






swin transformer
摘要
-
旨在将transformer用在所有视觉任务上(之前的vit只是将transformer用在分类任务上)
-
用在视角任务上有两个难点
- large variations in the scale of visual entities
- the high resolution of pixels in images compared to words in text
第一个主要是说:图像中目标对象的大小不一致,例如人和蚂蚁,但是NLP中每个token都是大小固定
第二个主要是说:若使用像素点作为基本单位(token)高分辨率图像计算负担太大。
针对第二个问题,以往的经验是:
- 用经过CNN之后的特征图
- 将图像打成一个一个的patch
- 用小窗口去计算注意力
-
作者提出了a hierarchical Transformer是用Shifted windows实现的
a hierarchical Transformer能提供各个尺度的信息,并且自注意力计算是在窗口内计算的,计算复杂度也下降。同时移动窗口也给带来了cross-window connection.
引言
-
废话-CNN的广泛应用
-
废话-transformer的应用
-
对于摘要中提出的2个问题,以及解决方法做了介绍。
To overcome these issues, we propose a general-
purpose Transformer backbone, called Swin Transformer,which constructs hierarchical feature maps and has linear computational complexity to image size.如图:

- 对于多尺度问题,用了patches merging, 具体地:swin transformer每一层小的patch(灰色格子,原文中patch_size是4**)合并成更大的patch,以此类比CNN中池化下采样增大感受野**。例如:上图中第一层一个红色是4个小patch(patch_size是4),第二次也是4个patch(但是这个patch明显更大,其patch_size是8),第三层4个patch的size是16,越往后感受野越大。其实patches merging主要把上一层中相邻的patch合并成了一个更大的patch
- 对于计算复杂度,主要是red windows,swin transformer只计算红色格子内部的注意力,而每个红色格子内部的灰色格子数量固定,所以计算复杂度也固定,图像大小的增加,只是增加红色格子数量,所以对于复杂度是线性增加的。
-
提到了shift of the window ,本文也说它是最关键的一环。如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tnfsi6BB-1655383025042)(F:\论文\论文\swin transformer\图片\fig2.png)]](https://img-blog.csdnimg.cn/e6cce2ff85fd4c00bc3302a0bb163853.png)
- 主要指出,将图像打成一个个红色窗口进行自注意力计算,是一个孤立自注意力(每个patch只能和同在一个红色窗口的patch计算),没有学习到图像全局的上下文信息。
- 通过移动之后形成的一个个新的红色窗口,一个patch就可以和新的patch进行计算自注意力,也就是摘要中说的cross-window connection。
方法
总体架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oIPTyn4p-1655383025043)(F:\论文\论文\swin transformer\图片\总体架构.png)]](https://img-blog.csdnimg.cn/aacebf68ad184b9a8d3eebe66695fc4d.png)
-
图像输入,大小:H×W×3,举例计算:224×224×3
-
打成pathch,原论文每个patch_size=4。 ( H ÷ 4 ) ( H \div 4) (H÷4) × $ (W \div 4)$个patch,同时每个patch_size为4,有3个通道,则一个patch的维度为= 3 × 4 × 4 3 \times 4 \times 4 3×4×4 =48,举例计算:224/4 = 56-> 56 × 56 × 48
-
Linear Embedding,将每个patch的维度变成transformer能够计算的数值,就算NLP中的词嵌入。这里把patch换成token的形式,同时上图中的C是超参数指定为96。即通过Linear Embedding 后举例计算结果变成:3136 × 96
VIT中patch_size=16,整个patch的数量也才196(224/16的平方),序列长度比较短。
而此处序列长度太长,已经3136,所以此处基于窗口的自注意力计算(red windows,原论文默认有7×7=49个patch)起到作用!!!
-
Swin Transformer Block,如上所说,进行基于窗口的自注意力计算,Transformer是输入序列多长,输出多长。举例计算结果还是:56 × 56 × 96。到此“Stage 1”已经结束。
-
Stage 2 的 Patch Merging,为了有多尺度信息,类比池化操作,则有了此层。简单地:把相邻2个patch合并成一个较大的patch(size=8)。具体地:如下图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WDACbDRs-1655383025044)(F:\论文\论文\swin transformer\图片\patch merge.jpg)]](https://img-blog.csdnimg.cn/0c79717326f5418d8c085cb380e27a3f.jpeg)
把每个windows中相同位置的patch拿出来合并成一个patch,然后在通道上把4个新patch拼接上。
新patch_size=旧patch_size * 2(本文为8),则patch数量=原patch数量/2 则为框架图上的H/4 -> H/8
把4个新patch在通道上拼接,则C=4C,为了和CNN保持一致,下采样2倍,通道数提升2倍,所以此处C=2C
举例计算过程:56/2 = 28,96 * 2 = 192 -> 28 × 28 × 192
-
Stage 2 的 Swin Transformer Block, 和Stage 1 一样的操作,此处的举例计算结果: 28 × 28 × 192
-
Stage 3 和Stage 4同样的操作,都是下采样2倍,通道数提升2倍。举例计算:Stage 3: 14 × 14 × 384 Stage 4: 7 * 7 * 768
-
Swin transformer的最后计算,在VIT中 使用了一个CLS字符,最后也是用CLS字符去进行分类任务,此架构中用了GAP(全局平局池化)获得最后的结果,再去做下游任务。举例计算:1 * 768。
基于窗口的自注意力计算优势
-
对于全局的自注意力计算复杂度为
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Y4ciETd-1655383025044)(F:\论文\论文\swin transformer\图片\全局复杂度.png)]](https://img-blog.csdnimg.cn/ffeec09a8aeb4ea1869f82fe7eb3a8f2.png)
- 一个组token(patch),即一个向量矩阵,会和参数W计算得到 Q K V,(hw,C)x(C,C), 计算复杂度 h w C 2 hwC^2 hwC2有3个,则为 3 h w C 2 3hwC^2 3hwC2
- QK的计算,(hw,C)x(C,hw) 则复杂度为 ( h w ) 2 C (hw)^2C (hw)2C
- 与V的加权计算,QK的计算得到 ( h w ) 2 (hw)^2 (hw)2, 加权计算 ( h w ) 2 ∗ ( h w , c ) (hw)^2 * (hw,c) (hw)2∗(hw,c),复杂度 ( h w ) 2 C (hw)^2C (hw)2C
- 线性投射层 , (hw,C)x(C,C) ,复杂度为 h w C 2 hwC^2 hwC2
- 综上所诉,总复杂度为上图。
-
基于窗口的自注意力计算复杂度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QKt2gJgf-1655383025045)(F:\论文\论文\swin transformer\图片\局部复杂度.png)]](https://img-blog.csdnimg.cn/13f6345166e94e86af8dfa2741802a6e.png)
- 每个窗口相当于一个全局计算,每个窗口大小为 M ∗ M M*M M∗M,则一个窗口的复杂度为 4 M 2 C 2 + 2 M 4 C 4M^2C^2+2M^4C 4M2C2+2M4C
- 一共有 ( H / M ) ∗ ( W / M ) (H/M) * (W/M) (H/M)∗(W/M)个窗口,则总的复杂度为 ( H / M ) ∗ ( W / M ) ∗ ( 4 M 2 C 2 + 2 M 4 C ) (H/M) * (W/M) * (4M^2C^2 + 2M^4C) (H/M)∗(W/M)∗(4M2C2+2M4C)经过化简为上图所示。
移动窗口
The window-based self-attention module lacks connections across windows, which limits its modeling power.
窗口与窗口之间并没有进行注意力的计算,没有全局建模的能力,损失了一定性能。用移动窗口的方式(向右下角移动,窗口patch数的一半),来达到窗口与窗口之间的通信。
如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9EvzhBnl-1655383025046)(F:\论文\论文\swin transformer\图片\fig2.png)]](https://img-blog.csdnimg.cn/6a7427128a5f4e468125120ffa3fc605.png)
原来是4个窗口,窗口内patch数量也一样,但是现在是9个窗口,且每个窗口大小不一致,计算上不能批量计算 。
文中提到最简单的方式是把每个窗口都pad到有16个patch(4*4)的大小,则有9个 4 × 4 4×4 4×4大小的窗口。但是复杂度提升了,之前计算4个窗口,现在计算9个窗口。
论文的解决方案:
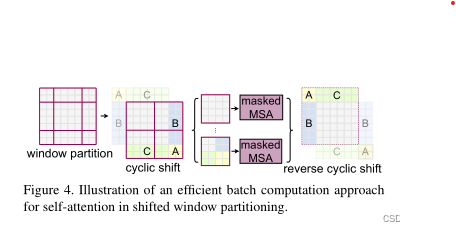
-
如上图将最上面一行的A C移动到最下面
-
再将最左边的B A移动到最右边,形成了上图中的cyclic shift
-
原来的9个大小不一的窗口,变成了cyclic shift中大小相等的4个窗口
-
新问题是:右下角的3个窗口中的ABC是从其他地方搬过来的patch,不应该有太大的联系,不能做自注意力,就比如天空不应该在地面下一样。
-
新问题解决方案:掩码,具体举例如下

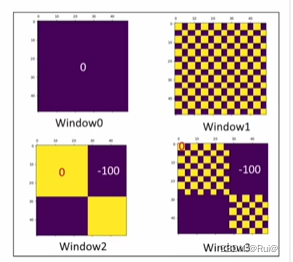
上图是一个经过循环位移的图,一个标准的窗口大小应该是$7×7 $个patch,即0序号的窗口。序号8是A移动后的,2 5 序号是B移动后的, 6 7 序号是C移动后的。
则新的4个窗口分别是 序号0,序号12组合,序号36组合,序号4578组合。
-
以序号36组合的窗口为例

将每个patch拉直成向量,则49个向量,先得到序号3的patch的向量,再得到序号6的patch的向量。之前说过,窗口移动时移动窗口大小(即窗口内patch数)的一半,此处大小为7,一半为3,则序号6的大小为3*7,序号3的大小为 4 ∗ 7 4 * 7 4∗7
则序号3有28个向量,序号6有21个向量
-
将这个窗口做自注意力计算
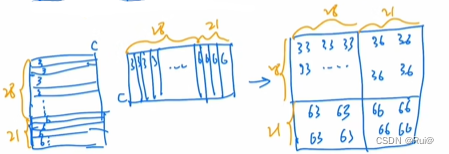
就是一个自注意力,得到最后边的一个自注意力矩阵,图中序号不一致的都是来自不同区域,是不想要的结果。
根据此,设置了一个掩码模板
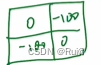
将这个掩码模板和计算所得的自注意力矩阵相加,再经过加权计算后的softmax,可以把不想要的结果变为0。
-
-
总的掩码形式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GcyGxgZN-1655383025052)(F:\论文\论文\swin transformer\图片\mask全模板windosws.png)]](https://img-blog.csdnimg.cn/80892a5b015a48908b28e39e4eb3b054.png)
参考
Swin Transformer论文精读【论文精读】
swin transformer详解
图解Swin Transformer














 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









