







 天津大学强化学习实验室提出RACE框架,结合进化算法和多智能体强化学习(MARL)以提升协作效率。RACE通过表征不对称团队构建和协作进化,解决了MARL的低奖励信号质量、探索性差、非稳态性及部分观测等问题。研究证明,RACE在复杂控制任务中能显著提升MARL性能,代码已开源。
天津大学强化学习实验室提出RACE框架,结合进化算法和多智能体强化学习(MARL)以提升协作效率。RACE通过表征不对称团队构建和协作进化,解决了MARL的低奖励信号质量、探索性差、非稳态性及部分观测等问题。研究证明,RACE在复杂控制任务中能显著提升MARL性能,代码已开源。

©PaperWeekly 原创 · 作者 | 李鹏翼
单位 | 天津大学郝建业课题组
研究方向 | 演化强化学习
本次介绍的是由天津大学强化学习实验室(http://icdai.org/)提出多智能体进化强化学习混合框架 RACE。该框架充分融合了进化算法与多智能体强化学习用于多智能体协作,并首次在复杂控制任务上证明了进化算法可以进一步提升 MARL 的性能。目前代码已经开源。

论文题目:
RACE: Improve Multi-Agent Reinforcement Learning with Representation Asymmetry and Collaborative Evolution
论文链接:
https://proceedings.mlr.press/v202/li23i.html
代码链接:
https://github.com/yeshenpy/RACE

Necessary Background and Problem Statement
1.1 Multi-Agent Reinforcement Learning
在多智能体强化学习(MARL)中,各个智能体与环境以及彼此进行交互,收集样本并接收奖励信号来评估它们的决策。通过利用价值函数逼近,MARL 通过梯度更新来优化策略。然而,MARL 经常面临以下挑战:
➢(Low-quality reward signals,低质量的奖励信号)奖励信号通常质量较低(例如,具有欺骗性、稀疏性、延迟性和只有 team level 的奖励信号),这使得获得准确的价值估计变得非常困难。
➢(Low exploration for collaboration,合作的探索性差)由于多智能体策略空间巨大,基于梯度的优化方法很容易陷入次优点,难以高效地探索多智能体策略空间,使得协作困难。
➢(Non-stationarity,非稳态性)由于智能体同时学习并不断地相互影响,打破了大多数单智能体强化学习算法所基于的马尔可夫假设,使得优化与学习过程过程不稳定。
➢(Partial observations,部分观测)大部分多智能体场景下都是部分可观测的,智能体无法得知其它智能体的状态以及相关信息,使得策略优化变得更加具有挑战性。
1.2 Evolutionary Algorithm
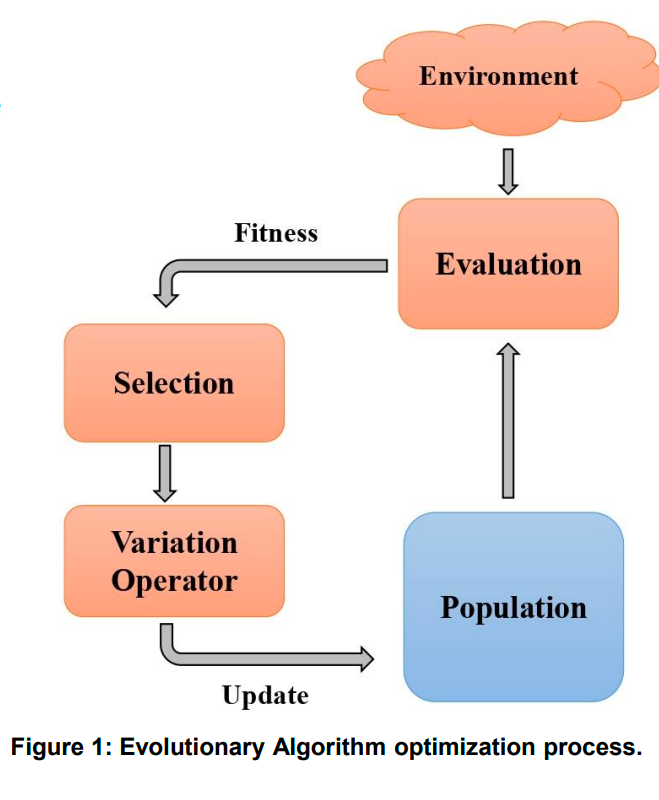
进化算法(Evolutionary Algorithm,EA)模拟了自然的遗传进化过程,不依赖于梯度信息进行策略优化,并已被证明在与强化学习(RL)竞争中表现出色。与通常仅维护一种策略的强化学习不同,EA 维护一个个体的群体,并根据策略适应度进行迭代演化。适应度通常被定义为一些回合的平均蒙特卡洛(Monte Carlo,MC)回报。
进化算法(EA)具有几个关键优势:
➢(对奖励质量不敏感)EA 不需要强化学习价值函数逼近,而是根据适应度,即累积奖励,直接对群体中的个体进行进化。这使得 EA 对奖励信号质量相对不敏感。
➢(避免非稳态问题)EA 在问题的形式化中不依赖于马尔可夫性质,并从团队的角度演化策略,从而避免了 MARL 中遇到的非稳态性问题。
➢(探索能力,鲁棒性,收敛性强)EA 具有强大的探索能力、良好的鲁棒性和稳定的收敛性。
下图是一个简化过的 EA 优化流程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3521
3521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









