







Pytorch:autograd自动求导
- torch.autograd.backward
功能:自动求取梯度
tensors:用于求导的张量,如loss
retain_graph:保存计算图
create_graph:创建导数的计算图,用于高阶求导
grad_tensors:多梯度权重
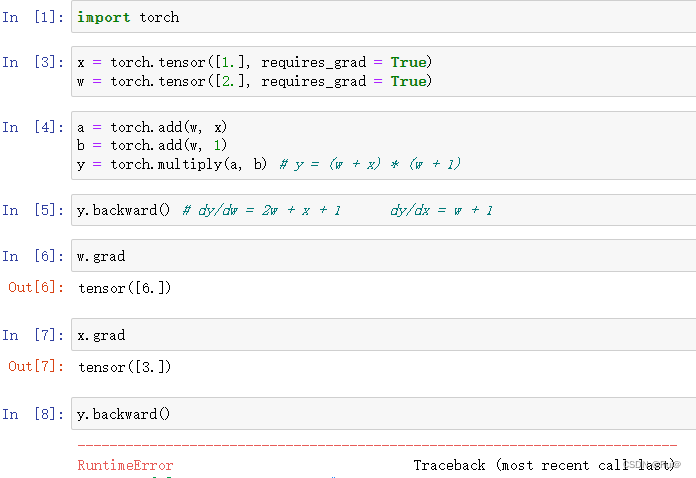
注:当一个张量直接调用backward时,如张量y,y.backward(),其实在源代码中这个张量被用去调用了torch.autograd.backward()方法。同时backward()只可以运行一次,否则将会报错,计算图释放,若是有需求第二次求导,需要在第一次backward时,设置参数retain_graph=True。

- torch.autograd.grad
功能:求取梯度
- outputs:用于求导张量,如loss
- inputs:需要梯度的张量
- create_graph:创建导数的计算图,用于高阶求导
- retain_graph:保存计算图
- grad_outputs:多梯度权重
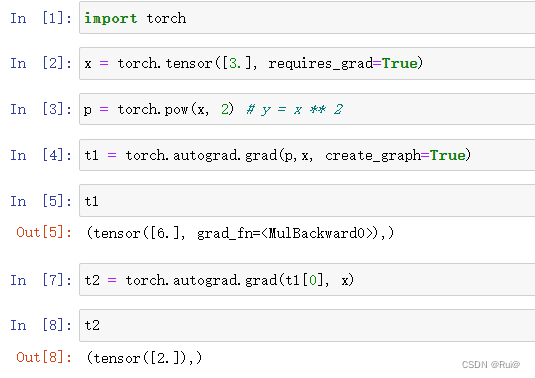
注:多于高阶求导,二阶以上的导数,create_graph=True,必须设置,因为高阶求导,需要创建导数的计算图,才能实现高阶求导
autograd自动求导的注意事项:
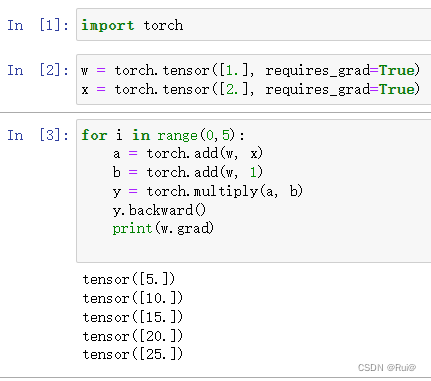
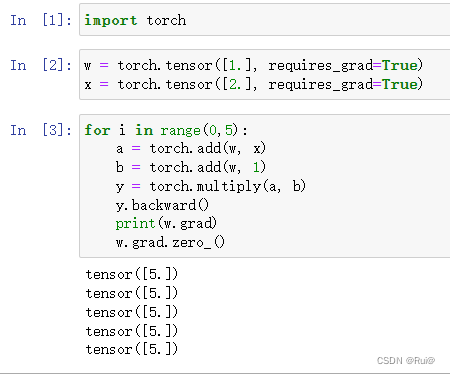
- 梯度不自动清零
通过w.grad.zero_()方法,可以手动归零。zero_有个下划线代表in-place操作
- 依赖叶子节点的节点,requires_grad默认为True
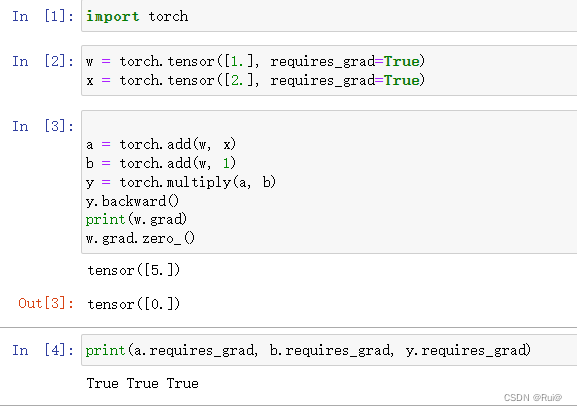
- 叶子节点不可执行in-place
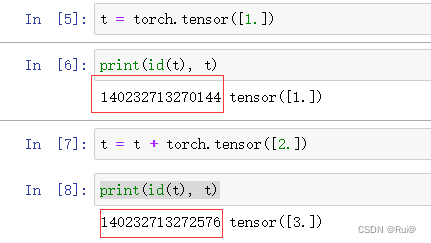
in-place操作代表,在原始内存中去改变这个数据。
如下图中,就不是in-place操作:
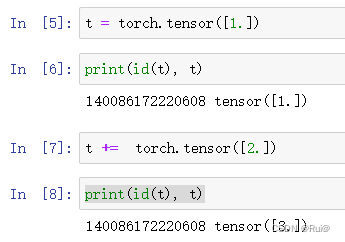
下图为in-place操作:
为什么叶子节点不能使用in-place操作呢?
因为在计算求导时(反向传播),中间节点会依赖叶子节点,需要用到叶子节点的值。所以正向传播时,会先记录叶子节点的地址,到反向传播时,就会根据这个地址去寻找叶子节点的值。如果叶子节点允许in-place操作,那么反向传播时,如果叶子节点的值改变了,这个求导就会出错。















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









