







文章目录
1.CUDA是什么?
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台,是一种通用并行计算架构,该架构使GPU能够解决复杂的计算问题。说白了就是我们可以使用GPU来并行完成像神经网络、图像处理算法这些在CPU上跑起来比较吃力的程序。通过GPU和高并行,我们可以大大提高这些算法的运行速度。
2.CPU&CUDA架构
处理器结构有2个指标要经常考虑的:延迟和吞吐。延迟指从发出指令到返回最终结果中间经历的时间间隔;吞吐指单位时间内处理的指令的条数。由于CPU以处理计算和控制为主要任务,所以设计理念是延迟导向内核;由于GPU以并行处理为主要任务,所以设计理念是吞吐导向内核。
(1)CPU
CPU(CentralProcessing Unit)中央处理器,是一块超大规模的集成电路,主要逻辑架构包括控制单元Control,运算单元ALU和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。简单说,就是计算单元、控制单元和存储单元。
架构图如下所示:

CPU遵循的是冯·诺依曼架构,其核心是存储程序/数据、串行顺序执行。因此CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以CPU在进行大规模并行计算方面受到限制,相对而言更擅长于处理逻辑控制。CPU无法做到大量数据并行计算的能力,但GPU可以。
(2)GPU
GPU(GraphicsProcessing Unit),即图形处理器,是一种由大量运算单元组成的大规模并行计算架构,早先由CPU中分出来专门用于处理图像并行计算数据,专为同时处理多重并行计算任务而设计。GPU中也包含基本的计算单元、控制单元和存储单元,但GPU的架构与CPU有很大不同,其架构图如下所示。

与CPU相比,CPU芯片空间的不到20%是ALU,而GPU芯片空间的80%以上是ALU。即GPU拥有更多的ALU用于数据并行处理。这就是为什么GPU可以具备强大的并行计算能力的原因。
从硬件架构分析来看,CPU和GPU似乎很像,都有内存、Cache、ALU、CU,都有着很多的核心,但是CPU的核心占比比较重,相对计算单元ALU很少,可以用来处理非常复杂的控制逻辑,预测分支、乱序执行、多级流水任务等等。相对而言GPU的核心就是比较轻,用于优化具有简单控制逻辑的数据并行任务,注重并行程序的吞吐量。
简单来说就是CPU的核心擅长完成多重复杂任务,重在逻辑,重在串行程序;GPU的核心擅长完成具有简单的控制逻辑的 任务,重在计算,重在并行。
3.NVIDIA显卡硬件架构:SM、SP、Warp
流处理器SP(streaming processor)
最基本的处理单元,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
SM(streaming multiprocessor)
多个SP加上其他的一些资源组成一个SM,也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。如下图是一个SM的基本组成,其中每个绿色小块代表一个SP。
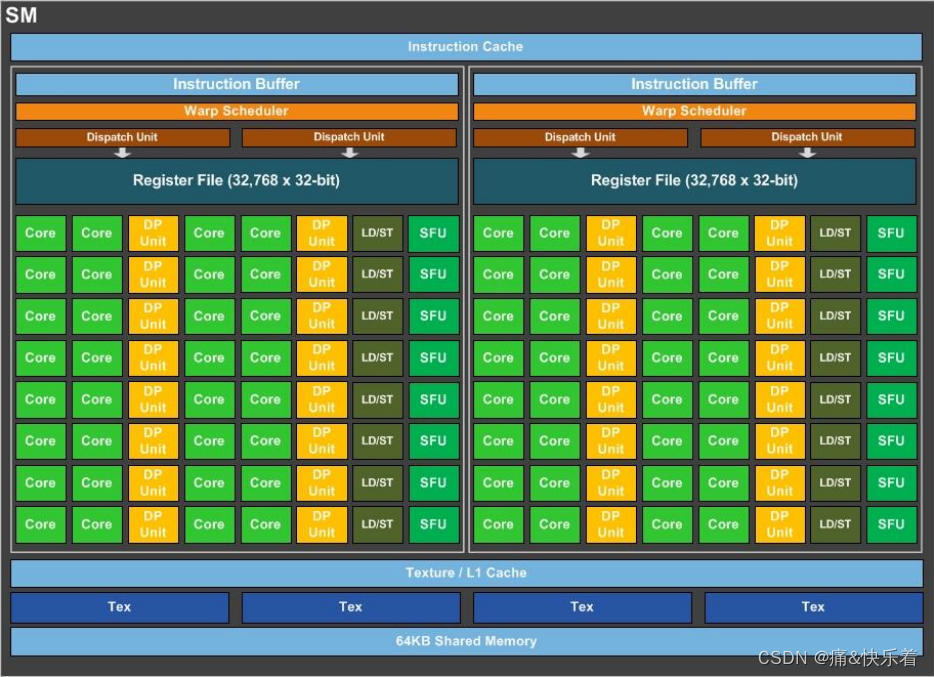
每个SM包含的SP数量依据GPU架构而不同,Fermi架构GF100是32个,GF10X是48个,Kepler架构都是192个,Maxwell都是128个。当一个kernel启动后,thread会被分配到很多SM中执行。大量的thread可能会被分配到不同的SM,但是同一个block中的thread必然在同一个SM中并行执行。
Warp调度
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。warp由SM的硬件warp scheduler负责调度,一个SM同一个时刻可以执行多个warp,这取决于warp scheduler的数量。目前每个warp包含32个threads(Nvidia保留修改数量的权利)。
4.软件架构:Kernel、Grid、Block
具体到我们如何调用GPU上的线程实现我们的算法,则是通过Kernel实现的。在GPU上调用的函数成为CUDA核函数(Kernel function),核函数会被GPU上的多个线程执行。我们可以通过如下方式来定义一个kernel:
kernel_function<<<grid, block>>>(param1, param2, param3....);
如下图所示为kernel、grid、block的组织方式以及对应的硬件部分。

Grid: 由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。Grid由很多Block组成,可以是一维二维或三维。
Block: 一个grid由许多block组成,block由许多线程组成,同样可以有一维、二维或者三维。block内部的多个线程可以同步(synchronize),可访问共享内存(share memory)。
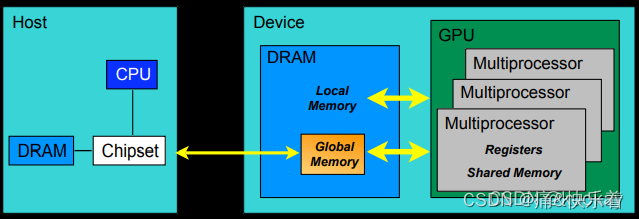
5.CUDA内存模型
CUDA中的内存模型分为以下几个层次:
- 每个线程都用自己的registers(寄存器)
- 每个线程都有自己的local memory(局部内存)
- 每个线程块内都有自己的shared memory(共享内存),所有线程块内的所有线程共享这段内存资源
- 每个grid都有自己的global memory(全局内存),不同线程块的线程都可使用
- 每个grid都有自己的constant memory(常量内存)和texture memory(纹理内存),),不同线程块的线程都可使用
- 线程访问这几类存储器的速度是register > local memory >shared memory > global memory
下面这幅图表示就是这些内存在计算机架构中的所在层次。
6.异构计算
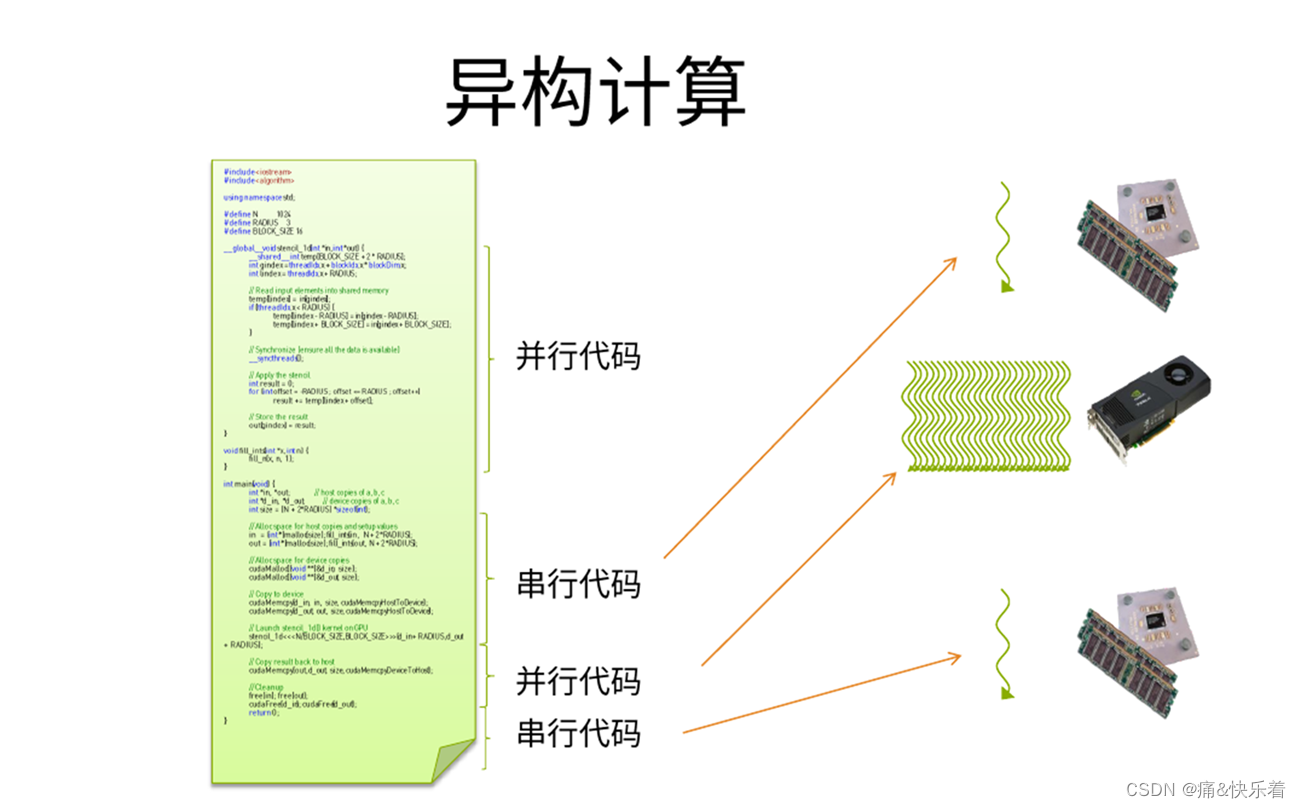
所谓异构计算,是指CPU+ GPU或者CPU+ 其它设备(如FPGA等)协同计算。⼀般我们的程序,是在CPU上计算。但是,当⼤量的数据需要计算时,CPU显得⼒不从⼼。那么,是否可以找寻其它的⽅法来解决计算速度呢?那就是异构计算。例如可利⽤CPU(Central Processing Unit)、GPU(Graphic Processing Unit)、甚⾄APU(Accelerated Processing Units, CPU与GPU的融合)等计算设备的计算能⼒从⽽来提⾼系统的速度。异构系统越来越普遍,对于⽀持这种环境的计算⽽⾔,也正受到越来越多的关注。
⽬前异构计算使⽤最多的是利⽤GPU来加速。主流GPU都采⽤了统⼀架构单元,凭借强⼤的可编程流处理器阵容,GPU在单精度浮点运算⽅⾯将CPU远远甩在⾝后。如图所示为CPU+GPU异构计算的一个示意图,其中GPU主要负责并行计算。
7.OpenCL与CUDA的关系
NVIDIA的CUDA架构和KHRONOS制定的OpenCL并不冲突,他们之间的关系是API与执行架构之间的关系,举个简单的例子:我们熟悉的X86架构是一种CPU架构,而各种编程语言,如:汇编语言、C语言等低级语言或高级语言仅仅是建立在X86运算架构之上的一种编程环境。那么,CUDA架构和OpenCL之间的关系和X86与编程语言的关系是相同的。
CUDA架构是OpenCL的运行平台之一,因此他们之间并不存在谁取代谁的关系。OpenCL仅仅是为CUDA架构提供了一个可编程的API而已。

参考文献
[1] http://t.zoukankan.com/liuyufei-p-13259264.html
[2] https://zhuanlan.zhihu.com/p/266633373?utm_id=0
[3] https://betheme.net/a/21450178.html?action=onClick
[4] https://blog.csdn.net/chongbin007/article/details/123667504














 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









