






看了这篇论文 觉得有趣的地方 希望能为后者提供些不同看法,不足之处希望各位指正
一、
该论文通过改进提高了生成图像的像素,有趣的一点在于作者能通过low-dimension feature channel 作为生成器的输入来实现实例级的目标修改,效果如下图:

论文中该方法的实现,
1)作者训练一个生成器网络E去找图片中每个实例对应的低维特征,E是一个encoder-decoder标准结构网络。
2)作者添加了instance-wise 平均池化层来保证每个实例的特征是一致的。
3)添加了用G(s,E(x))代替了GAN损失函数中的G(s),并且E与生成器,判别器一起训练。
4)在训练后,在训练图片上运行所有实例并获得特征。在这些特征上对每个语义类别运行K-mean集群(应该是用k-mean集群的方法对特征进行归类,但是K-mean需要提前知道要多少个集群数目K。)

二、
1)该论文的名字ConditionGAN的Condition主要是因为将合成图片与真实图片按2/4倍下采样成图片金字塔后用了三个判别器(discriminator)进行判别。这样在最粗糙的图片上会有最大的感受野。另一方面,好的图片也可以鼓励生成器生成更好的纹理。
2)同时该网络的生成器也是多个组成(该论文是三部分:全局生成G1,两个增强网络G2),如图:
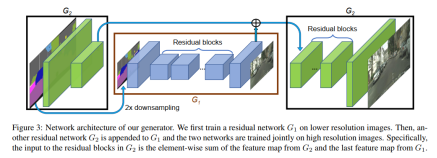
G1仿照论文 Perceptual Losses for Real-Time Style Transfer and Super-Resolution中的网络结构能生成1024512,经过G2后能扩大4倍到20481024.
三、
该论文添加了特征匹配损失来提高生成图片细节,损失函数如图:
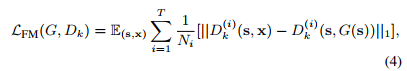
像运用到生成真实图像和风格转换的感知损失一样,该匹配损失从判别器的不同层提取特征图进行损失计算。
最后总的损失函数为:
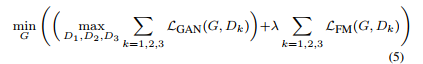
参考论文:
1 perceptual loss for real 论文翻译:http://www.jianshu.com/p/b728752a70e9
2 本论文下载地址















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









