






Masked Feature Prediction for Self-Supervised Visual Pre-Training
一、摘要
提出了用于视频模型自监督预训练的掩模特征预测(MaskFeat)。首先随机屏蔽输入序列的一部分,然后预测屏蔽区域的特征。研究了五种不同类型的特征,发现定向梯度直方图(HOG)(一种手工制作的特征描述符),在性能和效率方面效果特别好。此方法可以学习丰富的视觉知识并驱动基于 Transformer 的大规模模型。
当人类将世界视为连续的时空信息流时,它具有预测世界如何出现和移动的非凡能力。考虑图 1 第一列中的示例,即使没有看到被掩盖的内容,也能够通过使用有关对象的视觉知识来理解对象结构并绘制想象信息的粗略轮廓或轮廓(一些细节),预测某些屏蔽特征(例如第二列中的梯度直方图)可以成为自监督视觉预训练的强大目标,特别是在包含丰富视觉信息的视频领域。

提出了屏蔽特征预测(MaskFeat),这是一种直接回归屏蔽内容特征的预训练目标。研究了广泛的特征类型,从像素颜色和手工制作的特征描述符,到离散视觉标记、深度网络的激活以及网络预测的伪标签。
二、模型(屏蔽特征预测)
蒙版视觉预测任务,其动机是人类将蒙版视觉内容修复到某些细节的能力。该任务首先随机屏蔽视频的一些时空立方体,然后根据剩余的时空立方体预测被屏蔽的立方体。通过对屏蔽样本进行建模,模型必须首先根据可见区域识别对象,并且还知道对象通常会出现什么以及它们通常如何移动以修复缺失区域。
首先描述用于视频输入的 MaskFeat。视频被划分为时空立方体。然后将立方体投影(即卷积)为一系列标记。为了执行屏蔽,序列中的一些令牌被替换为 [MASK] 令牌而被随机屏蔽。为了进行预测,[MASK]令牌替换后的令牌序列(添加了位置嵌入)由 Transformer 进行处理。与屏蔽立方体相对应的输出标记通过线性层投影到预测。预测只是时间上以每个屏蔽立方体为中心的二维空间补丁的特征。输出通道的数量根据特定的目标特征进行调整(例如,如果预测 16×16 块中像素的 RGB 颜色,则为 3×16×16)。损失仅对遮罩立方体进行操作,如图所示。
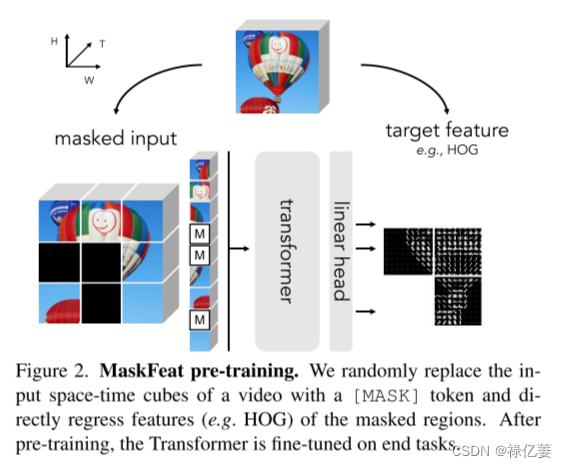
MaskFeat 预训练。用 [MASK] 标记随机替换视频的输入时空立方体,并直接回归屏蔽区域的特征(例如 HOG)。经过预训练后,Transformer 将针对最终任务进行微调。
MaskFeat 可以在图像领域轻松实例化,可以将其解释为单帧视频。大多数操作都是共享的,除了没有时间维度,并且每个标记现在仅代表一个空间补丁而不是时空立方体。具体来说,我们的方法通过视觉 Transformer 主干提取屏蔽时空输入,并预测屏蔽内容的某些特征表示。
三、目标特征
考虑五种不同类型的目标特征。目标分为两组:
1)可以直接获得的一阶段目标,包括像素颜色和定向梯度直方图 HOG;
2)由经过训练的深度网络或教师提取的其他两阶段目标。
这五种特征类型是:
像素颜色:视频像素的颜色。使用通过数据集的平均值和标准差标准化的 RGB 值。最小化模型预测与真实 RGB 值之间的 ℓ2 距离。虽然简单,但像素作为目标具有过度拟合局部统计数据(例如照明和对比度变化)和高频细节的潜在缺点,这对于视觉内容的解释来说可能是微不足道的。
HOG:定向梯度直方图(HOG)是一种特征描述符,描述局部子区域内梯度方向或边缘方向的分布。HOG 描述符是通过简单的梯度过滤(即减去相邻像素)来计算每个像素处的梯度大小和方向来实现的。然后,每个小的局部子区域或单元内的梯度被累积成几个箱的方向直方图向量,并由梯度大小投票。直方图标准化为单位长度。在整个图像的密集网格上,这适合随机屏蔽补丁的预测目标。HOG 的特点是捕获局部形状和外观。此外,当图像梯度和局部对比度归一化吸收亮度(例如照明)和前景-背景对比度变化时,它提供了光度变化的不变性。研究表明 HOG 中的局部对比度标准化对于 MaskFeat 预训练至关重要。最后,HOG 可以实现为双通道卷积,以生成 x 和 y 轴上的梯度(或通过减去相邻的水平和垂直像素),然后进行直方图和归一化。首先在整个图像上获得 HOG 特征图,然后将该图分割成补丁。通过这种方式,减少了每个遮罩补丁边界上的填充。然后,将屏蔽补丁的直方图展平并连接成一维向量作为目标特征。损失:最小化预测和原始 HOG 特征之间的 ℓ2 距离。
离散变分自动编码器(dVAE):为了解决视觉信号的连续高维性质,DALL-E [58] 提出使用 dVAE 码本压缩图像。特别是,每个补丁都被编码成一个令牌,该令牌可以使用预先训练的 dVAE 模型假设 8192 个可能的值。通过优化交叉熵损失来预测屏蔽标记的分类分布。然而,预训练 dVAE 和标记图像以及屏蔽特征预测会产生额外的计算成本。
深层次的特征:与离散化标记相比,考虑直接使用连续的深度网络特征作为预测目标。使用预先训练的模型作为教师(CNN 或 ViT(Vision Transformer))来生成特征,并且损失最小化余弦距离(即 ℓ2 归一化特征的均方误差)。对于 CNN 教师,使用与屏蔽补丁相对应的最后一层的特征,对于 ViT,使用相应的输出补丁标记。主要比较自监督模型的特征,它们被认为比监督模型的特征包含更多样化的场景布局并保留更多的视觉细节。监督特征预计会更加语义化,因为它们是通过人工注释进行训练的。与 dVAE 类似,当使用额外的模型权重来生成屏蔽特征时,会涉及大量的额外计算。
伪标签:为了探索更高级别的语义预测目标,考虑预测屏蔽补丁的类标签。利用令牌标签提供的标签,其中每个补丁都分配有一个单独的位置特定的 IN-1K 伪标签。该类标签图由预先训练的高性能监督深度网络教师生成。屏蔽特征预测阶段通过交叉熵损失进行优化。















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









