









引言
最近在对图像滤波算法进行加速时,偶然发现了omp这个好东西,其操作简单,只需要加入简单编译指导语句即可实现。
对于代码的加速,主要有以下几种策略:编译器优化(vs优化),算法加速(分块处理,代码优化等),CPU多线程(thread,openmp),指令集加速(SSE、AVX2等),GPU加速(CUDA,OpenCL)。
以下将介绍编译器优化和CPU多线程之openmp并行计算。
1.VS代码优化
- Release和Debug版本对程序的处理机制不同,特比是对变量的初始化,需要格外注意。
- 属性->配置属性->C/C+±>代码生成:启用增强指令集,可选用 流式处理 SIMD 扩展 2 (/arch:SSE2) (/arch:SSE2)、流式处理 SIMD 扩展 2 (/arch:SSE2) (/arch:SSE2) 进行加速浮点模型,可选用快速 (/fp:fast) 进行浮点数据运算的加速。
- 属性->配置属性->C/C+±>优化:可选用使速度最大化 (/O2)
进行优化。全程序优化选择是(/GL),在debug版本下不能这样设置,必须在release版本。
2.C++ 代码中使用openmp并行运算:
- 如今计算机都是多核的,因此为了充分利用资源,在对处理时间有要求的情况下可以考虑使用多线程并行计算。其中一种简单的方式就是openmp并行加速,它仅仅使用编译指导语句就可以实现for循环的并行加速。关于openmp的详细介绍,可以参考这篇博客。
OpenMP的使用
- 在vs中,项目属性-》C/C+±》语言,openmp支持,选是,包含头文件“omp.h”。
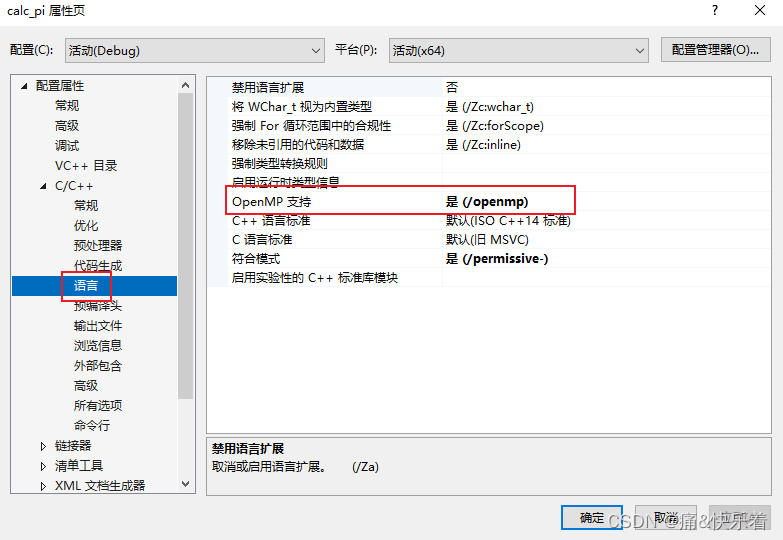
在代码中,在代码段使用编译指导语句即可实现并行计算。
#pragma omp parallel for
for ( int j = 0; j < 4; j++ )
{
printf(“Hello, World!, ThreadId=%d\n”, omp_get_thread_num() );
}
注意事项:
- 将VS编译器release下的C/C++ > 优化 > 优化 >使速度最大化 (/O2);
- #pragma omp parallel for schedule(static,1) 下面的for循环内部,所有使用到的新变量(非下标访问)需要在for循环内部定义成局部变量,而不能在for循环外面声明;
- #pragma omp parallel for schedule(static,1) 下面的while/for循环内部,不能使用continue/break。
参考文献:
omp的一个不错的文章
VS2022 OpenMP实验














 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









