







# -*- coding: utf-8 -*-
# @Time : 2022/5/26 14:07
# @Author : CWK
# @File : zhang20220526.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def rename_head(df): # 更改第一列的列名
col_head = df.columns[0]
df.rename(columns={col_head: "time_key"}, inplace=True) # 必须要加上inplace=True,才能改变d1表
def time_Resample(df): # (重采样)降采样处理,变为分钟级别
df['time_key'] = pd.to_datetime(df['time_key']) # 不加format也行,pandas自动推断日期格式,format='%Y-%m-%d %H:%M:%S'
df = df.set_index(df['time_key']) # 建立时间序列索引
df = df.resample('T', closed='left').mean() # 默认使用左标签(label=‘left’),左闭合(closed='left’)00:00:00~00:04:59 左标签00:00:00
return df
先导入包,rename_head(df)是因为原始数据列名有误,更改原始数据的列名先,time_Resample实现降采样的处理(将时间序列转化为分钟级的数据,这里的分钟内取的是mean均值。还有取值方法。),核心是resample函数。
选取excel特定两列:
df = pd.read_csv("sss.csv")
rename_head(df)
df = df.loc[:, ['time_key', 'kwh_chg']]
**df = df.loc[:, ['time_key', 'kwh_chg']]**实现选取excel表中的两列数据。
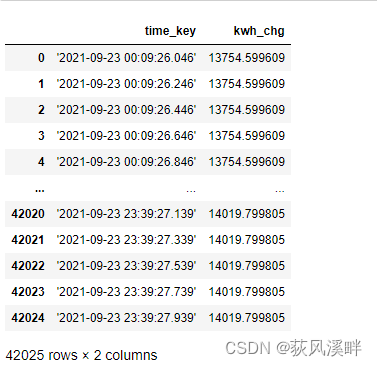
上下行数值相减:
df['kwh_chg']=df['kwh_chg'].diff()实现下一行减去上一行
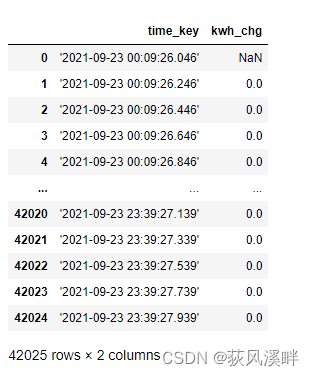
注意第一行没得减,变成缺失值!!
缺失值处理,按数值范围去除行的处理:
df['kwh_chg']=df['kwh_chg'].diff()
df = time_Resample(df) # 整体降采样
df = df.reset_index() # 采样完成后,重置索引(即将时间序列索引变为列,使用新的顺序索引)
df["time_key"] = df["time_key"].astype("datetime64[m]") # 必须先采样,再设置日期类型为分钟级
df=df.dropna()
df.drop(df[df.kwh_chg <= 0].index,inplace=True)
降采样完成后用df=df.dropna()暴力去除缺失值所在行先,
df.drop(df[df.kwh_chg <= 0].index,inplace=True) 去除所有kwh_chg 列小于等于0的行。
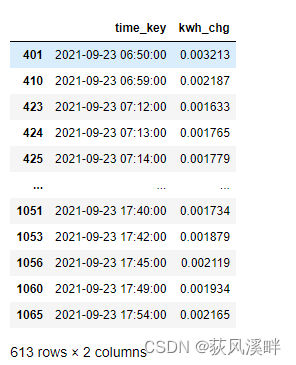
最后剩下613行分钟级别的数据。
画图(pandas依赖matplotlib可以很方便的实现):
df.plot("time_key", 'kwh_chg')
plt.show()
在pycharm中必须加上plt.show(),才能显示!!!!
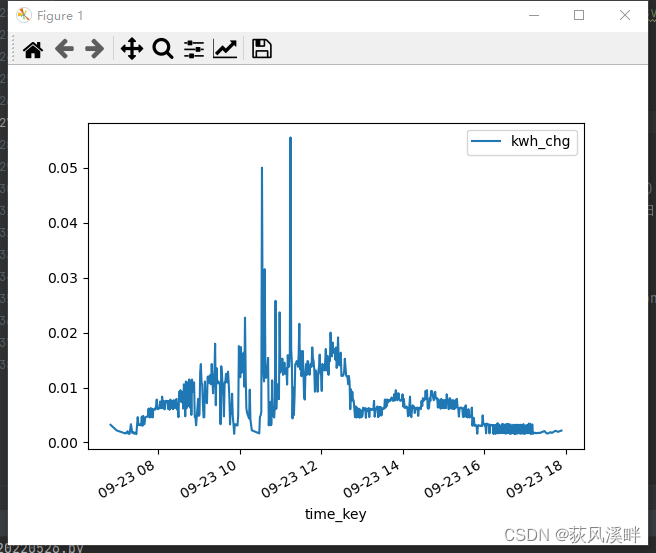
ps:上面所有代码连起来是完整程序。
















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









