







1.读取数据集
import torch
from IPython import display
from d2l import torch as d2l
from torchvision import transforms
import torchvision
from torch.utils import data
trans = [transforms.ToTensor()]
trans = transforms.Compose(trans)# 此处是为了设置类型
batch_size = 256
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True)#读取数据
test_iter = data.DataLoader(mnist_test, batch_size, shuffle=Flase)#读取数据
2.设置参数
num_inputs = 784 #此处应和一个数据铺开总列数相同
num_outputs = 10 #最终的输出有多少类
W = torch.normal(0,0.01,size = (num_inputs,num_outputs),requires_grad = True)#高斯分布随机数
b = torch.zeros(num_outputs,requires_grad=True)
3.定义softmax
def softmax(X):#指数化
X_exp = torch.exp(X) # 数据全部指数化
partition = X_exp.sum(1,keepdim=True) # 求和作为分母
return X_exp/partition # 求出每个数据占分母的多少分之一,即为概率化
例如
# 测试
X=torch.normal(0,1,(2,5))
X_prob = softmax(X)
X_prob,X_prob.sum(dim=1),X
"""结果为
(tensor([[0.2241, 0.1133, 0.0354, 0.0632, 0.5641],
[0.0420, 0.4374, 0.1621, 0.0691, 0.2894]]),
tensor([1., 1.]),
tensor([[ 0.0875, -0.5948, -1.7580, -1.1788, 1.0108],
[-1.2243, 1.1201, 0.1271, -0.7250, 0.7070]]))
"""
4.定义模型
def net(X):
return softmax(torch.matmul(X.reshape((-1,W.shape[0])),W)+b)
测试交叉熵函数
# 测试交叉熵函数
y = torch.tensor([0,2])
y_hat = torch.tensor([[0.1,0.3,0.6],[0.3,0.2,0.5]])
y_hat[[0,1],y]
"""
输出结果为:
tensor([0.1000, 0.5000])
"""
5.损失函数
# 定义损失函数
def cross_entropy(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)),y])#对数,正确标签的对数
cross_entropy(y_hat,y)
"""
tensor([2.3026, 0.6931])
"""
6.求分类标签正确的个数,再除以总数,即为精度。由此求精度。
# 分类精度 ----返回的是正确的标签个数
def accuracy(y_hat,y):
if len(y_hat.shape)>1 and y_hat.shape[1]>1 :
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
# 测试
accuracy(y_hat,y)/len(y) # 此处除以总数,即为精度
0.5
其中的那么多的dtpye 是为了将最终的输出转化为0,1,从而计算1的个数,判断正确的有多少。
测试如下:
y_h = y_hat.argmax(axis=1)
c = y_h.type(t.dtype) == y
c.type(y.dtype).sum()
"""输出为
tensor(1)
"""
7.求精度的具体实现
# 可评估任意模型net的精度
def evaluate_accuracy(net, data_iter):
if isinstance(net,torch.nn.Module):#判断模型是否是nn中的训练模型,意义不明
net.eval()#开启评估模式
metric = Accumulator(2)
with torch.no_grad(): #只是为了让下面的for语句计算结果是标量,即为requires_grad = Flase,为了节约内存
for X,y in data_iter:
metric.add(accuracy(net(X),y),y.numel())#这里是把正确的标签个数加起来放在metri[0],总的放在metric[1]中
return metric[0]/metric[1] #所有正确的精度加起来为metric[0],总样本个数为metric[1]
8.定义实用类累加器,从而把所有正确的概率全部加在一起。
class Accumulator: # 不断的累加
"""在n个变量上累加"""
def __init__(self, n): #此处的 n 仅为需要几列数据定义,并不是数据长度
self.data = [0.0] * n
def add(self, *args):#累加
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
测试累加器
a = Accumulator(3)
#print(a.data)
b= 0.1
for i in range(4):
a.add((i+5)/10,i*10)
#print(i,a.data)
a[0]/a[1]
a_hat = torch.tensor([0.1,0.6,0.5,0.3])
accuracy(y_hat,y)
"""
输出:
1.0
"""
9.训练函数
# 训练
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y) #得到log
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad() #梯度置零
l.mean().backward() #回滚,计算梯度
updater.step() #更新参数
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0]) # X.shape[0]是此时y的长度,即为此时批量的大小
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel()) #将相关数据通过累加器累加起来,用来计算精度
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
10.画图函数
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
11.训练模型,并且画图,仅for为训练
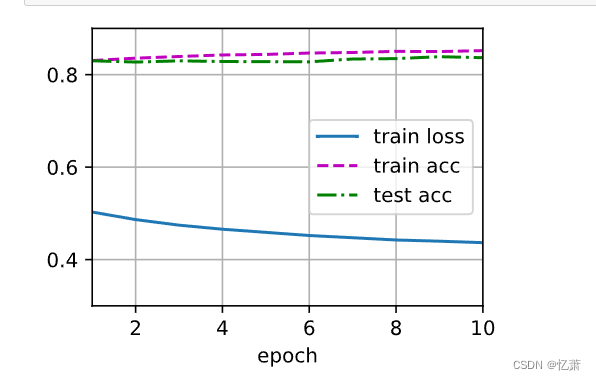
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
12.定义参数-并且训练-画图(需要点时间,半分钟左右)
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
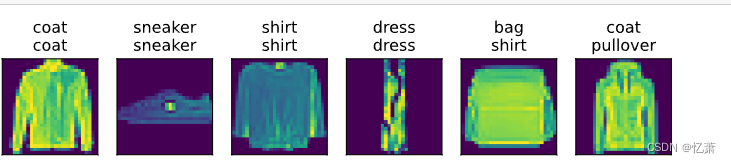
预测标签
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)
13.以下为个人部分笔记
#判断二者为同一类型
isinstance(1,int)
# 测试 损失函数 --不严谨、简单测试
X=torch.normal(1,1,(2,5))
y=torch.tensor([1,0])
print(X,cross_entropy(X,y))
"""
tensor([[ 0.2384, 0.9031, -0.1576, 2.7306, 0.4581],
[ 2.9696, 3.3440, 0.9458, 1.2803, 2.0923]]) tensor([ 0.1019, -1.0884])
"""
#各部分的shape
W.shape #torch.Size([784, 10]) # 总的规模数
W[0].shape # torch.Size([10]) #一行有多少列
W.shape[0] # 784 在[784,10]中,即为总规模中查看有多少行,同理,1 为列
# softmax的具体形式
def softmax_test(X):
print(X)
X_exp = torch.exp(X)
print(X_exp)
partition = X_exp.sum(1,keepdim=True)
print(partition)
return X_exp/partition
test_1 = torch.tensor([[1,2,3],[4,5,6]])
d= softmax_test(test_1)
d
"""
tensor([[1, 2, 3],
[4, 5, 6]])
tensor([[ 2.7183, 7.3891, 20.0855],
[ 54.5981, 148.4132, 403.4288]])
tensor([[ 30.1929],
[606.4401]])
tensor([[0.0900, 0.2447, 0.6652],
[0.0900, 0.2447, 0.6652]])
"""
#测试累加器
a = Accumulator(3)
for i in range(4):
a.add((i+5)/10,i*10)
print(i,a.data)
a[0]/a[1]
#输出结果:
"""
0 [0.5, 0.0]
1 [1.1, 10.0]
2 [1.8, 30.0]
3 [2.6, 60.0]
0.043333333333333335
"""















 1406
1406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









