






1 MoCo论文阅读
- 题目:Momentum Contrast for Unsupervised Visual Representation Learning
从题目中可以提炼出两个信息:
momentum-动量
Contrast-对比
unsupervised-无监督
1.1 各类监督学习
介绍各类监督学习,本文其实也是用的自监督的方式。
-
有监督:有标签的数据训练
-
无监督:无标签的数据训练
-
半监督:有标签和无标签的数据进行训练,具体是:先用有标签的小规模数据集训练一个teacher模型,再用这个模型对规模较大的无标签数据集预测伪标签,作为student模型的训练数据。
-
自监督:在无标注的数据上训练,通过一个些辅助任务让模型学习到数据的内在表征,再接上下游任务进行微调。
辅助任务:是一个间接任务,并不是真正的任务,只是为了得到数据的特征,以供下游任务使用。CV中常见的辅助任务:图像着色,图像修复,图像的变换,打乱预测顺序。
The term “pretext” implies that the task being solved is not of genuine interest, but is solved only for the true purpose of learning a good data representation.
下游任务:真正的任务。
-
弱监督:用含噪声的有标签数据
1.2 对比学习
对比学习是自监督学习中的一种,另一种是生成式(MAE)。
对比学习是将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。
例如:有3个image(A B C),A和B都是人,C是狗。对比学习并不需要知道AB的类别是人(C是狗),只需要知道A和B是类似的,C和AB都不是类似的,他们在特征上有差距。
对比学习旨在把类似图片的特征拉近,和不相似图片的特征远离。
疑问:虽然对比学习,不需要类别标签,但是它至少还是需要知道那些图片相似,那些图片不相似,简单来说,还是需要相似的标签
为什么对比学习是自监督,而标题中说是无监督?
-
CV领域中对比学习都被认为是无监督方式
-
CV中的定义了很多辅助任务,这些辅助任务可以用来定义那些图片是相似的,那些是不相似的。
以下是一种辅助任务instance discrimination task(个体判别):
有一组图片集合。
从集合中随机选取一张图片 x i xi xi
对 x i xi xi进行裁剪得到 x i 1 xi1 xi1 x i 2 xi2 xi2 并做数据增广,由于得到的$xi1 $ x i 2 xi2 xi2是从同一张图片转换过来,语言信息上不会发生改变,就将其作为正样本。
剩下的所有图片都当作不相似,作为负样本。
可以看出这个代理任务把每张图片当成一类,剩下的图片和他都不是一个类别。
1.3 摘要
-
基于对比学习,但把对比学习看作字典查询任务(
From a perspective on contrastive learning [29] as dictionary look-up,) -
构建了一个动态字典,动态字典由队列和一个移动平均编码器组成。
-
以队列和移动平均编码器组成的字典可以是很大的而且有一致性的
-
这样的字典对无监督的对比学习效果也很好
1.4 引言
-
讲解了以前在CV领域的对比学习工作,其实就是一个字典查询任务
对比学习,通过一些辅助任务,把样本生成一组key,和一个query,去做对比,学习到同类别和不同类别的特征。
The “keys” (tokens) in the dictionary are sampled from data (e.g., images or patches) and are represented by an encoder network. Unsupervised learning trains encoders to perform dictionary look-up: an encoded “query” should be similar to its matching key and dissimilar to others. -
认为字典要大且有一致性
为什么?
大:字典大才可以在高维的连续的视觉空间上抽样—就是说字典越大,里面的K越多,表示的视觉信息越丰富,当用query去与字典里的K做对比时,可以学到把不同物体分开的特征,如果字典太小,K太少,不能很好的泛化。
一致性:字典中的K都应该用相同或者相似的编码器来生成,只有这样才可以保证在与query做对比时,保持一致性。如果每个K是由不同编码器得到,那么用query来查下时,可能会匹配到与query生成使用的编码器相似的K。简单来说,如果用不同编码器,没有保持一致性,在用query对比时,可能比较的就不是比较语义信息相似性,而是去比较编码器的相似性。
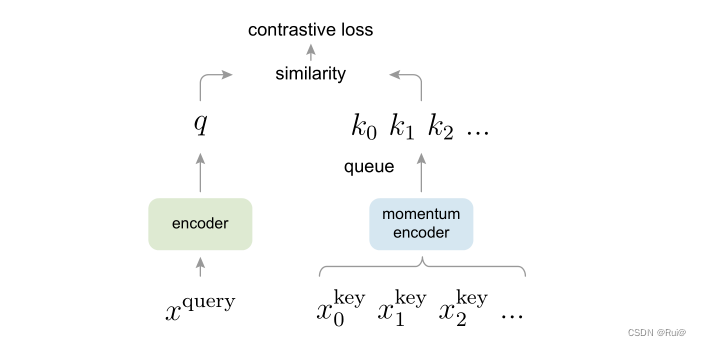
如上图就是MoCo的对比学习流程图,和作者在引言提到的一样,其实就是一个字典查询任务,那本文的创新在哪儿?
-
queue
-
momentum
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tpwkdtgd-1659711818272)(assets/2022-07-07-21-42-00-image.png)]](https://img-blog.csdnimg.cn/724dc17526b643fc9fb6ff3113c83742.png)
为什么要用字典表示队列?
受限于显卡的内存,如果字典太大,要输入很多图片,去更新这个队列,显卡能力不足。用队列先进先出的方式,可以一点一点的去更新字典,不用一次用很大batch_size去更新字典。以这种方式把字典大小和batch_size大小给解耦开来,不用保持相同大小。
为什么用momentum encoder?
如同引言部分提到的一样,要保持一致性。但是采用队列字典之后,每次入队的K,都是和前一个时刻是不同的编码器,就没有保持一致性。所以用动量的方式来更新K的编码器,而不是和Q的编码器一样更新很快。
最开始,K的编码器是从Q复制而来,往后每次更新, k 的编码器 = m ∗ K 上个时刻编码器 + ( 1 − m ) Q 当前时刻编码器 k的编码器 = m * K上个时刻编码器 + (1 - m) Q当前时刻编码器 k的编码器=m∗K上个时刻编码器+(1−m)Q当前时刻编码器
- 提出MoCo只是为对比学习提出一个动态字典的机制,MoCo可以用于不同的辅助任务,同时也表明本文采用了个体判别的任务。
1.5 结论
-
数据集从1百万增加到1亿时,有提升,但是不明显。
-
提出把MoCo和masked auto-encoding的代理任务相结合(就是后面的MAE)
1.6 方法
- 假设模型有编码之后有一个Q和一组K,字典里只有唯一一个K和Q配对。当唯一的K和Q相似时,这个损失函数loss应该是十分小的;当Q和其他K不相似时,loss也应该十分小。反之,若Q和其他K相似时,说明这个模型有问题,需要一个很大的loss去更新参数。本文提出了InfoNCE损失函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rVmpf8F1-1659711818272)(assets/2022-07-07-22-18-09-image.png)]](https://img-blog.csdnimg.cn/76ae7930e98b448d8153bcb54f30dd6c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y6v6LsMe-1659711818273)(assets/2022-07-07-22-20-21-image.png)]](https://img-blog.csdnimg.cn/9252d8cae2d54af4a62df855c176e65d.png)
-
再次提出字典需要大而有一致性
-
以队列方式创建字典,可以重新使用之前batch的K,把batch的大小和字典的大小解耦开来,使得我们可以让字典变得十分大。这种方式,可以随意设置字典大小,当作超参数设置了。队列的先进先出,可以让最早进入队列已经过失的K先出去,这些K本来已经过时,和Q最不相似。
-
用队列方式创建字典,可以让字典变得十分大,但是没有办法去给队列里的元素进行梯度回传了(K的编码器没有办法通过反向传播的方式更新参数)。解决方法:直接把Q的更新好的编码器的复制过来。但是这种方式有个缺点,Q的编码器一直在快速改变,如果K编码器直接复制Q的编码器降低了在其一致性。提出如下图动量的方式。每次更新时,都是大部分依赖于上一次K的编码器,论文也提出,将m参数设置为了0.99。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m6FJexMN-1659711818273)(assets/2022-07-07-22-33-23-image.png)]](https://img-blog.csdnimg.cn/2d8c9414bfb747ae9bb21475a59a3a0e.png)
-
-
提到其他相关工作,主要说明为什么一样是字典查询任务,为什么MoCo脱颖而出?
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7jFxsmsH-1659711818273)(assets/2022-07-07-22-37-26-image.png)]](https://img-blog.csdnimg.cn/0a75c710e98d44d4b69c8419fb6e7852.png)
这种端到端的方式,可以看到能做反向传播,但是字典大小收到局限了(字典大小和batch大小是相等的)
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kbd80kwu-1659711818273)(assets/2022-07-07-22-40-51-image.png)]](https://img-blog.csdnimg.cn/6b01ad43edf5424ca8ebe4896f80bdd8.png)
只有一个编码器Q,K是没有一个单独编码器,把整个数据集特征放到memory bank,再从memory bank中随机抽样当作字典。具体做法:第一次先从memory中抽取样本当作负样本,计算loss,更新Q的编码器,再把刚刚抽取出的样本通过这个新编码器更新特征,再放回memory bank,后面以此类推,所以每次更新都是不同编码器。
所以这种方式不能保证一致性。
-
-
伪代码:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6AYSYFk3-1659711818274)(assets/2022-07-07-22-52-10-image.png)]](https://img-blog.csdnimg.cn/a9d10c797f7c45c492ab0b5edcbb2b08.png)
2 参考资料
MoCo 论文详解_flow筝的博客-CSDN博客_moco论文
【研一小白论文精读】《MoCo》_Titus W的博客-CSDN博客_moco论文
MoCo论文详解_PD我是你的真爱粉的博客-CSDN博客_moco论文
有监督、半监督、无监督、弱监督、自监督的定义和区别_dwqy11的博客-CSDN博客_半监督和无监督
sdn.net/weixin_52185313/article/details/125139327)















 8791
8791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









