






CoReFace: Sample-Guided Contrastive Regularization for Deep Face Recognition
一、摘要
人脸识别对比正则化(CoReFace)(损失函数),将图像级正则化应用于特征表示学习。 具体来说,采用样本引导对比学习直接利用图像-图像关系来规范训练。 为了将对比学习整合到人脸识别中,通过增加嵌入而不是图像,以避免图像质量下降。 然后,通过结合自适应边距和监督对比掩模,提出了一种新颖的表示分布对比损失,以生成稳定的损失值并避免与分类监督信号的冲突。 最后,通过探索新的配对耦合协议来发现并解决对比学习中的语义重复信号问题。
创新点:
• 提出了一个对比损失函数来执行有效的正则化,其中包含一个自适应边距来增强对比监督信号,以及一个监督对比掩模来避免联合训练中的监督冲突。
• 研究了有限负样本情况下对比学习中的语义重复信号SRS问题,并探索不同的配对耦合协议来缓解这个问题。
二、网络结构
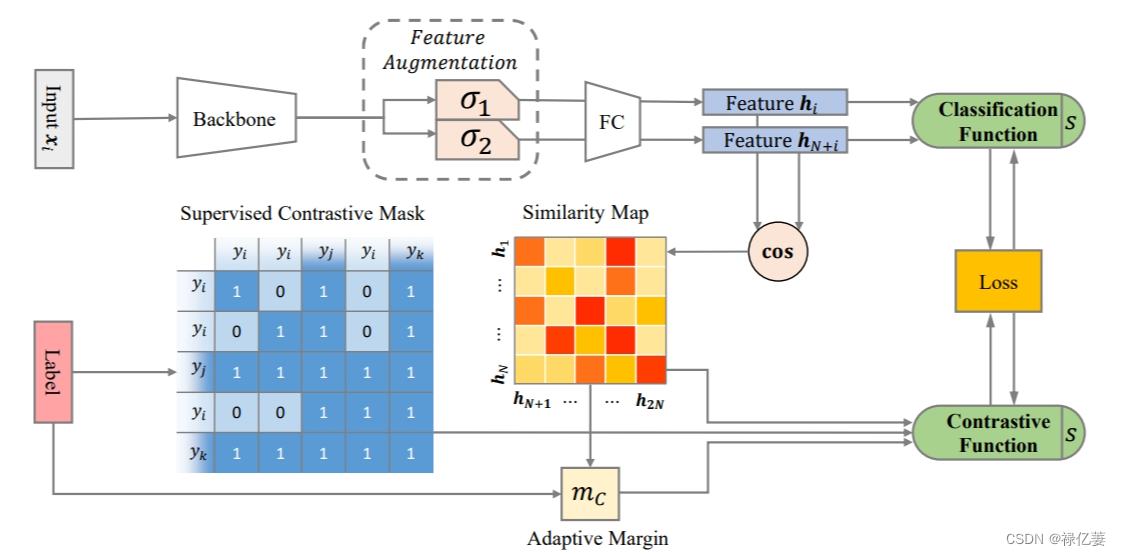
应用正则化和样本引导对比学习来解决训练中忽略图像-图像关系以及评估中放弃分类器造成的不一致问题。
首先,为了解决图像质量下降问题,采用特征增强来代替广泛使用的正对组合数据增强。我们通过具有不同掩码的两个 dropout 通道 σ1 和 σ2 在主干之后传递隐藏嵌入。 Dropout以一定的概率随机丢弃输入的某些部分。 它可以看作是两个相邻层之间的一种增强。 丢失掩码是在每个小批量中随机生成的,并对所有输入样本进行操作。通过特征增强,可以组合正对进行对比学习(对比学习旨在调整特征表示分布),同时避免图像质量下降问题。此外,与对输入样本进行数据增强并将增强的样本两次传递到整个模型相比,此次特征增强对特征进行操作,并节省了近一半的计算量。
其次,通过整合自适应边缘和监督对比掩模提出了一种新颖的对比损失。 自适应边距旨在保持正负相似度的大小接近,并在联合训练期间产生稳定的损失值。 监督对比掩模(SCM)采用类别标签生成掩模,该掩模将同一类别的样本从负比较池中排除。 这样就避免了与分类方法的冲突。
第三,研究语义重复信号(SRS)问题,即对比学习中的一些关键对是重复的。 这会扭曲特征分布并干扰即将进行的相似度计算,设计了新的配对策略来缓解这个问题。
最后,通过与 CoReFace 损失函数联合训练分类方法,将图像-图像正则化应用于 FR。
三、损失函数
FR中的样本引导对比损失函数和分类损失函数都是基于交叉熵损失函数。 这两类损失的常见形式如下:
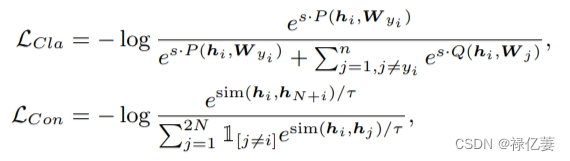
自适应边距。由于最相似的负对和正对对决策边界的影响最大,我们的对比损失用它们相似度之间的差异来更新边际 m。 裕度保证了softmax中分子和分母的指数大小接近,并保持损失值稳定。
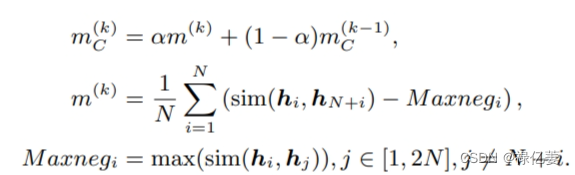
基于自适应边缘的对比损失可以表示为
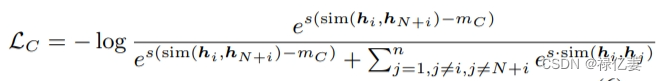
四种类型的配对耦合协议。 两个增强通道 σ1 和 σ2 的每个组合都代表小批量中图像的特征组合。 当存在多个增强通道组合时,重复特征组合。语义重复信号问题,即对比学习中的一些关键对是重复的。选择σ1-->σ2减少语义重复问题,并将其应用到损失函数中。
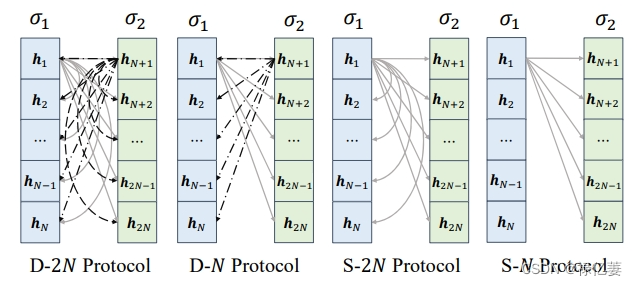
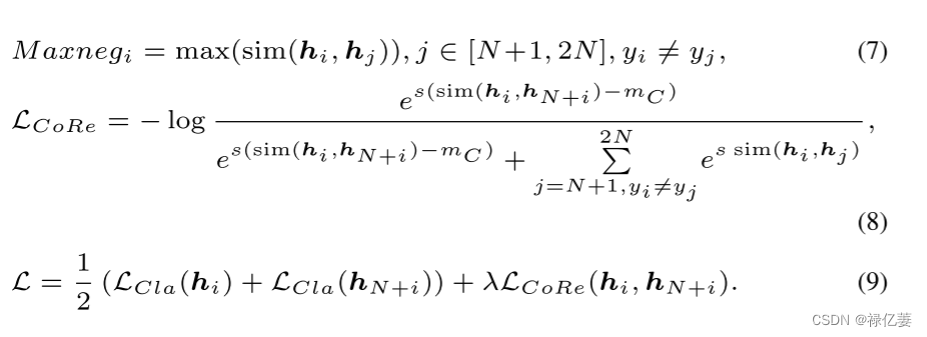
对比损失用于通过提供图像级分布指导来约束特征的分布,以补偿基于身份的训练和基于样本的评估之间的不一致。CoReFace 损失可以生成稳定的损失值,并考虑分类标签以避免与分类损失发生冲突。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









