







文章目录
前言
本文是在学习数据分析实战课程中的用户分析、活动分析后,搜集了某办公用品网上商城的真实交易数据,采用RFM模型对电商用户按照其价值进行分层,做了用户画像的描绘和分析,记录了数据预处理、数据可视化和数据建模的全过程,旨在锻炼如何有效切入问题、熟悉分析算法的代码实现以及分析流程的设计等,更好的掌握数据分析的思维。
1. 项目准备
- 语言:Python 3.8
- IDE:Pycharm
- 库:Pandas、Numpy、matplotlib、wordcloud
- 其他工具:EXCEL
2. 数据梳理
本次的样本数据来自和鲸社区,数据集为某办公用品网上商城在2015年1月1日至2018年12月30日间发生的所有网络交易订单信息。
2.1 数据字段梳理
数据集包含一个订单表,字段如下:
订单表:
- 行ID
- 订单ID
- 订单日期
- 发货日期
- 邮寄方式
- 客户ID
- 客户名称
- 客户性别
- 细分(客户类别:公司,小型企业,消费者)
- 城市
- 省/自治区
- 国家
- 地区
- 产品ID
- 类别(商品所属的大类)
- 子类别(商品大类的细分)
- 产品名称
- 销售额
- 数量
- 折扣(购买时给予的折扣:0,0.1,0.2,0.25,0.4,0.6,0.8)
- 利润
2.2 指标梳理
- 结果指标:
- 销售额
- 订单量
- 利润
- 维度:
- 客户 ID
- 订单日期:订单生成的时间(2015年1月1日至2018年12月30日)
- 商品类别(大类:类别,小类:子类别)
- 客户性别
- 细分(客户类别:公司、小型企业、消费者)
3. 数据清洗
3.1 数据加载及预览
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示正负号
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 读取数据
data = pd.read_csv('商城详细销售数据-副本.csv')
data.head()
考虑到在Pycharm控制台中输出,只展示前5行数据,故此处直接截取Excel表格的内容做展示:
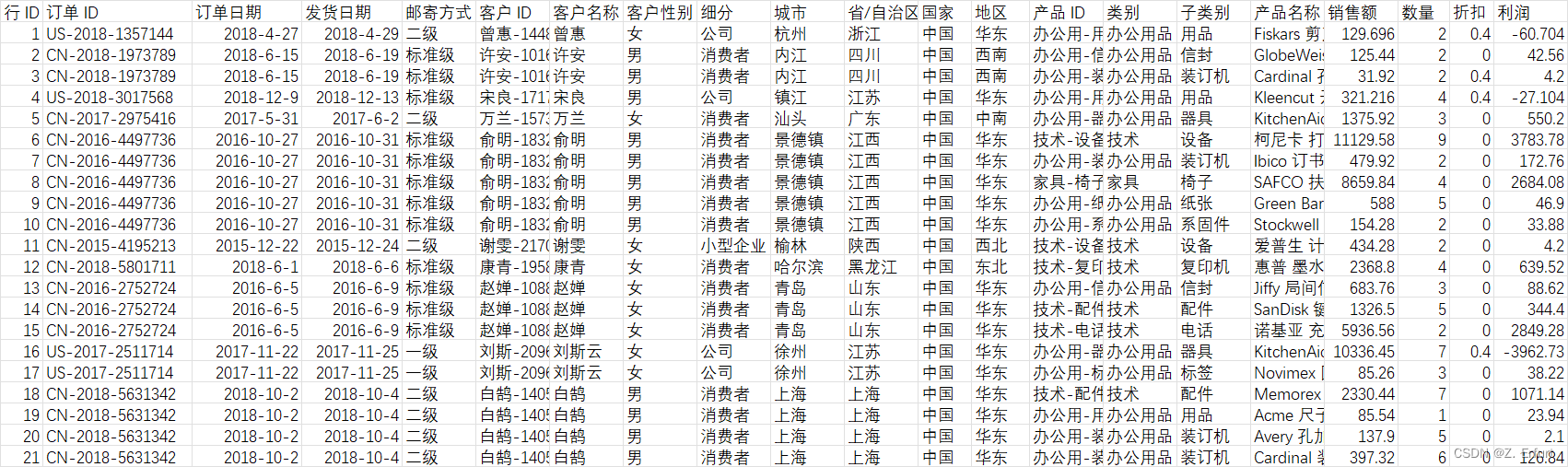
# 查看数据集基本信息
data.info()

3.2 处理缺失值
# 查看缺失值数量和比例
pd.DataFrame({
"NaN_num":r3ound(data.isnull().sum(),2),
"NaN_percent":(data.isnull().sum()/data.shape[0]).apply(lambda x:str(round(x*100,2))+'%')
})
.sort_values("NaN_num",ascending=False)

可以看到,数据集较完好,没有缺失值。因为本文需要对用户做价值分析,所以需要保证客户 ID 不为空。
3.3 处理重复值
# 删除重复值
data.drop_duplicates(inplace=True)
data.shape[0] # 9959
3.4 处理异常值
3.4.1 日期
# 将日期字符串转换成时间格式
data['订单日期'] = pd.to_datetime(data.订单日期,format='%Y/%m/%d %H:%M')
data['发货日期'] = pd.to_datetime(data.发货日期,format='%Y/%m/%d %H:%M')
# 查看是否有日期不在选定范围内
data.query("订单日期 < '2015-01-01' | 订单日期 > '2018-12-30'")
data.query("发货日期 < '2015-01-01' | 发货日期 > '2018-12-30'")
订单日期的查询结果返回Empty DataFrame,说明订单日期全部介于2015-01-01至2018-12-30。
但发货日期查询到有62行数据超出范围,还存在2019年的数据。
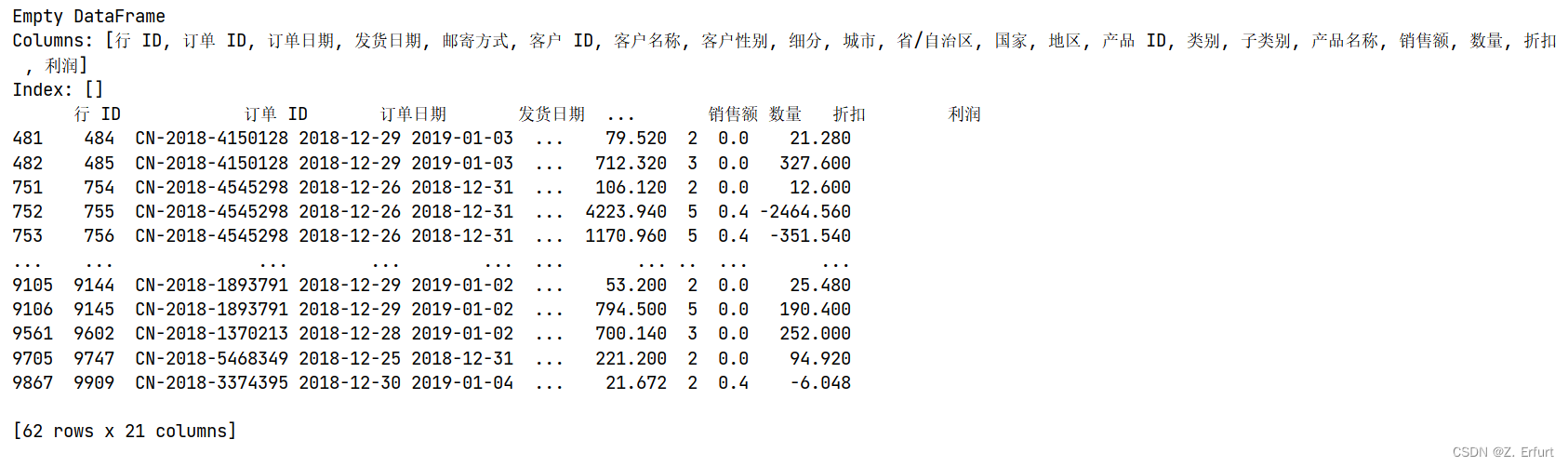
将超出选定时间范围内的数据删除,即删除发货日期大于2018-12-30的数据。
# 将超出统计范围的数据删除
data.drop(data.query("发货日期 > '2018-12-30'").index, inplace=True)
# 验证是否删除
data.shape[0] #现在的数据量是9897, 删除之前是9959, 删除了62条数据
data.query("发货日期 > '2018-12-30'")
再次查询返回Empty DataFrame,说明数据已删除。

3.4.2 销售额、数量、利润
# 描述性统计
print(data[["销售额","数量","折扣","利润"]].describe())
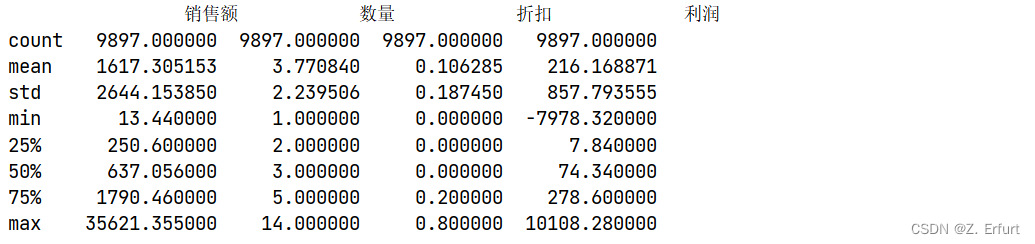
可以看到,利润存在负值。
# 查看利润为负的数量
print("利润为负的数量",data.query("利润 < 0").shape[0])
print(data[["折扣","利润"]].query("利润 < 0").sort_values("折扣",ascending=True))

利润为负的数据共有2024条,可以粗略的看到利润为负的数据的折扣不为0,利润与折扣的关系需要验证。
# 查看折扣为0的订单的利润是否为负
print(data.query("折扣 == 0 & 利润 < 0"))
# 查看折扣不为0的订单的利润是否为正
print(data.query("折扣 > 0 & 利润 > 0"))

第一个查询返回Empty DataFrame,说明折扣为0的订单的销售额均为正。
第二个查询返回了683条数据,说明仍然存在折扣不为0但利润为正的订单。
由此可以得出利润为负的数据不是异常值,是由于商品打折之后得到的销售价小于成本造成的。
为了厘清他们之间的数量关系,使数据更完善,故在原数据上增加两列:商品单价、商品成本。
注:商品成本是某种商品单个的成本,总成本需要乘以数量并根据聚合维度求和。
# 增加商品单价和商品成本
data["商品单价"] = round(data.销售额/(1-data.折扣)/data.数量,2)
data["商品成本"] = round((data.销售额 - data.利润)/data.数量,2)
print(data[["商品单价","折扣","数量","销售额","商品成本","利润"]].head())

销售额 = 商品单价 × (1-折扣) × 数量
利润 = 销售额 - 商品成本 × 数量
4. 用户特征字段创造和词云构建
4.1 RFM模型
4.1.1 R值
# R 最近一次购买的时间
# 计算每个客户最近一次购买的日期
R = data.groupby('客户 ID')['订单日期'].max()
# 计算每位客户最近一次购买距离截止日期的天数 截止日期:2018-12-30
R_days =(data['订单日期'].max()-R).dt.days
# 数据非正态分布,将最近一次购买距离截止日期的天数按中位数分为5层,并依次评分,距离天数越大,得分越低
R_scores = pd.qcut(R_days,q=5,duplicates='drop',labels=[5,4,3,2,1])
R_temp = pd.concat([R,R_days,R_scores],axis=1)
print(R_temp)
第一列是最近一次购买时间,第二列是距离截止日期的天数,第三列是得分。

4.1.2 F值
# F 在统计周期内的消费频次
# 计算每个客户在2015-01-01至2018-12-30的消费次数
F = data.groupby('客户 ID')['订单 ID'].nunique()
# 查看消费次数的占比情况,确定分箱策略
F_data = pd.DataFrame({
'count':F.value_counts(),
'percent':(F.value_counts()/F.value_counts().sum()).apply(lambda x:str(round(x*100,2)) + '%')
}).sort_values('count',ascending=False)
print(F_data)
索引列是消费次数,第一列是某一消费次数出现了多少次,第二列是出现频率。可以看到,消费了4、5、6、7次的最多,合计超过了60%。

# 自定义分箱
F_scores = pd.cut(F,[1,4,6,8,10,F.max()+1],labels=[1,2,3,4,5],right = False)
F_temp = pd.concat([F,F_scores],axis=1)
print(F_temp)
第一列是消费次数,第二列是得分。
4.1.3 M值
# M 购买金额
# 计算每个客户在2015-01-01至2018-12-30的购买金额
M = data.groupby('客户 ID')['销售额'].sum()
# 将购买金额按照中位数分为5层,并依次评分
M_scores = pd.qcut(M,q=5,duplicates='drop',labels=[1,2,3,4,5]) # duplicates='drop' 分箱临界值不唯一,丢弃非唯一
print(pd.concat([M,M_scores],axis=1))
索引列是客户ID,第一列是每个客户所有订单的购买金额求和,第二列是得分。

4.1.4 分值计算
# 合并R、F、M
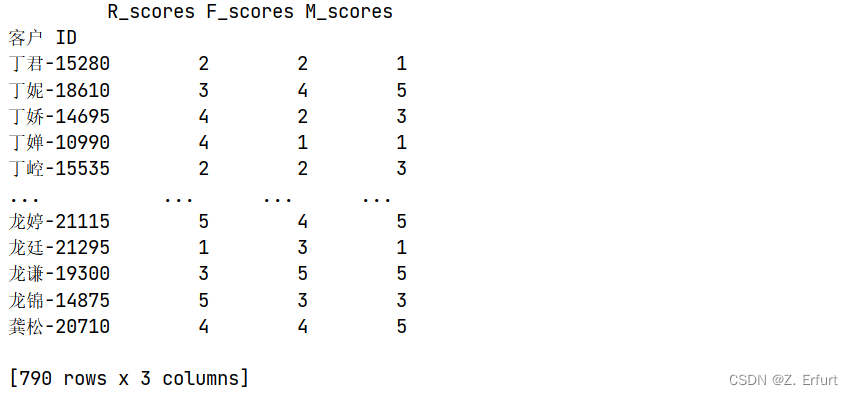
RFM = pd.concat([R_scores,F_scores,M_scores],axis=1)
RFM.columns = ['R_scores','F_scores','M_scores']
print(RFM)
for i in RFM.columns:
RFM[i] = RFM[i].astype(float)
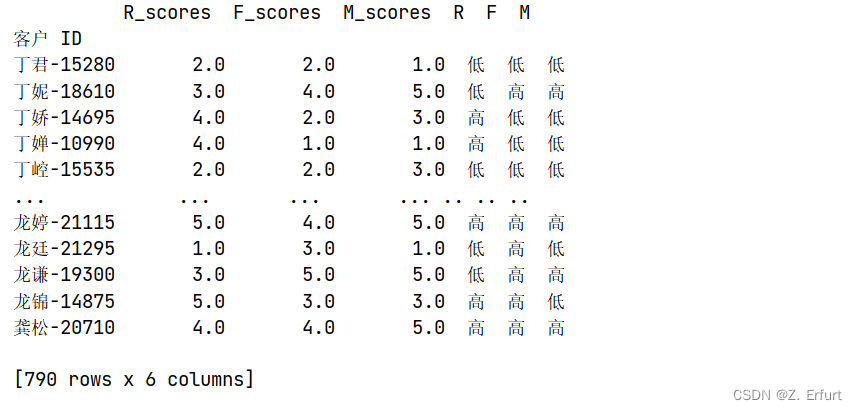
# 将每个值按R/F/M均值的大小分别定义其高低
for i,j in enumerate(['R','F','M']):
RFM[j] = np.where(RFM.iloc[:,i] > RFM.iloc[:,i].mean(),'高','低')
print(RFM)
# 创造综合价值变量
RFM['value'] = RFM['R'] + RFM['F'] + RFM['M']
map_dict = {'高高高':'重要价值客户',
'高低高':'重要发展客户',
'低高高':'重要保持客户',
'低低高':'重要挽留客户',
'高高低':'一般价值客户',
'高低低':'一般发展客户',
'低高低':'一般保持客户',
'低低低':'流失客户'}
RFM['CustomerLevel'] = RFM['value'].map(map_dict)
print(RFM)
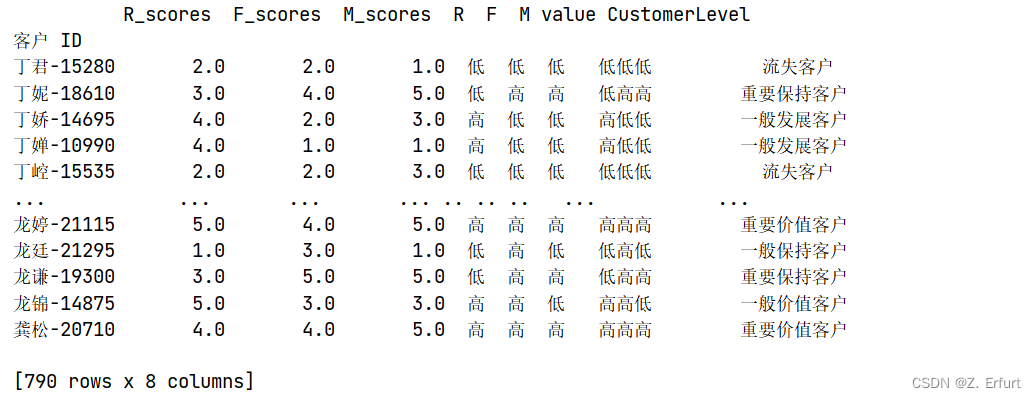
到目前为止,已使用RFM模型完成所有客户的价值分层,客户价值的分析在本文第五节 5.3营销策略制定。
4.2 用户词云
4.2.1 用户特征汇总
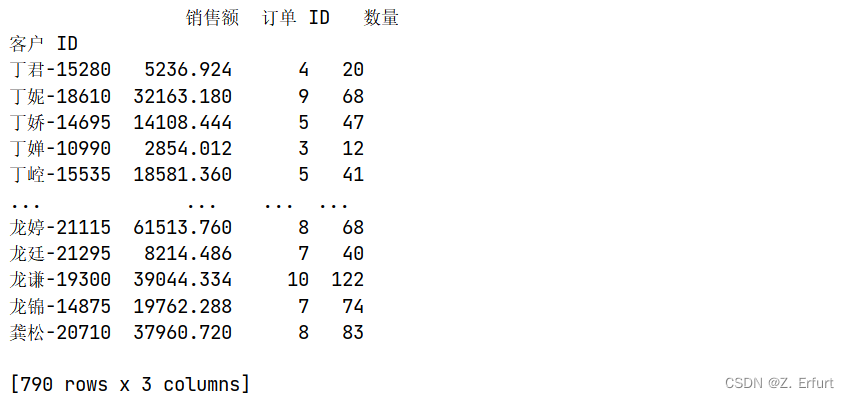
# 计算出每个客户的消费总金额,下单总数,下单的产品总数
data_temp = data.groupby('客户 ID').agg({
'销售额':np.sum,
'订单 ID':'nunique',
'数量':np.sum,
})
print(data_temp)
第一列是消费金额,第二列是下单数,第三列是下单的产品总数
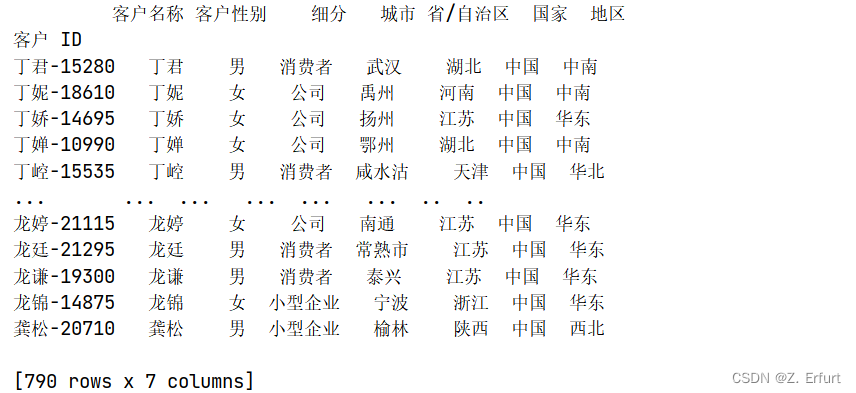
# 提取每个客户的基本信息
data_temp2 = data.groupby('客户 ID')['客户名称','客户性别','细分','城市','省/自治区','国家','地区'].first()
print(data_temp2)
# 将所有客户特征合并,形成客户信息表
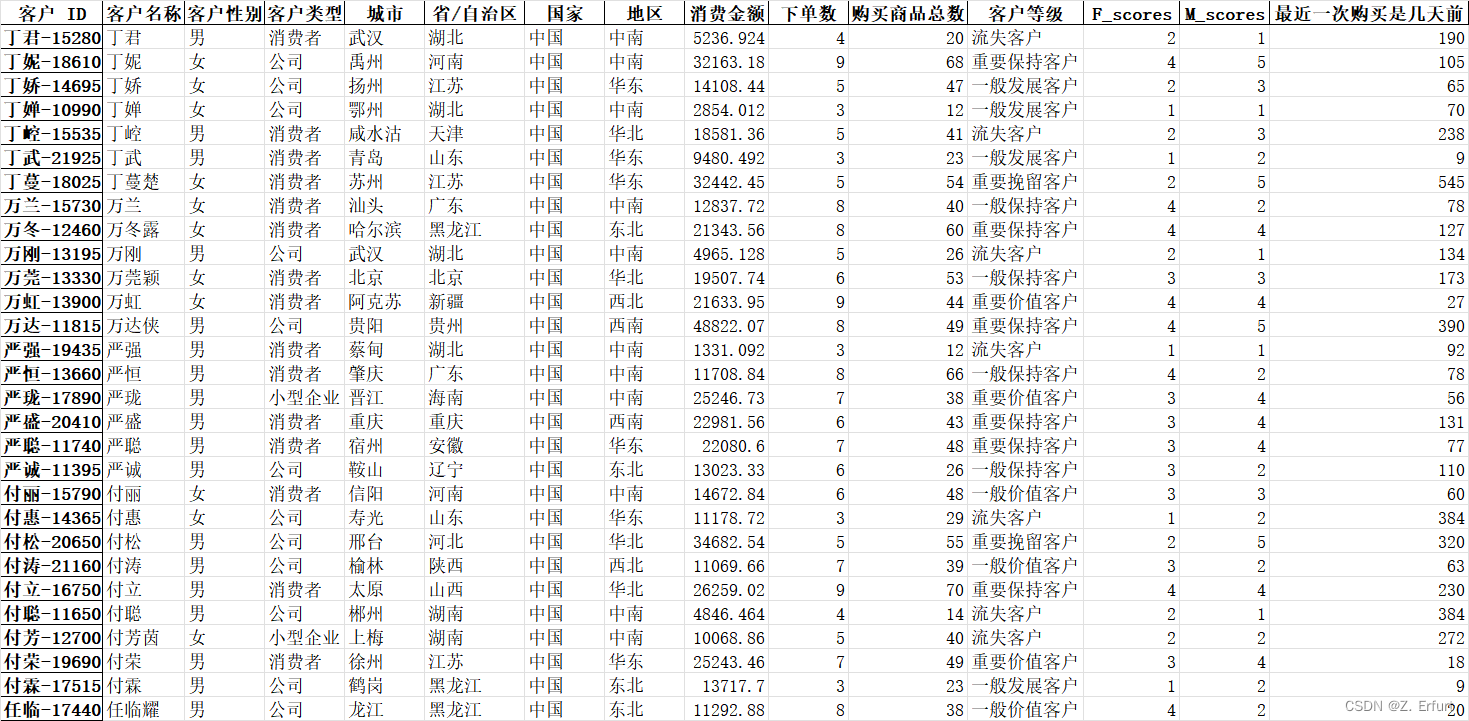
Customer_Info = pd.concat([data_temp2,data_temp,RFM[['CustomerLevel','F_scores','M_scores']],R_days],axis=1)
Customer_Info.columns = ['客户名称','客户性别','客户类型','城市','省/自治区','国家','地区','消费金额','下单数','购买商品总数','客户等级','F_scores','M_scores','最近一次购买是几天前']
print(Customer_Info)
Customer_Info.to_excel('客户信息.xlsx',index=True)
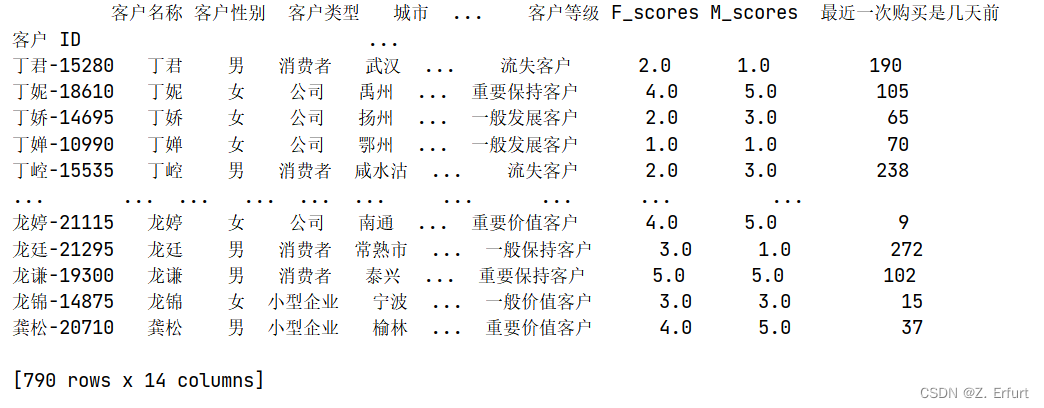
导出为.xlsx表格:
4.2.2 词云构建
from wordcloud import WordCloud
# 从 Customer_Info 中提取词云所要展示的信息
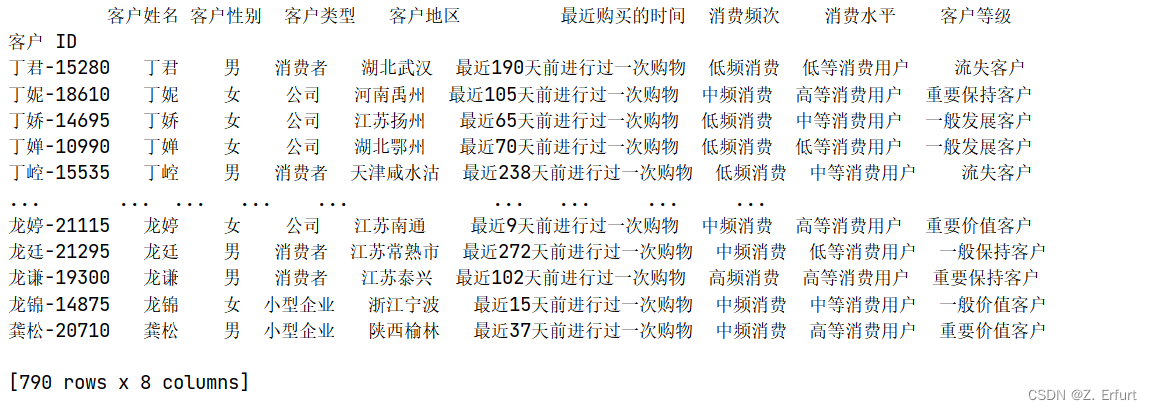
Customer_Profile = pd.DataFrame()
Customer_Profile['客户姓名'] = Customer_Info['客户名称']
Customer_Profile['客户性别'] = Customer_Info['客户性别']
Customer_Profile['客户类型'] = Customer_Info['客户类型']
Customer_Profile['客户地区'] = Customer_Info['省/自治区'] + Customer_Info['城市']
Customer_Profile['最近购买的时间'] = Customer_Info['最近一次购买是几天前'].apply(lambda x:"最近" + str(x) + "天前进行过一次购物")
#消费频次用F的分值计算,1、2:低频消费(不超过5次),3、4:中频消费(5-10次),5:高频消费(10次以上)
Customer_Profile['消费频次'] = Customer_Info['F_scores'].apply(lambda x:'高频消费' if x == 5 else '中频消费' if x > 2 else '低频消费')
#消费水平用M的分值计算,1、2:高等消费,3、4:中等消费,5:高等消费
Customer_Profile['消费水平'] = Customer_Info['M_scores'].apply(lambda x:'高等消费用户' if x == 5 else '中等消费用户' if x > 2 else '低等消费用户')
Customer_Profile['客户等级'] = Customer_Info['客户等级']
print(Customer_Profile)
# 开始绘制用户词云,封装成一个函数来直接显示词云
def wc_plot(df, id_label):
"""
df: 客户特征数据集
id_label: 客户ID
"""
text = df.loc[id_label].values.tolist()
# 设置词云蒙版,男性用“男生头像.png”,女性用“女生头像.png”
if df.loc[[id_label],["客户性别"]].values == [['男']]:
my_mask = imageio.imread("男生头像.png")
else:
my_mask = imageio.imread("女生头像.png")
plt.figure(dpi = 100)
wc = WordCloud(font_path = 'msyh.ttc',
background_color = 'white',
width = 700,
height = 500,
min_font_size=8,
mask = my_mask,
scale = 4, # 默认为1,若生成的词云字体很模糊就将此参数调大
repeat = True # 是否重复 单词较少,重复单词以填满
)\
.generate_from_text(' '.join(text))
# # 若需要从图片中提取配色方案,需要使用color_func 就用下面的方法:
# imgobj = imageio.imread('配色.png')
# image_colors = wordcloud.ImageColorGenerator(np.array(imgobj))
# wc.recolor(color_func=image_colors)
plt.imshow(wc)
plt.axis('off')
plt.savefig(f'./{id_label}的用户画像.png')
plt.show()
# 调用词云函数来绘制用户画像,自行选择客户ID作为入参
wc_plot(Customer_Profile, '丁婵-10990')
丁婵-10990 的画像:

丁婵,女,来自湖北鄂州,是一名公司采购。她最近70天前在本商城进行过一次购物,三年内消费次数不超过5次,属于低频消费客户,消费金额比较低,是低等消费用户,总体来看,属于一般发展客户。
# 调用词云函数来绘制用户画像,自行选择客户ID作为入参
wc_plot(Customer_Profile, '龙谦-19300')
龙谦-19300 的画像:

龙谦,男,来自江苏泰兴,是个体消费者。他最近102天前在本商城进行过一次购物,三年内消费次数在10次以上,并且消费金额比较高,是高频消费和高等消费用户,总体来看,属于重要保持客户。
丁妮-18610 的画像:

丁妮,女,来自河南禹州,是一名公司采购。她最近105天前在本商城进行过一次购物,三年内消费次数在5到10次之间,属于中频消费客户,消费金额比较高,是高等消费用户,总体来看,属于重要保持客户。
# 调用词云函数来绘制用户画像,自行选择客户ID作为入参
wc_plot(Customer_Profile, '龚松-20710')

龚松,男,来自陕西榆林,是一名小型企业采购者。他最近37天前在本商城进行过一次购物,三年内消费次数在5到10次之间,属于中频消费客户,消费金额比较高,是高等消费用户,总体来看,属于重要价值客户。
5. 统计分析
5.1 客户男女比例、类型分析
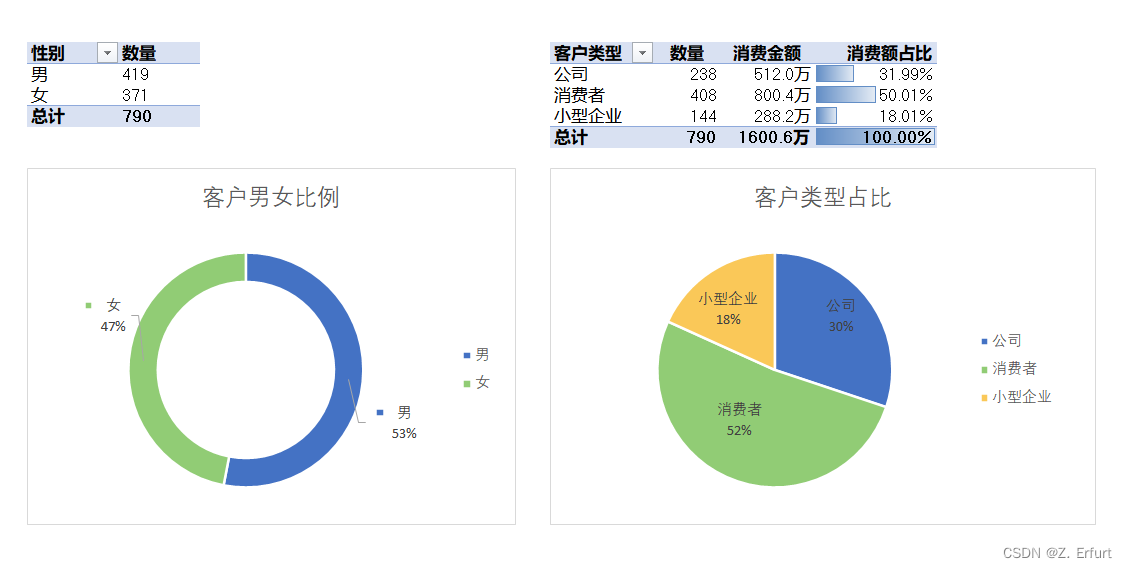
本小节采用Excel数据透视表做可视化,巩固Excel所学。Excel数据透视表功能很强大,数据透视图的图表样式、配色方案也很多,绘制基础图表,零代码岂不美哉~
-
客户结构分析
- ① 商城 53%的客户是男性,47%的客户是女性,男性消费者要多于女性消费者,但比例较均衡,差异不明显。
- ② 商城的客户中,约有二分之一的客户是个体消费者,三分之一的客户是公司采购,五分之一的客户是小型企业批发商。
- ③ 不同类型客户贡献的消费额与客户数量占比一致。
5.2 订单分布分析

-
各地区订单分布情况:
- ① 订单主要分布在华东地区、中南地区和东北地区,三者合计占比为73%。
- ② 西北地区的订单量最少,占比最小,仅有5%。 各省订单分布情况:
- ① 订单量排行前十的省份依次是山东、广东、辽宁、黑龙江、江苏、湖北、河南、湖南、浙江、四川,以东部沿海地区居多。 建议:
- ① 商城广告的投放地区应优先选择 华东地区、中南地区和东北地区, 东部沿海一带的省份是推广重点。
- ② 山东、广东、辽宁、黑龙江、江苏、湖北、河南、湖南、浙江、四川 这几个省份的单量靠前, 资源可适当倾斜于这几个省份。
5.3 商品分析
5.3.1 各品类商品销量、销售额、利润分析
用数据透视表+时间切片器做数据汇总,得出2015年-2018年各品类商品的销量、销售额、利润,如下图所示:
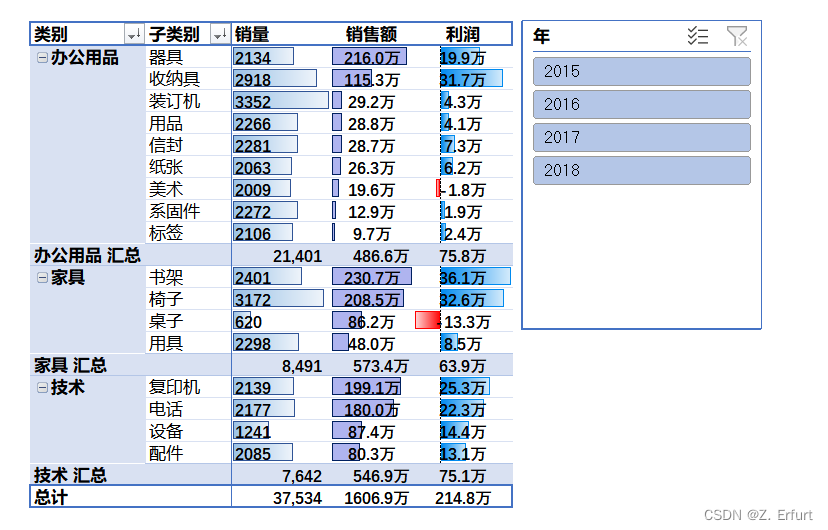
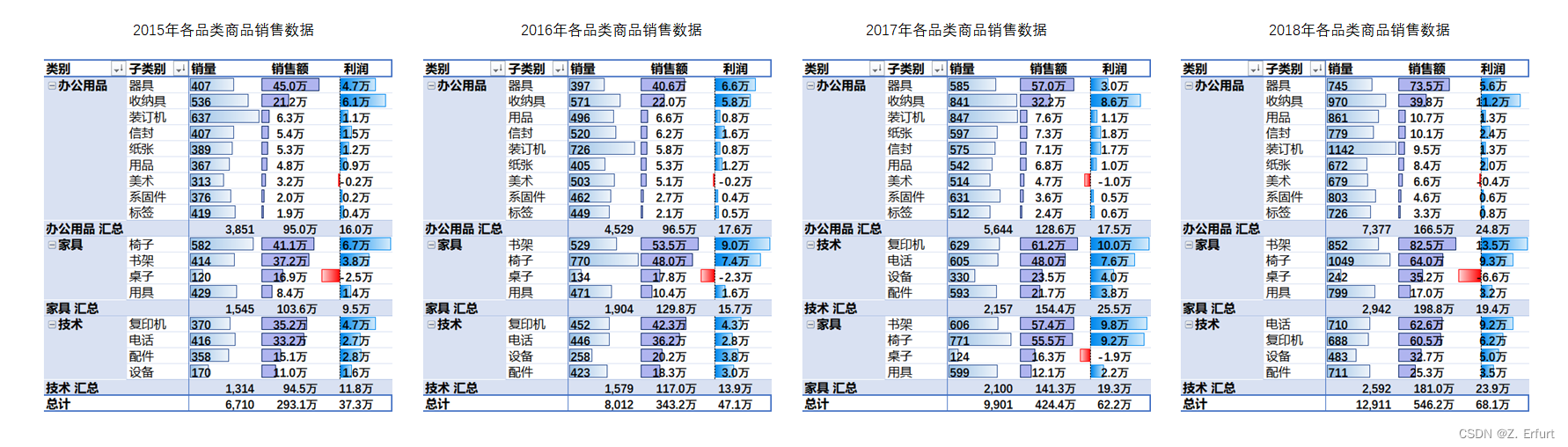
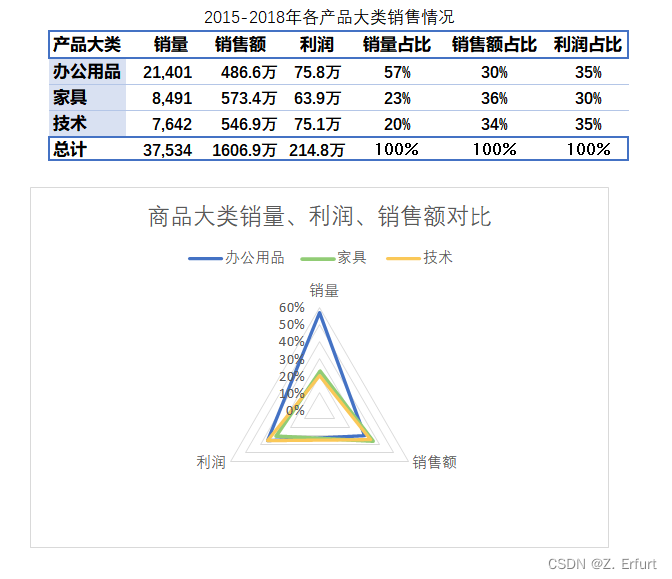
- 商城在售的商品共分为三大类:办公用品、家具和技术类。
- 2015-18年中,总销量占比最高的是办公用品大类,达到了57%。
- 办公用品类商品是商城的主推产品,客户需求量大,日常需关注安全库存量和供应链情况,避免出现缺货。
- 家具类产品的销售额占比最大,但利润占比最低。
- 技术类产品的销量最低,销量占比仅有20%,但利润占比达到了35%。
- 技术类产品销量低,但在销售额和利润上都有不错的表现,建议从技术类产品中挑选引流产品,增加此类商品的广告投放,提高曝光率,从而提升毛利。
5.3.2 挑选爆品
不论是在平台上经营店铺还是经营一个独立站(自建站),要想获得高流量、高利润,就离不开核心商品的把控。我们把商品分为爆款、引流款、利润款三个层次,爆款,顾名思义就是非常火爆的产品,高流量、高曝光度、高订单量是它的代名词。爆款商品虽然可能不是利润的主要来源,但是可以给平台内的其他商品带来关联流量。
一般爆款产品都具有以下几个因素:
- 没有库存积压的压力
- 市场潜力大,利润率高
- 具有独特性/创意性
- 能带来较高流量
- 销售周期长
- 具有话题性、趣味性,有利于口碑传播
选品首先就是要选择市场需求量大的产品,其中最好是刚需产品。因为刚需产品的市场消费群体已经十分庞大,不需要再花时间和精力去挖掘潜在用户群,且其潜在用户群是聚集的,用户购买是从需求出发购买而不是从个人喜好出发,成交会更容易,用户的转化率会更高,也更易于打造爆款。
上一小节 5.3.1 已分析出本商城办公用品大类的市场需求量最大,因此本小节讨论如何在办公用品类商品中挑选出爆款。
首先,在办公用品中,四年来销售额稳居前五的品类从高到低依次是器具、收纳具、装订机、用品、信封。爆款将在这五个品类中选择。
其次,排除这五类商品中的季节性商品,此类商品更新换代快,容易产生库存积压。
绘制2015年-2018年器具、收纳具、装订机、用品、信封的每月销量趋势图。
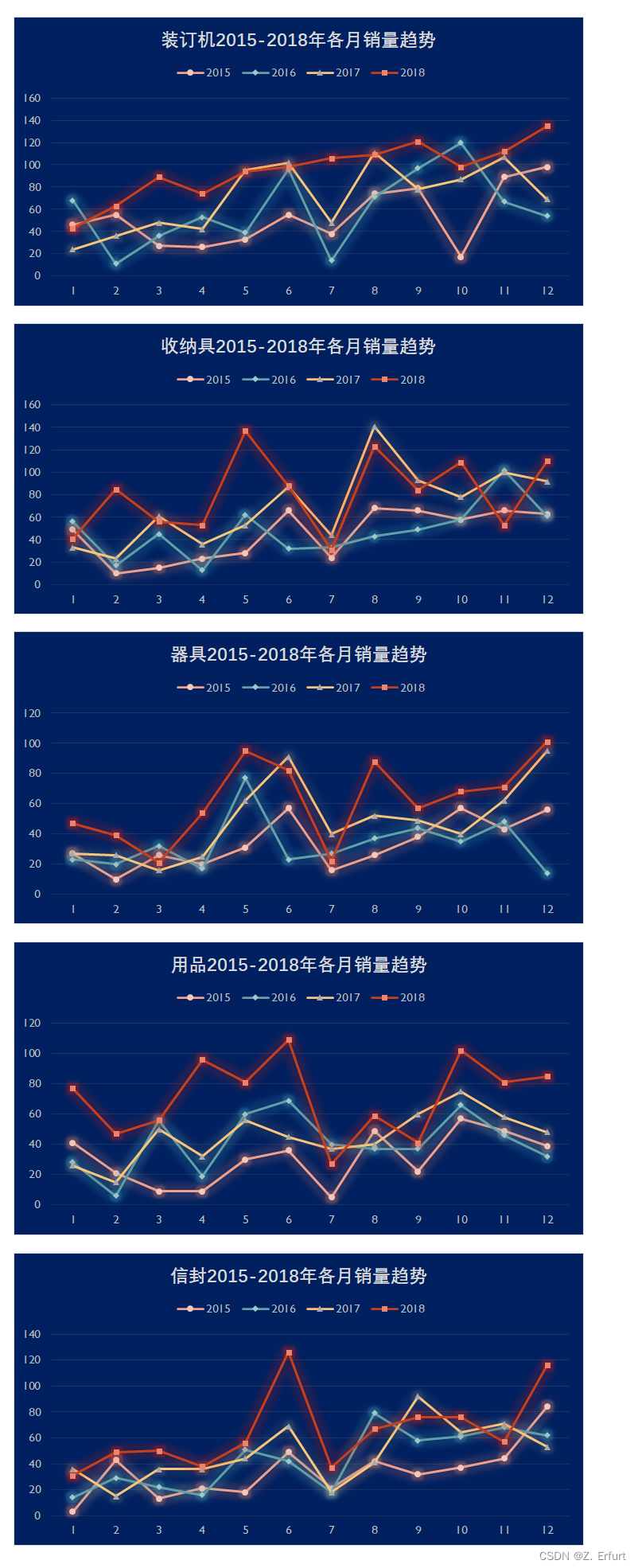
-
观察器具、收纳具、装订机、用品、信封的每月销量趋势图,可以发现:
- ① 装订机的销量呈现逐月上涨、逐年递增的趋势,并且波动较小,并未出现攀升至高峰然后断崖式下降情况。
- ② 收纳具、用品虽然销售额可观,但是近三年来销售趋势呈现每月增减交替的现象,每月销量差异约为20单。 结论
-
综合来看,装订机销量随时间变化较小,库存积压风险小,并且暂未出现过断崖式增长后下降的情况,能有效把控安全库存,同时在销售额、利润方面表现良好,故选择装订机作为爆款,下面讨论选择哪一款装订机作为爆款。

- 销量平均值为5,取销量大于平均值的品牌。
- 取销售额排名靠前的品牌, 即销售额>4000的品牌可满足销售额排名在前7%。
- 设利润率阈值为10%, 舍弃利润率过低的产品。
最终可以得到以下11款产品作为爆品候选:
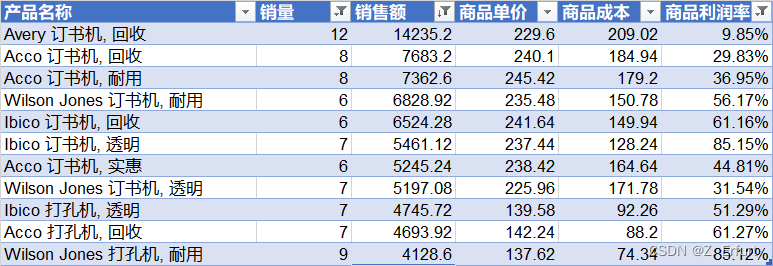
5.3 营销策略制定
5.3.1 用户价值分析
本文第四节 4.1 RFM模型 已经对所有用户进行了价值分层, 各项指标如下:
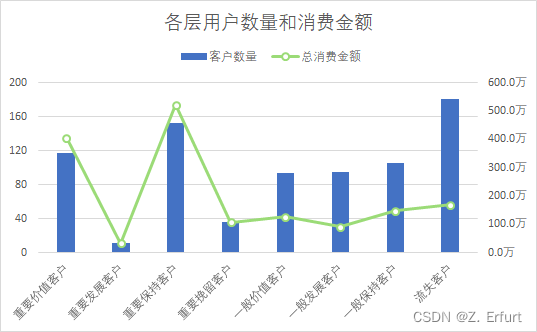
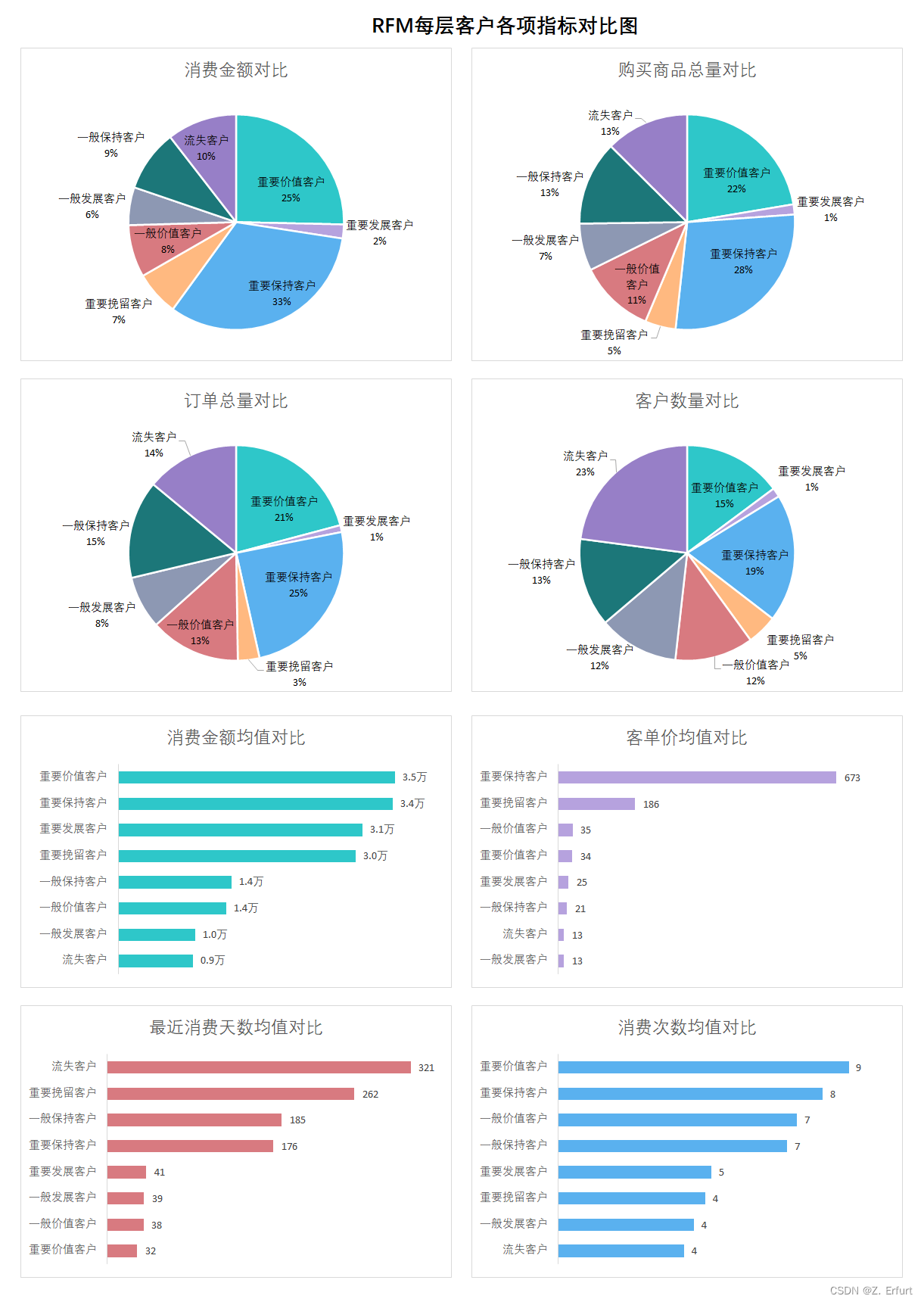
| R | F | M | 客户等级 | 行为特征 | 营销策略 |
|---|---|---|---|---|---|
| 高 | 高 | 高 | 重要价值客户 | 近期购买过,购买频率高,消费高, 是主要消费客户 | 升级为VIP客户,建立单独的社群,提供个性化服务,倾斜较多的资源,保障留存率 |
| 高 | 低 | 高 | 重要发展客户 | 近期购买过, 购买频率低,消费较高, 此层级的客户数量很少,但消费水平高,可能是新的批发商或企业采购 | 提供会员积分服务,给予一定程度的优惠来提供高留存率 |
| 低 | 高 | 高 | 重要保持客户 | 近期没有购买,购买频率高,消费较高,客单价很高,是主要消费群体 | 通过短信、邮件等方式来介绍新产品/功能, 发放红包/优惠券等来唤醒此部分用户,促进消费 |
| 低 | 低 | 高 | 重要挽留客户 | 近期没有购买,购买频率低,消费高 | 通过短信、邮件、电话等介绍最新产品/功能/升级服务促销折扣等,避免流失 |
| 高 | 高 | 低 | 一般价值客户 | 近期购买过,购买频率高,消费低 | 潜力股, 提供社群服务,介绍新产品/功能促进消费 |
| 高 | 低 | 低 | 一般发展客户 | 近期购买过,购买频率低,消费低,客单价低,可能是新客户,个体消费者居多 | 提供社群服务,介绍新产品/功能,提供折扣等提高留存率, 制定计划时可与重要发展客户一致,但资源分配时优先考虑重要发展客户 |
| 低 | 高 | 低 | 一般保持客户 | 近期没有购买,购买频率高,消费低 | 介绍新产品/功能等方式唤起此部分用户 |
| 低 | 低 | 低 | 流失客户 | 近期没有购买,购买频率低,消费低,已流失 | 促销折扣等方式唤起此部分用户,当资源分配不足时可以暂时放弃此部分用户 |
6. 总结
-
推广建议:
-
① 商城广告的投放地区应优先选择华东地区、中南地区和东北地区,东部沿海一带的省份是推广重点。
-
② 山东、广东、辽宁、黑龙江、江苏、湖北、河南、湖南、浙江、四川 这几个省份的单量靠前,资源可适当倾斜于这几个省份。
爆品选择:
-
一般爆款产品都具有以下几个因素:
- 没有库存积压的压力
- 市场潜力大,利润率高
- 具有独特性/创意性
- 能带来较高流量
- 销售周期长
- 具有话题性、趣味性,有利于口碑传播
-
建议从下面11款产品中挑选爆品:
| 产品 ID | 产品名称 |
|---|---|
| 办公用-装订-10002836 | Avery 订书机, 回收 |
| 办公用-装订-10001062 | Acco 订书机, 回收 |
| 办公用-装订-10000416 | Acco 订书机, 耐用 |
| 办公用-装订-10004615 | Wilson Jones 订书机, 耐用 |
| 办公用-装订-10001078 | Ibico 订书机, 回收 |
| 办公用-装订-10003676 | Ibico 订书机, 透明 |
| 办公用-装订-10002471 | Acco 订书机, 实惠 |
| 办公用-装订-10002580 | Wilson Jones 订书机, 透明 |
| 办公用-装订-10000749 | Ibico 打孔机, 透明 |
| 办公用-装订-10004255 | Acco 打孔机, 回收 |
| 办公用-装订-10002575 | Wilson Jones 打孔机, 耐用 |
不同等级客户的营销策略:
| R | F | M | 客户等级 | 行为特征 | 营销策略 |
|---|---|---|---|---|---|
| 高 | 高 | 高 | 重要价值客户 | 近期购买过,购买频率高,消费高, 是主要消费客户 | 升级为VIP客户,建立单独的社群,提供个性化服务,倾斜较多的资源,保障留存率 |
| 高 | 低 | 高 | 重要发展客户 | 近期购买过, 购买频率低,消费较高, 此层级的客户数量很少,但消费水平高,可能是新的批发商或企业采购 | 提供会员积分服务,给予一定程度的优惠来提供高留存率 |
| 低 | 高 | 高 | 重要保持客户 | 近期没有购买,购买频率高,消费较高,客单价很高,是主要消费群体 | 通过短信、邮件等方式来介绍新产品/功能, 发放红包/优惠券等来唤醒此部分用户,促进消费 |
| 低 | 低 | 高 | 重要挽留客户 | 近期没有购买,购买频率低,消费高 | 通过短信、邮件、电话等介绍最新产品/功能/升级服务促销折扣等,避免流失 |
| 高 | 高 | 低 | 一般价值客户 | 近期购买过,购买频率高,消费低 | 潜力股, 提供社群服务,介绍新产品/功能促进消费 |
| 高 | 低 | 低 | 一般发展客户 | 近期购买过,购买频率低,消费低,客单价低,可能是新客户,个体消费者居多 | 提供社群服务,介绍新产品/功能,提供折扣等提高留存率, 制定计划时可与重要发展客户一致,但资源分配时优先考虑重要发展客户 |
| 低 | 高 | 低 | 一般保持客户 | 近期没有购买,购买频率高,消费低 | 介绍新产品/功能等方式唤起此部分用户 |
| 低 | 低 | 低 | 流失客户 | 近期没有购买,购买频率低,消费低,已流失 | 促销折扣等方式唤起此部分用户,当资源分配不足时可以暂时放弃此部分用户 |
项目经验:
初学数据分析,每一个结论的产生、每一个图表的完成,对我来说都弥足珍贵。
本文由于缺乏页面访问量、跳出率、投资回报率、客户购买时间等,无法进一步分析消费者偏好、给出职能人员资源分配建议等,实在遗憾。客户分层时只尝试了RFM模型, 没有进一步基于RFM加权得分,今后会根据不同的业务场景灵活的调整比重来划分客户层级,使分析结果更符合业务现状。














 3664
3664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









