







目录
1. UNet
UNet是一种广泛应用于图像分割任务的卷积神经网络架构,由Olaf Ronneberger等人于2015年提出。
其核心设计采用独特的U形对称结构,主要由编码器(下采样)和解码器(上采样)两部分组成。
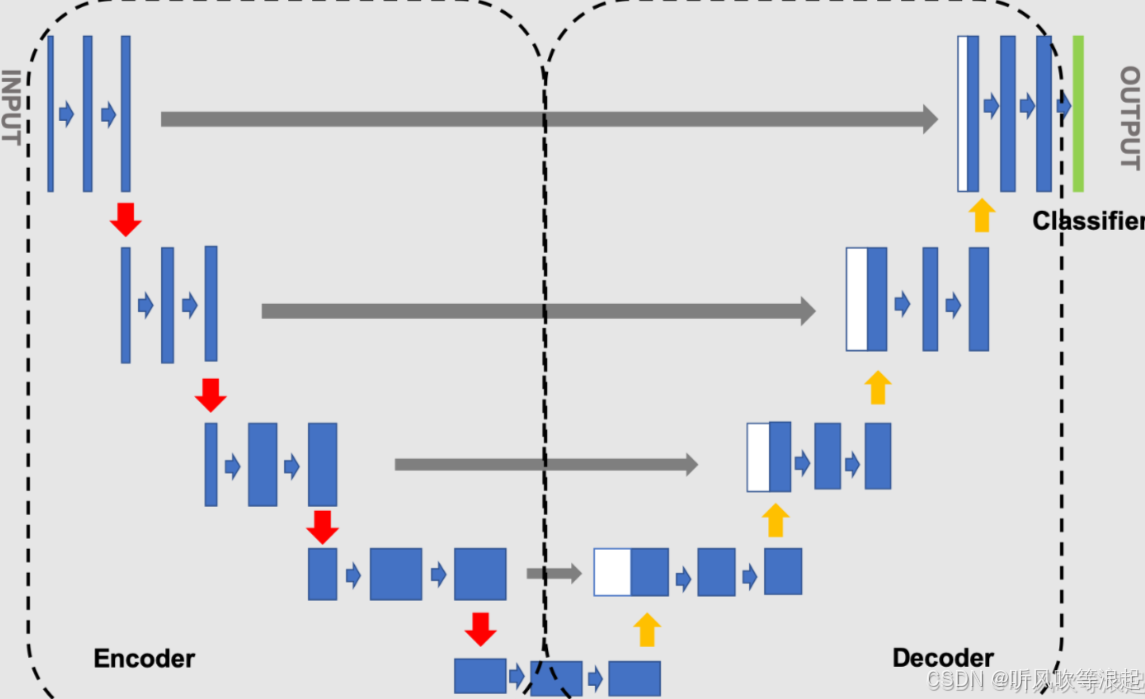
编码器通过连续卷积和池化操作逐步提取高层次特征并缩小空间维度,而解码器则通过转置卷积或插值操作逐步恢复空间细节。两者之间的跳跃连接(skip connections)将浅层定位信息与深层语义特征融合,有效解决了梯度消失问题并提升了小目标分割精度。
UNet的创新性在于其端到端的训练方式、对少量标注数据的高效利用能力,以及适应不同尺寸输入的灵活性。
该模型最初针对生物医学图像设计,现已成为语义分割领域的基准模型,广泛应用于医学影像分析(如肿瘤检测)、卫星图像解译、自动驾驶场景理解等任务。后续改进版本(如UNet++、3D UNet)通过引入嵌套跳跃连接或三维卷积进一步扩展了其应用场景。
2. CBAM、联合损失
2.1 CBAM
CBAM(Convolutional Block Attention Module)是一种轻量级的注意力模块,由Sanghyun Woo等人在2018年的论文《CBAM: Convolutional Block Attention Module for Channel and Spatial Attention》中提出。它通过结合通道注意力和空间注意力机制,帮助卷积神经网络(CNN)动态聚焦于图像中的重要区域和特征通道,从而提升模型性能。
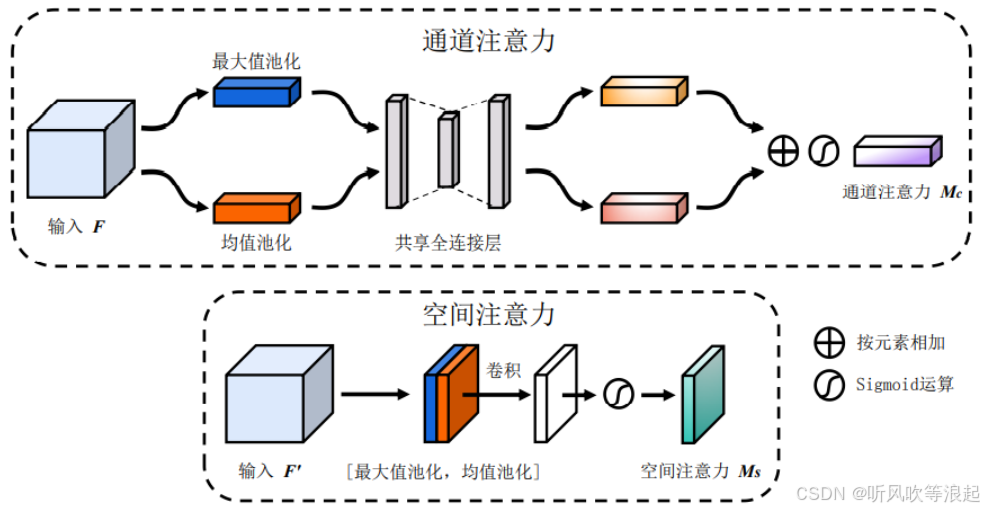
CBAM的核心结构
CBAM包含两个串联的子模块:
-
通道注意力模块(Channel Attention Module)
-
作用:学习不同通道的权重,突出重要的特征通道。
-
实现步骤:
-
对输入特征图分别进行全局平均池化(GAP)和全局最大池化(GMP),得到两个1D向量。
-
通过共享的多层感知机(MLP)生成通道注意力权重。
-
将GAP和GMP的结果相加后通过Sigmoid激活,得到最终的通道注意力图。
-
-
公式:
Mc(F)=σ(MLP(GAP(F))+MLP(GMP(F)))
-
-
空间注意力模块(Spatial Attention Module)
-
作用:学习空间位置的权重,关注特征图中的关键区域。
-
实现步骤:
-
沿通道维度对特征图进行平均池化和最大池化,得到两个2D特征图。
-
将两者拼接后通过卷积层压缩为单通道,再通过Sigmoid生成空间注意力图。
-
-
公式:
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))
-
CBAM的工作流程
-
输入特征图 F 先经过通道注意力模块,得到加权后的特征 F′=F⊗Mc(F)。
-
F′ 再经过空间注意力模块,得到最终输出 F′′=F′⊗Ms(F′)。
特点与优势
-
轻量高效:仅增加少量计算开销,可嵌入任何CNN架构(如ResNet、MobileNet)。
-
即插即用:无需修改网络结构,直接插入卷积模块后。
-
双重注意力:同时优化通道和空间维度,比单一注意力(如SENet)更全面。
-
显著提升性能:在分类、检测、分割等任务中验证有效(如ImageNet top-1准确率提升1-2%)。
代码示例(PyTorch)
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super().__init__()
self.gap = nn.AdaptiveAvgPool2d(1)
self.gmp = nn.AdaptiveMaxPool2d(1)
self.mlp = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(in_channels // reduction_ratio, in_channels)
)
def forward(self, x):
gap = self.mlp(self.gap(x).squeeze(-1).squeeze(-1))
gmp = self.mlp(self.gmp(x).squeeze(-1).squeeze(-1))
attention = torch.sigmoid(gap + gmp).unsqueeze(-1).unsqueeze(-1)
return x * attention
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2)
def forward(self, x):
avg = torch.mean(x, dim=1, keepdim=True)
max = torch.max(x, dim=1, keepdim=True)[0]
attention = torch.sigmoid(self.conv(torch.cat([avg, max], dim=1)))
return x * attention
class CBAM(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.ca = ChannelAttention(in_channels)
self.sa = SpatialAttention()
def forward(self, x):
x = self.ca(x)
x = self.sa(x)
return x2.2 联合损失
联合损失(Joint Loss 或 Combined Loss) 是深度学习中常用的策略,通过结合多个损失函数的优势,解决单一损失函数可能存在的局限性(如梯度不平衡、任务冲突等)。它在多任务学习、分类与回归联合任务、对抗训练等场景中尤为重要。
1. 联合损失的核心思想
-
互补性:不同损失函数关注不同方面的优化(如分类误差和位置误差)。
-
平衡权重:通过权重系数调节各损失的贡献,避免某一项主导梯度。
-
端到端优化:统一优化多个目标,提升模型整体性能。
2. 常见联合损失组合
以下是几种典型的联合损失应用场景及公式:
(1) 分类 + 回归任务
场景:目标检测(如Faster R-CNN)、人脸关键点检测等。
组成:
-
分类损失(如交叉熵损失)确保正确分类。
-
回归损失(如Smooth L1损失)精确定位边界框或关键点。
公式:
Ltotal=λcls⋅Lcls+λreg⋅Lreg
示例:
-
Faster R-CNN中,分类用交叉熵,回归用Smooth L1,权重通常为1:1。
(2) 分类 + 对比学习
场景:人脸识别、表征学习。
组成:
-
Softmax交叉熵损失:区分不同类别。
-
Triplet Loss 或 ArcFace:拉近同类样本,推开异类样本。
公式:
Ltotal=LCE+α⋅Ltriplet
作用:提升特征的判别性和泛化能力。
(3) 生成对抗网络(GAN)
场景:图像生成、风格迁移。
组成:
-
对抗损失(GAN Loss):让生成器欺骗判别器。
-
重构损失(L1/L2 Loss):保证生成内容与真实数据的相似性。
公式:
Ltotal=LGAN+λ⋅LL1
示例:
-
Pix2Pix中,联合对抗损失(BCE)和L1损失(λ=100)。
(4) 多任务学习(Multi-Task Learning)
场景:语义分割 + 深度估计、文本分类 + 情感分析。
组成:
-
各任务独立损失加权求和,如交叉熵(分类) + 均方误差(回归)。
公式:
Ltotal=i=1∑Nλi⋅Li
关键点:需动态调整权重(如GradNorm方法)。
3. 权重分配策略
联合损失的核心挑战是平衡不同损失的权重,常见方法包括:
-
手动调参:通过实验固定权重(如λ1=1.0,λ2=0.5)。
-
动态调整:
-
Uncertainty Weighting(ICLR 2018):根据任务不确定性自动调整。
-
GradNorm:平衡各任务的梯度量级。
-
-
损失归一化:对各损失进行标准化(如除以初始值或均值)。
4. 代码示例(PyTorch)
(1) 分类 + 回归联合损失
import torch
import torch.nn as nn
class JointLoss(nn.Module):
def __init__(self, lambda_cls=1.0, lambda_reg=1.0):
super().__init__()
self.lambda_cls = lambda_cls
self.lambda_reg = lambda_reg
self.ce_loss = nn.CrossEntropyLoss()
self.reg_loss = nn.SmoothL1Loss()
def forward(self, cls_pred, reg_pred, cls_target, reg_target):
loss_cls = self.ce_loss(cls_pred, cls_target)
loss_reg = self.reg_loss(reg_pred, reg_target)
return self.lambda_cls * loss_cls + self.lambda_reg * loss_reg| 任务类型 | 联合损失组成 | 典型应用 |
|---|---|---|
| 目标检测 | 分类损失 + 回归损失 | Faster R-CNN, YOLO |
| 人脸识别 | Softmax + Triplet Loss | FaceNet, ArcFace |
| 图像生成 | GAN Loss + L1/L2 Loss | Pix2Pix, CycleGAN |
| 语义分割 | 交叉熵 + Dice Loss | U-Net, DeepLab |
| 多任务学习 | 加权各任务损失 | NLP联合模型(如BERT) |
3. UNet+CBAM+联合损失
实现思路是,在最后的输出层前加入inception模块
网络结构如下:
CBAM_UNet(
(in_conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(down1): Down(
(downsampling): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down2): Down(
(downsampling): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down3): Down(
(downsampling): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down4): Down(
(downsampling): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(up1): Up(
(upsampling): ConvTranspose2d(1024, 512, kernel_size=(2, 2), stride=(2, 2))
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up2): Up(
(upsampling): ConvTranspose2d(512, 256, kernel_size=(2, 2), stride=(2, 2))
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up3): Up(
(upsampling): ConvTranspose2d(256, 128, kernel_size=(2, 2), stride=(2, 2))
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up4): Up(
(upsampling): ConvTranspose2d(128, 64, kernel_size=(2, 2), stride=(2, 2))
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(cbam): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(4, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
(out_conv): OutConv(
(conv): Conv2d(64, 3, kernel_size=(1, 1), stride=(1, 1))
)
)联合损失采用交叉熵+dice loss:
class DiceLoss(nn.Module):
"""多分类Dice Loss(按类别计算后取平均)"""
def __init__(self, smooth=1e-6):
super(DiceLoss, self).__init__()
self.smooth = smooth
def forward(self, pred, target):
# pred: [B, C, H, W] (未归一化,需先Softmax)
# target: [B, H, W] (值为0,1,2)
pred = F.softmax(pred, dim=1)
num_classes = pred.shape[1]
dice_loss = 0.0
# 将target转为one-hot编码 [B, C, H, W]
target_onehot = F.one_hot(target, num_classes).permute(0, 3, 1, 2).float()
for c in range(num_classes):
pred_c = pred[:, c, :, :]
target_c = target_onehot[:, c, :, :]
intersection = (pred_c * target_c).sum()
union = pred_c.sum() + target_c.sum()
dice_loss += 1 - (2. * intersection + self.smooth) / (union + self.smooth)
return dice_loss / num_classes # 平均各类别Dice Loss
class JointLoss(nn.Module):
def __init__(self, lambda_dice=0.5, lambda_ce=0.5):
super(JointLoss, self).__init__()
self.dice = DiceLoss()
self.ce = nn.CrossEntropyLoss() # 自动处理Softmax
self.lambda_dice = lambda_dice
self.lambda_ce = lambda_ce
def forward(self, pred, target):
# pred: [B, C, H, W] (原始logits)
# target: [B, H, W] (值为0,1,2)
dice_loss = self.dice(pred, target)
ce_loss = self.ce(pred, target)
return self.lambda_dice * dice_loss + self.lambda_ce * ce_loss4. 水体分割
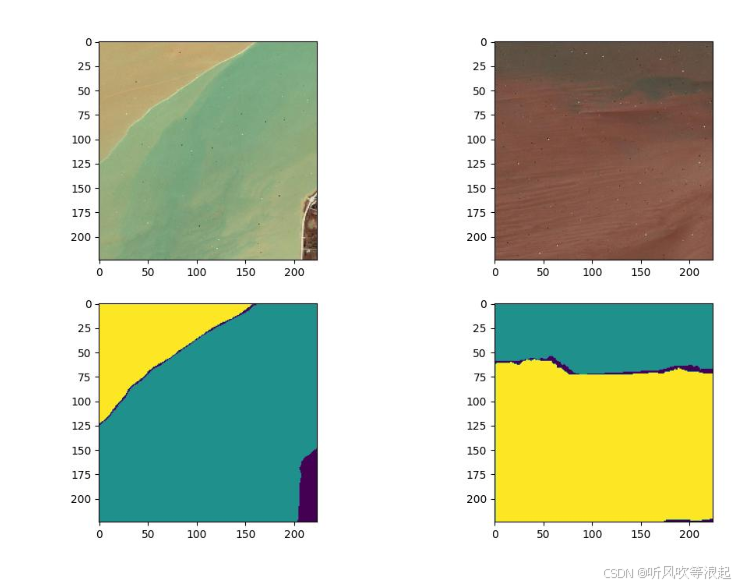
数据集采用水体分割,标签如下

对黄色和绿色两种水体进行分割
项目目录结构:
分别为数据、训练的结果、代码三部分

4.1准备工作
本人项目运行的环境为:python版本为3.10
einops==0.8.0
matplotlib==3.9.3
numpy==2.2.0
opencv_python==4.9.0.80
opencv_python_headless==4.10.0.84
Pillow==11.0.0
torch==2.0.1+cu118
tqdm==4.66.4
训练的时候,摆放好数据如下即可:

4.2 train 训练脚本
训练参数如下:
- 如果数据集是CT格式的话,将ct参数设置为True在加载数据的时候会运用windowing方法自动增强数据
- results 是返回的结果,这里默认保存在runs目录下
- 如果有测试集的话,按照train和val摆放好,设置为True,会自动进行测试
--data--train---images 训练集的图像
--data--train---masks 训练集的图像标签
--data--val---images 验证集的图像
--data--val---masks 验证集的图像标签
--data--test---images 测试集的图像(如果有的话)
--data--test---masks 测试集的图像标签
parser.add_argument("--ct", default=False,type=bool,help='is CT?') # Ct --> True
parser.add_argument("--model", default='unet',help='unet')
parser.add_argument("--base-size",default=(224,224),type=tuple) # 根据图像大小更改
parser.add_argument("--batch-size", default=8, type=int)
parser.add_argument("--epochs", default=50, type=int)
parser.add_argument('--lr', default=0.0001, type=float)
parser.add_argument('--lrf',default=0.001,type=float) # 最终学习率 = lr * lrf
parser.add_argument("--img_f", default='.jpg', type=str) # 数据图像的后缀
parser.add_argument("--mask_f", default='_mask.png', type=str) # mask图像的后缀
parser.add_argument("--results", default='runs', type=str) # 保存目录
parser.add_argument("--data-train", default='./data/train/images', type=str)
parser.add_argument("--data-val", default='./data/val/images', type=str)
parser.add_argument("--data-test", default=False, type=bool,help='if exists test sets')4.3 训练过程
这里简单训练了500轮,可以自行训练:
"train parameters": {
"model": "unet",
"input size": [
224,
224
],
"batch size": 4,
"lr": 0.0001,
"lrf": 0.001,
"ct": false,
"epochs": 500,
"num classes": 3
},
"Parameter:": 31038373.0,
"FLOPs:": 41923152960.0,
"Inference time:": 0.042989253997802734,
4.4 训练生成的结果---->runs
这里训练的结果保存在runs下,自行查看即可,这里只做简单展示
所有的结果都在json文件里,曲线啥的都是根据该文件生成
最好的一轮指标:
"epoch:499": {
"train log:": {
"info": {
"pixel accuracy": [
0.8883134722709656
],
"Precision": [
"0.8361",
"0.8701"
],
"Recall": [
"0.8971",
"0.8732"
],
"F1 score": [
"0.8655",
"0.8716"
],
"Dice": [
"0.8655",
"0.8716"
],
"IoU": [
"0.7629",
"0.7724"
],
"mean precision": 0.8530791997909546,
"mean recall": 0.8851511478424072,
"mean f1 score": 0.8685768842697144,
"mean dice": 0.8685768842697144,
"mean iou": 0.7676980495452881
}
},
"val log:": {
"info": {
"pixel accuracy": [
0.8461740612983704
],
"Precision": [
"0.7993",
"0.8683"
],
"Recall": [
"0.9044",
"0.8151"
],
"F1 score": [
"0.8486",
"0.8409"
],
"Dice": [
"0.8486",
"0.8409"
],
"IoU": [
"0.7371",
"0.7254"
],
"mean precision": 0.8338322639465332,
"mean recall": 0.8597488403320312,
"mean f1 score": 0.8447480201721191,
"mean dice": 0.8447479605674744,
"mean iou": 0.7312436699867249
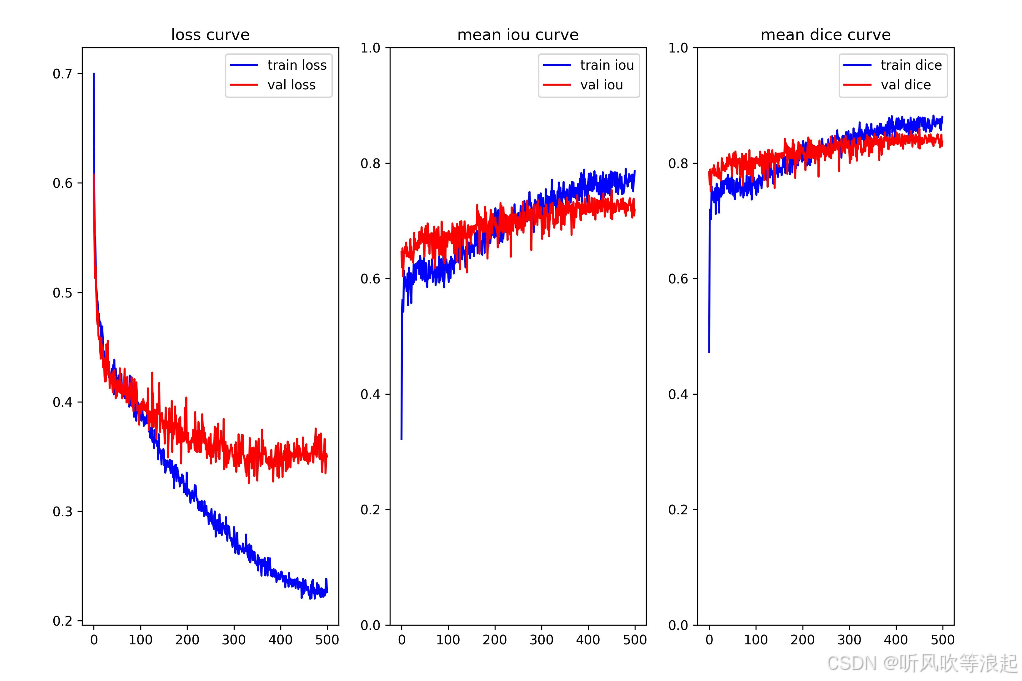
}loss+iou+dice曲线:
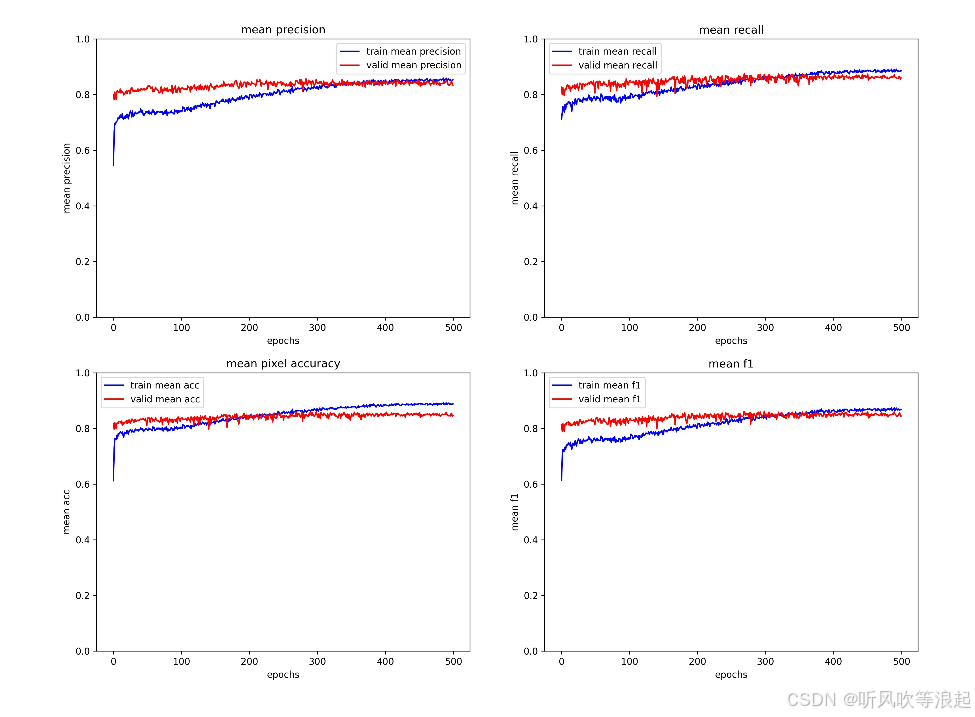
各类的指标曲线:截图工具截取的可能有点模糊
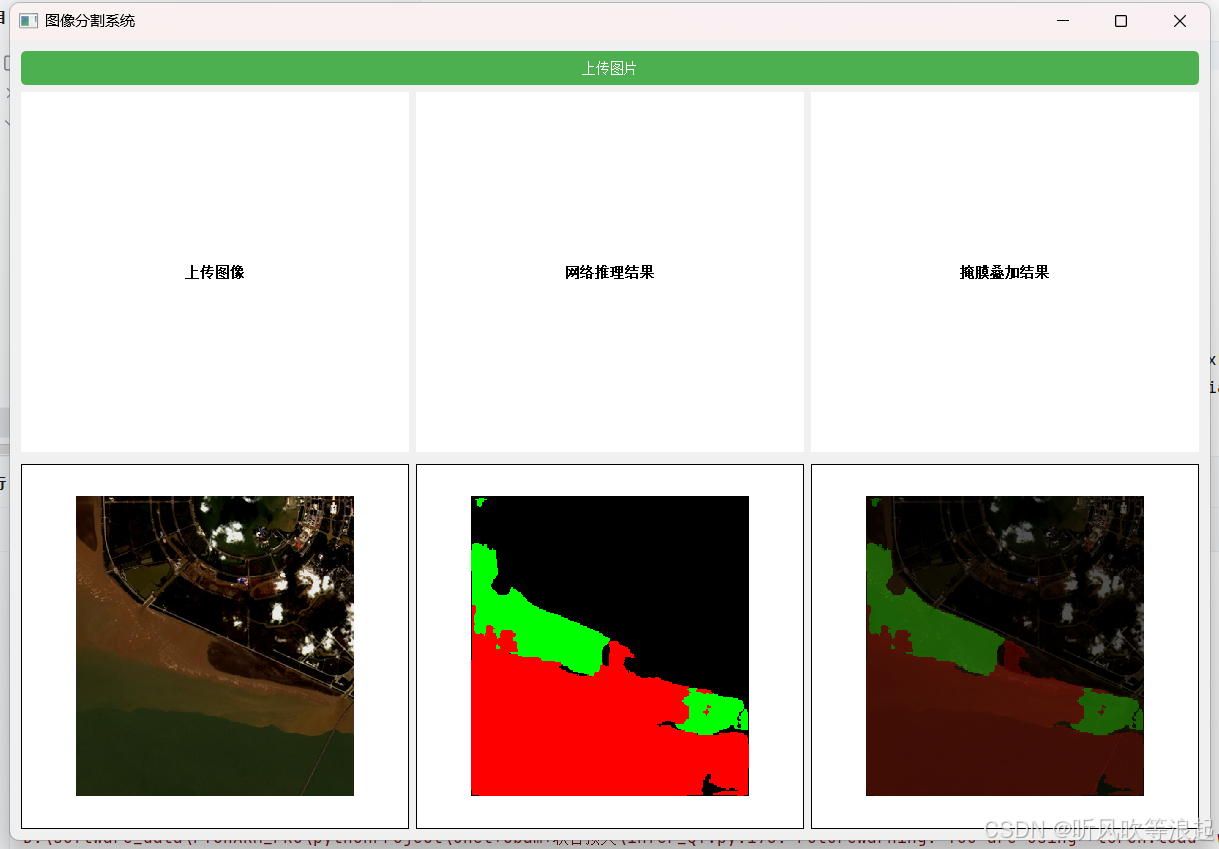
4.5 推理
推理的时候,直接运行infer_ui即可:
5. 项目下载
关于更多的ai改进:AI 改进系列_听风吹等浪起的博客-CSDN博客
本文的项目下载:
Unet+CBAM+联合损失改进:遥感水体图像分割数据集(3类图像分割任务)资源-CSDN文库



















 1647
1647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











