度最大的框加入返回值列表中 index = order[-1] #保留该类剩余box中得分最高的一个 picked_boxes.append(bboxes[index]) picked_score.append(confidence_score[index]) # 获取当前置信度最大的候选框与其他任意候选框的相交面积 x11 = np.maximum(x1[index], x1[order[:-1]]) y11 = np.maximum(y1[index], y1[order[:-1]]) x22 = np.minimum(x2[index], x2[order[:-1]]) y22 = np.minimum(y2[index], y2[order[:-1]]) # 计算相交的面积,不重叠时面积为0 w = np.maximum(0.0, x22 - x11) h = np.maximum(0.0, y22 - y11) intersection = w * h # 利用相交的面积和两个框自身的面积计算框的交并比 ratio = intersection / (areas[index] + areas[order[:-1]] - intersection) # 保留IoU小于阈值的box keep_boxes_indics = np.where(ratio < threshold) # 保留剩余的框 order = order[keep_boxes_indics] # 返回NMS后的框及分类结果 return picked_boxes, picked_score
参考资料
- 黑马视频
- https://zhuanlan.zhihu.com/p/107989173

















 1415
1415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









