







Deep RL agents for TE
一、 前言
这篇文章选于ICNP2020,作者将深度强化学习方法用于流量工程问题,能够实现multi-region网络的全局优化,并能够适应高维、动态变化的网络。在看这篇文章之前,我未曾深入的了解过强化学习。但在这篇文章之后,我觉得相见恨晚,常说多智能体协同,而未曾听说强化学习中的agent就具有智能体的含义,这是一种损失。之前,我尝试将遗传算法和神经网络相结合以解决某些控制问题,这篇文章也给了我一些新的思路。
二、 文章概述
对于multi-regionTE问题的解决方法可以大致分为两类,一类是Traditional model-based routing,另一类是Data-driven routing。作者的方法属于第二种,结合了RL强化学习和DNN深度神经网络。(在此,我不带入任何一方的观点来评价哪种方法更好,而是客观阐述作者如何解决问题。)为了解决多区域问题,作者选择为每一种区域设置两种agent:T-agent负责terminal demand,O-agent负责outgoing demand。其中,terminal demand的destination node在当前区域,outgoing demand的destination node在其他区域。同时,两者(agents)的输入采用edge utilization代替传统RL方法的TM,可以加快收敛速度。T-agent的reward function只和当前region有关,O-agent的reward不仅与当前region有关,还和其他的区域相关。因为outgoing demand可能会造成相邻区域的拥塞。区分T-agent和O-agent的方法可以减少区域间的通信开销。
三、 算法设计
为了减少decision space,作者采用了预计算forwarding paths和区分mice flow及elephant flow的方法,这在下面介绍T-agent和O-agent的设计时,会集中体现。
T-agent
- input

- 当edge failure发生时,edge utilization为0.
- action
- 区分mice flow和elephant flow,mice flow使用static routing(ECMP),agent只学习并调整elephant flow,预计算每对ingress node to egress node的K条转发路径(K=3较好,K>3计算消耗大)。T-agent学习的是路径上的流量分割比率。
- reward
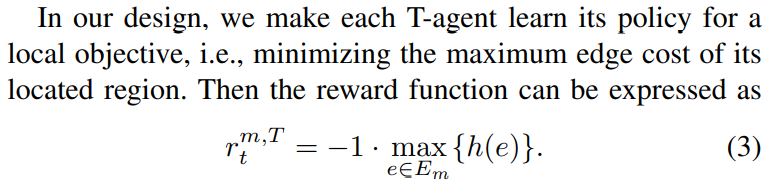
O-agent
- input
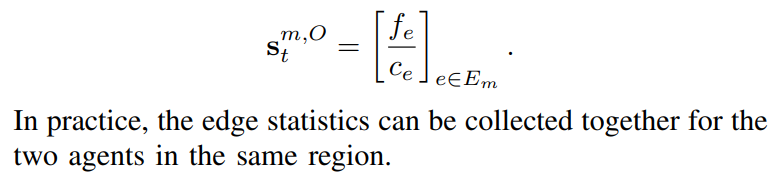
- action
- O-agent不区分mice flow和elephant flow,因为一个mice flow如果跨越多个区域,也可能会导致多个区域的拥塞。它也设置一系列转发路径,它决定的是如何跳转到下一个egress node。
- reward
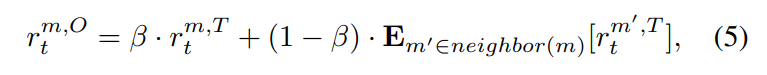
四、 仿真
- First, we use a measured topology called Telstra (AS 1221) obtained from the Rocketfuel project [29]. The network nodes are scattered(分散的) across Australia. We consider each state or territory(领土) of Australia as a region and ignore the regions with few nodes. Thus we obtain five regions. We also remove the nodes whose degree is no larger than one, which does not affect the evaluation of routings [30]. (孤立或不重要的,到时候需要看一下文献30)Particularly, the reduced Telstra topology contains 38 nodes and 152 edges.
- Second, we use a real topology obtained from Google cloud [31]. Particularly, we consider three regions: Europe, Asia, and North America, and there are a total of 44 nodes and 160 edges.
- Third, we use a large-scale synthetic topology whose region-level topology is a 2D 4×4 grid. Thus there are 16 regions in total. We use BRITE [32] to generate each region’s topology randomly. In particular, each region’s topology contains 10 to 15 nodes, and the link density (the ratio of link number divided by node number) is set to 2 (i.e., 20 to 30 pairs of edges in one region) according to our analysis of many available topologies [33] [29]. For any two adjacent regions, we generate 2 to 4 pairs of edges by selecting border nodes in each region randomly. Particularly, we use a synthetic topology (named as BRITE) with 204 nodes and 964 edges.
MRTE对比方案,HPR,ECMP,TRPO。

可见,算法表现能力显著。















 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









