







CNN卷积网络神经网络----笔记梳理
前言:
本文知识作者在学习相关知识时一些自己的整理和理解,写这篇博客是为了后续更好的查阅和掌握相关知识,内容多为借鉴和一些自己的理解,其中若有错误和其他不便之处欢迎大家指出,共同学习!
借鉴于:https://blog.csdn.net/v_JULY_v/article/details/51812459
一,神经网络
前面我们说了神经网络,在了解神经网络之后我们对于人工智能的处理问题的方法和思路一定有了新的认知。我们知道神经网络是由输入层–隐藏层–输出层组成的。
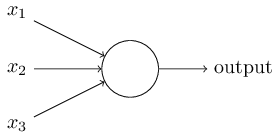
这是一个神经元,一群这样的神经元组合在一起就成了我们说的神经网络。下面这个就是典型的三层神经网络。

∙
\bullet
∙输入层(Input layer),众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。
∙
\bullet
∙输出层(Output layer),讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。
∙
\bullet
∙隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数。
每一层的输出经过激活函数和自身权重的更新变成下一层的输入,在输入层和隐藏层都有一个偏置项,如下图

图中的x
0
_{0}
0,a
0
_{0}
0就是偏置项。
a
i
j
_{i}^{j}
ij就是第j层第i个单元的激活函数;
Θ
j
\Theta^{j}
Θj就是从第j层映射到j+1层的权重矩阵。如下图显示
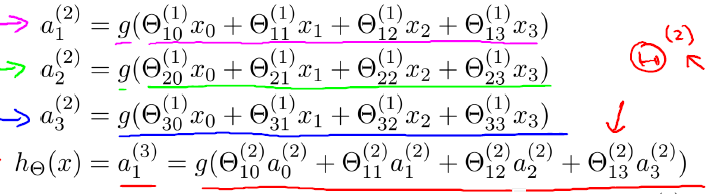 注:这里每一层之间都是全连接结构。
注:这里每一层之间都是全连接结构。
二,卷积神经网络之层级结构

对于上面图片,CNN的作用就是要对于一张给定的未知图片,我们要求判定出这是什么,是牛是马还是车?
先把上面的结构分析清楚:
∙
\bullet
∙ 最左边是数据输入层,对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
∙
\bullet
∙ 中间是:
CONV:卷积计算层,线性乘积 求和。
RELU:激励层,ReLU是激活函数的一种,它比sigmd函数在CNN中有更好的优势。在梯度下降中,sigmoid容易饱和、造成终止梯度传递,且没有0中心化。RELU的优势是收敛快,求梯度简单。
POOL:池化层,有平均池化和最大值池化。就是字面意思,求均值或者是最大值。cnn用的基本是最大池化,即每个小的区域取最大值,最后把所有的最大值组成新的小矩阵。
∙ \bullet ∙ 最右边是FC:全连接层。
三,CNN之卷积计算层
对于CNN来说,输入的图片都转换成像素的矩阵,然后对于多个特征进行比较判断,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配。相对于传统的直接对比,这样的识别率和正确率都更高一些。
每一个feature就像是一个小图(就是一个比较小的有值的二维数组)。不同的Feature匹配图像中不同的特征。在字母"X"的例子中,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。

这些features很有可能就是匹配任何含有字母"X"的图中字母X的四个角和它的中心。那么具体到底是怎么匹配的呢?如下:





现在你只知道了那些特征是如何进行匹配的,但是具体应该怎么计算,下面告诉你。

这里面的数学操作,就是我们常说的“卷积”操作。接下来,我们来了解下什么是卷积操作。
四,什么是卷积
对图像和滤波器filter做内积的操作就是所谓的卷积。
滤波器filter:是一组恒定的权重。
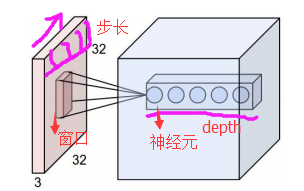
注:在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,
数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
a. 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
b. 步长stride:决定滑动多少步可以到边缘。
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
在所有大的二维矩阵输入后经过卷积计算输出的矩阵都会变小。为了确保我们的输出和输入保持一致大小,我们需要进行填充,一般填充0;
计算公式
假设输入的是n * n的矩阵,过滤器是f * f的,输出矩阵是m * m,p为填充数,s为步长;
∙
\bullet
∙ Valid卷积(无填充) m=n-f+1;
∙
\bullet
∙ Same卷积(输出等于输入大小),用p个像素填充,m=n-f+2p+1=n;所以确定p的值,p=(f-1)/2; 注:f基本都是偶数。
∙
\bullet
∙ 当s!=1时,m=(n-f+2p)/s+1;注:当不能整除时,向下取整。
∙
\bullet
∙ 三维图像卷积的计算:
输入:n* n* n
c
_{c}
c,过滤器:f* f* n
c
_{c}
c,两个n
c
_{c}
c相同
输出:m=(n-f+1)* (n-f+1)* n
c
‘
^{`}_{c}
c‘ (n
c
‘
^{`}_{c}
c‘是过滤器的个数)
举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。

中间滤波器filter与数据窗口做内积,其具体计算过程则是:4* 0 + 0* 0+ 0* 0 + 0* 0 + 0* 1 + 0* 1 + 0* 0 + 0* 1 + -4* 2 = -8。对应元素相乘然后相加。
五,GIF动态卷积图

可以看到:
∙
\bullet
∙ 两个神经元,即depth=2,意味着有两个滤波器。
∙
\bullet
∙ 数据窗口每次移动两个步长取3*3的局部数据,即stride=2,zero-padding=1。
然后分别以两个滤波器filter为轴滑动数组进行卷积计算,得到两组不同的结果。(几个过滤器得到几个结果)
∙
\bullet
∙ 左边是输入(7 * 7 * 3中,7 * 7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)
∙
\bullet
∙ 中间部分是两个不同的滤波器Filter w0、Filter w1
∙
\bullet
∙ 最右边则是两个不同的输出
随着左边数据窗口的平移滑动,滤波器Filter w0 / Filter w1对不同的局部数据进行卷积计算。
注: 左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的CNN中的局部感知机制。
计算过程中,是每个相应的小矩阵对应相乘相加,最后得到的值在相加得到最后输出矩阵对应位置的结果。
打个比方,滤波器就像一双眼睛,人类视角有限,一眼望去,只能看到这世界的局部。如果一眼就看到全世界,你会累死,而且一下子接受全世界所有信息,你大脑接收不过来。当然,即便是看局部,针对局部里的信息人类双眼也是有偏重、偏好的。比如看美女,对脸、胸、腿是重点关注,所以这3个输入的权重相对较大。
但是在平移计算中,过滤器的权重是固定不变的,这就是cnn的参数共享机制。
六,CNN网络传播原理详解
在CNN网络构建完之后,我们要进行训练,训练的过程就是对这个神经网络不断的提供任务,让模型在执行任务的过程中不断的积累经验,最终对类似的事件可以进行判断。
在进行传播时,我们要了解前向传播和反向传播,在传播的过程中,我们要了解权重的更新和激活函数的选择。
具体的更新方法和步骤,大家可以参考一下博主的博文,写的非常详细。
https://blog.csdn.net/LEEANG121/article/details/102646805















 25万+
25万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









