







优化算法能处理复杂问题,遗传算法是其中一种。
它可以方便地与PyTorch结合,用于多种优化任务。接下来介绍如何用PyTorch实现遗传算法。
1.遗传算法
遗传算法(GA)是一种受自然选择启发的优化方法。
它从一组初始解出发,通过多代迭代不断优化。
GA模拟自然选择机制,先评估解的优劣,再通过交叉和变异生成新解。
该过程反复进行,逐步改进解的质量,直至获得满意结果。
GA尤其适合解决传统方法难以处理的复杂问题。
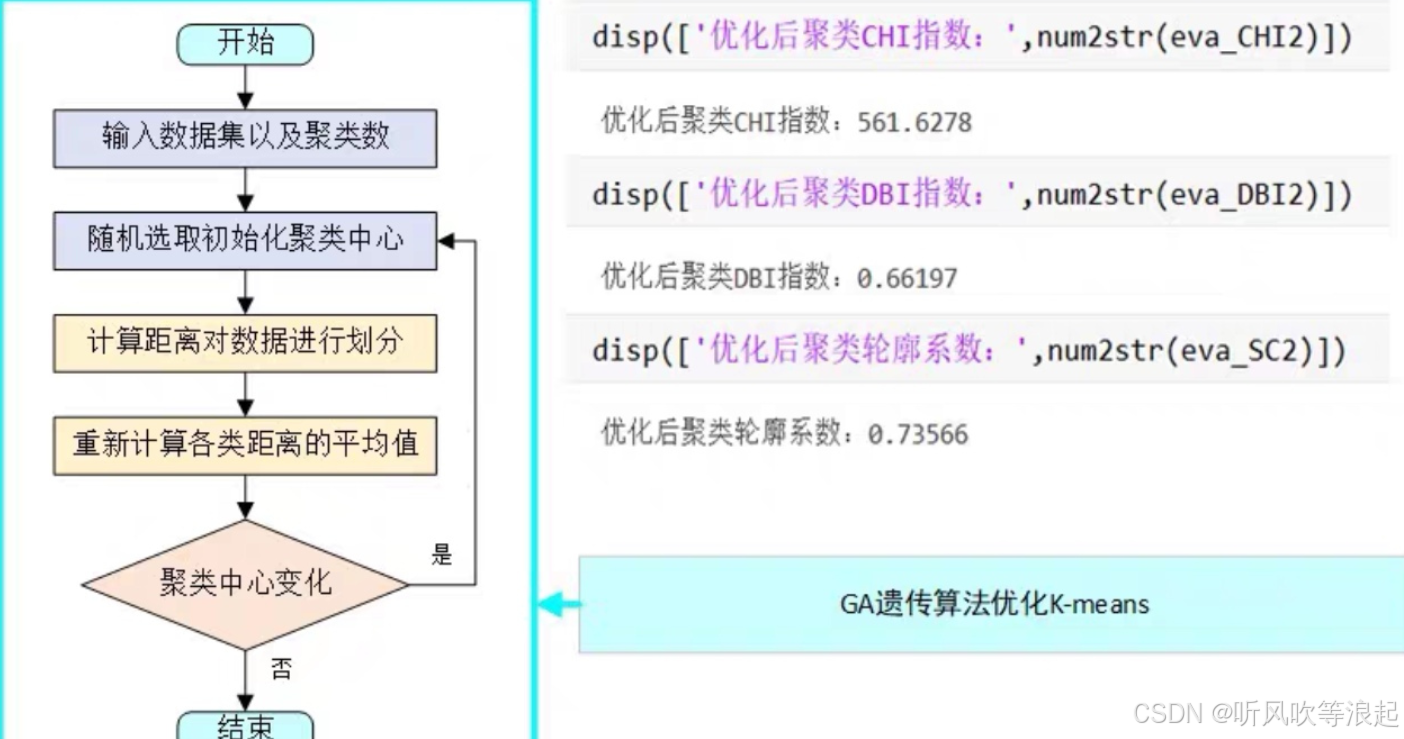
遗传算法流程:
- 初始化:随机生成一组初始解。
- 适应度评估:用适应度函数衡量每个解的质量。
- 选择:筛选优质解作为父代。
- 交叉:组合父代生成新解(子代)。
- 变异:随机扰动部分解以维持多样性。
- 迭代:重复上述步骤多代,逐步优化解。
2.使用 PyTorch 实现遗传算法
我基于PyTorch实现了一个简易遗传算法(GA)用于神经网络超参数优化。具体流程如下:首先初始化一个包含多组超参数的种群;然后通过训练网络并评估性能来计算个体适应度;接着执行选择、交叉和变异操作生成新一代种群;最后重复该过程直至达到预定迭代次数。整个过程遵循以下步骤:
-
种群初始化
-
适应度评估
-
选择操作
-
交叉操作
-
变异操作
-
迭代优化
该方法通过多代进化逐步优化网络超参数配置。
步骤1:导入必要的库
我们首先导入必要的库:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader步骤2:神经网络定义
使用PyTorch的nn.Module构建CNN架构,具体结构如下:
- 卷积层
conv1: 第一卷积层conv2: 第二卷积层
- 池化层
- 最大池化操作
- 全连接层
fc1: 第一全连接层fc2: 第二全连接层(输出层)
该CNN通过堆叠卷积、池化和全连接层实现特征提取与分类。
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.max_pool2d(x, kernel_size=2, stride=2)
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, kernel_size=2, stride=2)
x = x.view(-1, 64 * 7 * 7)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return torch.log_softmax(x, dim=1)步骤3:适应度计算
定义适应度函数,用于评估个体的性能表现:
- 训练阶段:在训练集上对模型进行5个epoch的优化
- 评估阶段:在测试集上计算模型的分类准确率
- 适应度值:将测试准确率作为个体的适应度评分
该过程通过模型的实际表现来量化每个超参数组合的优劣。
def compute_fitness(model, train_loader, test_loader):
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters())
model.train()
for epoch in range(5):
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = correct / total
return accuracy步骤4:遗传算法参数配置
设置遗传算法运行的关键参数:
-
种群规模 (population_size):定义每代包含的个体数量
-
变异率 (mutation_rate):控制每个参数发生突变的概率
-
迭代代数 (num_generations):指定算法进化的总世代数
这些参数直接影响算法的搜索能力和收敛速度。
population_size = 10
mutation_rate = 0.1
num_generations = 5步骤5:种群初始化函数
该函数使用指定数量的 CNN 模型初始化种群。
def initialize_population():
population = []
for _ in range(population_size):
model = CNN()
population.append(model)
return population步骤6:交叉算子(crossover)
交叉算子将两个父模型的遗传信息结合起来,产生两个子模型。它通过交换父模型层面层之间的权重来实现单点交叉。
def crossover(parent1, parent2):
child1 = CNN()
child2 = CNN()
child1.conv1.weight.data = torch.cat((parent1.conv1.weight.data[:16], parent2.conv1.weight.data[16:]), dim=0)
child2.conv1.weight.data = torch.cat((parent2.conv1.weight.data[:16], parent1.conv1.weight.data[16:]), dim=0)
return child1, child2步骤7:变异变异(mutate)
变异算子以一定的概率(mutation_rate)对模型的参数进行随机扰动。它会给模型的参数添加高斯噪声。
def mutate(model):
for param in model.parameters():
if torch.rand(1).item() < mutation_rate:
param.data += torch.randn_like(param.data) * 0.1
return model步骤8:加载数据集
使用torchvision加载MNIST数据集。它由手写数字图像和相应的标签组成。
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)步骤9:遗传算法主循环
通过迭代优化实现超参数进化:
-
世代迭代:循环执行预设的代数(num_generations)
-
适应度评估:对当前种群所有个体进行模型训练和测试准确率计算
-
精英选择:保留每代表现最优的个体直接进入下一代
-
交叉重组:对选中个体进行超参数组合交换
-
随机变异:按概率(mutation_rate)对部分参数进行扰动
该过程持续优化种群,逐步逼近最优超参数组合。
population = initialize_population()
for generation in range(num_generations):
print("Generation:", generation + 1)
best_accuracy = 0
best_individual = None
for individual in population:
fitness = compute_fitness(individual, train_loader, test_loader)
if fitness > best_accuracy:
best_accuracy = fitness
best_individual = individual
print("Best accuracy in generation", generation + 1, ":", best_accuracy)
print("Best individual:", best_individual)
next_generation = []
selected_individuals = population[:population_size // 2]
for i in range(0, len(selected_individuals), 2):
parent1 = selected_individuals[i]
parent2 = selected_individuals[i + 1]
child1, child2 = crossover(parent1, parent2)
child1 = mutate(child1)
child2 = mutate(child2)
next_generation.extend([child1, child2])
population = next_generation3.运行结果和分析
输出结果说明
-
迭代信息
- 代数标识:显示当前进化到第X代(Generation: X)
- 性能指标:输出该代最高测试准确率(Best accuracy in generation X: Y%)
-
模型架构
- 最优个体:展示当代最佳CNN的超参数配置(Best individual: ...)
-
最终输出
- 进化结果:完成所有迭代后,输出最终种群
- 个体表示:每个个体对应一个CNN模型,并标注其超参数组合
该输出结构可清晰追踪算法进化过程与优化结果。
4.完整代码
如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.max_pool2d(x, kernel_size=2, stride=2)
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, kernel_size=2, stride=2)
x = x.view(-1, 64 * 7 * 7)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return torch.log_softmax(x, dim=1)
def compute_fitness(model, train_loader, test_loader):
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters())
model.train()
for epoch in range(5):
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = correct / total
return accuracy
population_size = 10
mutation_rate = 0.1
num_generations = 5
def initialize_population():
population = []
for _ in range(population_size):
model = CNN()
population.append(model)
return population
def crossover(parent1, parent2):
child1 = CNN()
child2 = CNN()
child1.conv1.weight.data = torch.cat((parent1.conv1.weight.data[:16], parent2.conv1.weight.data[16:]), dim=0)
child2.conv1.weight.data = torch.cat((parent2.conv1.weight.data[:16], parent1.conv1.weight.data[16:]), dim=0)
return child1, child2
def mutate(model):
for param in model.parameters():
if torch.rand(1).item() < mutation_rate:
param.data += torch.randn_like(param.data) * 0.1
return model
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
population = initialize_population()
for generation in range(num_generations):
print("Generation:", generation + 1)
best_accuracy = 0
best_individual = None
for individual in population:
fitness = compute_fitness(individual, train_loader, test_loader)
if fitness > best_accuracy:
best_accuracy = fitness
best_individual = individual
print("Best accuracy in generation", generation + 1, ":", best_accuracy)
print("Best individual:", best_individual)
next_generation = []
selected_individuals = population[:population_size // 2]
for i in range(0, len(selected_individuals), 2):
parent1 = selected_individuals[i]
parent2 = selected_individuals[i + 1]
child1, child2 = crossover(parent1, parent2)
child1 = mutate(child1)
child2 = mutate(child2)
next_generation.extend([child1, child2])
population = next_generation


















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











