







对哈希表的理解:定义一个通用的算法,对于每一个输入的key值进行处理,得到一个value值并存储,每个key值对应一个value值,
- 哈希函数:能够将集合中任意可能的元素映射到一个固定范围的整数值,并将该元素存储到整数值对应的地址上。
- 冲突处理:由于不同元素可能映射到相同的整数值,因此需要在整数值出现「冲突」时,需要进行冲突处理。总的来说,有以下几种策略解决冲突:
- 链地址法:为每个哈希值维护一个链表,并将具有相同哈希值的元素都放入这一链表当中。
- 开放地址法:当发现哈希值 hh 处产生冲突时,根据某种策略,从 hh 出发找到下一个不冲突的位置。例如,一种最简单的策略是,不断地检查 h+1,h+2,h+3,\ldotsh+1,h+2,h+3,… 这些整数对应的位置。
- 再哈希法:当发现哈希冲突后,使用另一个哈希函数产生一个新的地址。
- 扩容:当哈希表元素过多时,冲突的概率将越来越大,而在哈希表中查询一个元素的效率也会越来越低。因此,需要开辟一块更大的空间,来缓解哈希表中发生的冲突
最一般的构造方法是除留余数法,例如对一组int型数据的处理,key是输入的int数据,value是数据在哈希数组里的对应值,例子如下,value为key值除以12的余数

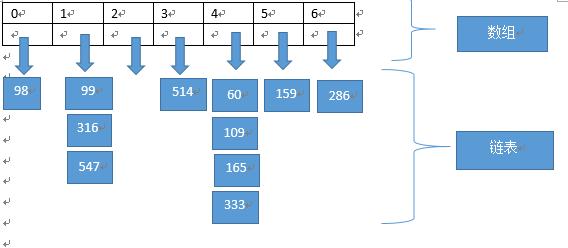
代码:哈希表的创建,输入的key值的范围为1— ,为了避免冲突,将除数取为质数,这里取1009(大于1000的第一个质数)。并采用如下图的连地址法,创建一个长度为1009的vector数组,数组内的元素为链表。
class MyHashSet {
private:
vector<list<int>> data;
static const int base = 1009;
static int hash(int key) {
return key % base;
}
public:
/** Initialize your data structure here. */
MyHashSet(): data(base) {}
void add(int key) {
int h = hash(key);
for (auto it = data[h].begin(); it != data[h].end(); it++) {
if ((*it) == key) {
return;
}
}
data[h].push_back(key);
}
void remove(int key) {
int h = hash(key);
for (auto it = data[h].begin(); it != data[h].end(); it++) {
if ((*it) == key) {
data[h].erase(it);
return;
}
}
}
/** Returns true if this set contains the specified element */
bool contains(int key) {
int h = hash(key);
for (auto it = data[h].begin(); it != data[h].end(); it++) {
if ((*it) == key) {
return true;
}
}
return false;
}
};















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









