






Hive基础
摘要
本篇博客参考线上教程的笔记,对Hive数据仓库的基础进行简单总结,以便加深理解和记忆
1.Hadoop快速开始
简介
Hadoop是Apache基金会下的一个开源分布式计算平台,以Hadoop分布式文件系统HDFS (Hadoop Distributed File System)和MapReduce分布式计算框架为核心,为用户提供了底层细节透明的分布式基础设施。
①主要模块
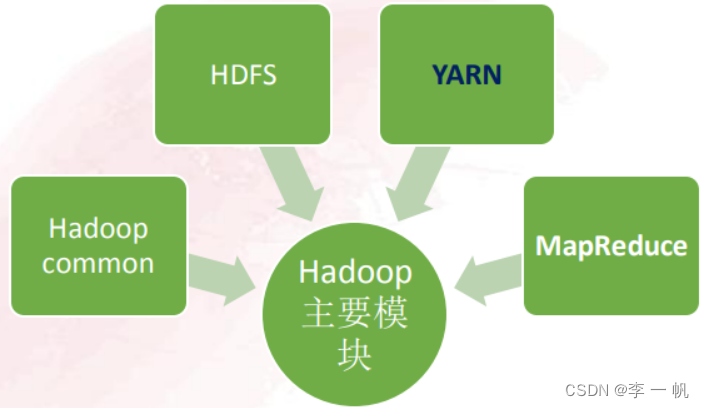
- Hadoop Distributed File System (HDFS):可以运行在低成本通用计算机上的分布式文件系统,是GFS的开源实现。HDFS的数据存储采用master/slave架构模式,主要由HDFS Client、NameNode、Secondary NameNode和Data Node组成
- NameNode:负责存储并维护文件的元数据信息,包括命名空间、访问控制信息、文件和Block的映射信息、以及Block的位置信息,对外提供创建、打开、删除和重命名文件或目录的服务
- DataNode:负责存储实际文件数据,处理客户端对数据的读写请求。它定期向NameNode发送心跳信息,NameNode通过响应心跳信息来给DataNode传达命令。客户端读写数据时,先与 NameNode交互获取元数据信息,然后和DataNode通信读取或写入实际数据。
- Secondary NameNode:辅助 NameNode完成元数据信息的合并

HDFS各个实体间的通信方式:简单交互Hadoop RPC实现,交互大量数据时,使用基于TCP或基于HTTP的流式接口

HDFS特性(相比于普通的文件系统):
| 特性 | 解释 |
|---|---|
| 存储容量大 | HDFS的总数据存储容量可以达到PB级,并且容量随着集群中节点数的增加而线性增长。另外,HDFS中存储的文件也可以很大,典型的文件大小从G bytes 到T bytes |
| 分布式存储 | HDFS中存储的大文件被框架自动分布到多个节点上存储,文件的大小可以大于集群中任意一个物理磁盘的容量。客户端在读写文件时不用关心数据的具体存储位置。HDFS总容量随着集群中节点数的增加而线性增长。 |
| 高度容错 | 快速自动的故障恢复是HDFS的核心设计目标之一。HDFS通过自动维护多个数据副本和在故障发生时自动重新部署处理逻辑来实现高可靠性。NameNode和 DataNode上都部署了周密的错误检测和自动恢复机制。对大规模HDFS集群 (几千个节点)来说,每天都会有一两个节点失效。集群一般能很快将失效 节点上的Block副本在其他DataNode节点上重新创建出来。 |
| 高吞吐量 | 应用程序需要通过流方式访问HDFS中的数据。HDFS设计为批处理模式,而不是交互模式,它强调高吞吐量而不是低延时。HDFS是为高数据吞吐量应用优化的,而这可能会以高时间延迟为代价。 |
| 高可扩展 | HDFS无需停机动态扩容,并且系统的计算和存储能力几乎能够随着集群节点数的增加线性增长。HDFS能够实时增加服务器台数来应对一些高峰或者突发服务需求。 |
| 负载均衡 | HDFS能够在运行时刻根据各个数据存储节点的可用存储容量变化和实际负载情况动态调整数据在多个节点上的分布,即具有一定的负载均衡能力 |
- MapReduce:一个分布式计算框架,是Google MapReduce的开源实现。
MapReduce能够将任务可以被分解为多个子问题,这些子问题相对独立,彼此之间不会有牵制,可以并行处理,待并行处理完这些子问题后,任务便被解决。
常见海里数据处理问题:
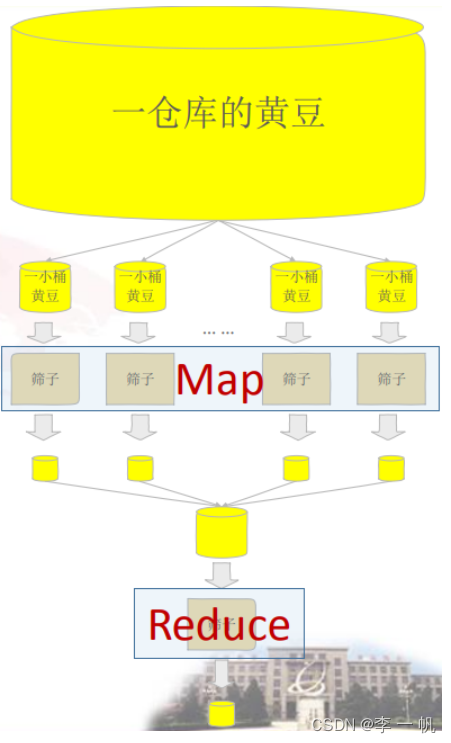
Top K:找出一仓库黄豆中最大的K个黄豆
方案1:一个很熟练的人筛黄豆,直到找出最大的K个(高性能计算)
方案2:找N个人一起筛黄豆,最后把每个人筛出的K个黄豆放在一起 (总共N × K个黄豆),再交由一 个人筛出N × K个黄豆里最大的K个(分布式计算)
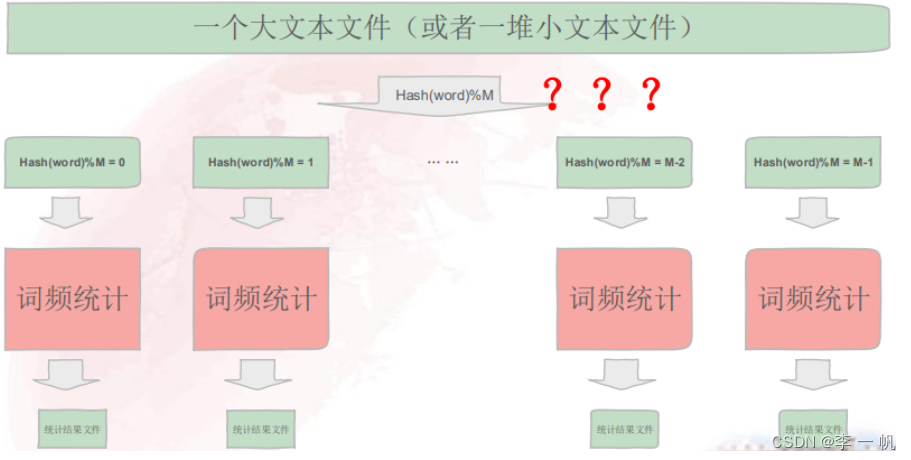
频率统计:统计一个大文本文件(或者一堆小文件)中的词频
方案1:一台依次扫描文件进行词频统计(高性能计算)若单词数很多,假设一个单词1B,则n GB内存的计算机最多处理具有nG个不同单词的词频统计
方案2:顺序读取大文件,对于每个词x,取,然后按照该值存到N个 小文件,再使用N台计算机分别扫描这N个小文件块统计文件词频,再将 这N台计算机的结果汇总得到最后的词频汇总(分布式计算/分而治之)

MapReduce 编程模型:
MapReduce由两个阶段完成:Map阶段和Reduce阶段。用户只需编写map()和reduce()两个函数,即可完成简单的分布式程序的设计:
Map():以k-v作为输入,产生一系列的k-v作为中间结果输出写入本地磁盘。MapReduce框架会自动将这些中间数据按照key值进行分区,且key值分区结果相同的数据会被交给同一个reduce()函数处理
Reduce():以key以及对应的value列表(即<key,list>)作为输入, 经过合并key相同的value值后,产生一系列的k-v对作为最终结果输出

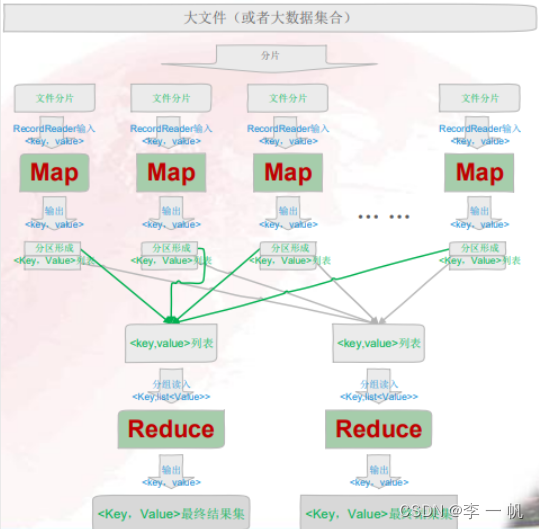
实例:
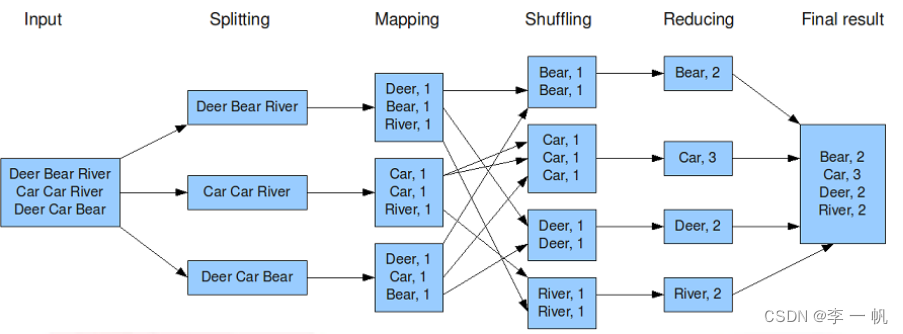
工作流:大文件(或大数据集集合) → 输入格式(InputFormat) → 输入分片(InputSplit)→ 记录读取(RecordReader) → Map → 排序Sort → Map端整合Combine → 分区Patition → 排序Sort → 分组Group → Reduce → 记录写入RecordWriter → 输出格式 OutputFormat
MapReduce架构:
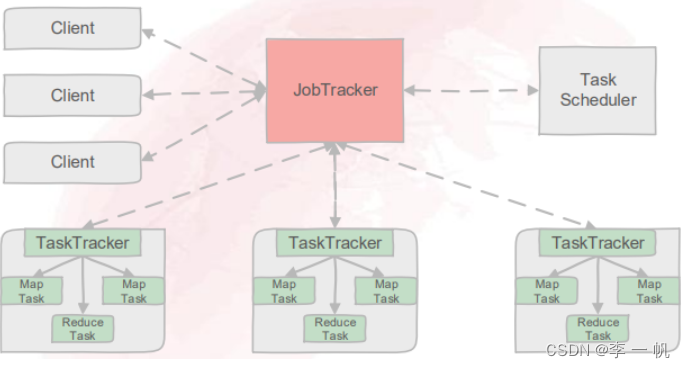
Client:用于提交用户编写的MapReduce程序
JobTracker:主要负责资源监控和作业调度
TaskTracker:周期性地通过心跳将本节点上资源的使用情况和任务运行的进度汇报给JobTracker。Task分为Map Task和Reduce Task,均由TaskTracker启动
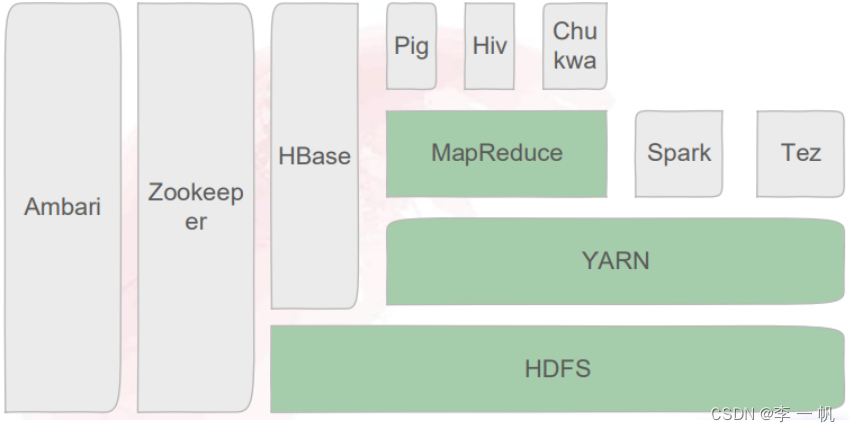
- Hadoop Common:支持其他模块的常用工具集,为在通用硬件上搭建云计算环境提供基础服务,并为运行在该平台上的软件开发提供了所需的API
- 配置信息处理模块
- Configuration类:处理配置信息
- Configurable接口:类的可配置性
- 序列化与反序列化机制
- Hadoop Writable机制:void write(DataOutput out)、void readFields(DataInputin)
- 其他序列化框架
- Avro数据序列化系统,用于支持大批量数据交换的应用
- Thrift一个可伸缩、跨语言的服务开发框架,由Facebook贡献
- Google Protocol
- 压缩框架:压缩广泛应用于海量数据处理中,对数据文件进行压缩,可以有效减少存储文件所需要的空间,并加快数据在网络上或者到磁盘上的传输速度。 在Hadoop中,压缩应用于文件存储的Map阶段到Reduce阶段的数据交换 (需要打开相关的选项)等情景
- 抽象文件系统FileSystem
- 为了提供对不同数据访问的一致接口,Hadoop借鉴了Linux虚拟文件系统的概念,引入了Hadoop抽象文件系统,并在Hadoop抽象文件系统的基础上,提供了大量的具体文件系统的实现,满足构建于Hadoop上应用的各种数据访问需求
- 抽象文件系统方法:处理文件和目录相关的操作;读写文件数据相关操作
- 文件系统的缓存CACHE
- 配置信息处理模块
- YARN(Yet Another Resource Negotiator):作业调度和集群资源管理框架,朝着多种框架进行统一管理的方向发展(MapReduce、Spark、Storm、S4、MPI等都可以在其上运行)。共享集群模式,具有资源利用率高、运营成本低、数据共享等特点
3)相关项目
- HBase:一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统的关系型数据库不同,HBase采用了Google BigTable的数据模型:增强的稀疏排序映射表(key/value),其中,键由行关键字、列关键字、和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
- Hive:一个构建在Hadoop上的数据仓库平台,提供了类似于SQL的查询语言HiveQL 以执行查询、变换数据等操作,通过解析,HiveQL语句在底层被转换为相应的MapReduce操作
- Spark:Spark是一个基于内存计算的开源集群计算系统,目的是让数据分析更加快速。Spark非常小巧,使用的语言是Scala。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。
- Zookeeper:一个高效、可靠的协同工作系统。解决分布式系统中的一致性问题,在此基础上,还可用于处理分布式应用中经常遇到的一些数据管理问题,如统一命名服务、状态同步服务、集群管理、分布式应用项的管理等。
4)缺点
- 优先考虑吞吐量,很难满足低时延
- master/slave结构,单点故障不可避免
- 一次写入多次读取,无法实现修改,只能覆盖或追加
- 网络带宽会成为系统瓶颈
- 采用Java实现,对于CPU密集型任务存在劣势
- 不适合小文件存储
- 存在安全问题
环境搭建
- 操作系统
虚拟机:VMWare
虚拟机硬盘:350G(实际至少给20G)
虚拟机内存:4G
操作系统:Ubuntu 18.04.6
- 安装JDK
sudo apt update
sudo apt install openjdk-8-jdk -y
java -version; javac -version
- 安装配置SSH
"""当前用户在{username下}"""
# 1.安装OpenSSH服务器和客户端
sudo apt install openssh-server openssh-client -y
# 2.修改sudoers文件为可修改状态
sudo chmod -v u+w /etc/sudoers
sudo vim /etc/sudoers
### 修改内容 ###
# User privilege specification
root ALL=(ALL:ALL) ALL
{username} ALL=(ALL:ALL) ALL # 要配置SSH免密的用户
# 3.免密SHH
# 生成密钥,定义存储位置
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 存储公钥至指定文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 设置权限
chmod 600 ~/.ssh/authorized_keys
# 验证,输入y|yes
ssh localhost
- 安装Hadoop
# 下载安装包,Downloads目录
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
# 解压安装包
sudo tar xzf hadoop-2.7.6.tar.gz -C /opt
# 重命名文件夹
sudo mv /opt/hadoop-2.7.6 /opt/hadoop
# 设置用户权限
sudo chown -R {username} /opt
- 配置Hadoop
### 单节点,伪分布模式 ###
# 进入用户目录
cd
# 1.配置环境变量
sudo vi .bashrc
# ===填写的内容=== #
# Hadoop Related Options
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/opt/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
# ===填写的内容=== #
# 更新环境变量
source ~/.bashrc
# 2.编辑hadoop-env.sh文件(此处不修改也可以,因为默认为系统的JAVA_HOME环境变量,上面已经配置了绝对路径)
sudo vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 3.编辑core-site.xml文件
sudo vi $HADOOP_HOME/etc/hadoop/core-site.xml
# ===填写的内容=== #
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
</configuration>
# ===填写的内容=== #
# 3.编辑hdfs-site.xml文件
sudo vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
# ===填写的内容=== #
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
# ===填写的内容=== #
# 4.编辑mapred-site.xml文件
cd $HADOOP_HOME/etc/hadoop/
sudo cp mapred-site.xml.template mapred-site.xml
sudo vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
# ===填写的内容=== #
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# ===填写的内容=== #
# 5.编辑yarn-site.xml文件
sudo vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
# ===填写的内容=== #
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
# ===填写的内容=== #
- 格式化HDFS节点
hdfs namenode -format # 该命令勿重复执行
- 启用Hadoop集群
# 1.关闭防火墙
sudo ufw disable
# 开启防火墙
# sudo ufw enable
# 2.启动hadoop:yes
start-all.sh
# start-all.sh
# start-dfs.sh
# start-yarn.sh
# 3.查询启动情况
jps
# 重新启动服务
# sudo service ssh restart
- 访问Hadoop界面
http://localhost:50070/
基础使用
# 启动hadoop
start-all.sh
# 查询启动情况
jps
# 设置hadoop用户为本地指定文件夹的所有者
sudo mkdir /data
cd /data
sudo chown -R hadoop /data
# 设置root用户为分布式文件系统指定文件夹的所有者
hadoop fs -chown -R root /user/hive/warehouse
### 修改文件权限
# 允许所有用户读写但不能执行
hadoop fs -chmod 666 /test.txt
# 允许所有用户所有操作
hadoop fs -chmod 777 /test.txt
# user为用户名,group用户组
hadoop fs -chown {user}:{group} /test.txt
hadoop fs -chown -R root /warehouse/test.txt
### 查看命令帮助
curl https://hadoop.apache.org/docs/r1.0.4/cn/
hadoop fs -help ls
### 文件操作
# 查看文件目录
hadoop fs -ls /
# 删除空目录
hadoop fs -rmdir /test
# 创建文件夹
hadoop fs -mkdir /test
# 删除文件夹,recursion递归,递归删除文件夹及文件
hadoop fs -rm -r /test
# 创建文件
hadoop fs -touchz /test.txt
# 删除文件
hadoop fs -rm -r /test.txt
hadoop fs -rm /test.txt
# 重命名
hadoop fs -mv /aaa /bbb
# 复制文件
hadoop fs -cp /aaa/test.txt /bbb
# 移动文件
hadoop fs -mv /aaa/test.txt /bb
# 追加内容
hadoop fs -appendToFile /file1.txt /file2.txt
# 将HDFS文件复制至本地
hadoop fs -get /warehouse/test.txt /local
hadoop fs -copyToLocal /warehouse/test.txt /local
# 将本地文件复制到HDFS
hadoop fs -put /local/test.txt /warehouse
hadoop fs -copyFromLocal /local/test.txt /warehouse
# 将本地文件剪切到HDFS
hadoop fs -moveFromLocal /local/test.txt /warehouse
# 设置文件副本数量
hadoop fs -setrep 3 /test.txt
# 合并下载多个文件
hadoop fs -getmerge /warehouse/* local/test.txt
# 查看文件信息
# 查看文件的全部内容
hadoop fs -cat /test.txt
# 打印文件内容
hadoop fs -text /test.txt
# 统计文件系统的可用空间信息
hadoop fs -df -h /
# 统计指定目录下的文件节点数量
hadoop fs -count /test/
# 统计文件夹的大小信息
hadoop fs -du -s -h /test
# 查看文件的末尾内容
hadoop fs -tail /test.txt
2.Mysql环境搭建
# 1.安装mysql服务
sudo apt-get install mysql-server
# 2.安装配置
sudo mysql_secure_installation
# 2.1选择N,不会进行密码的强校验
# 2.2密码设置
# 2.3选择N,不删除匿名用户
# 2.4选择N,允许root远程连接
# 2.5选择N,不删除test数据库
# 2.6选择Y,修改权限立即生效
# 3.查看服务状态
systemctl status mysql.service
# 4.允许远程访问
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
# ===填写的内容=== #
bind-address = 0.0.0.0
# ===填写的内容=== #
# 5.重启mysql
sudo /etc/init.d/mysql restart
# 6.进入mysql服务配置
# 进入mysql服务
sudo mysql -uroot -p
# 切换数据库
use mysql;
# 查询用户表
select user, authentication_string, host, plugin from user;
# 修改加密规则
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '{密码}';
# 更新用户密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '{密码}' PASSWORD EXPIRE NEVER;
# 允许远程访问
UPDATE user SET host = '%' WHERE user = 'root';
# 刷新权限
flush privileges;
# 退出mysql服务
quit;
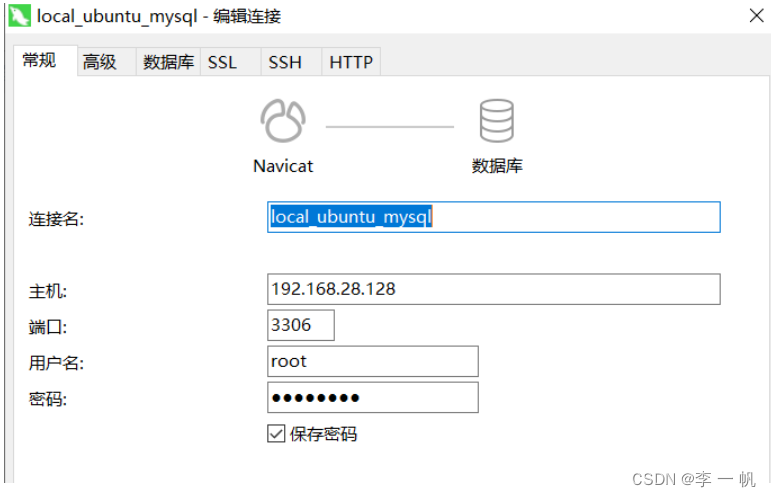
# 7.本机navicate连接虚拟机mysql
# 开启3306防火墙
firewall-cmd --query-port=3306/tcp # 查询端口3306是否被开放
firewall-cmd --add-port=3306/tcp # 开启3306端口通过防火墙
# 查询虚拟机网络ip
ifconfig
3.Hive概述
1)Hive简介
Hive是基于Hadoop的一个数据仓库工具,将结构化的数据映射为一张二维表且提供类SQL的查询功能。其本质就是将SQL语句转换为MapReduce/Spark程序进行运算,底层数据由HDFS分布式文件系统进行存储。可以简单地将Hive理解为MapReduce/Spark的客户端
MapReduce学习成本较高,而项目周期要求太短时,若要实现复杂的查询逻辑,则开发难度较大。Hive的接口类似于SQL语法,可以提高开发效率,而且提供了功能扩展。
Hive的特点
- 可扩展性:可以自由扩展集群的规模
- 延展性:支持用户自定义函数,开发灵活
- 容错性:结点出现问题SQL仍可以完成执行
2)Hive架构
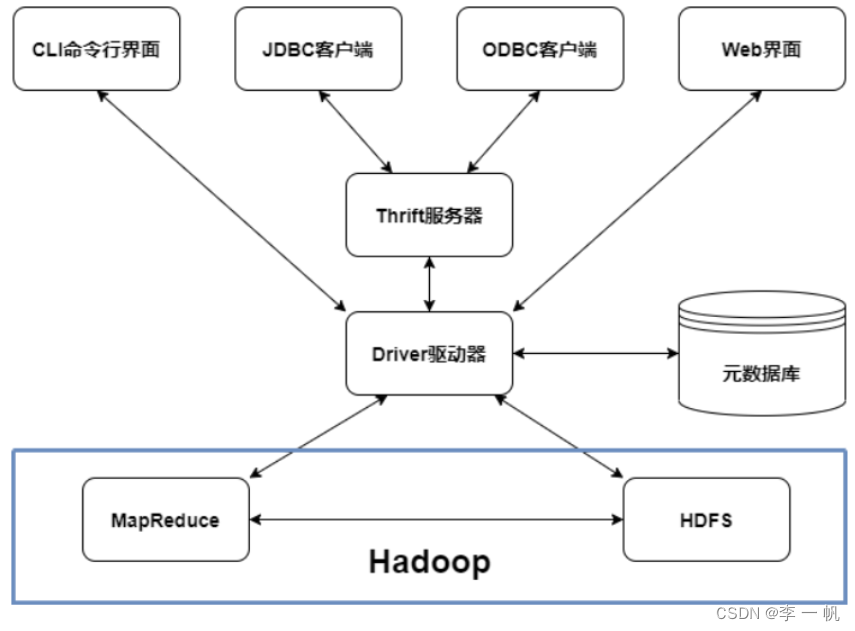
- 用户接口
- CLI:shell命令行界面
- JDBC:Java数据库连接
- ODBC:开放数据库连接
- WebGUI:Web图形用户界面
- 元数据库:存储表名、列名、分区属性、数据所在目录等元数据,元数据一般存储在关系型数据库如derby(默认)、mysql
- 驱动器:将HiveSQL进行解析、编译、优化并生成执行计划,然后调用底层的MapReduce计算框架
3)Hive与Hadoop的关系
提交SQL语句 → Hive将SQL语句转换为MapReduce程序 → 执行MapReduce程序 → HDFS分布式文件系统
4)Hive与关系型数据库对比
Hive的表面与关系型数据类似,但应用场景完全不同,Hive只适合用来做大规模数据的离线处理及分析
- 数据更新或删除:数据仓库是读多写少,所以不支持update、delete
- 执行延迟:Hive没有索引,需要扫描全表,另外MapReduce本身具有较高的延迟,所以大规模数据才能体现出其优势
- 数据规模:Hive建立在集群上,利用MapReduce进行并行计算,所以支持大规模数据
| Hive | RDBMS | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS分布式文件系统 | 原始设备与本地文件 |
| 执行引擎 | MapReduce | Excutor |
| 执行延迟 | 高 | 低 |
| 数据规模 | 大 | 小 |
| 索引 | 无 | 有复杂索引 |
5)Hive数据存储
- 数据存储格式
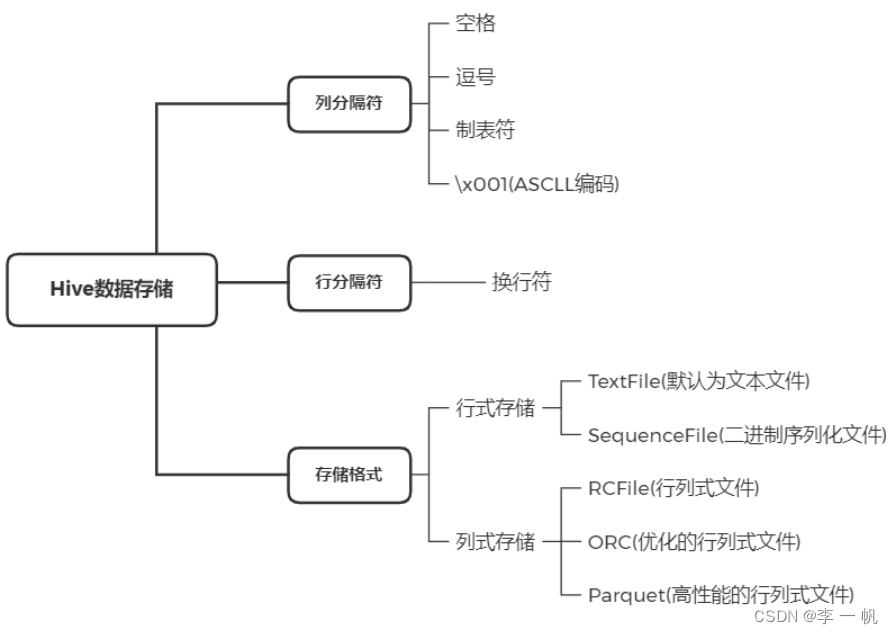
- 数据存储模型
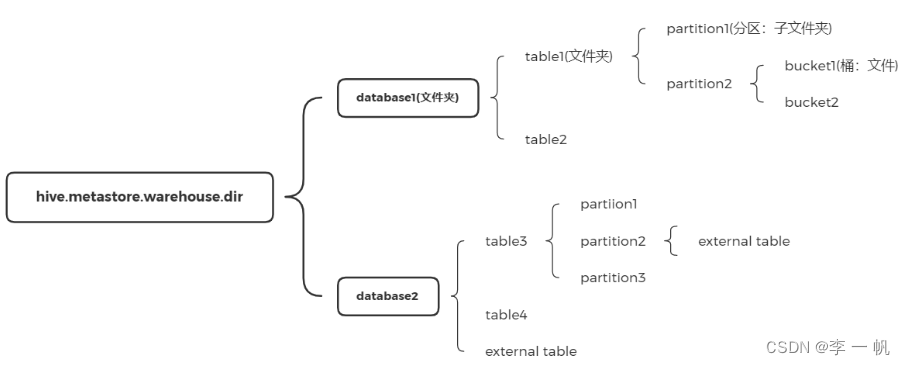
- 数据类型

6)Hive的计算引擎
MapReduce、Tez、Spark
set hive.execution.engine=mr;
set hive.execution.engine=spark;
set hive.execution.engine=tez;
4.Hive环境搭建
Mysql
-
在之前虚拟机上搭建的mysql环境中创建
myhive数据库,并设置字符编码为UTF8格式,作为Hive的元数据库 -
下载JDBC的配置包:
https://dev.mysql.com/downloads/connector/j
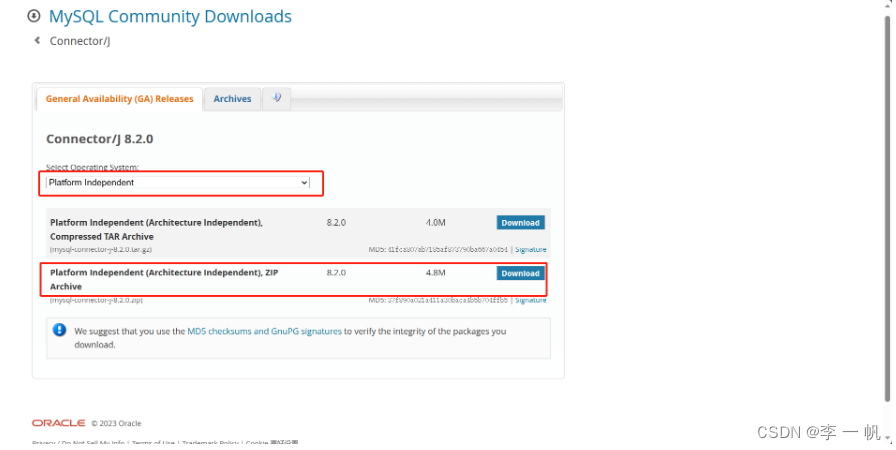
选择平台独立的ZIP包,注意8.2.0正常对应的是Ubuntu的22.04以上版本,Ubuntu的18.04.6版本正常对应的应该是JDBC配置包的8.0.25版本。
将该ZIP包下载/上传到虚拟机用户目录的Downloads目录下
Hive
# 1.下载安装包,Downloads目录
wget http://archive.apache.org/dist/hive/hive-2.1.1/apache-hive-2.1.1-bin.tar.gz
# 2.解压安装包
sudo tar xzf apache-hive-2.1.1-bin.tar.gz -C /opt
# 3.重命名文件夹
sudo mv /opt/apache-hive-2.1.1-bin /opt/hive
# 4.设置用户权限
sudo chown -R {user} /opt
# 5.配置环境变量
# 进入用户家目录
cd
sudo vi .bashrc
# ===填写的内容=== #
# Hive Related Options
export HIVE_HOME=/opt/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
export PATH=$PATH:$HIVE_HOME/bin
# ===填写的内容=== #
# 使环境变量生效
source ~/.bashrc
# 6.编辑 hive-config.sh 文件
sudo vi $HIVE_HOME/bin/hive-config.sh
# ===填写的内容=== #
export HADOOP_HOME=/opt/hadoop
# ===填写的内容=== #
# 7.hdfs分布式文件系统上创建两个hive目录并赋予读写权限(这一步注意保证hadoop服务启动)
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -mkdir -p /tmp/hive
hadoop fs -chmod -R 777 /user/hive/warehouse
hadoop fs -chmod -R 777 /tmp/hive
# 8.配置hive-site.xml文件
cd $HIVE_HOME/conf
# 使用hive-default.xml模板创建hive-site.xml文件
cp hive-default.xml.template hive-site.xml
sudo vi hive-site.xml
# 清空文件内容
:%d
# ===填写的内容=== #
<configuration>
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>1</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/myhive?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>{密码}</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>{密码}</value>
</property>
<!-- 免密登陆(可选) -->
<!--
<property>
<name>hive.server2.authentication</name>
<value>NOSASL</value>
</property>
-->
</configuration>
# ===填写的内容=== #
# 9.配置hive-env.sh文件
cd $HIVE_HOME/conf
# 使用hive-env.sh.template模板创建hive-env.sh文件
cp hive-env.sh.template hive-env.sh
sudo vi hive-env.sh
# ===填写的内容=== #
export HADOOP_HOME=/opt/hadoop
export HIVE_CONF_DIR=/opt/hive/conf
export HIVE_AUX_JARS_PATH=/opt/hive/lib
# ===填写的内容=== #
# 10.设置hive的JDBC配置包
# 解压JDBC配置包至/opt目录
sudo unzip -d /opt mysql-connector-j-8.2.0.zip
cd /opt/mysql-connector-j.8.2.0
cd bin
# 将JDBC配置包拷贝至/opt/hive/lib目录下
sudo mv mysql-connector-j-8.2.0.jar /opt/hive/lib
# 11.初始化Hive元数据对应的MySQL数据库
cd /opt/hive/lib
schematool -initSchema -dbType mysql
# 12.启动hive
hive --service metastore &
hive --service hiveserver2 &
# 13.进入hive服务(检测环境搭建是否成功)
hive
show databases;
5.Hive基础使用
-
DDL(数据定义语言 Data Definition Language):①对数据库的操作②对数据表的操作
-
DQL(数据查询语言 Data Query Language):①单表查询、多表查询 ②常用函数:聚合函数、条件函数、日期函数、字符串函数等 ③高级函数:多行合并、单行拆分 ④窗口函数、增强聚合函数
-
DML(数据操纵语言 Data Manipulation Language):insert into、insert overwrite、update不支持、delete不支持
-
DCL(数据控制语言 Data Control Language):grant授权、revoke撤销
准备工作:数据文件目录创建
# 本地创建目录
sudo mkdir -p /data/import
sudo mkdir -p /data/export
# 修改本地目录权限
sudo chown -R {user} /data
# hdfs创建目录
hadoop fs -mkdir /user/hive/warehouse/import
hadoop fs -mkdir /user/hive/warehouse/export
# 修改hdfs目录权限
hadoop fs -chown -R root /user/hive/warehouse
虚拟机上/data用于存储数据,/data/import/目录用于数据的上传导入,/data/export/目录用于计算、处理后数据的导出
数据库的操作
# 1.创建数据库并添加注释, hdfs新增test.db文件夹
create database if not exists test comment 'hive test database';
# 2.展示所有库
show databases;
# 3.使用test库
use test;
# 4.展示当前库下所有表
show tables;
# 5.修改数据库的属性信息
alter database test set dbproperties('createtime'='20221011');
# 6.不支持修改库名
# 7.查看数据库的基本信息
describe database test;
# 8.查看数据库的详细信息
describe database extended test;
# 9.删除数据库(库下无表), 如库下有表则报错, hdfs删除test.db文件夹
# drop database test;
# 10.删除数据库(无论库下是否有表 强制删除, 执行前备份)
# drop database test cascade;
表的类型与表级操作
- 准备工作:上传数据
### 上传数据 ###
sudo mkdir /data/test1
cd /data/test1
# 上传 person.txt
# 进入hive服务
hive
### 导入本地数据 ###
# hdfs创建文件夹
hadoop fs -mkdir /user/hive/warehouse/test.db/person
# 从本地向hdfs推送数据文件
hadoop fs -put /data/test1/person.txt /user/hive/warehouse/test.db/person
# 退出hive服务
exit;
- 内部表(受控表)
数据均存储在配置文件hive-site.xml指定的hive.metastore.warehouse.dir目录下。内部表与关系型数据库的表类似,每个表都有自己的存储目录。当表定义被删除(删除表)的时候,表中的数据随之(hdfs上的数据和元数据)均被删除。内部表与关系型数据库的表类似, 每个表都有自己的存储目录
# 创建内部表
create table if not exists test.person(
id int comment '工号',
name string comment '姓名',
sex string comment '性别')
row format delimited
fields terminated by ','
location '/user/hive/warehouse/test.db/person'; # 指定hdfs存储位置,若不设置默认就在Hive的工作目录区
# 表查询
select * from test.person;
# 删除内部表, 元数据和数据文件均会删除
# drop table test.person;
# 创建一张表和已存在的一张表的结构相同,只会创建表结构
create table person1 like person;
# 创建一张表和已存在的一张表的结构相同,还可以带有数据,并且插入数据查哪个字段就会插入哪个字段的数据。
create table person2 AS SELECT id,name,sex from person;
# 查看表描述信息:EXTENDED极简的方式显示(默认就是极简的方式)、FORMATTED格式化方式来显示
DESCRIBE [EXTENDED|FORMATTED] person;
# 查看建表语句
show create table test.person;
- 外部表
数据存在与否和表的定义互不约束,仅仅只是表对hdfs上相应文件的一个引用,当删除表定义的时候,表中的数据依然存在
# 创建外部表, external关键字
create external table if not exists test.person(
id int comment '工号',
name string comment '姓名',
sex string comment '性别')
row format delimited
fields terminated by ','
location '/user/hive/warehouse/test.db/person'; # 指定hdfs存储位置
# 删除外部表, 只删除元数据而不删除数据文件, 其他方面和内部表类似
drop table test.person;
- 内外部表的互相转换
# 内 → 外
alter table {表名} set tblproperties('EXTERNAL'='TRUE');
# 外 → 内
alter table {表名} set tblproperties('EXTERNAL'='FALSE');
-
临时表(测试环境):在当前会话期间内存在,会话结束自动消失,生命周期随之session
-
分区表:将一批数据分成多个目录来存储,以防止力扫描全表,可以提高查询效率。
- 静态分区表
### 单分区表 ### # 指定分区 create table day_table (id int, content string) partitioned by (dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ; # 操作单分区表 # insert单条插入的方式往分区表中插入数据 insert into day_table partition (dt = "9-26") values(1,"anb"); # load批量插入的方式往分区表中插入数据 # load data local inpath "/root/ceshi" into table day_table partition (dt="9-27"); # 删除Hive分区表中的分区 # ALTER TABLE day_table DROP PARTITION (dt="9-27"); ### 多分区表 ### create table day_hour_table (id int, content string) partitioned by (dt int,hour int) # 指定多个分区 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ; # 操作多分区表 # insert单条插入的方式往分区表中插入数据 insert into day_hour_table partition(dt=9,hour=1) values(1,"a2 bc"); # load批量插入的方式往分区表中插入数据 # load data local inpath "/root/ceshi" into table day_table partition (dt=10,hour=10); # 删除Hive分区表中的分区 # LTER TABLE day_table DROP PARTITION (dt=10,hour=10); # 创建一个空分区,然后将数据上传到空分区对应的目录下,分区表中就会显示数据 ALTER TABLE day_hour_table ADD PARTITION (dt=10000, hour=2000); # 创建一个空分区并且将空分区指向数据位置 # ALTER TABLE day_hour_table ADD PARTITION (dt=10000, hour=2000) location "/test" # 往分区中添加数据的五种方式 # (1)insert 指定分区 # (2)load data 指定分区 # (3)查询已有表的数据,insert到新表中 # from day_hour_table insert into table newt partition(dt=01,hour=9898) select id,content # (4)alter table add partition创建空分区,然后使用HDFS命令往空分区目录中上传数据 # (5)创建分区,并且指定分区数据的位置- 动态分区表
静态分区表,一个文件数据只能导入到某一个分区中,并且分区是用户指定的,这种方式 不够灵活,业务场景比较局限。动态分区可以根据数据本身的特征自动来划分分区,比如 我们可以指定按照数据中的年龄、性别来动态分区。使用动态分区表
# 启用动态分区表 # 开启动态分区 set hive.exec.dynamic.partition=true; # 使用非严格模式。严格模式是指必须要有一个静态分区 set hive.exec.dynamic.partition.mode=nostrict; # 创建动态分区表:创建动态分区表的语句与创建静态分区表的语句是一模一样的,只是在指定分区的时候用表中的字段来指定 create table if not exists test.person_p( id int comment '工号', name string comment '姓名', sex string comment '性别') partitioned by( province string comment '省份', city string comment '城市') row format delimited fields terminated by ','; # 往动态分区表中加载数据:往动态分区表中加载数据不能使用 load data 。load data只是将数据上传到HDFS指定目录中。使用load data往分区表导入数据的时候,都是要指定partition分区的,这样他才会知道将数据上传到HDFS的哪一个分区。所以得采用 from insert的方式往动态分区表中插入数据。 # 查看分区数:动态,静态都可以查看 show partitions test.person_p; -
分桶表
分桶表就是按指定列进行哈希(hash)计算,然后根据hash值进行切分,将具有不同hash值的数据写入每个桶对应的文件中。由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中 对于hive中每一个表、分区都可以进一步进行分桶。 好处:提高了join的效率;提高了随机抽样的效率。
# 启用分桶表
set hive.enforce.bucketing=true;
# 创建分桶表
create table if not exists test.person_p(
id int comment '工号',
name string comment '姓名',
sex string comment '性别')
partitioned by(
province string comment '省份',
city string comment '城市')
clustered by (sex) sorted by (id) into 2 buckets
row format delimited
fields terminated by ',';
# 往分桶表中插入数据:不能使用load data,只能使用insert
# 抽样
# X代表从哪个桶开始抽取数据
# Y必须为该表总桶数的倍数或因子,表示步长
select * from test.person_p tablesample(bucket X out of Y on age);
- 修改和删除表
create table test.person2 as select * from test.person;
# 修改表名称
alter table test.person rename to test.person_new;
# 新增表的字段
alter table test.person_new add columns(email string, addr string);
# 修改表的字段类型
alter table test.person_new change column addr addr varchar(1000);
# 删除表的字段, 通过替换来删除,不支持drop column
alter table test.person_new replace columns(t_id int, t_name string, email string);
# 删除外部表只删元数据, 不删除数据文件
drop table test.person_new;
# 清空表数据
truncate table test.person_new;
视图
通过隐藏复杂的操作过程(表关联\子查询\分组\聚合\筛选\窗口函数等)来简化查询,通过视图屏蔽敏感信息
# 创建视图表
create view test.person_view as
select
ps.t ,
ps.g
from test.person ps ;
# 查询视图表
select * from test.person_view;
# 查看视图表的建表语句
show create table test.person_view;
# 删除视图(不会删除数据文件)
# drop view test.person_view;
# 重新定义视图
alter view test.person_view as
select
ps.t,
ps.ame,
ps.g
from test.person ps ;
表数据导入与导出
-
导入
-
insert into方式向分区表中加载数据(insert into插入、insert overwrite更新)
-
查询方式向分区表中加载数据
-
location方式从hdfs中加载数据(外部表)
-
load data方式向分区表中加载数据
# 1.解决hive导入时中文乱码 vim {文件}.csv # 内容 :set fileencoding=utf8 :set fileencodings=utf8 # 2.建表 # 3.导入数据 # 3.1从本地文件系统中导入数据,其实就是先将数据文件临时复制到HDFS的一个目录下,再从那个临时目录将数据文件移动到对应表的数据目录中 # 3.2从HDFS上导入数据(两者的语法是相同的)[overwrite]是否覆盖 load data inpath '{path}/{filename}.txt' [overwrite] into table tablename; -
export的导入与Import的导入(内部表)
# export导出表数据到hdfs export table test.person to '/user/hive/warehouse/export/person'; # import导入表数据.必须是export导出的数据, 目录下必须得有_metadata和data create table test.person_import like test.person; import table test.person_import from '/user/hive/warehouse/export/person';
-
-
导出
-
insert导出
# 将查询结果导出至本地 insert overwrite local directory '/data/export/score' select * from edu.score; # 将查询结果格式化后导出至本地 insert overwrite local directory '/data/export/score' row format delimited fields terminated by '\t' select * from edu.score; # 将查询结果格式化后导出至hdfs insert overwrite directory '/user/hive/warehouse/export/student' row format delimited fields terminated by '\t' select * from edu.student; -
hadoop shell命令导出到本地
hadoop fs -get /user/hive/warehouse/edu.db/student/edu_student.csv /data/export/edu_student.csv -
hive shell命令导出到本地
hive -e "select * from edu.teacher;" > /data/export/edu_teacher.csv
-
DQL
select all | distinct col1, col2, ...
from db.table_name
join db.table_name on '连接条件'
where '分组前筛选'
group by '分组字段'
having '分组后筛选'
cluster by '分区及局部排序字段' | distribute by '分区字段'
sort by '局部排序字段' | order by '全局排序字段'
limit '限制行数'
- 单表查询:where筛选、group by分组
- 多表查询:join连接
# 内连接
select * from edu.teacher t
inner join edu.course c on c.t_id = t.t_id;
# 内连接
select * from edu.teacher t, edu.course c
where c.t_id = t.t_id;
# 左连接
select * from edu.teacher t
left join edu.course c on c.t_id = t.t_id;
# 右连接
select * from edu.teacher t
right join edu.course c on c.t_id = t.t_id;
# 全连接
select * from edu.teacher t
full join edu.course c on c.t_id = t.t_id;
- 数据抽样与排序
-
随机抽样
# 设置reduce个数 set mapreduce.job.reduces=3; # 查询reduce个数 set mapreduce.job.reduces; # 随机分区,按指定列升序 select * from test.person distribute by rand() sort by s_score [asc|desc] limit 2; # 随机分区,随机升序 select * from test.person distribute by rand() sort by rand() limit 2; # 等价写法:distribute by rand() sort by rand() 等价于 cluster by rand() select * from test.person cluster by rand() limit 2; # 全局排序,慎用 select * from test.person order by rand() [asc|desc]; -
块抽样
# 按比例抽样 select * from test.person tablesample(10 percent); # 按大小抽样,单位为字节 select * from test.person tablesample(200B); # 按行数抽样 select * from test.person tablesample(10 rows); -
分桶抽样
# 将表随机分成10组, 抽取其中1组数据 select * from test.person tablesample(bucket 1 out of 10 on rand());
-
常用运算
- 关系运算
- 等值(=)、不等值(!= 或 <>)、小于(<)、小于等于(<=)、大于(>)、大于等于(>=)、空值判断(is null)、非空判断(is not null)
- LIKE模糊匹配:A LIKE B,如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B的正则语法,则为TRUE;否则为 FALSE。B中字符“_”表示任意单个字符,而字符“%”表示任意数量的字符。
- RLIKE模糊匹配(JAVA正则表达式)
- REGEXP模糊匹配(通用正则表达式)
- 数学运算:加(+)、减(-)、乘(*)、除(/)、取余(%)、位与(&)、位或(|)、位异或(^)、位取反(~)
- 逻辑运算:与(and)、或(or)、非(not)(注意:and优先级高于or)
- 数值运算
- 取整函数: round(double a)、指定精度取整函数:round(double a, int d)
- 向下取整函数: floor、向上取整函数: ceil
- 取随机数函数: rand
- 自然指数函数: exp、以10为底对数函数: log10、幂运算函数: pow、开平方函数: sqrt
- 二进制函数: bin
常用函数
- 聚合函数
- count():count(*)包含null,count(id)不含null
- max(),min(),sum(),avg()
- var_pop(col):统计总体方差(忽略null)
- var_samp(col):统计样本方差(忽略null)
- stddev_pop(col):统计总体标准差(忽略null)
- stddev_samp(col):统计样本标准差(忽略null)
- percentile(BIGINT col, p):求指定分位点的数值,p介于0和1之间
- 排序函数
- row_number():1,2,3,4
- rank():1,2,2,4
- dense_rank():1,2,2,3
- 偏移函数
- 按相对位置偏移
- lead(expr, n):向前偏移,返回当前行的前n行的值
- lag(expr, n):向后偏移,返回当前行的后n行的值
- 按绝对位置偏移
- first_value(expr):返回首行的值
- last_value(expr):返回尾行的值
- nth_value(expr, n):返回第n行的值(Hive不支持,MySQL支持)
- 按相对位置偏移
- 分桶函数:ntile(n):将数据集分为n桶,返回分桶的序号
- 分布函数
- cume_dist():小于等于当前行rank值的行数 / 总行数
- percent_rank():(当前行rank值-1) / (总行数-1)
- 聚合增强函数(加强版group by;Hive支持,MySQL不支持)
- grouping sets(区域, (区域,产品))
- grouping__id,维度组合的ID
- cube
- rollup(cube的子集)
- 条件函数
- If函数:
if(boolean testCondition, T valueTrue, T valueFalseOrNull),当条件testCondition为TRUE时,返回valueTrue,否则返回valueFalseOrNullselect if(1=1, 100, 200); - 非空查找函数: coalesce(T v1, T v2, …),返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL
select coalesce(null, '100', '50'); - 条件判断函数(其一):
case when a then b [when c then d]...[else e] end,如果a为TRUE,则返回b;如果c为TRUE,则返回d,否则返回eselect case when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end - 条件判断函数(其二):
case a when b then c [when d then e]...[else e] end,如果a等于b,则返回c,如果a等于d,则返回e,否则返回eselect case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end
- If函数:
- 日期函数
- unix_timestamp():获得当前时区的UNIX时间戳
select unix_timestamp(); - from_unixtime(bigint unixtime[, string format]):UNIX时间戳转日期函数
select from_unixtime(1616906976, 'yyyy-MM-dd'); - unix_timestamp(string date):日期转UNIX时间戳
select unix_timestamp('2021-03-08 14:21:15'); - unix_timestamp(string date, string pattern):指定格式日期转UNIX时间戳
select unix_timestamp('2021-03-08 14:21:15', 'yyyy-MM-dd HH:mm:ss'); - to_date(string timestamp):日期时间转日期函数
select to_date('2021-03-28 14:03:01'); - 日期取年、月、日、时、分钟、秒、周函数:year(string date)、month (string date)、day (string date)、hour (string date)、minute (string date)、second (string date)、weekofyear (string date)
- datediff(string enddate, string startdate):日期比较函数,返回结束日期减去开始日期的天数
select datediff('2020-12-08','2012-05-09'); - date_add(string startdate, int days):日期增加函数,返回开始日期startdate增加days天后的日期
select date_add('2020-12-08', 10); - date_sub (string startdate, int days):日期减少函数
select date_sub('2020-12-08', 10);
- unix_timestamp():获得当前时区的UNIX时间戳
- 字符串函数
- 字符串长度函数:length
- 字符串反转函数:reverse
- 字符串连接函数:concat
- 带分隔符字符串连接函数:concat_ws
- 字符串截取函数:substr, substring
- 字符串转大写函数:upper, ucase
- 字符串转小写函数:lower, lcase
- 去空格函数:trim
- 左边去空格函数:ltrim、右边去空格函数:rtrim
- 正则表达式替换函数:regexp_replace、正则表达式解析函数:regexp_extract
- URL解析函数:parse_url
- json解析函数:get_json_object
- 空格字符串函数:space
- 重复字符串函数:repeat
- 首字符ascii函数:ascii
- 左补足函数:lpad、右补足函数:rpad
- 分割字符串函数: split
- 集合查找函数: find_in_set
- 窗口函数
- 窗口函数指定了函数工作的数据窗口大小(以当前行为基准,上下多少行),这个数据窗口大小可能随着行的变化而改变。窗口函数与聚合函数相比,聚合函数对于每个组只返回一行数据,窗口函数对于每个组的每一行返回一行数据。
- over([partition by 列名] [order by 列名] [rows/range between 起始位 and 结束位])
- 若orver()中不添加任何函数,则窗口是整个分区的数据、partition by是分组,类似于group by,order by排序,rows between按行指定窗口范围,range between按数值指定窗口范围
复合类型数据常用操作
- 复合数据类型构建
- Map类型构建:
map(key1, value1, key2, value2, …),根据输入的key和value键值对,构建字典map类型create table map_table as select map('100', 'tom', '200', 'mary') as t; - Struct类型构建:
struct(val1, val2, val3, …),根据输入的参数,构建结构体struct类型create table struct_table as select struct("tom", "mary", "tim") as t; - array类型构建:
array(val1, val2, …),根据输入的参数,构建数组array类型create table array_table as select array("tom", "mary", "tim") as t; - uniontype类型构建:
create_union (tag, val1, val2, …),根据输入的tag和表达式,构建联合体uniontype类型。tag表示使用第tag个表达式作为uniontype的valuecreate table uniontype_table as select create_union(2, 'a', array(1, 2, 3), map('b', 1, 'c', 2)) as t;
- Map类型构建:
- 复合数据类型访问
- array类型访问:array[index]
select t[0], t[1] from array_table; - map类型访问:map[key]
select t['200'], t['100'] from map_table; - struct类型访问:struct.column
select t.col1, t.col3 from struct_table;
- array类型访问:array[index]
- 复合数据类型长度统计
- map类型长度函数: size(Map)
select size(t) from map_table; - array类型长度函数: size(Array)
select size(t) from array_table;
- map类型长度函数: size(Map)
数据透视
Hive 中实现数据透视_hive 透视表sql-CSDN博客
lateral view 与 explode 行列转换
Hive SQL中的 lateral view 与 explode(列转行)以及行转列-CSDN博客
reflect函数
reflect函数支持调用java函数
-- 调用java的max函数求两列最大值
select
*, reflect('java.lang.Math', 'max', quality, service) as max_score
from test.test_reflect;
-- 不同的行执行不同的java函数
select
tb.order_id
, tb.product
, tb.quality
, tb.service
, reflect('java.lang.Math', method_name, tb.quality, tb.service) as score
from (
select
t.order_id
,t.product
,t.quality
,t.service
, case t.product when '配饰' then 'max'
when '服饰' then 'min' end as method_name
from test.test_reflect t
) as tb;
执行计划 explain
- explain:查看基本信息
使用场景举例:查看join是否会过滤null、group by会排序么、比较两种查询语句的性能
explain
select
sc.s_id, avg(sc.s_score) as avg_score
from edu.student s
join edu.score sc on sc.s_id = s.s_id
where s.s_class = 3
group by sc.s_id
having avg(sc.s_score) > 60
order by avg_score desc
limit 3;
- explain dependency:用于描述数据来源,输出json格式,其中input_partitions描述数据来源的表分区,input_tables描述数据来源的表
使用场景举例:判断两代码是否等价
explain dependency select * from edu.student;
explain dependency select * from sm.sm_order_detail;
- explain authorization:查看授权信息
explain authorization
select s_id, s_name from edu.student;
性能调优
- union all
-- 创建数据库
create database test;
-- 创建分区表,最高分插入到max分区,最低分插入到min分区
create table test.course_max_min (
c_id int comment '课程id',
s_score int comment '分数'
) comment '每个课程的最高分和最低分'
partitioned by (tp string comment '分数类型');
-- 开启动态分区,分两次运行
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
-- 优化前, 同一张表分组两次(运行前开启动态分区)
-- Total jobs = 5
insert into table test.course_max_min partition(tp)
select
sc.c_id, max(sc.s_score) as s_score, 'max' as tp
from edu.score sc
group by sc.c_id
union all
select
sc.c_id, min(sc.s_score) as s_score, 'min' as tp
from edu.score sc
group by sc.c_id;
-- 优化后, 同一张表分组一次(运行前开启动态分区)
-- Total jobs = 1
from edu.score sc
insert into table test.course_max_min partition(tp)
select
sc.c_id, max(sc.s_score) as s_score, 'max' as tp
group by sc.c_id
insert into table test.course_max_min partition(tp)
select
sc.c_id, max(sc.s_score) as s_score, 'min' as tp
group by sc.c_id;
- distinct
-- 优化前
select count(1)
from(
select s_id
from edu.student
group by s_id
) tb;
-- 优化后
select count(distinct s_id)
from edu.student;
- left semi join
-- 通过退货表的订单编号筛选订单详情表的数据
-- 优化前, in子查询
select *
from sm.sm_order_detail_np a
where a.order_id in (
select b.order_id
from sm.sm_return_info b);
-- 优化前, exists子查询
select *
from sm.sm_order_detail_np a
where exists(
select b.*
from sm.sm_return_info b
where a.order_id = b.order_id)
-- 优化后, left semi join左半连接(执行效率更佳)
-- select子句只能选择左表的字段
-- on子句的过滤条件只能是等于号
-- 右表的过滤条件只能在on子句设置
select a.*
from sm.sm_order_detail_np a
left semi join sm.sm_return_info b on b.order_id = a.order_id;
- 并行执行优化
-- 启动并行执行
set hive.exec.parallel=true;
-- 设置并行执行的线程数量
set hive.exec.parallel.thread.number=16;
连接Hive
- python连接Hive
# 安装MapRHiveODBC64后,odbc登录hive即可
import pandas as pd
import pyodbc # pip install pyodbc
con = pyodbc.connect('DSN=hive', autocommit=True)
df = pd.read_sql('select * from edu.student', con=con)
- excel连接Hive
- Tableau连接Hive
6.数据仓库
基本概念
-
实体:数据分析的对象
-
维度:分析问题的角度
-
度量:是一个数值,衡量业务规模大小及质量好坏,可分为:
- 完全可加:可按任意维度汇总,如销量/销售额/订单计数等
- 半可加:可按某些维度汇总,但不可按任意维度汇总、如银行账户余额按时间汇总没有意义
- 完全不可加:不可按任意维度汇总,如利润率、合格率、好评率等
-
粒度:度量的单位,如商品是按件记录还是按批记录,选择合适的粒度级别是数仓建设好坏的关键。设计粒度时,要明确具体分析什么?存储资源多少?根据具体需求设计合适的粒度。存储资源越少,设计的粒度就越高,就越不能做细粒度的数据分析。设计粒度需要满足日常业务决策分析的需求
-
口径:取数逻辑
-
指标:口径的衡量值,如统计近7天的销量,近7天就是统计口径,销量就是指标。
- 主要计算部分:计数逻辑(count、max等),指定维度(group by),业务限定(where、case)
- 分类:原子指标(基本业务事实,没有指定维度,没有业务限定,如销量、利润),派生指标(指定维度+业务限定+原子指标,如宝安店(指定维度)近7天(业务限定)的销售额(原子指标),衍生指标(原子指标经过运算得到的,如利润率)
-
标签:根据业务场景人为设定的
-
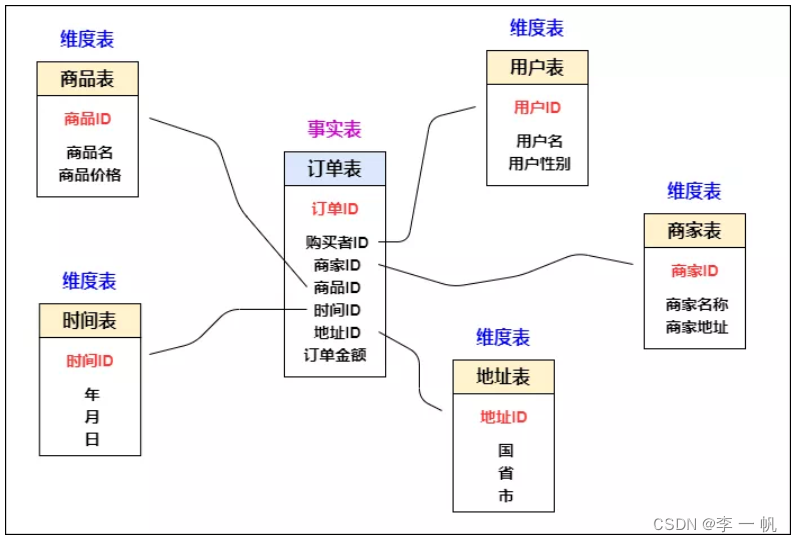
数据表分类
- 实事表:维度和指标的组合,描述业务事实
- 维度表:事实表的一个分析角度,对事实各个方面的描述
- 实体表:只描述各个事务,不存在具体业务事实,也就是只包含维度不包含指标
- 表类型:星型模型、雪花模型、星座模型
-
数据命名规范
-
维度分析
- 上卷/上钻:从细的粒度到粗的粒度来分析数据
- 下钻:从粗的粒度到细的粒度来分析数据
-
退化维度:维度属性存储在事实表, 但是实际上并没有对应的维度表, 这类维度被称为退化维度(冗余信息)
-
键
- 自然键:业务系统的标识符就是自然键, 具有唯一性,比如商品编号\员工编号等
- 持久建:保持永久性不会发生变化, 比如身份证号码
- 代理键:代理键就是不具有业务含义的键, 主要为了连接维度表和事实表
-
数据仓库分层
| 分层 | 解释 |
|---|---|
| 存储层ODS Operational Data Store | 以快照表存储历史的原始数据,不做任何数据转换 |
| 明细层DWD Data Warehouse Detail | 对数据进行规范化(编码转换\数据清洗\统一格式\脱敏等), 不做任何表的关联(横向整合) |
| 主题层DWT Data Warehouse Topic | 对明细层的数据进行横向整合(表关联), 输出主题宽表 |
| 汇总层DMA Data Warehouse Aggregation | 集中建设通用性和高频使用的维度和指标, 降低业务需求开发成本 |
| 应用层APP Data Warehouse Application | 面向业务部门, 对业务需求进行定制开发, 提供报表数据 |
数据仓库流程
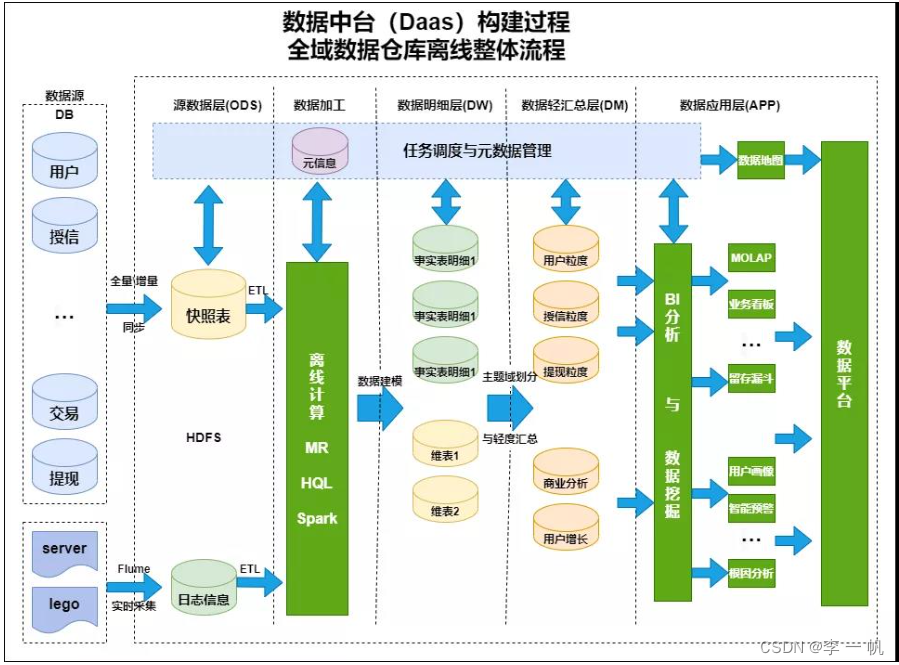















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









